Intel Sandy Bridge im Test: Fünf Modelle auf 54 Seiten untersucht
8/54„Back End“
Sind die Informationen erst einmal durch das „Front End“ gekommen, werden sie im „Back End“ weiterverarbeitet. Dabei kommt eine weitere wesentliche Neuerung der „Sandy Bridge“ zum Vorschein: die „Physical Register Files“. An deren Umsetzung hatte sich Intel bereits beim Pentium 4 versucht – man hat sich in den folgenden Generationen aber wieder für das klassische System entschieden.

Bisher hat jeder µOp (Micro-Befehl) eine Kopie seinesgleichen im Buffer (ROB) abgelegt. Dadurch wurden immer Speicherplatz und gleichzeitig auch Transferkapazität belegt, der mit der Einführung des Physical Register Files (PRF) anderweitig genutzt wird. Statt nun eine Kopie mitzuführen, wird der Micro-Befehl im PRF abgelegt und dort gezielt angesprochen. Um dies möglichst effektiv zu tun, stattet Intel die neuen Prozessoren mit zwei Physical Register Files (PRF) aus. Während sich der eine Teil mit bis zu 160 Integer-Operanden beschäftigen kann, können im zweiten PRF bis zu 144 Operanden für die Fließkommaberechnung (FP-PRF) aufgenommen werden. Dank AVX-Unterstützung, der wir uns auf der kommenden Seite widmen, können diese bis zu 256 Bit breit sein, was das FP-PRF jedoch auch ausladend und langsamer werden lässt. Um dem entgegen zu steuern, hat Intel die Buffer für Zwischenspeicherungen und letztendlich auch den „Re-Order Buffer“ (ROB) gegenüber dem Vorgänger teilweise massiv ausgebaut.

Drei der sechs Ports der „Execution Unit“ stehen mit jeweils drei Blöcken für Integer-, SIMD- und Gleitkomma-Operationen zur Verfügung. Genau in dem Bereich wird auch AVX eingreifen können und je nach Optimierungsgrad der Anwendung Performancegewinne herbeiführen. Die restlichen drei Ports der Ausführungseinheit gehen den direkten Weg zum „Memory Cluster“.
