
Intel Sandy Bridge im Test: Fünf Modelle auf 54 Seiten untersucht
7/54„Front End“
Es gibt keinen modernen x86-Prozessor, der die komplexen CISC-Befehle variabler Länge direkt verarbeitet. So übersetzen sowohl AMD als auch Intel die eingehenden x86-Befehle in kleine, handliche Instruktionen, die das Prozessor-Back-End versteht. Diese Vorverarbeitung (Decodierung) erfolgt im Prozessor-Front-End, das die Mini-Instruktionen, so genannte Micro-Befehle (µOps), erzeugt. Die Hauptaufgabe und Herausforderung des „Front End“ ist es nun, stets genügend µOps an das „Back End“ zu liefern, damit dieses unentwegt beschäftigt ist. Genau dort hat Intel umfangreiche Optimierungen angesetzt, denn je reibungsloser und besser der Datenstrom funktioniert, desto effektiver und schneller wird ein Prozessor.
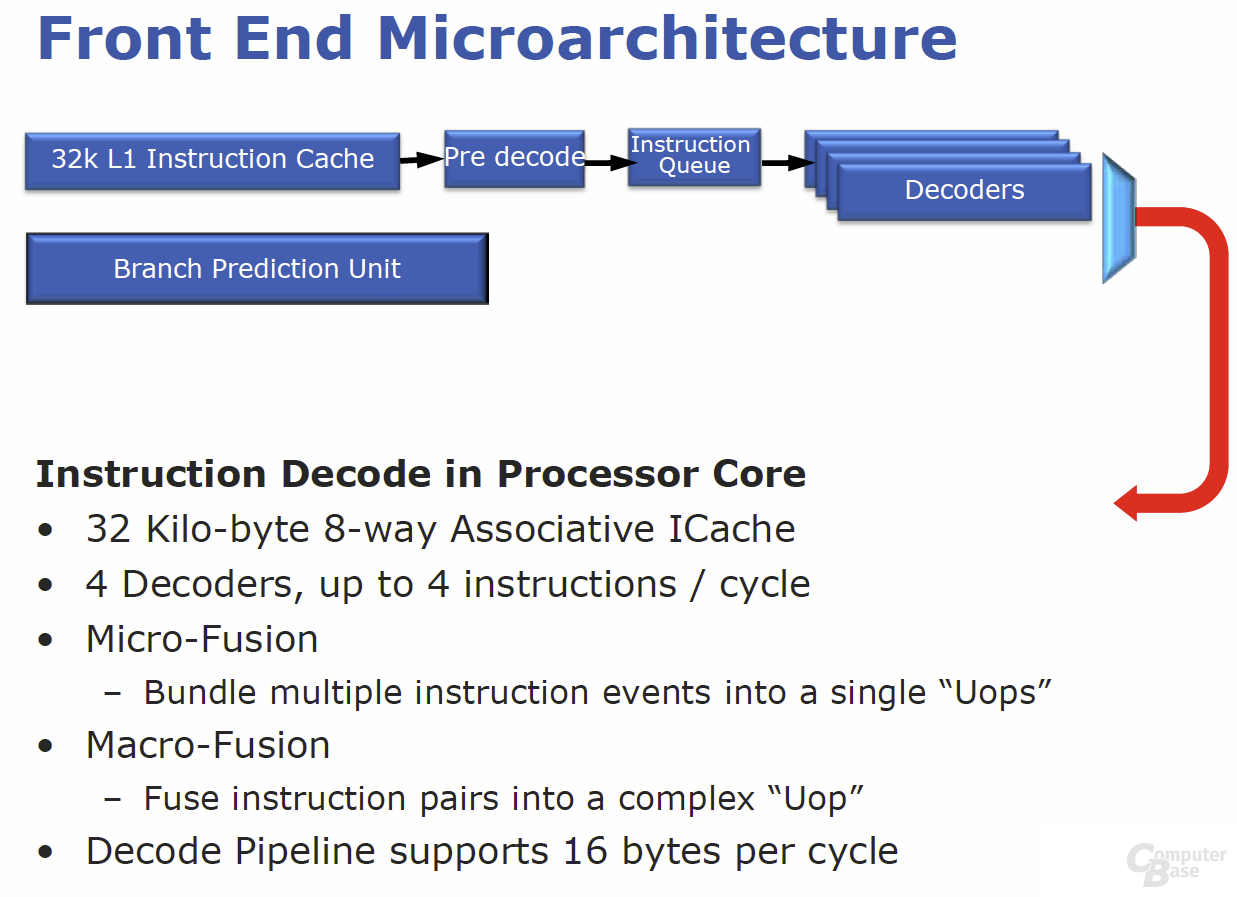
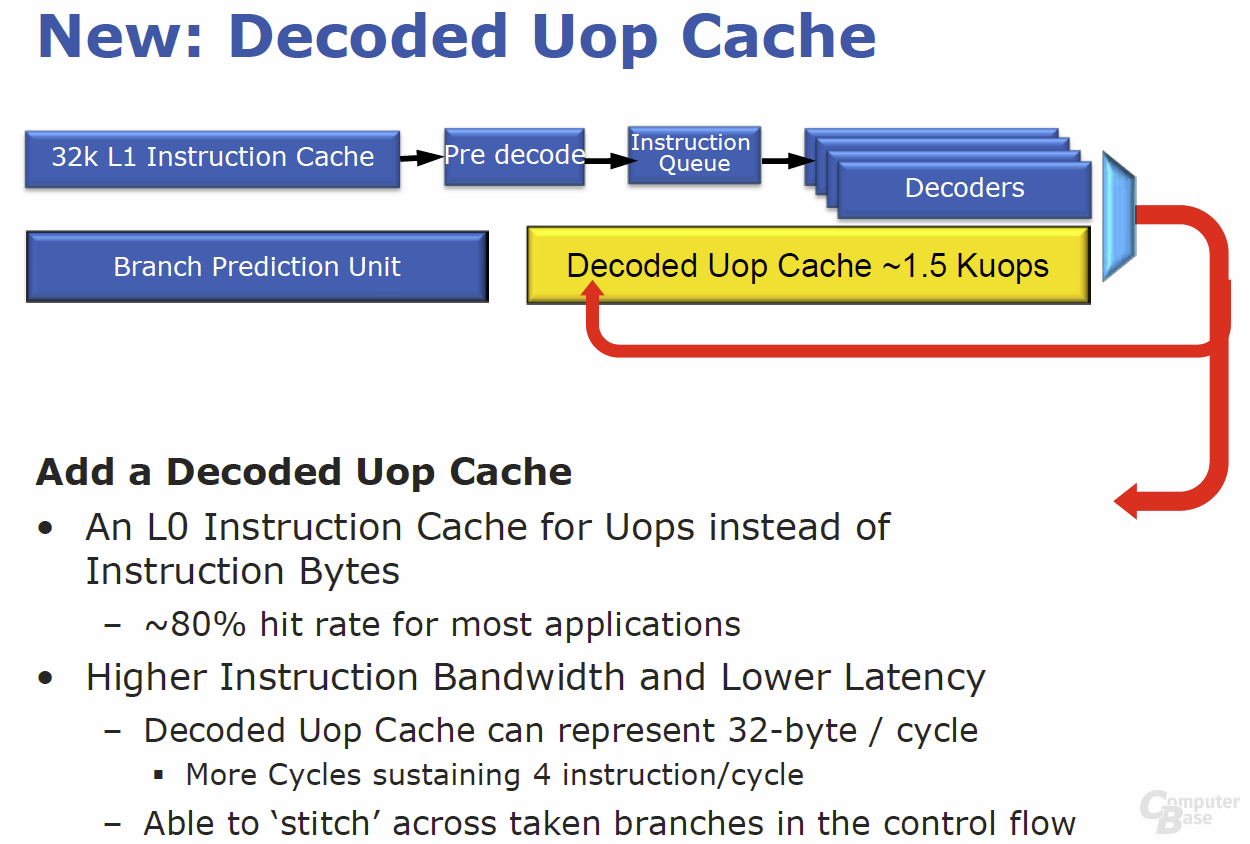
Bei „Sandy Bridge“ wird unter anderem ein µOp-Cache helfen, dieser Aufgabe besser gerecht zu werden. Der µOp-Cache ist ein Nachfolger des Trace-Cache aus Pentium-4-Zeiten, unterscheidet sich aber hinsichtlich vieler Details und Optimierungen. Er funktioniert quasi als 6 KByte großer L0-Cache, der in den 32 KByte großen L1-Instruktion-Cache eingebettet ist. Ein neuer Befehl wird direkt nach der Initialisierung und damit vor dem vollständigen Decodieren mit dem µOp-Cache verglichen, der bis zu 1.500 Micro-Befehle enthalten kann. Werden Übereinstimmungen gefunden – laut Intel soll dies in 80 Prozent der Fälle gelten –, wird die gesamte verbleibende Dekodierstufe abgeschaltet und der Befehl wandert direkt in die nächste Sektion. Für die restlichen 20 Prozent der Befehle heißt es, weiterhin den klassischen Weg vom L1-Instruktion-Cache über die Decoder (3 × Simple, 1 × Complex, 1 × µCode-Sequenzer) zu gehen. Insgesamt soll sich mit dem Prozedere neben einer deutlichen Leistungssteigerung auch eine massive Energieersparnis erreichen lassen. Wie der µOp-Cache genau funktioniert und die Daten abgleicht, ist großes Betriebsgeheimnis und wurde von Intel im Rahmen von drei großen Briefings vorab nicht verraten.
