Intel Core 2 Extreme QX9650 im Test: Mit Penryn auf und davon
3/27Penryn-Architektur
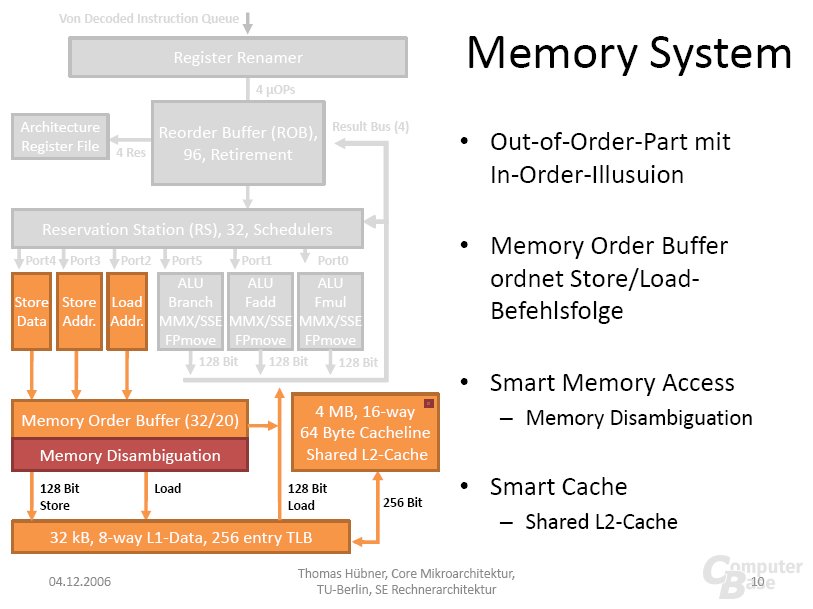
Die Penryn-Mikroarchitektur wird in den Bereichen Mobile, Desktop, Workstation (DP) und Server (MP) eingesetzt werden. Ihrem Einsatzgebiet entsprechend besitzen einige dieser Boliden besondere Funktionen. In einem solchen Fall wird explizit darauf hingewiesen. Als naher Verwandter der Core-Mikroarchitektur wird auf vererbte Besonderheiten im Vergleich zu Pentium 4 und Athlon 64 nicht gesondert eingegangen. Für ein Grundverständnis von Core und der Befehlsausführung innerhalb einer Out-of-Order Pipeline wird eine Betrachtung der folgenden Bildgalerie empfohlen.
-
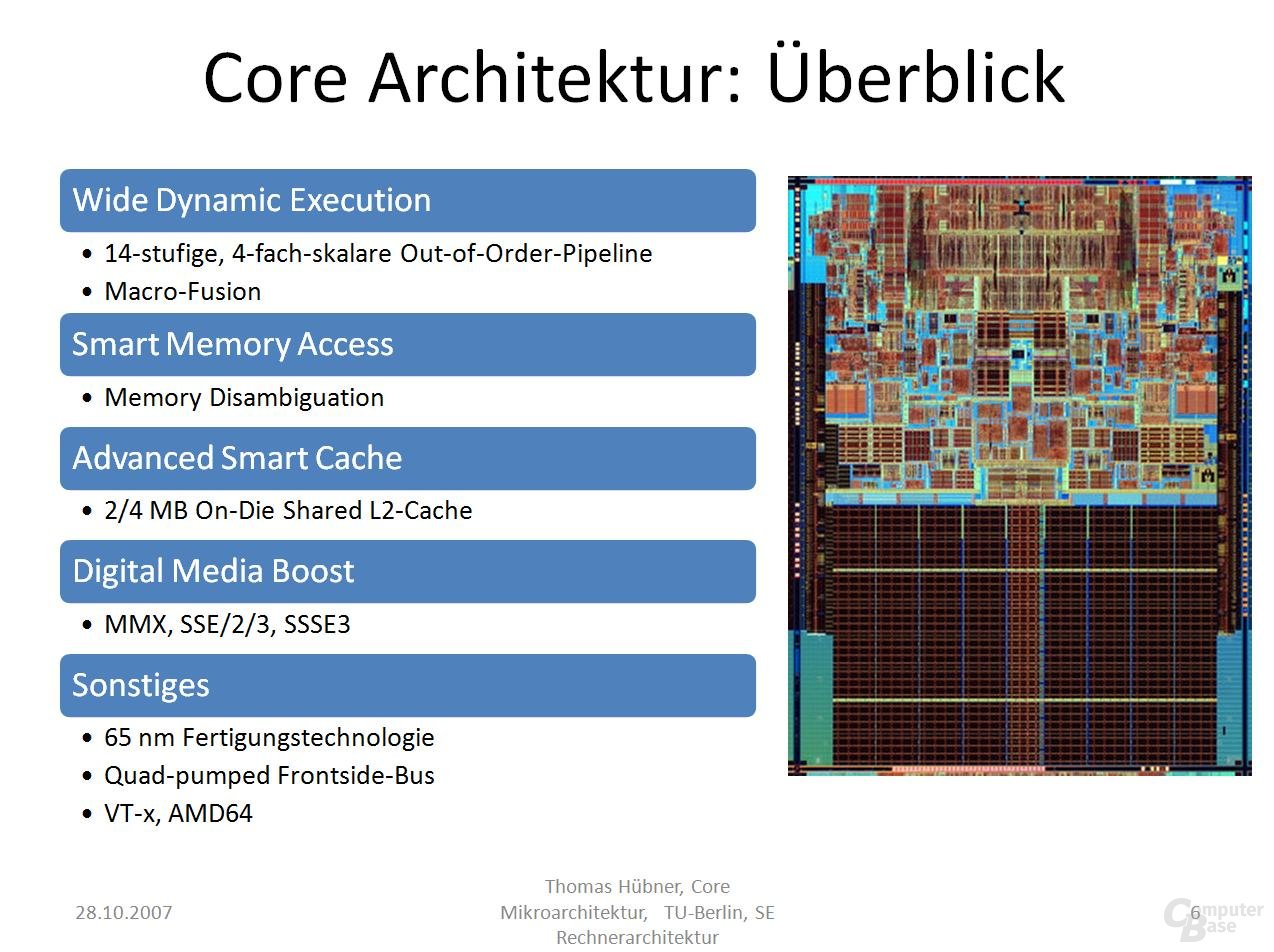 Intel Core Mikroarchitektur im Überblick
Intel Core Mikroarchitektur im Überblick
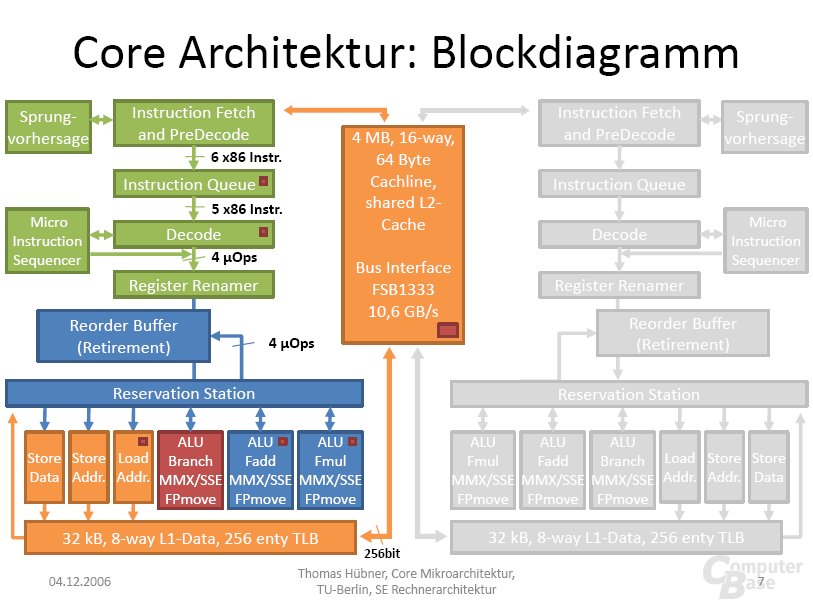
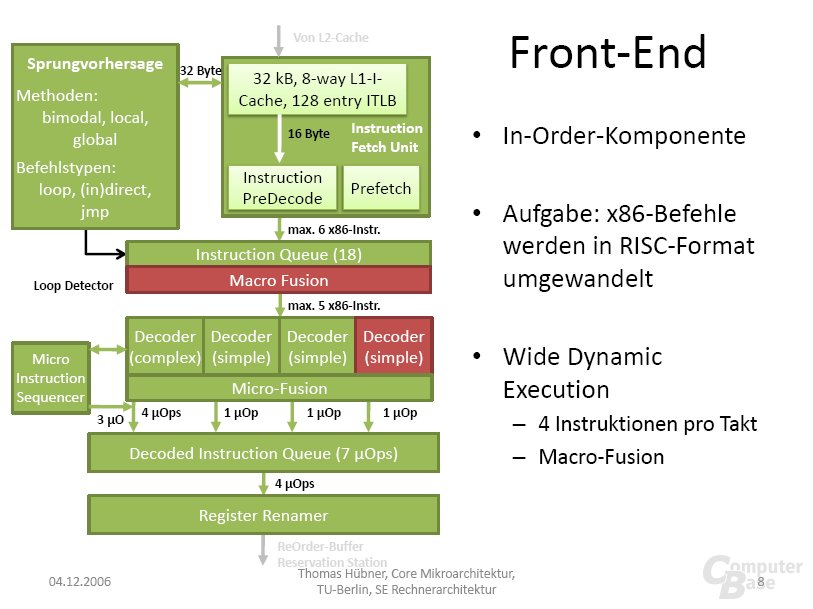
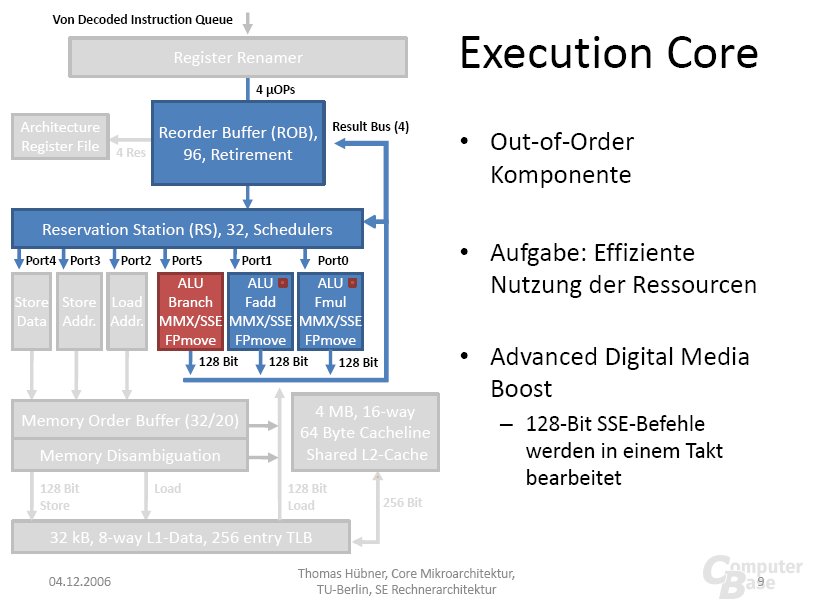
Doch nun zur Penryn-Familie: Nach dem derzeitigen Wissenstand sind Modelle mit zwei bis sechs Prozessorkernen geplant, die die folgenden Codenamen tragen.
- Mobile: Penryn (Dual Core), ? (Quad Core, zwei Penryn-Chips)
- Desktop: Wolfdale (Dual Core), Yorkfield (Quad Core, zwei Penryn-Chips)
- Workstation: Wolfdale-DP (Dual Core), Harpertown (Quad Core, zwei Penryn-Chips)
- Server: Dunnington (6-Core, ein Chip, ungesichertes Gerücht)
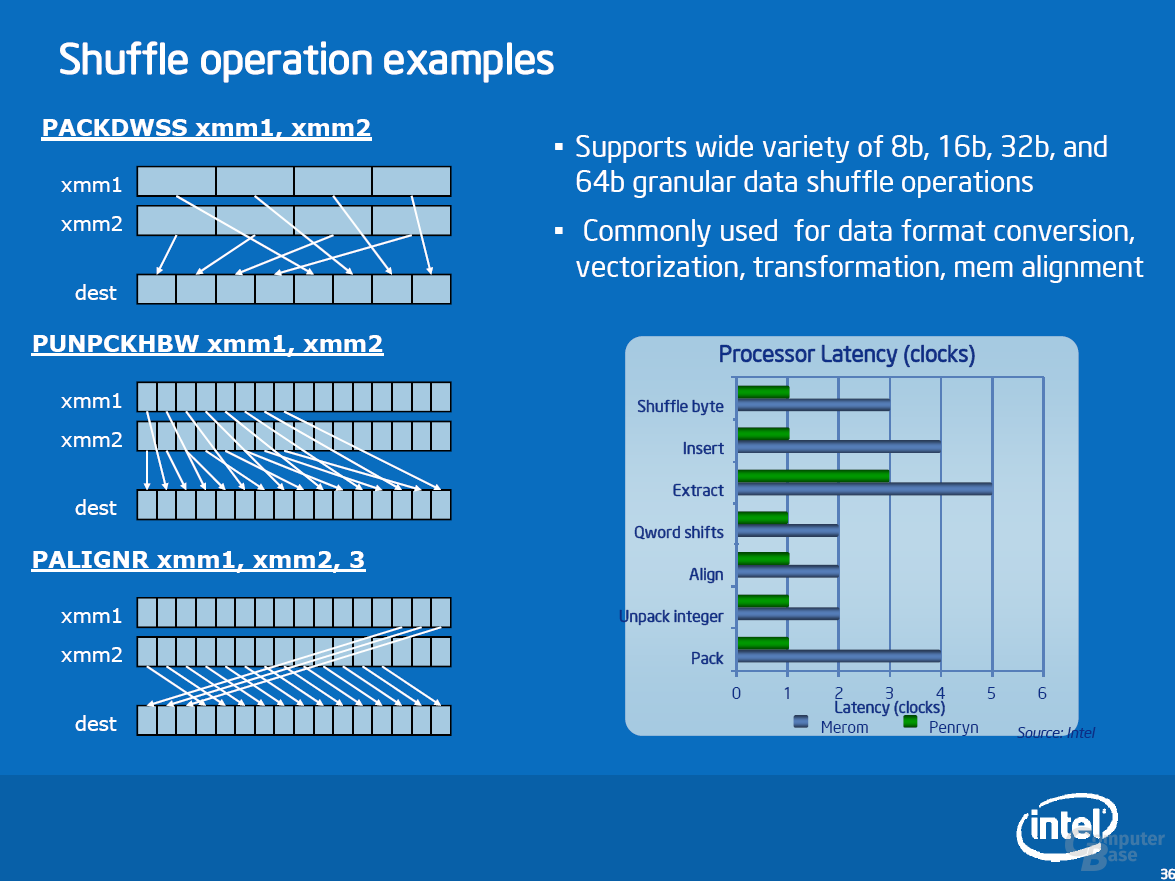
Die Verbesserungen von Penryn konzentrieren sich in den Bereichen Out-of-Order Execution, Cache/Speicher und Power Management. Im Bereich Execution wurde die bisherige Radix-4- durch eine Radix-16-Dividierer/Quadratwurzeleinheit ersetzt. Außerdem beschleunigt die neue Super Shuffle Engine SSE-Befehle, die mit der Bitmanipulation zu tun haben. Des Weiteren unterstützten die drei vorhandenen SSE-Einheiten nun SSE4. Im Bereich Cache/Speicher wurde das Store Forwarding verbessert und die Assoziativität des L2-Caches erhöht. Das Power Management wurde um einen C6-State (Deep Power Down) und eine verbesserte Dynamic Acceleration Technology (EDAT) komplettiert. Darüber hinaus gibt es einige Optimierungen im Detail.
Ein Penryn-Chip (Dual Core) besitzt 410 Millionen Transistoren auf einer Fläche von 107 mm². Für den Aufbau einer Cache-Speicherzelle (SRAM) werden 6 Transistoren benötigt. Bei einem 6 MByte großen L2-Cache entfallen auf diesen 288 Mio. Transistoren (+Steuerlogik). Merom kam bei 4 MB L2-Cache auf insgesamt 291. Mio. Transistoren. Bei einer Transistordifferenz von 119 Mio. entfallen rund 100 Mio. auf den größeren Cache, die übrigen 19 Mio. schlagen sich in den neuen und verbesserten Funktionseinheiten nieder.

Das Front-End der Pipeline wurde nicht verändert. Bei 64-Bit-Befehlen ist daher Macro-Ops-Fusion auch weiterhin nicht aktiv. Intel hat eine Änderung des Front-Ends in Betracht gezogen, die benötigten Änderungen hätten jedoch zu viele Datenpfade in ihrer Breite verändert und weitere Anpassungen erfordert – zu viel für ein „Tick“.
Out of Order Execution: SSE4
Zur Beschleunigung von Multimedia-Anwendungen wartet Penryn mit SSE4.1 auf. Diese SIMD-Erweiterung beinhaltet 47 neue Befehle, die sich über verschiedene Bereiche erstrecken. Obwohl die neuen Befehle verschiedene Bereiche abdecken, sieht Intel eigentlich nur einen Bereich, in dem SSE4 für einen massiven Geschwindigkeitsschub sorgen kann: Videoencoding. Allgemeiner ausgedrückt: alle Algorithmen, die eine Motion Estimation durchführen müssen – Spiele gehören in aller Regel nicht dazu. Details zu SSE4 und Beispiele sind der Bildgalerie zu entnehmen.
-
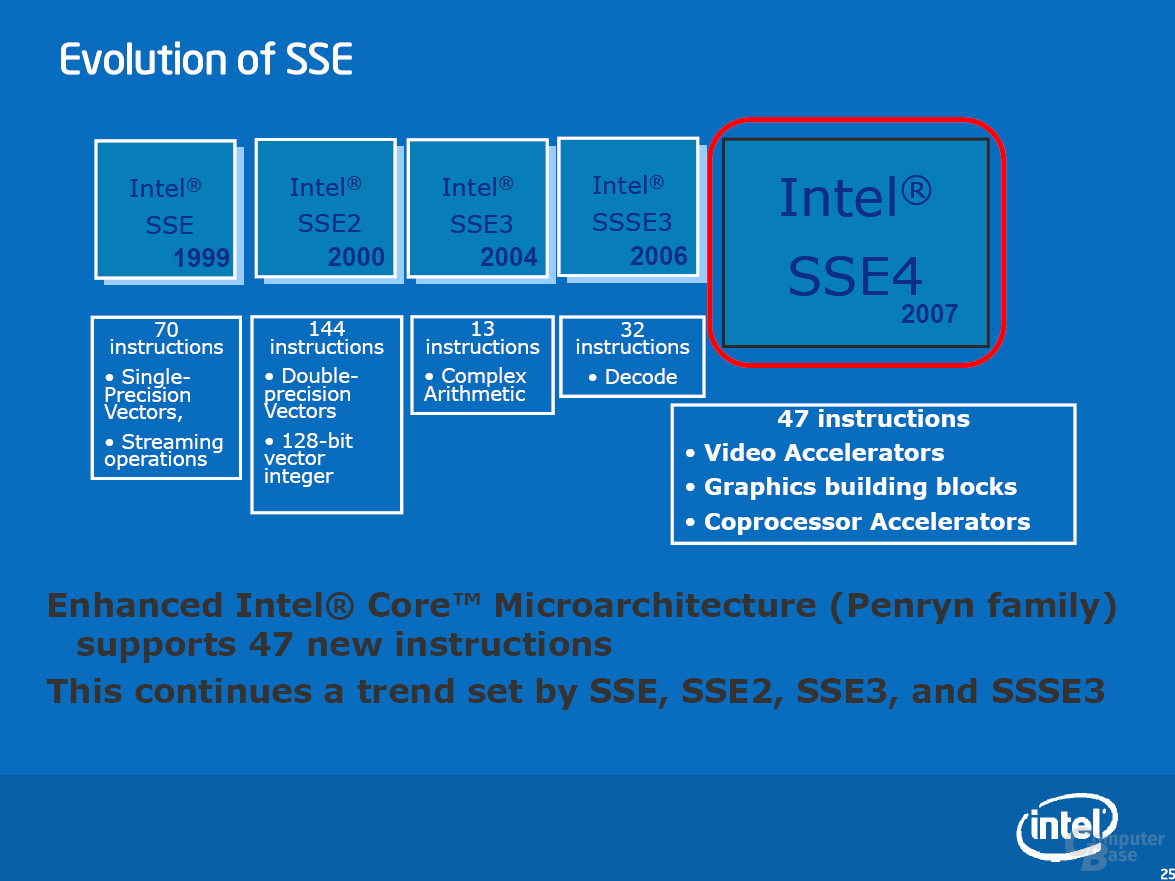 SSE4.1-Erweiterung von Penryn
SSE4.1-Erweiterung von Penryn
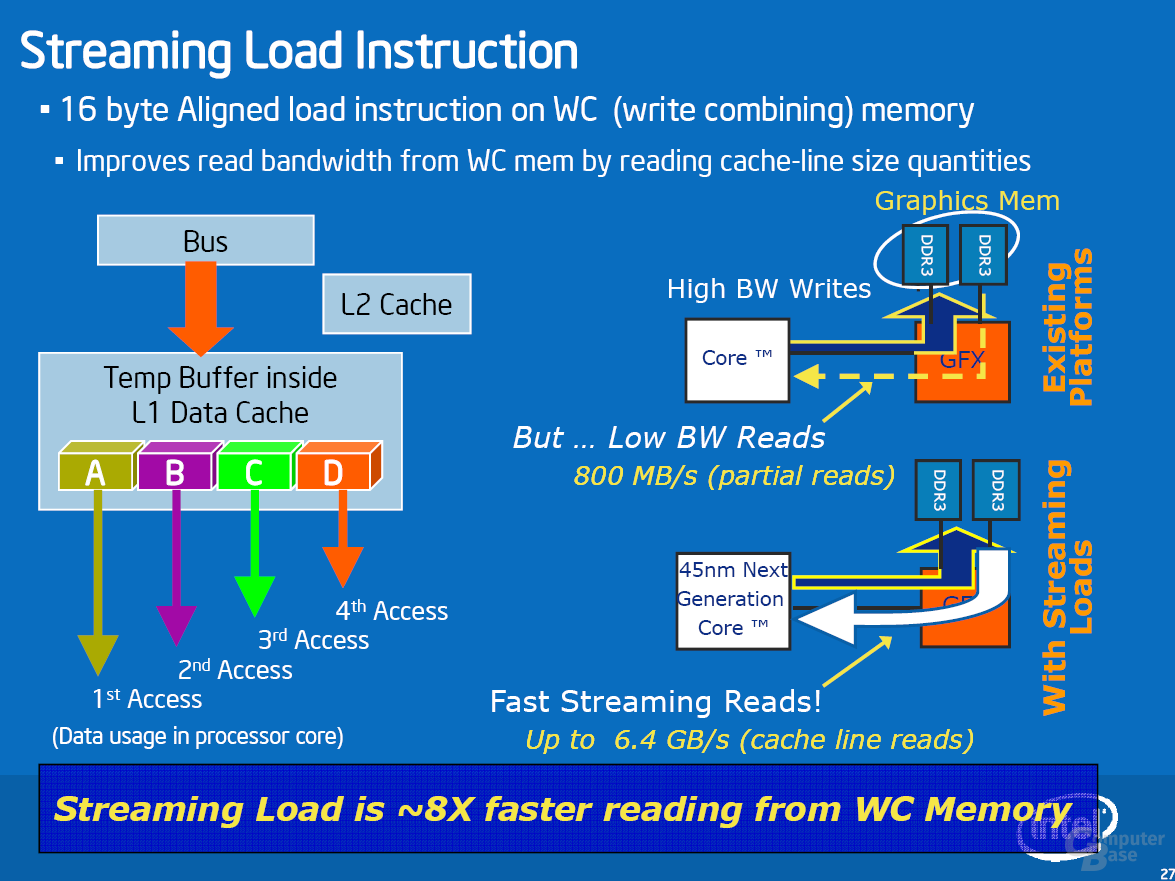
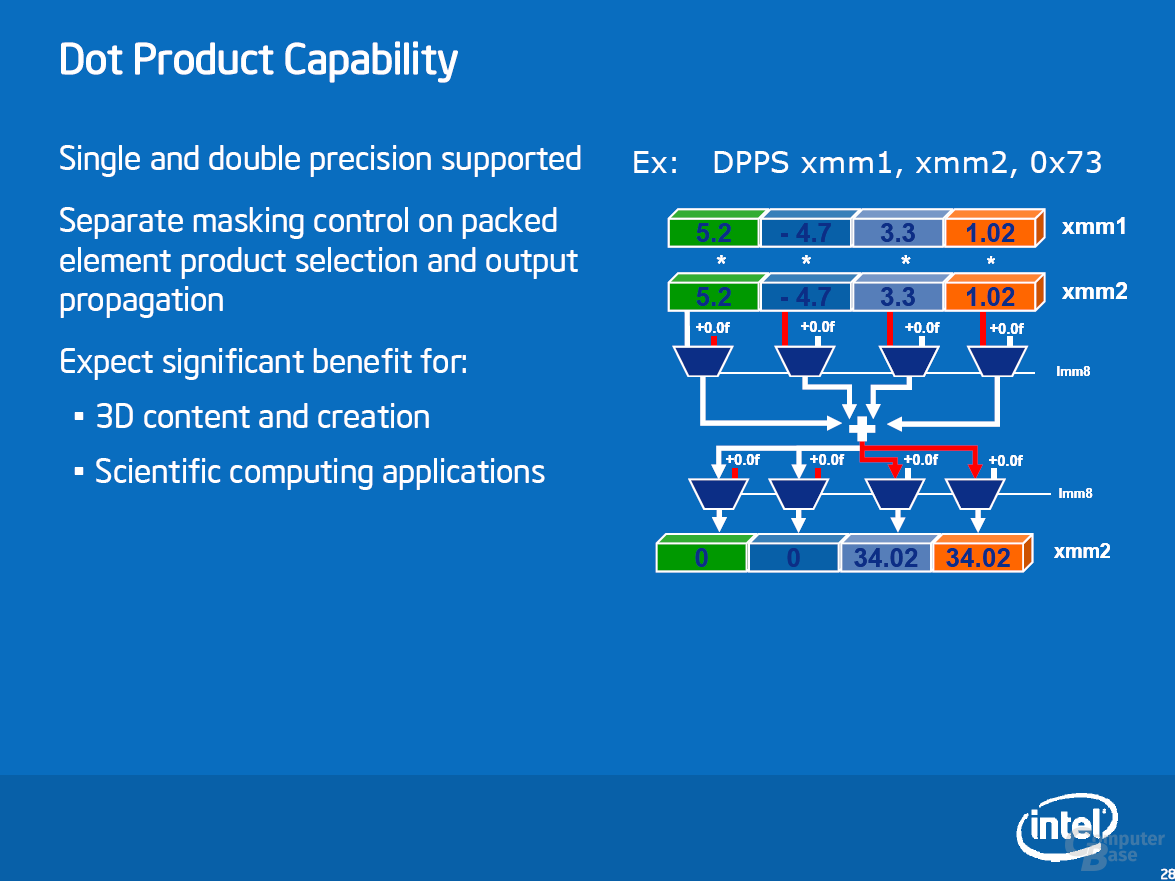
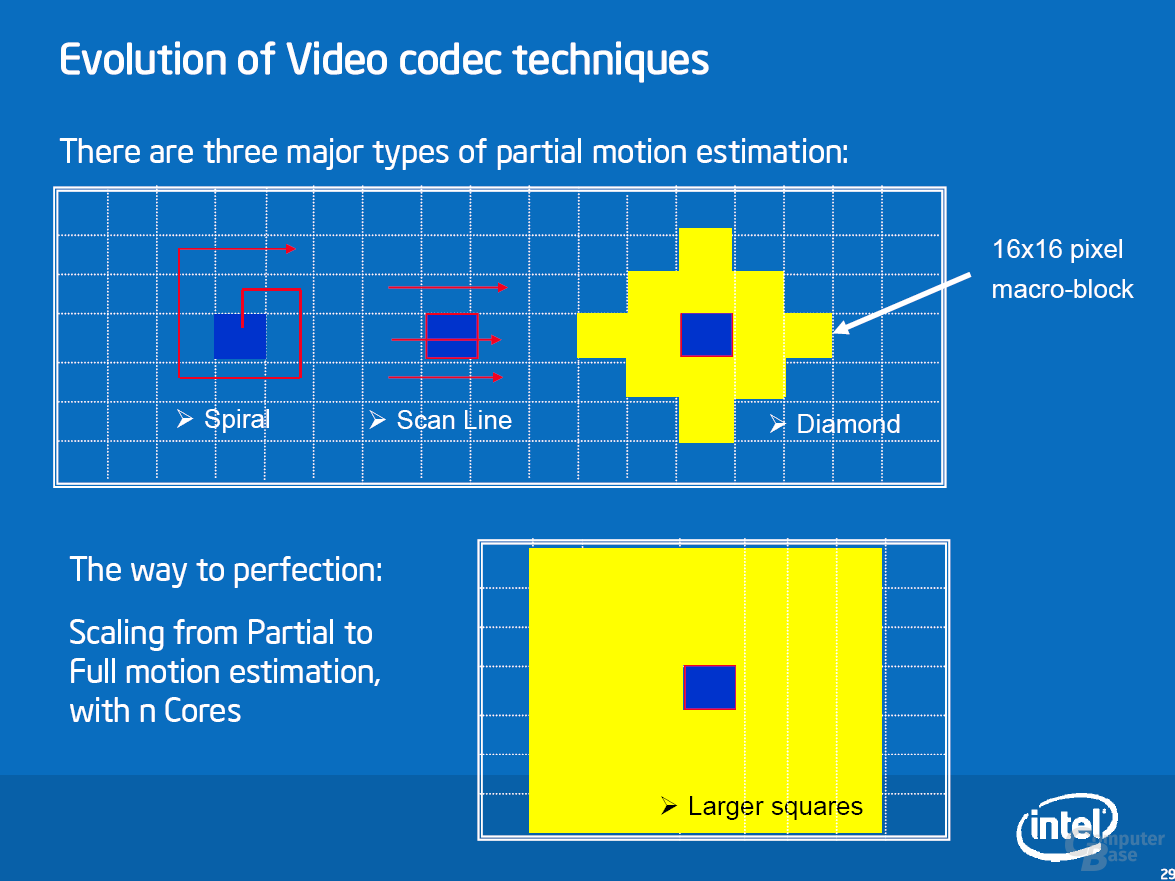



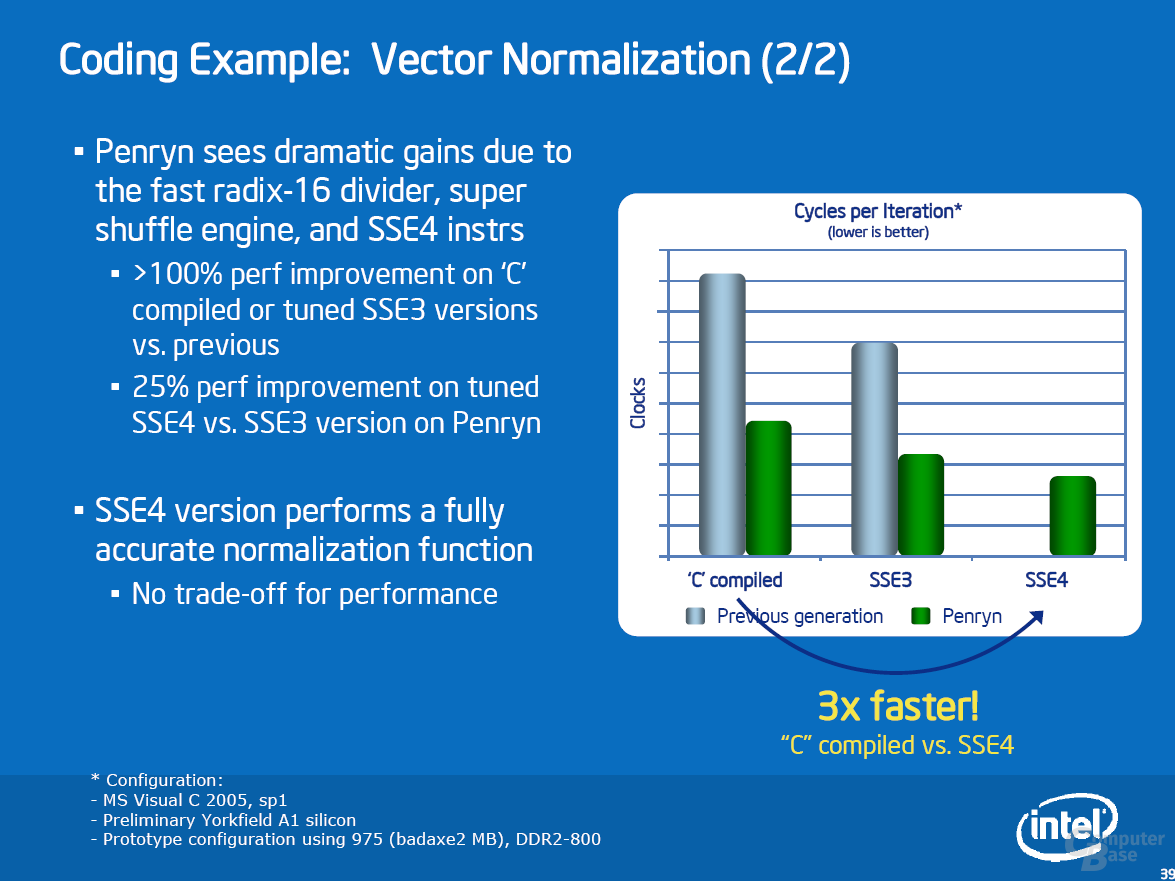



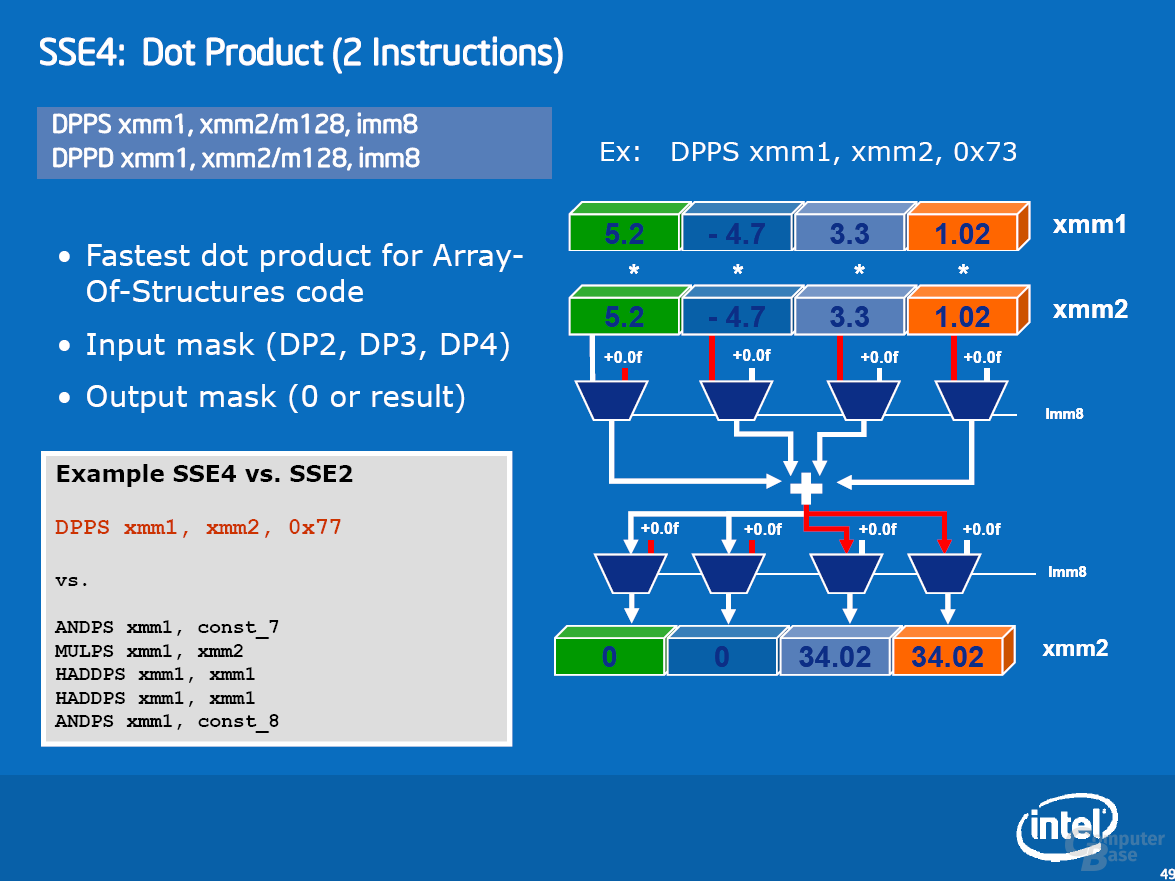
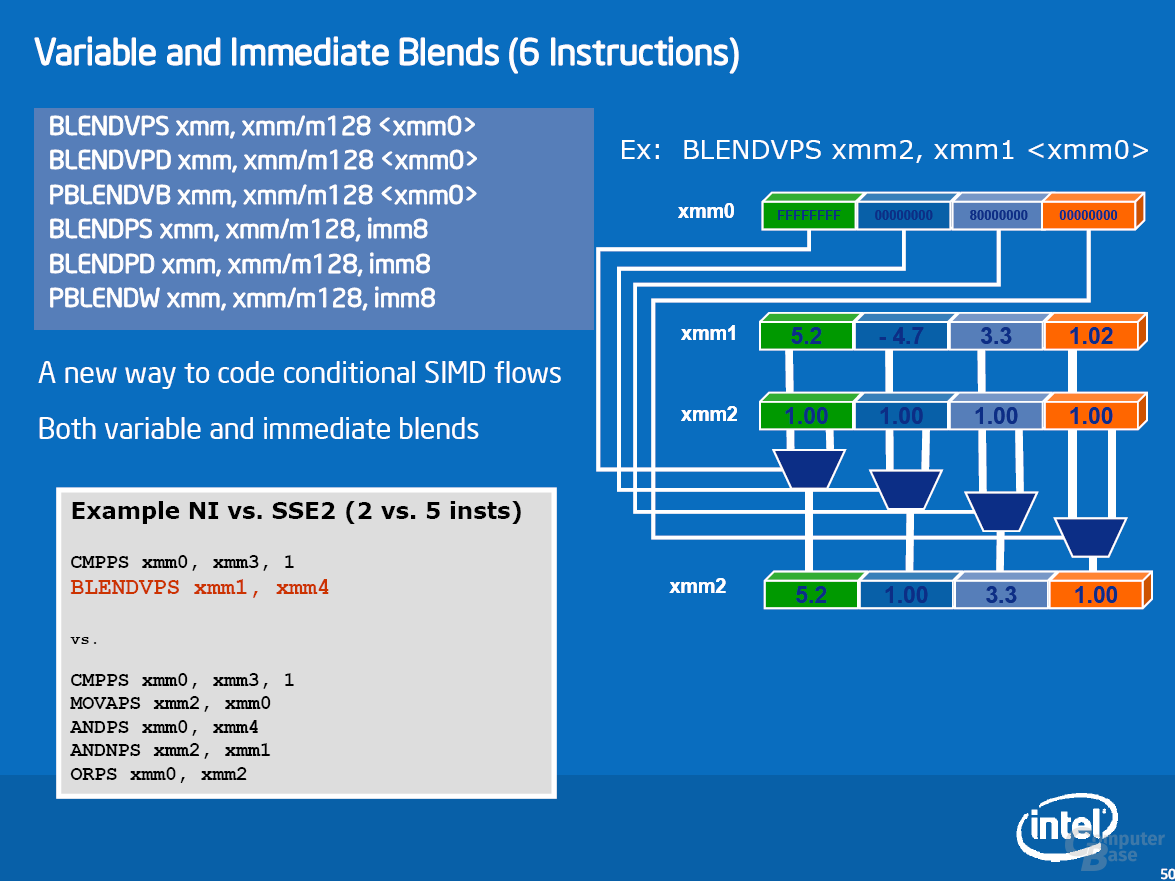
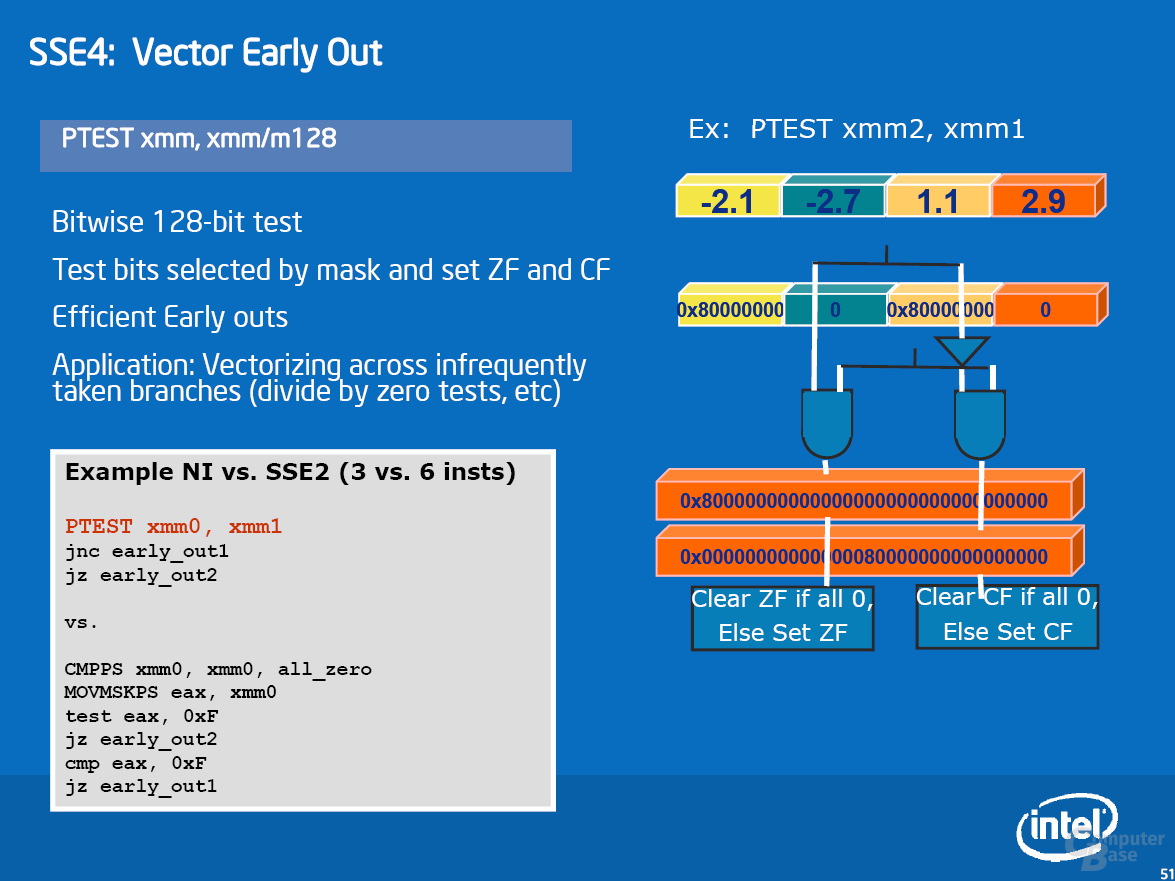
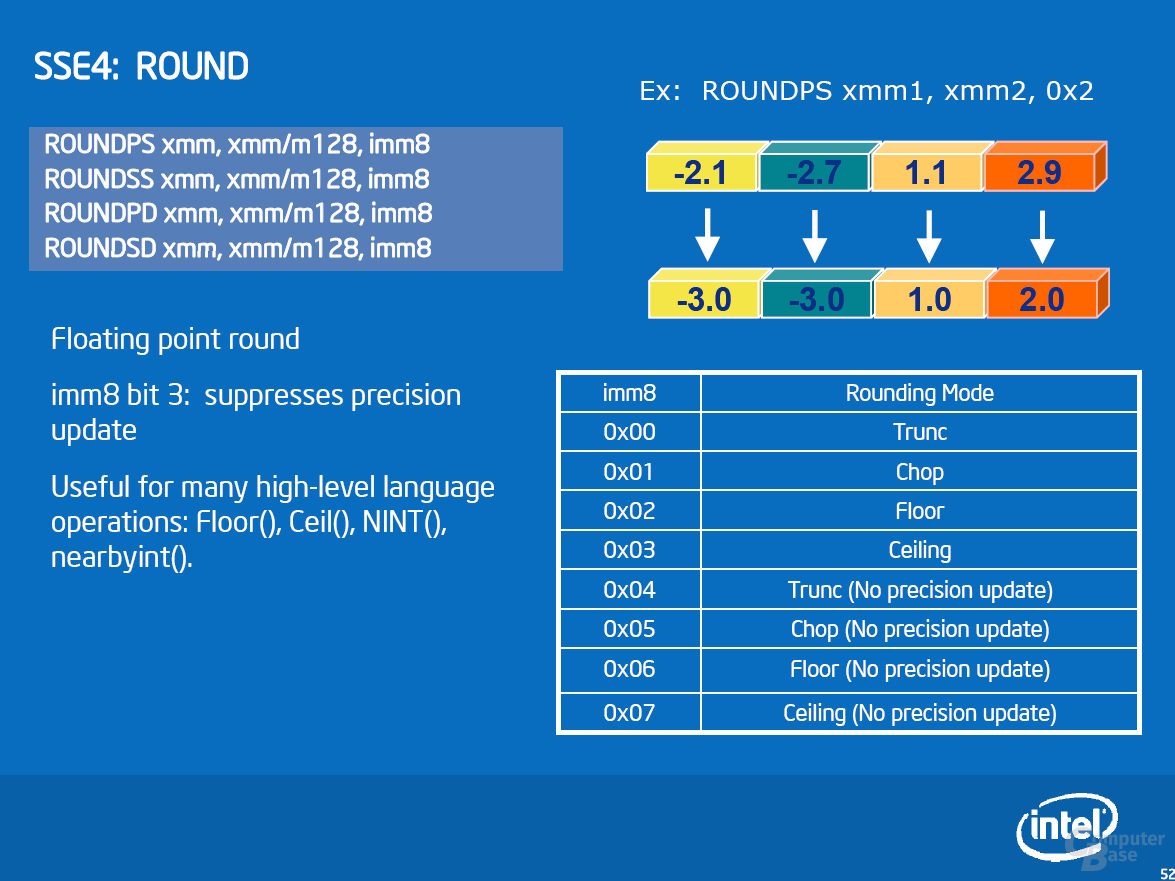
Als erste Applikation unterstützt DivX seit Version 6.6.1 die neuen Befehle. Je nach Einstellung sehen Intels Messungen einen Geschwindigkeitsvorteil von bis zu 63 Prozent. Unsere Ergebnisse in diesem Bereich sehen wir später. Weitere SSE4-Anwendungen sind bereits am Horizont: das Anfang November erwartete TMPGenc Xpress 4.4 wird sie unterstützen und soll ein Performanceplus von 40 Prozent erfahren. Für Adobe Premiere CS3 ist ein Patch in der Entwicklung, das Ende 2007 erscheinen soll und ein Speedup von bis zu 38 Prozent bewirkt. Auch Adobe Photoshop CS3 soll mit einem Update für die neuen Befehle gerüstet werden. Dieses erscheint voraussichtlich jedoch nicht im nächsten halben Jahr.
Out of Order Execution: Radix-16 Divider/Squareroot und Super Shuffle Engine
Bei Penryn hat Intel die Divisionseinheit gravierend beschleunigt. Während bisher ein Algorithmus genutzt wurde, der 2 Bits pro Arbeitsschritt betrachtet (Radix-4), wird man zukünftig mit Radix-16 gleich 4 Bits pro Takt verarbeiten. Diese Technik wird nicht nur sowohl bei Gleitkomma- (Floating-Point) als auch Integer-Operationen genutzt, sondern beschleunigt auch das Berechnen von Quadratwurzeln. Verglichen mit dem Core 2 Duo soll das Ergebnis eine im Durchschnitt doppelt so schnelle Verarbeitung sein. Von der Radix-16-Einheit profitieren alle Befehle (z.B DIVF, SQRT) die Divisionen oder Wurzelberechnungen auf verschiedenen Bitbreiten durchführen.
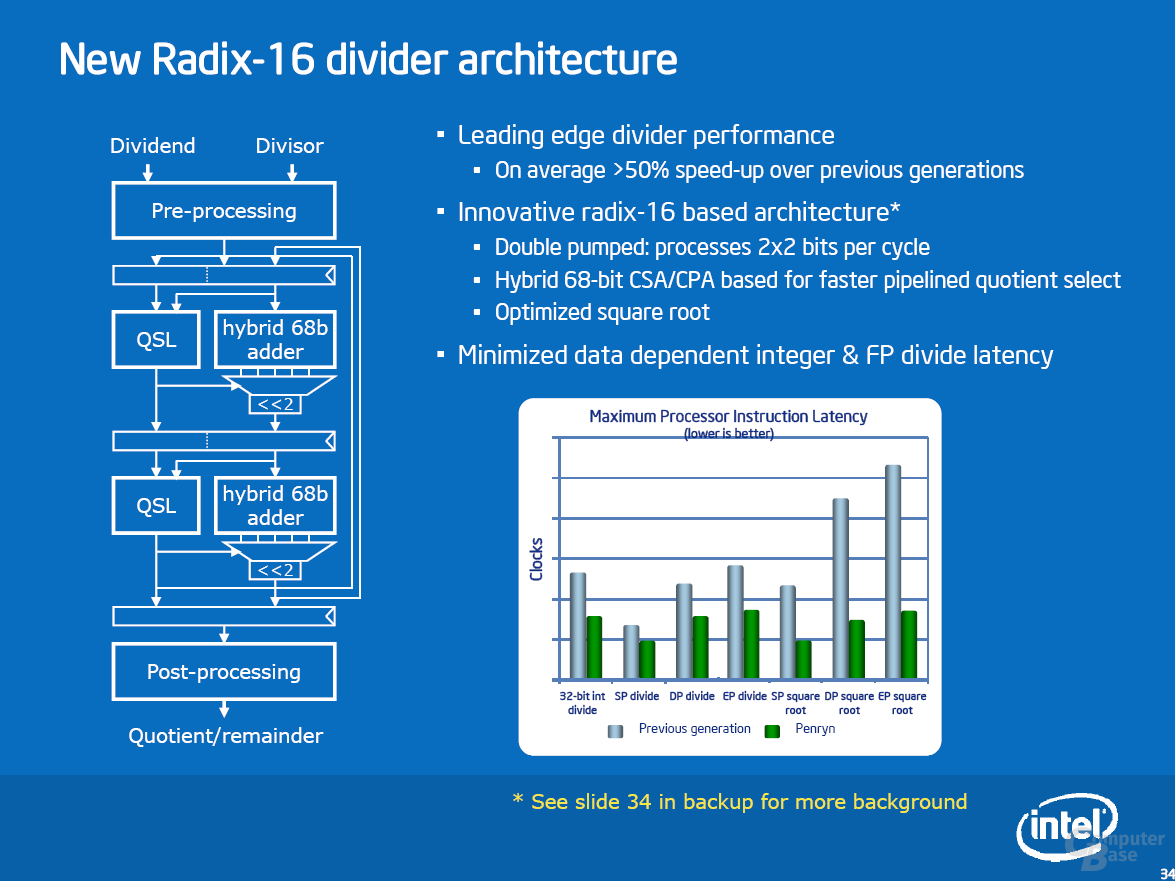

Wie das Blockdiagramm zeigt, hat Intel Radix-16 in Form von zwei Radix-4-Einheiten implementiert, die auf unterschiedlichen Taktflanken (Double Pumped) arbeiten. Für ein weiteres Verständnis der Radix-Problematik sei auf Computer Architecture: A Quantitative Approach (Hennessy, Patterson) oder z. B. IEEE 9040080 verwiesen.
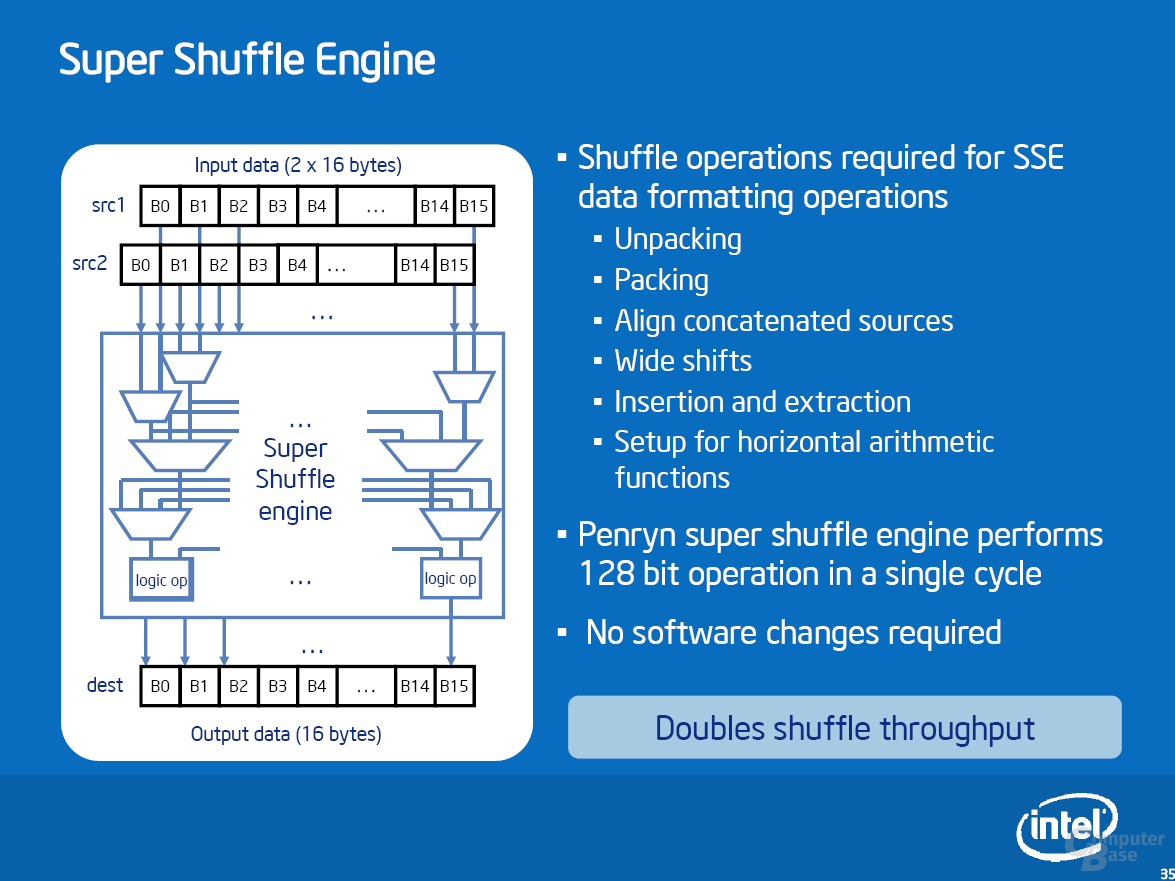
Mit der stetig wachsenden Anzahl an SSE-Befehlen (SIMD) hängt die Ausführungsgeschwindigkeit zunehmend davon ab, wie schnell die für SSE benötigten Datenvektoren aus 32- oder 64-Bit Paketen zusammengebaut oder die Ergebnisse nach ihrer Berechnung zerlegt und an die richtigen Stellen geschrieben werden können. Um diesen Prozess zu beschleunigen, hat Penryn die „Super Shuffle Engine“ die all diejenigen (bereits vorhandenen) SSE-Befehle beschleunigt, die für die Vorbereitung der Daten zuständig sind. Insbesondere die 32 SSSE3-Befehle (TNI), die mit Merom vorgestellt wurden, sollen von der neuen Einheit stark profitieren.
Cache/Speicher: Store Forwarding Misaligned Store und Sonstiges
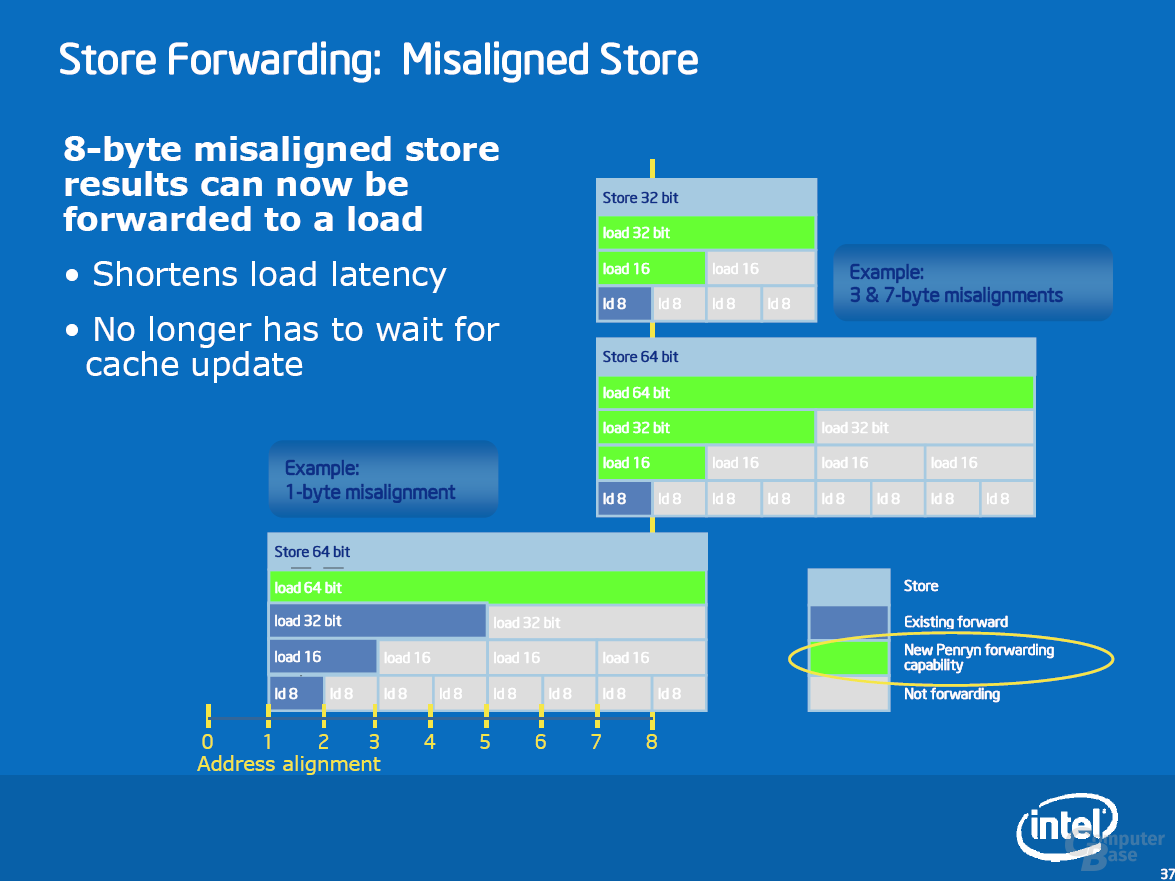
Der Memory Order Buffer (MOB) kann Store Operationen an nicht ausgerichtete Adressen nun besser verwalten. Im Programmablauf kommt es sehr häufig vor, dass an eine Adresse im Speicher zuerst Daten geschrieben und kurze Zeit später erneut gelesen werden. Da Speicherzugriffe mit einer hohen Latenz verbunden sind und die Speicherbandbreite ebenfalls begrenzt ist, wird versucht, unnötige Zugriffe zu vermeiden. Im Idealfall reicht ein Store-Befehl sein Ergebnis direkt an einen später auf die selbe Adresse stattfinden Load weiter. Dieser Prozess wird als Store-Forwarding bezeichnet und vom MOB durchgeführt. Im Vergleich zu Merom kann der MOB diesen Vorgang nun auch bei unglücklich platzierten Operationen häufiger durchführen, was der effektiven Bandbreite zu Gute kommt.