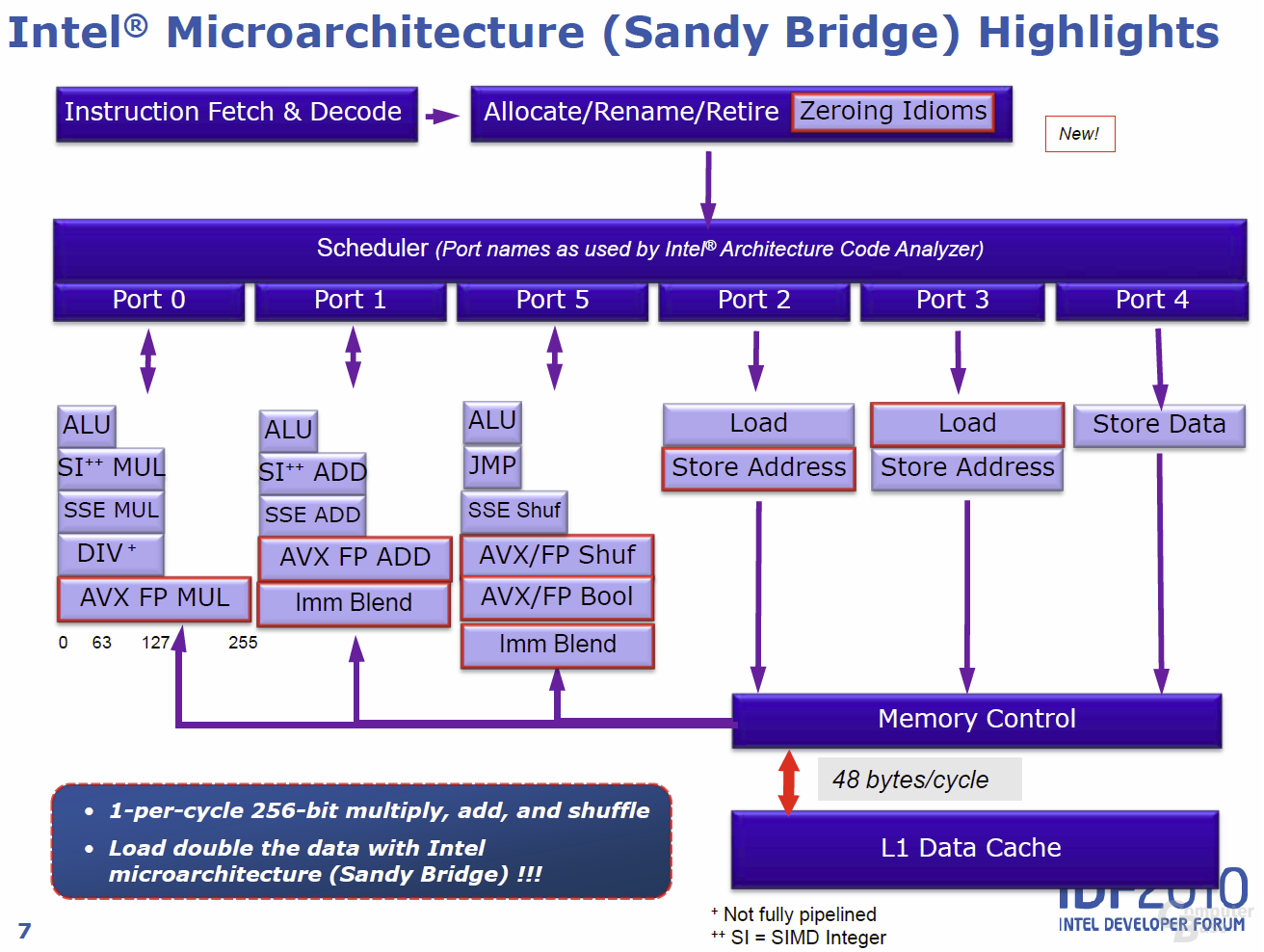
Das letzte Teil des „Back Ends“ ist der ebenfalls überarbeitete „Memory Cluster“. Wie der Vorgänger „Nehalem“ besitzt auch „Sandy Bridge“ drei Lade-/Speicher-Einheiten. Dieser konnte bisher 16 Byte große Operationen fürs Laden und weitere 16-Byte-Adressierungen fürs Speichern verarbeiten.
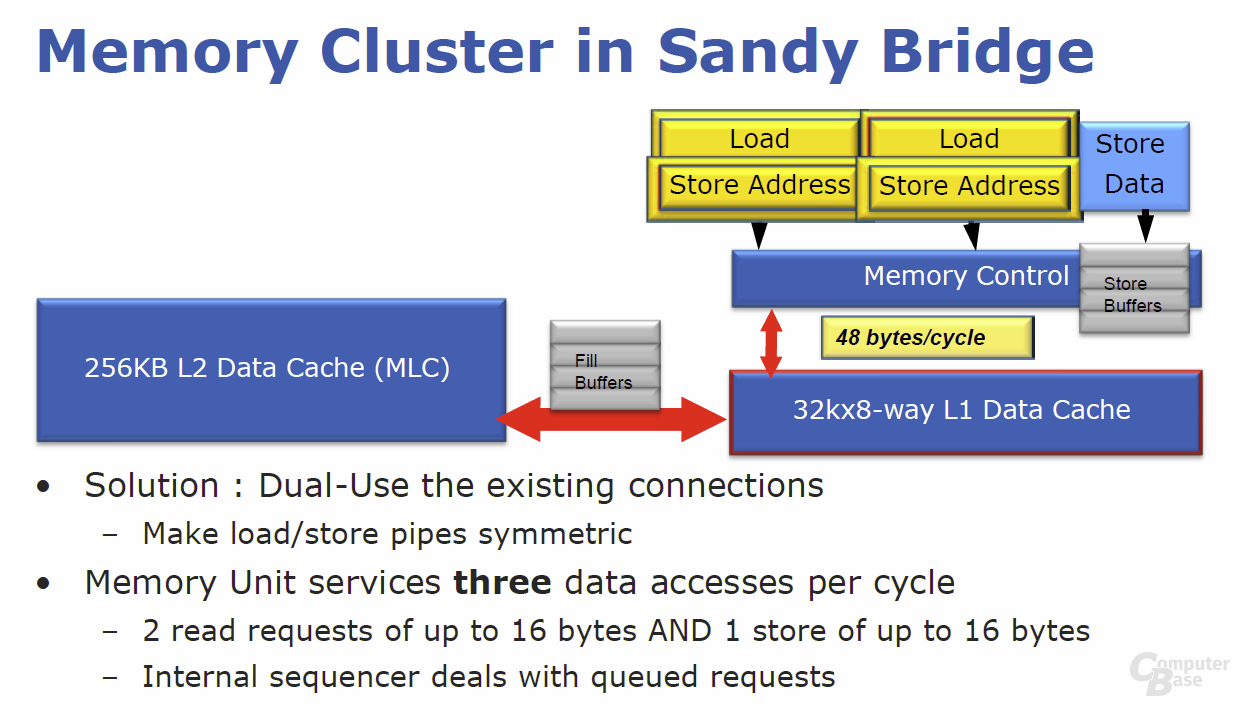
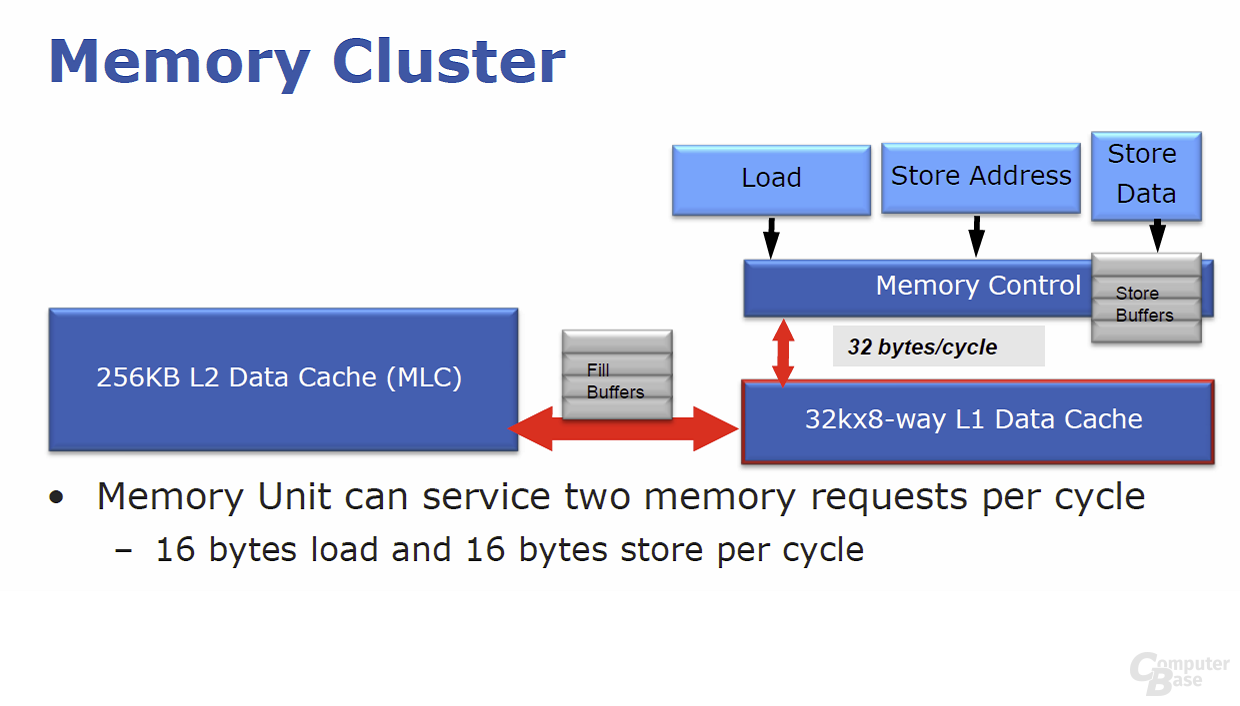
Bei „Sandy Bridge“ können die ersten dieser beiden Einheiten fortan sowohl Lade- als auch Speicheroperationen durchführen. Im Endeffekt können die drei Einheiten so gleichzeitig zwei Operationen lesen und eine weitere Operation schreiben, was die Bandbreite von 32 (2 × 16) auf 48 Bytes (3 × 16) pro Zyklus steigert.
Mit dem Memory Cluster ist unsere Detailbetrachtung der Neuerungen in der Architektur des reinen Prozessors abgeschlossen. Fasst man das zuvor Beschriebene zusammen, ergibt es das folgende Bild:
