Intel Pentium 4 „Prescott“ im Test: Rückschritt dank Fortschritt?
4/29Mehr Cache wohin man schaut
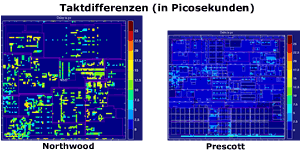
Der verbesserte Fertigungsprozess ermöglicht also kleine Strukturen und eine höhere Transistorendichte. Wer nun glaubt, der Prescott sei nicht mehr als ein geschrumpfter (shrinked) Pentium 4 mit Northwood Kern, der täuscht! Auch wenn die CPU nach wie vor auf der Netburst-Architektur des ersten Pentium 4 (Willamette) basiert, so hat Intel die Anordnung der Recheneinheiten auf dem Prozessorkern komplett geändert. Ansporn dieser Umverteilung war das Ziel, beim Prescott eine möglichst gleichmäßige Verteilung des Prozessortaktes zu erreichen. Mit anderen Worten: Möglichst alle Units sollten sich in der selben Schwingungsphase befinden. Dadurch wird es unkomplizierer an der Taktschraube zu drehen. Laut Intel ist die Clock Distribution beim Prescott gegenüber seinem 0,13 µm Vorgänger um den Faktor vier besser. Also auf zu neuen Taktrekorden.
Um die Hatz nach höheren Taktfrequenzen weiter zu unterstützen, hat Intel heimlich, still und leise die ohnehin schon recht lange Pipeline der Pentium 4 Prozessoren weiter verlängert: Vorher war man mit 20 Pipeline-Stages bei Desktop-Prozessoren der Spitzenreiter, nun ist man mit 31 Stages uneinholbar vorne. Nun gut, die eine Zahl ist größer als die andere, doch was bedeutet das für den Endverbraucher? Hierfür muss natürlich klar werden, was man sich unter den Pipeline-Stages vorstellen muss. Das lässt sich sehr gut mit einer Schnitzeljagd vergleichen. Der Proband ist in diesem Fall eine Instruktion, die um ins Ziel zu gelangen, also fertig bearbeitet zu werden, gewisse Stationen anlaufen muss. Beim Pentium 4 der ersten und zweiten Generation (Willamette, Northwood) waren es noch 20 Stationen. Pro Takt kann die Instruktion nur eine Station anlaufen. War die Instruktion bisher also nach 20 Takten am Ziel, sind nun schon 31 Takte nötig.
Doch das ist nur die halbe Wahrheit, denn: Bei einer 20-stufigen Schnitzeljagd sind die "Rätsel" natürlich komplizierter als bei einer mit 31 Stufen. Deshalb muss man bei weniger Fragen auch mehr Gehirnschmalz anstrengen, als das bei vielen kleinen Fragen der Fall ist. Geht man zu hastig an die Sache, schleichen sich bei ersterem natürlich schneller Flüchtigkeitsfehler ein. Man muss also jede Station mit weniger "Takt" anlaufen. Bei 31 Stufen kann man dagegen mehr Tempo machen. Beide Varianten haben als sowohl Vor- als auch Nachteile.

Übrigens versucht ein moderner Prozessor aufgrund von Hardware Data Perfetching und Branch Prediction die nächsten Rätsel der Schnitzeljagd vorher zu erraten und beginnt ohne gefragt zu werden mit der Lösung des Problems. Hat er richtig geraten, so kann er sich glücklich schätzen, lag er daneben muss er komplett von vorne beginnen. Das ist bei einer langen Pipeline natürlich um so schmerzlicher. Abkürzen ist also nicht immer hilfreich, doch der Prozessor kann nicht anders! Also sollten diese Algorithmen zum Vorhersagen möglichst gut arbeiten.
Hier hat Intel beim Prescott gleich drei Verbesserungen vorgenommen: Das Simple Static Branch Prediction Schema, welches genutzt wird, wenn der Branch Target Buffer (BTB) keine Vorhersage für einen Rechenzweig abliefert, wurde verbessert. Gleiches trifft auch auf den Dynamich Branch Prediction Algorithmus zu, der nun weniger falsche Vorhersagen treffen soll. Außerdem hat man sich von den Ergebnissen des Pentium M (Banias, Kernstück der Centrino Mobile Technology) begeistern lassen und integrierte nun einen „Indirect Branch Predictor“. Tests mit Spec CPU2000 bestätigen diese Verbesserungen. Unter bestimmten Bedingungen hat sich die Anzahl der falschen Vorhersagen sogar halbiert.
Manchmal fehlt dem Prozessor auch das Wissen, einen Sachverhalt zu verarbeiten, und so muss er deshalb auf Informationen aus dem Arbeitsspeicher warten - die Pipeline wird blockiert. Damit das nicht vorkommt, verfügt ein Prozessor über besonderes schnelle Zwischenspeicher (Caches), durch die Zugriffe auf den langssamen Arbeitsspeicher reduziert werden sollen. Beim Prescott hat Intel die Größe des L1 Data Caches verdoppelt. Desweiteren ist er nun achtfach verknüpft, bisher war er nur vierfach assoziativ. Auch sonst wurden viele andere Caches vergrößert: Die Floating Point Schedulers haben nun vier Einträge mehr, die Store Buffers wurde von 24 auf 32 erweitert, die Load Request Buffers von vier auf acht und die Write Combining Buffers von sechs auf acht. Weiterhin wurde der L2-Cache abermals verdoppelt: Beim Willamette waren es nur 256 kB, beim Northwood 512 kB und nun sind es 1024 kB. Damit zieht man mit der Konkurrenz von AMD gleich. Stellenweise steht somit jedem virtuellen Hyper-Threading-Prozessor doppelt so viel schneller Cache-Zwischenspeicher zur Verfügung.
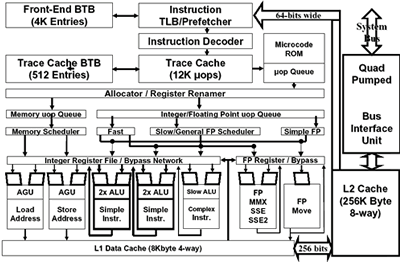
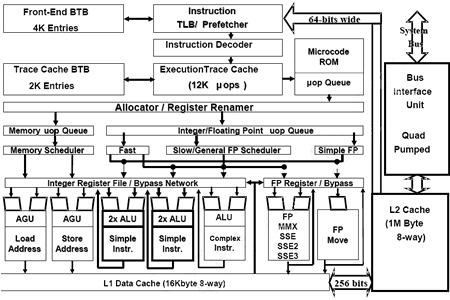
Weitere Verbesserungen betreffen das verbesserte Erkennen von Befehlsabhängigkeiten, was wiederum Register (kleine Speicher) spart.
Bisher wurden Abhängigkeiten bei den Befehlen xor, pxor und sub erkannt. Neu hinzugekommen sind jetzt xorps (SSE), psub und xorpd (SSE3). Zudem können nun mehr µOp-Typen im Trace Cache abgelegt werden, wodurch der Microcode ROM entlastet wird, der wie bisher die für den Trace Cache zu komplexen Instruktionen aufnimmt. Während im Microcode ROM also x86-Befehle landen, erhält der Trace Cache gleich die dekodierten (so genannten) Mikro-Operations. Auch bei einer ALU (Arithmetic Logic Unit) wurde etwas verbessert.