Penryn besitzt pro Dual-Core einen gemeinsam nutzbaren und 6 MB großen L2-Cache (Quad-Core besteht aus zwei Dual-Core-Chips). Während die Assoziativität von Merom (Anzahl der Stellen, an denen ein Element mit einer bestimmten Adresse im Cache abgelegt werden kann) beim 4 MB-Modell noch 16-Way betrug, kann der in 45 nm gefertigte Enkel mit 24 Ways aufwarten. Dies verringert die Wahrscheinlichkeit von Datenkonflikten.
Ursprünglich waren für Penryn außerdem „Split Load Cache Enhancements“ geplant, mit Hilfe derer zwei unabhängige Zugriffe auf den Cache möglich gewesen wären. Das ist immer dann von Vorteil, wenn auf Daten (L1-Data-Cache) zugegriffen wird, die nicht korrekt an Adressen ausgerichtet sind. Überlappt ein Dateneintrag (kleiner 128 Bit) zwei Cache-Lines, so sind hierfür aktuell zwei getrennte Zugriffe nötig. Penryn hätte einen 128-Bit-Zugriff aufteilen – wahrscheinlich in zwei 64-Bit-Zugriffe – und so bei „glücklich unausgerichteten“ Daten in einem Takt den kompletten Informationssatz in die Arbeitsregister laden können. In den jüngsten Präsentationen ist von diesem Feature nicht mehr die Rede. Eine Stellungnahme der Pressestelle steht noch aus.
Power Management: Deep Power Down (C6)
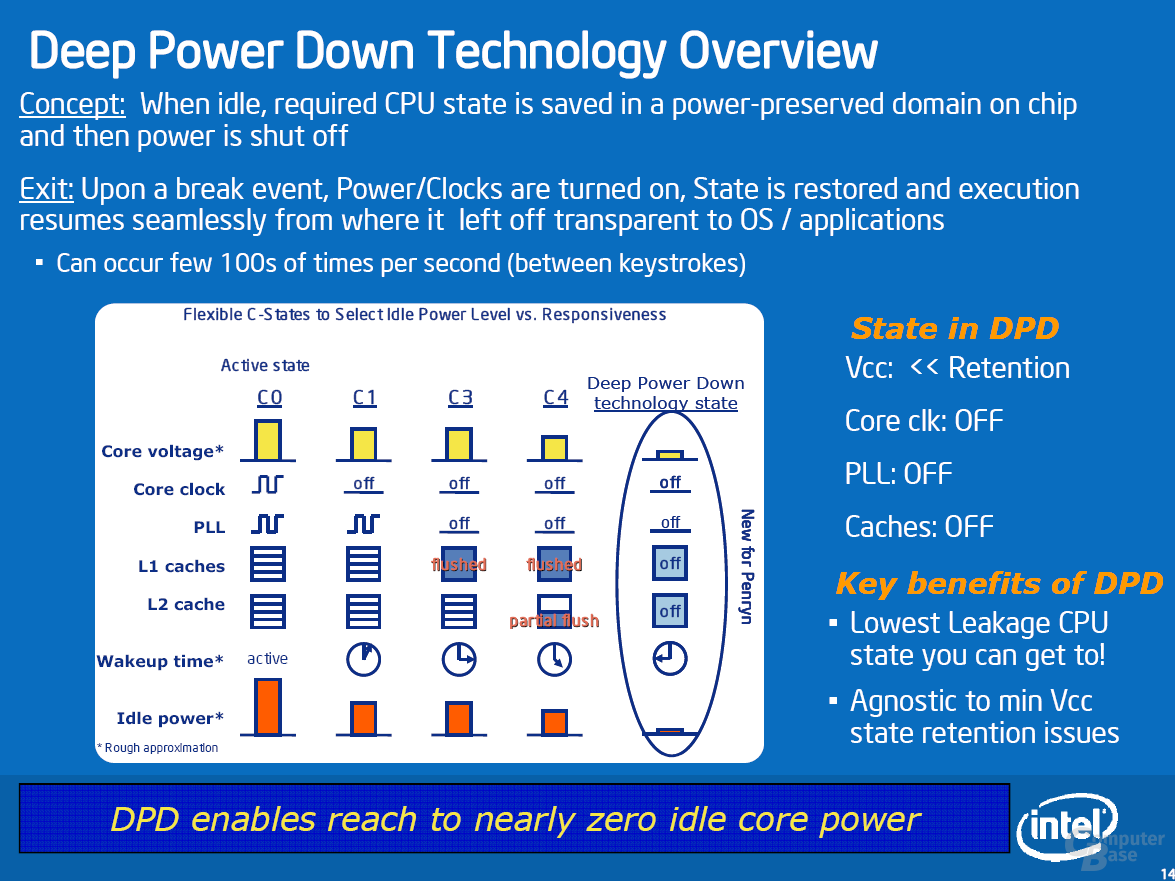
Speziell für die kommenden Notebook-Prozessoren der Penryn-Generation hat Intel zwei Innovationen in der Hinterhand. Die neue Deep Power Down Technology (C6) schaltet im Idle-Zustand nahezu den kompletten Prozessor ab hilft somit erheblich Strom zu sparen. Es wird ein Chipsatz vorausgesetzt, der C6 unterstützt. Sowohl Santa Rosa (GM/PM965) als auch die 2008 erscheinende Montevina-Plattform sind hierfür vorbereitet.
-
 Penryn-Architektur
Penryn-Architektur

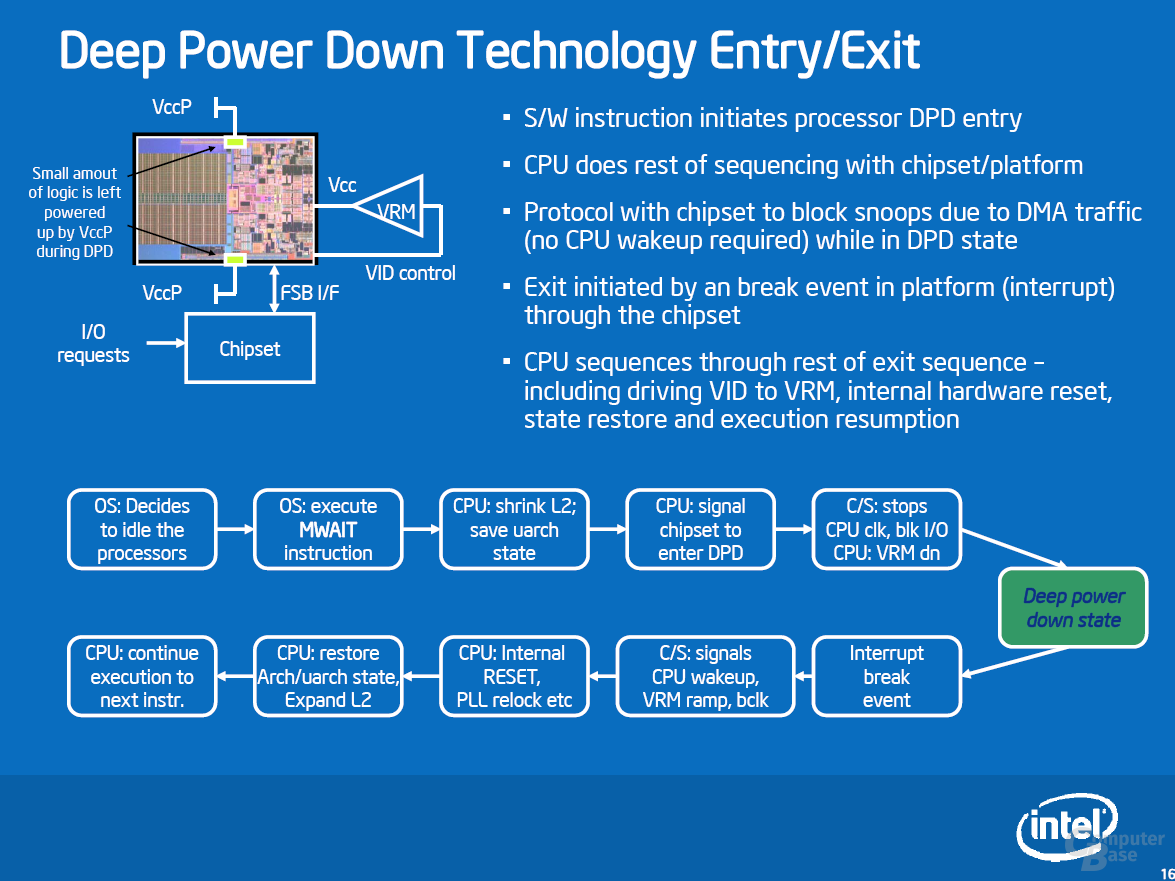
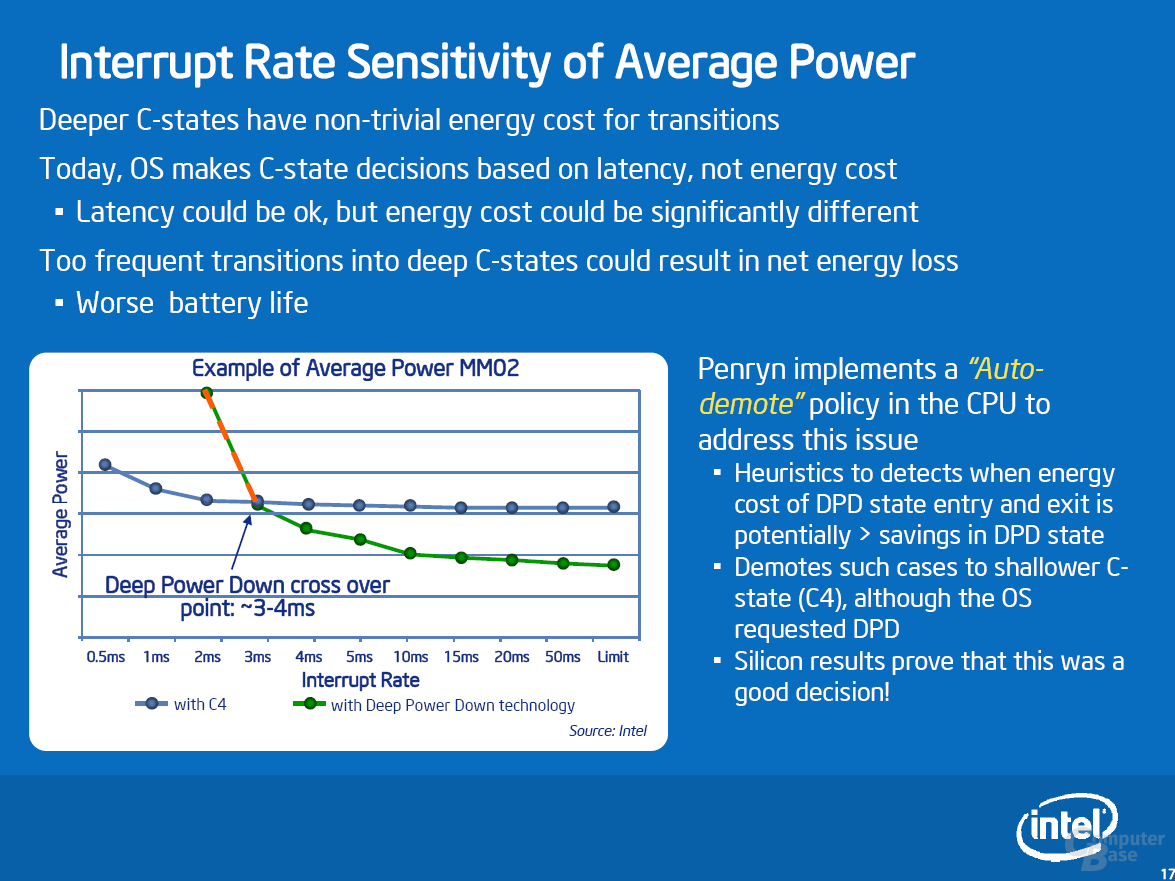
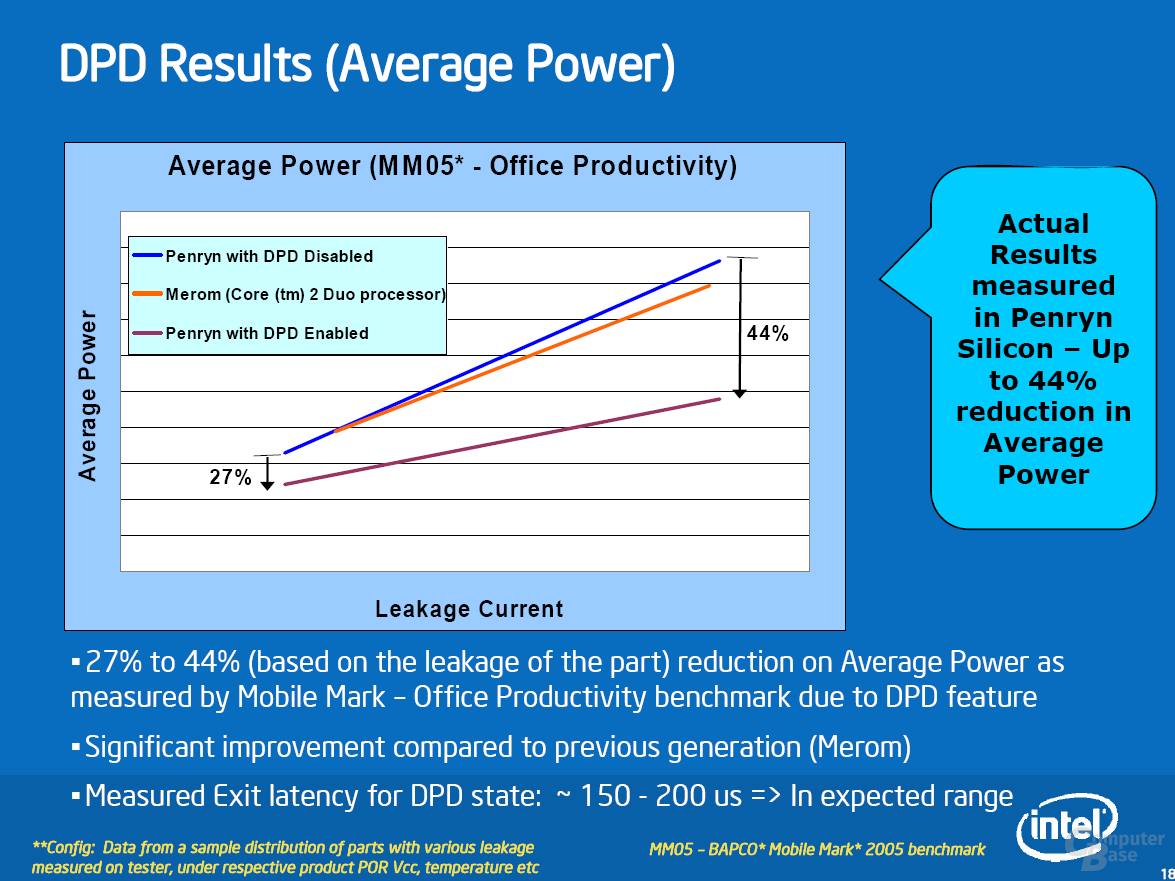
Deep Power Down (DPD) funktioniert folgendermaßen: Ist der Rechner unbelastet (Idle), führen heutige Betriebssysteme den mwait-Befehl aus. Dieser Befehl zusammen mit einem Paramater sagt dem Prozessor, welchen Stromsparzustand er bis zum nächsten Interrupt (dem Signal zum Aufwachen) einnehmen soll. Lautet der Parameter C6, beginnt eine längere Ereigniskette (siehe Bild), an dessen Ende der