Doch auch das wichtigste Element des „Front End“ wurde völlig überarbeitet: die Sprungvorhersage. Auch bietet sich für die Architekten großer Spielraum für Optimierungen, denn immer wenn ein Sprung (engl. Branch) falsch vorher gesagt wird, muss die gesamte Pipeline geleert werden. Dies reduziert nicht nur die Performance, auch bereits investierte Energie geht verloren. Im Wesentlichen basiert die Sprungvorhersage von „Sandy Bridge“ auf der des „Nehalem“, wurde jedoch deutlich verbessert. Beim Branch-Target-Buffer (BTB) werden unterschiedlich entfernte Sprungziele nun effizienter gespeichert, indem ferne Sprünge separat abgelegt werden – bisher konnte immer die maximal mögliche Sprungdistanz hinterlegt werden, was viele Ressourcen schlichtweg verschwendete. Mehr als doppelt zu viele Sprungziele sollen so ohne zusätzliche Hardware-Ressourcen gespeichert werden können. Die Branch-History-Table (BHT), die pro Adresse das vorherige Sprungverhalten protokolliert, wurde in der effektiven Größe erhöht, indem bestimmte Spünge nicht mehr abgespeichert werden.
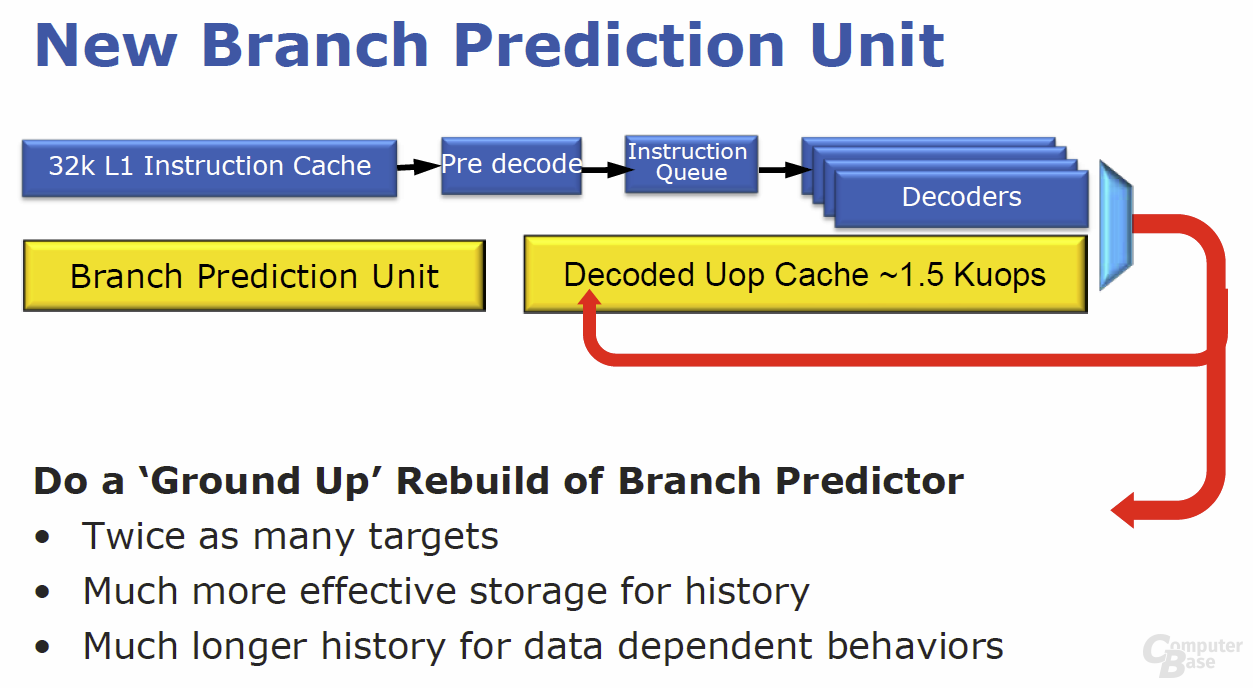
Der dadurch frei werdende Speicherplatz lässt sich direkt für weitere Sprünge nutzen und so soll die Effektivität der gesamten Sprungvorhersage deutlich ansteigen. Laut Intel erhöht sich durch das Gesamtpaket die Korrektheit der Sprungvorhersage gegenüber dem Vorgänger um mehr als fünf Prozent.
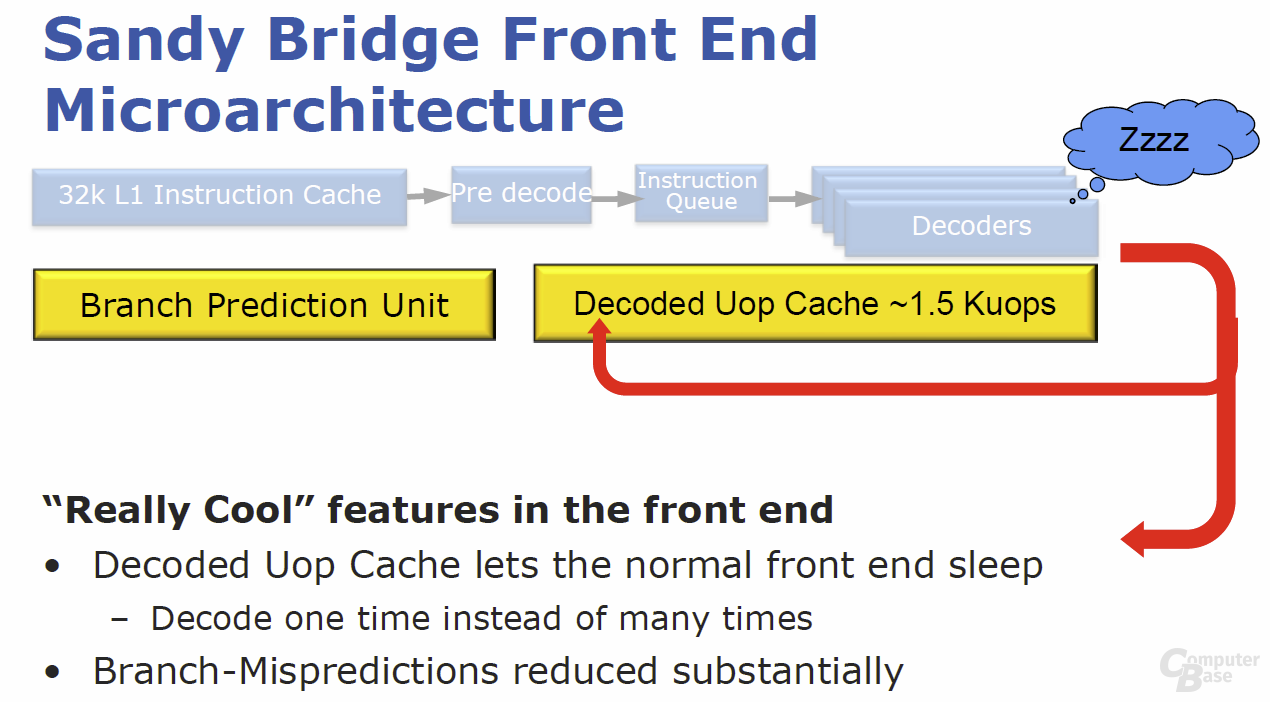
Die weiteren Bauteile des „Front End“ entsprechen im Wesentlichen dem der Vorgängergeneration „Nehalem“. Vier Decoder können bis zu vier Instruktionen pro Zyklus weiterleiten, denen der 32 KByte große L1-Instruktion-Cache mit achtfacher Assoziativität zur Seite steht.