Prozessor seinen aktuellen Zustand in einem 8 kB großen SRAM-Speicher sichert. Die Spannung kann nun zu allen Bereichen bis auf die Mini-Speicher abgeschaltet werden. Die Restspannung beträgt Laut Intel 0,3 Volt und der Prozessor verbraucht nur noch 100 mW. Die Rückkehr in den aktiven C0-State (Prozessor rechnet) kommt einem Reset gleich. Im Vergleich zum Warmstart werden jedoch die Informationen aus den 8 kB SRAMs zurückgespielt.
Aufgrund der langwierigen Prozedur und der Spannungsanpassung macht C6 nur Sinn, wenn der Prozessor mindestens 4-5 ms schlafen kann, bevor er vom Chipsatz aufgeweckt wird (z.B. Timer-Interrupt, Keyboard-Interrupt etc.). Bei geöffneten Windows Media Player erhöht Windows automatisch die Interrupt-Refrequenz von 16 auf eine 1 ms. Damit C6 in diesem Fall nicht zum Nachteil wird (das Betriebssystem kennt C6 nicht explizit), wurde ein Gedächtnis implementiert. Hat sich C6 die letzten Male nicht gelohnt, tritt Auto-demote in Kraft und die Anforderung des Betriebssystems wird beispielsweise mit C4 überschreiben.
Power Management: Enhanced Dynamic Acceleration Technology (EDAT)
Die „Dynamic Acceleration Technology“ (DAT) (erstmals bei der Santa-Rosa-Plattform und Merom-Prozessoren dabei) wird Penryn in einer erweiterten Variante unterstützen. Zur Erklärung: DAT ist eine Technologie, bei der ein Prozessorkern eines Dual-Core-Chips automatisch mit dem nächst höheren Multiplikator betrieben wird, sofern der andere in einem Stromsparzustand (z. B. CC3) ist. Als Neuerung kann EDAT nun auch dann aktiv sein, wenn kurzzeitig beide Prozessoren aktiv sind. Eine Logik entscheidet abhängig von den vergangenen Aktivitäten des Idle-Kerns, wie zu verfahren ist. Diese Hysterese sorgt für eine Performance-Steigerung von bis zu 7 Prozent.

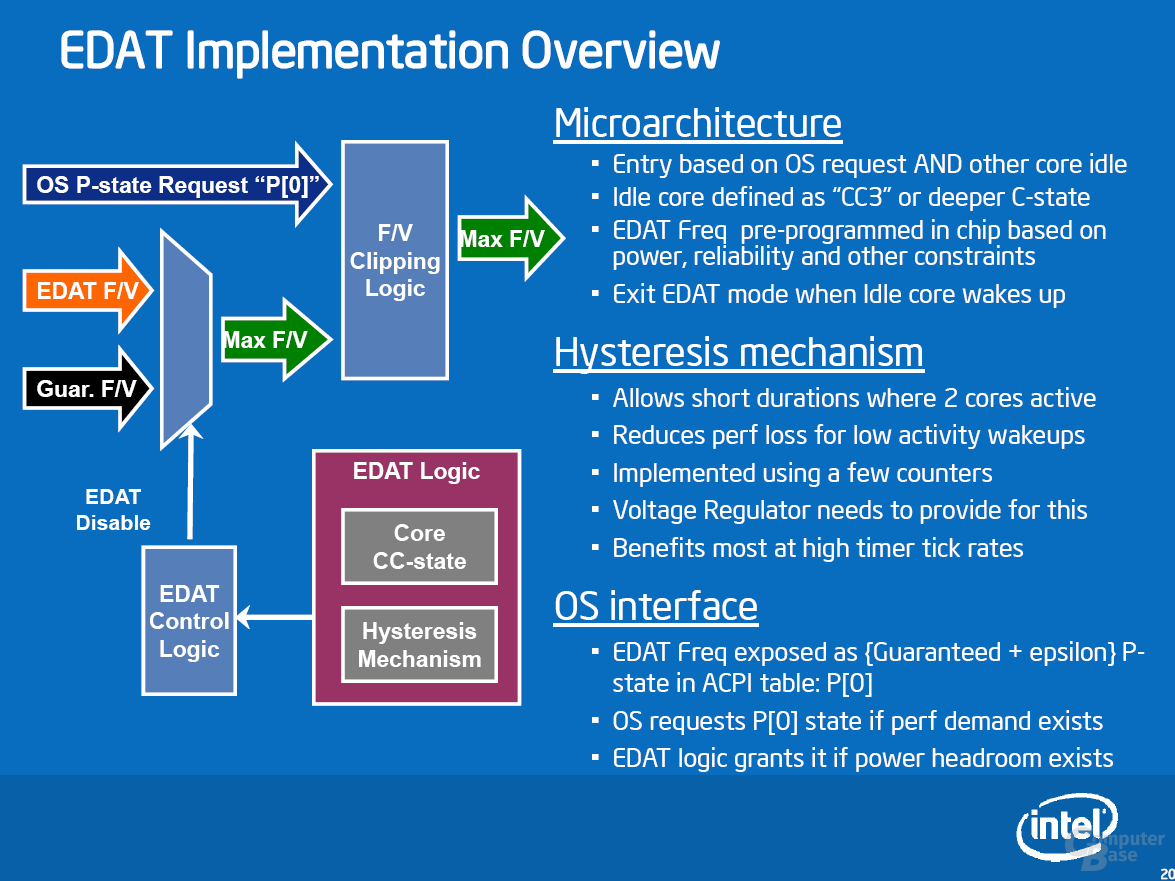
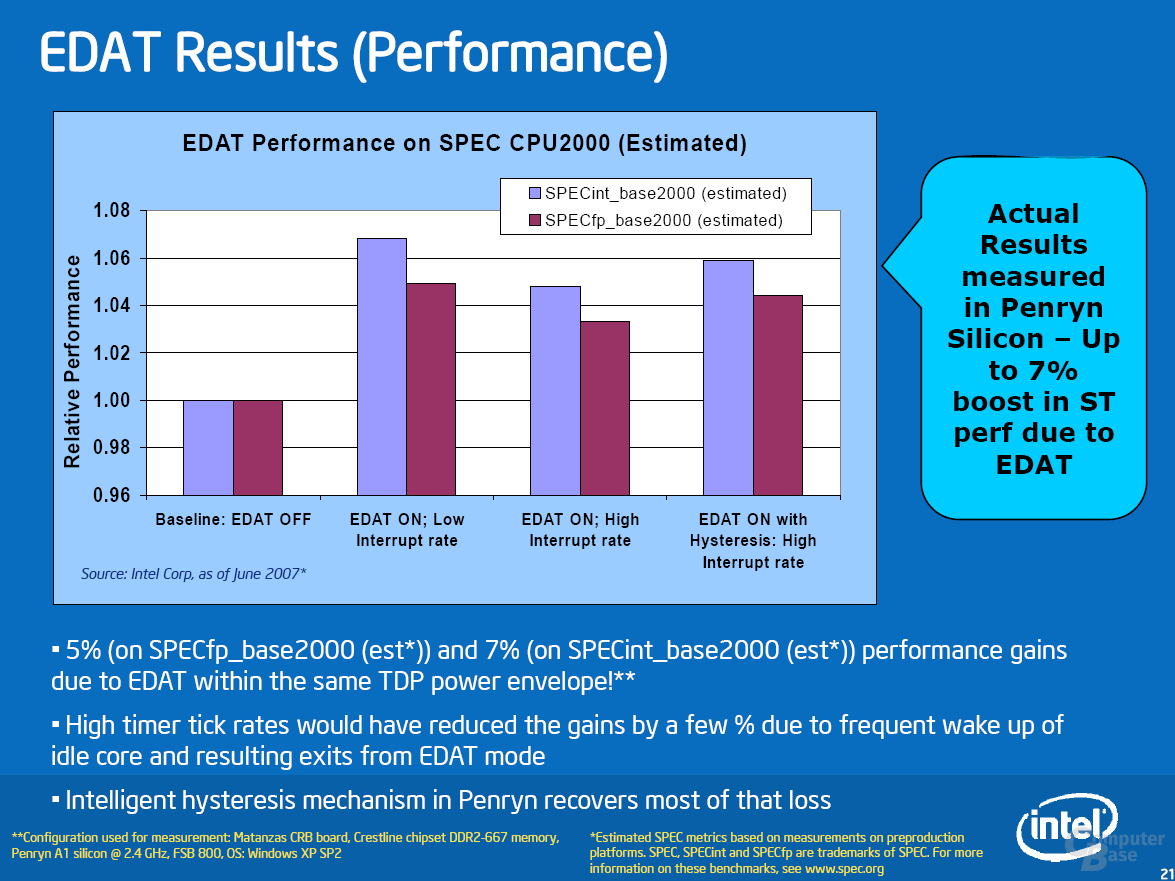
Das Feature wird weiterhin exklusiv für die Notebook-Prozessoren bleiben. Die Taktfrequenz bei diesen Prozessoren wird nicht danach gewählt, was technisch möglich, sondern was von der Thermal Design Power (TDP), also dem Stromverbrauch, vorgesehen ist. Dadurch besitzen Mobile-Chips einen gewissen Taktspielraum, der bei Desktop-Prozessoren von vornherein ausgenutzt wird.
Power Management: Core C3 (CC3) und weitere Detailverbesserungen
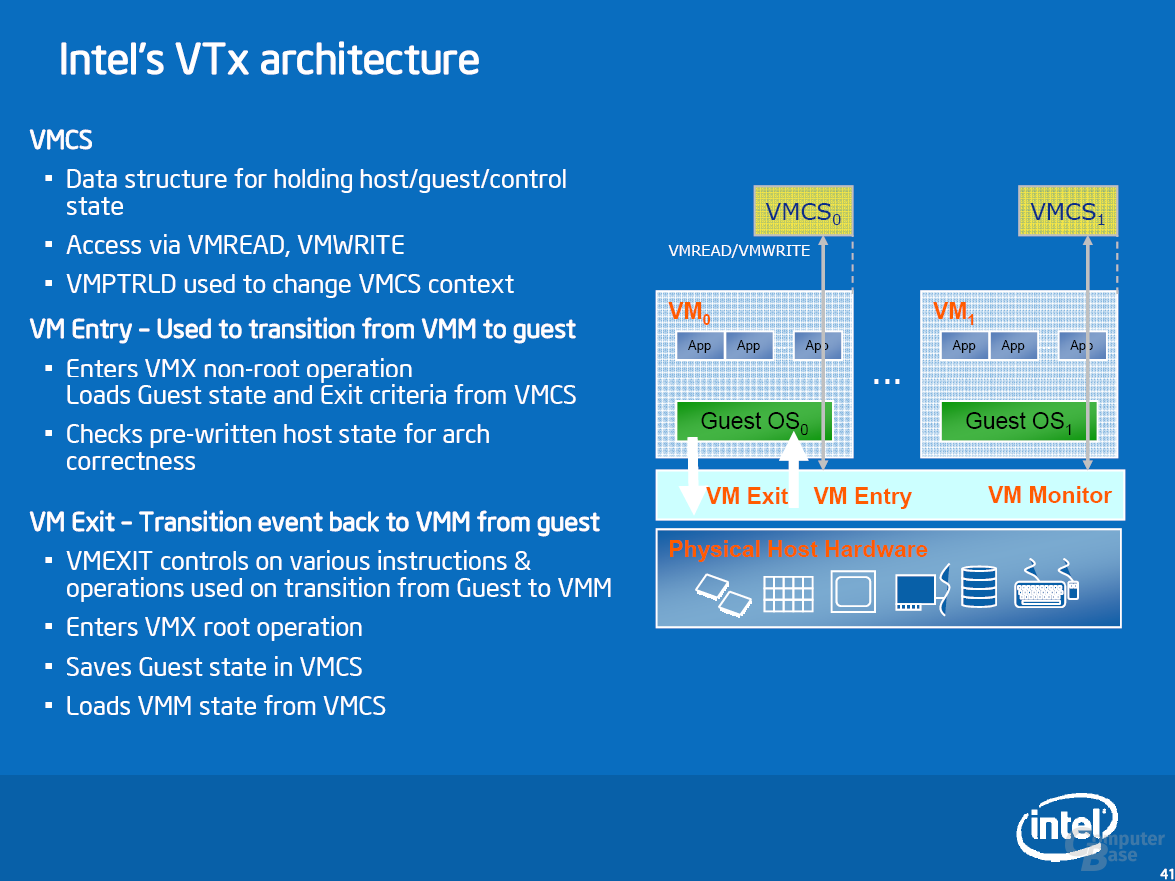
Für Server von Bedeutung, jedoch bei allen Produkten verfügbar, soll Penryn auch bei Virtuellen Maschinen punkten. Mit Hilfe von „VMCS state management caching“ können Befehle zum Betreten und Verlassen einer Virtuellen Maschine (VMentry, VMexit) wesentlich schneller ausgeführt werden, da Sicherheitsanfragen ggf. aus dem State Cache abgefragt werden können. Der Prozess-Wechsel (Task Switch) bei virtuellen Maschinen soll um 25 bis 75 Prozent schneller durchgeführt werden können.
Der zunehmenden Anzahl an Ereignissen und Geräten trägt Intel mit zwei Detailverbesserungen Rechnung: das Maskieren von Interrupts über die Befehle CLI (Clear Interrupts) und TSI (Transparent System Interrupt) erfolgt nun doppelt so schnell. Die bei Datenbank-Servern häufig benutzte Zeitabfrage mitteils RDTSC (Read Time Stamp Counter) wurde um den gleichen Faktor beschleunigt.


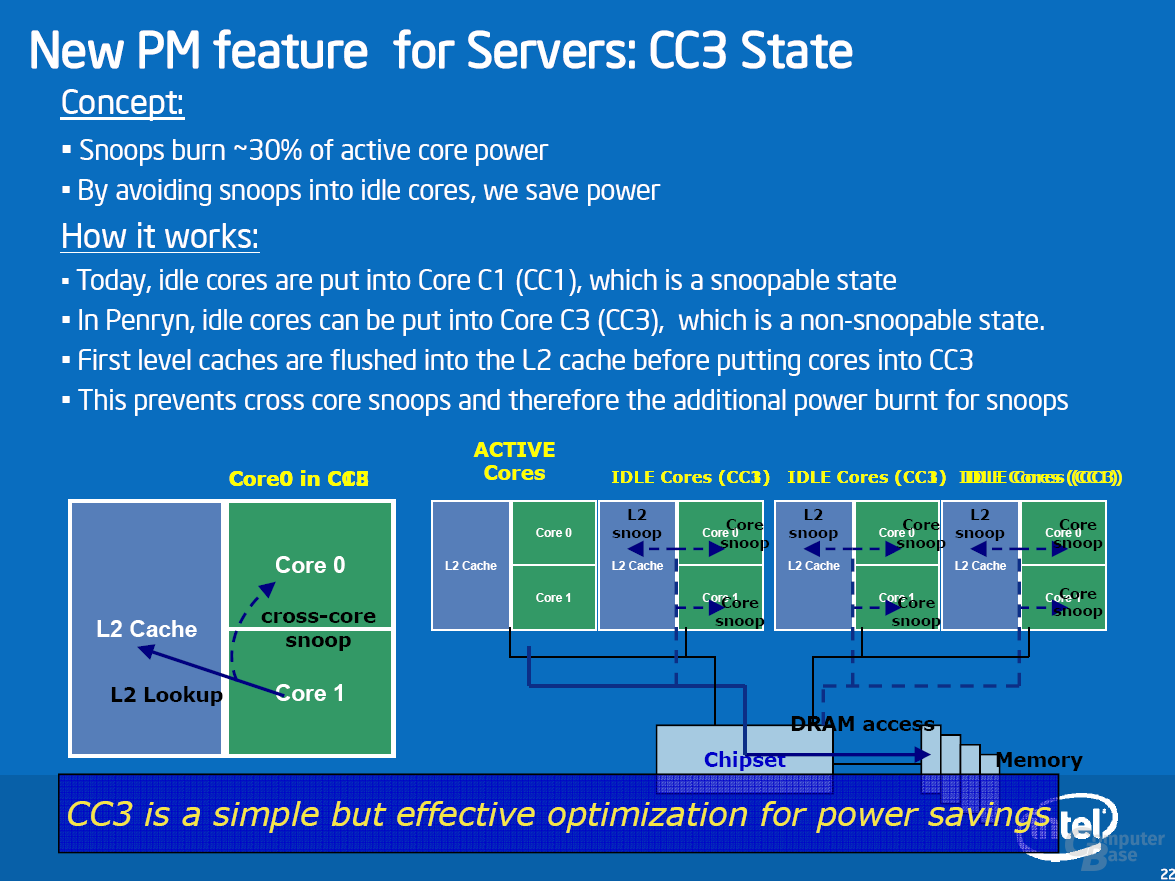

Exklusiv für Wolfdale-DP, Harpertown und Dunnington besitzt die Penryn-Architektur einen Core-C3-Zustand. Bisher unterstützen die Desktop- und Server-Prozessoren die Betriebsmodi C0 (Active), C1/C1E (Halt State, Enhanced Halt State) und C2 (Stop Grant, selten genutzt, da vom Chipsatz anzuordnen), während die Mobil-Prozessoren auf Merom-Basis darüber hinaus C3 (Deep Sleep) und C4 (Deeper Sleep) bieten.
Das Problem bei Servern: Es muss Datenkohärenz sichergestellt werden. Dies erreicht man durch Snooping (Schnüffeln). Hierbei lauschen alle Kerne auf den Speicherbussen und greifen ein, sofern in ihrem Cache ein Datum liegt, das neuer als das im Speicher ist (bzw. als exklusiv markiert war, MESI-Protokoll). L1-Cache-Snooping kostet bei Idle-Prozessoren unnötig Strom und ist leicht zu vermeiden, wenn einzelne Kerne in den C3 (daher der Name CC3) wechseln. Im CC3-Zustand wird der L1-Cache geleert und abgeschaltet (Sleep-Transistor). Als Nebeneffekt wird L1-Cache-Snooping für diesen Kern unterbunden. Der Stromverbrauch lässt sich hiermit um bis zu 16 Prozent senken.