Intel Sandy Bridge im Test: Fünf Modelle auf 54 Seiten untersucht
9/54Advanced Vector Extensions (AVX)
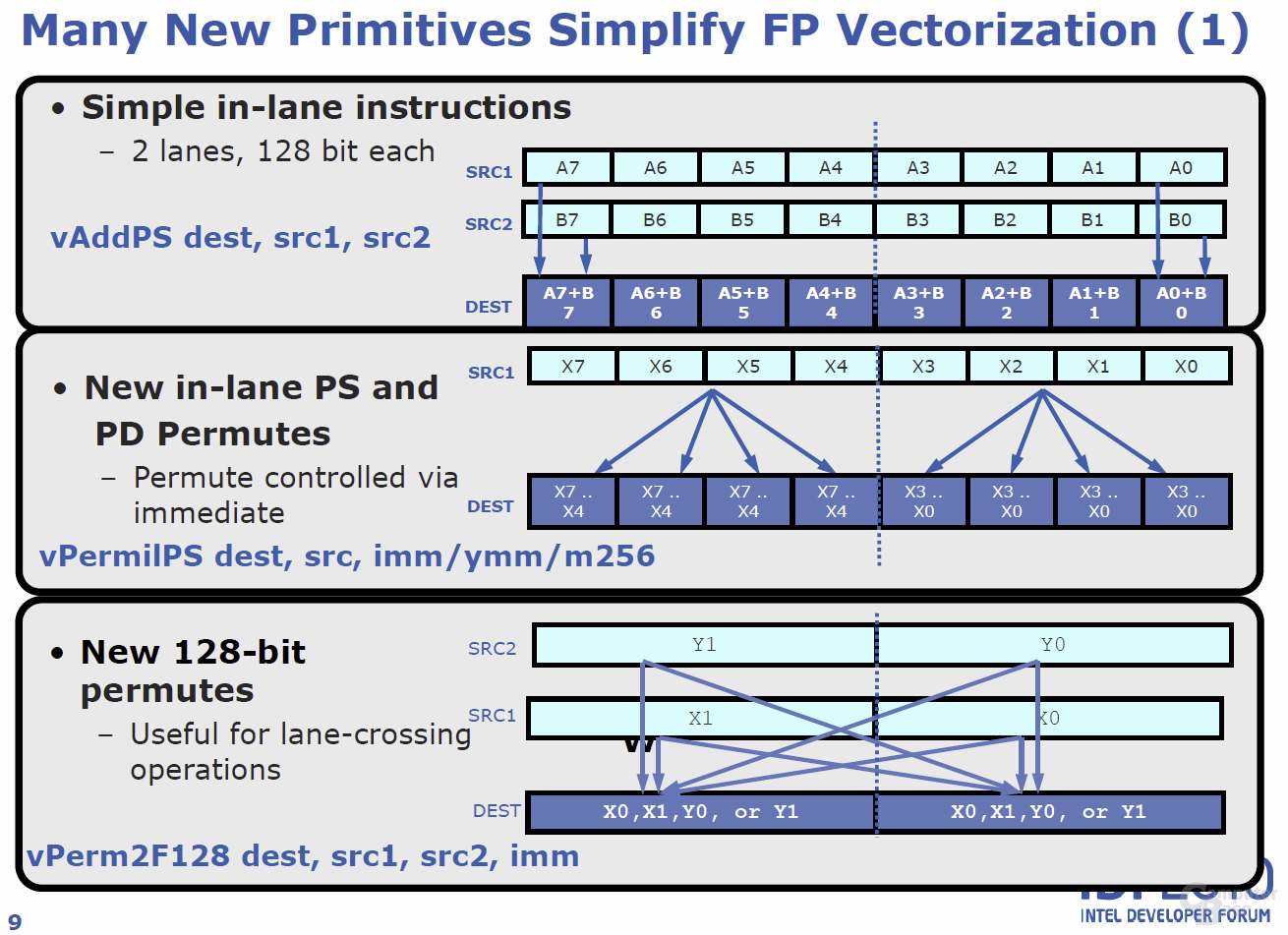
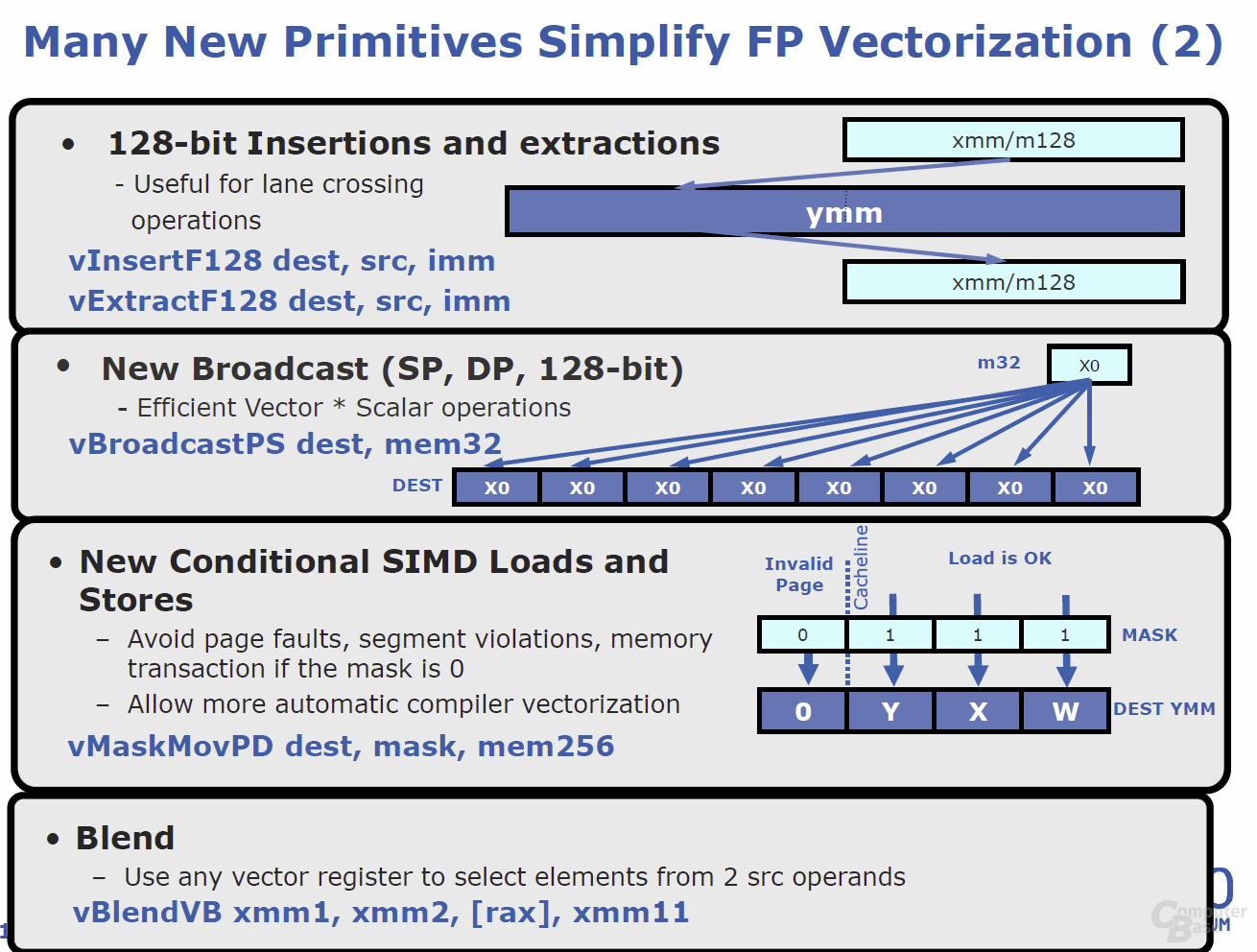
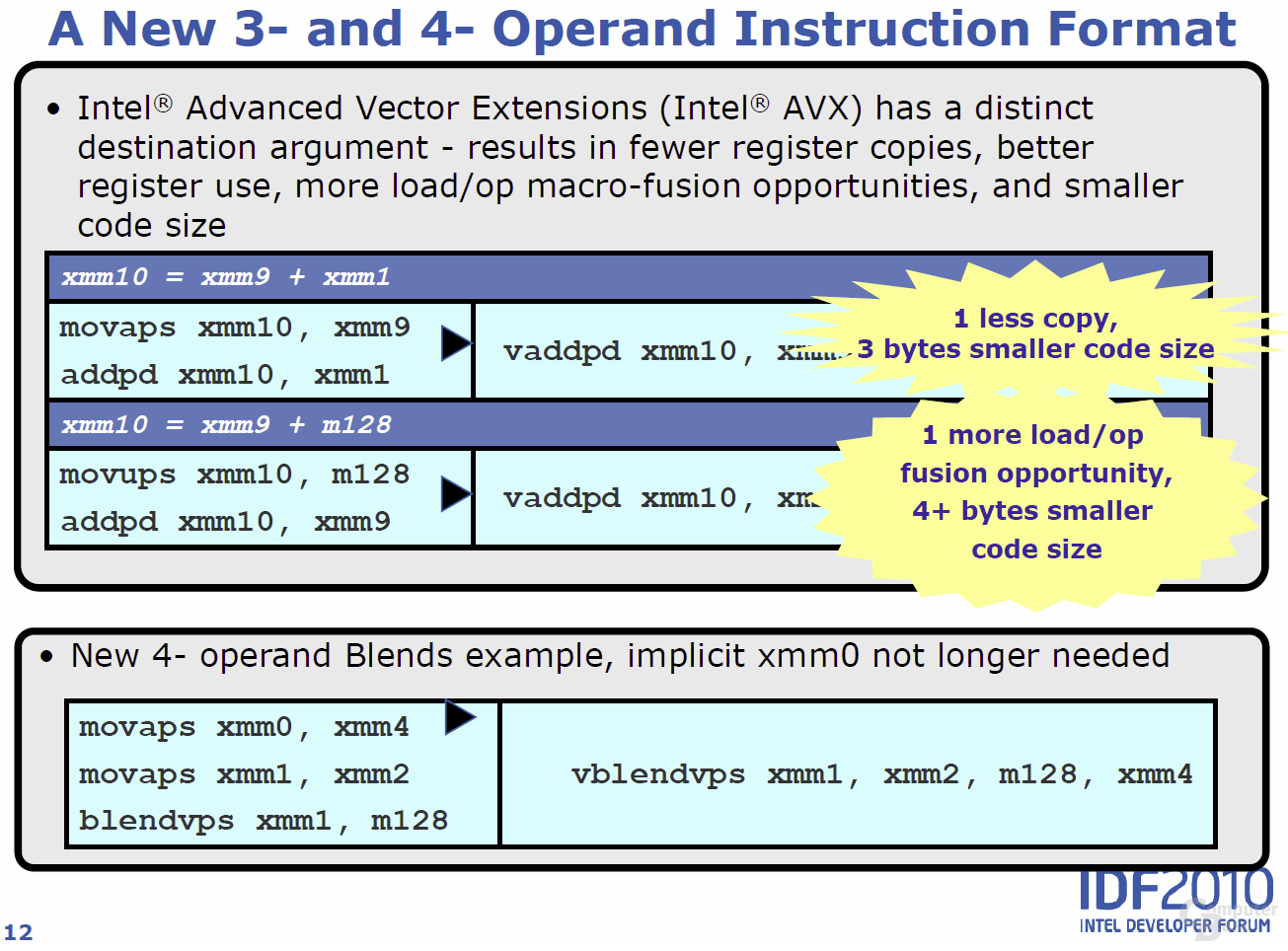
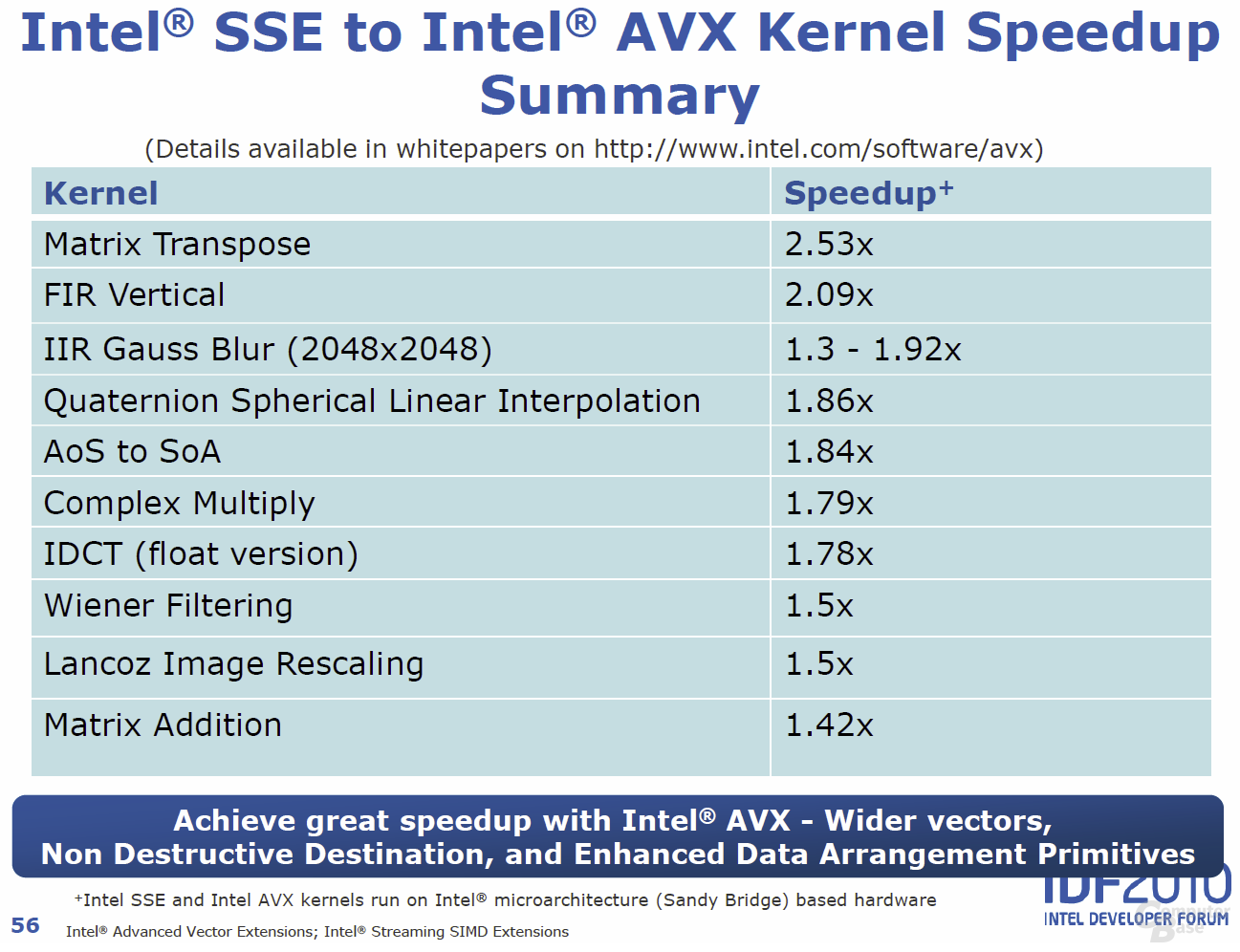
Die Advanced Vector Extensions (AVX) – also ein neuer Satz an Instruktionen – sind eine der wichtigsten Neuheiten, die fortan von allen auf „Sandy Bridge“ basierenden Produkten unterstützt werden. AVX geht dabei den Weg weiter, den Intel mit SSE vor Jahren eingeschlagen hat: Software kann speziell auf die Nutzung der neuen Instruktionen optimiert werden, so dass am Ende in der Realität laut Intel Performancegewinne von bis zu 30 Prozent möglich sein sollen. In der Theorie ergibt sich durch die Verdoppelung der Vektorgröße von 128 auf 256 Bit eine doppelte Rechenleistung. Schließlich können dank SIMD (Single Instruktion Multiple Data) nun statt vier 32-Bit-Operationen gleich derer acht (4× 32 Bit vs. 8x 32 Bit) verarbeitet werden.
-
 Advanced Vector Extensions
Advanced Vector Extensions


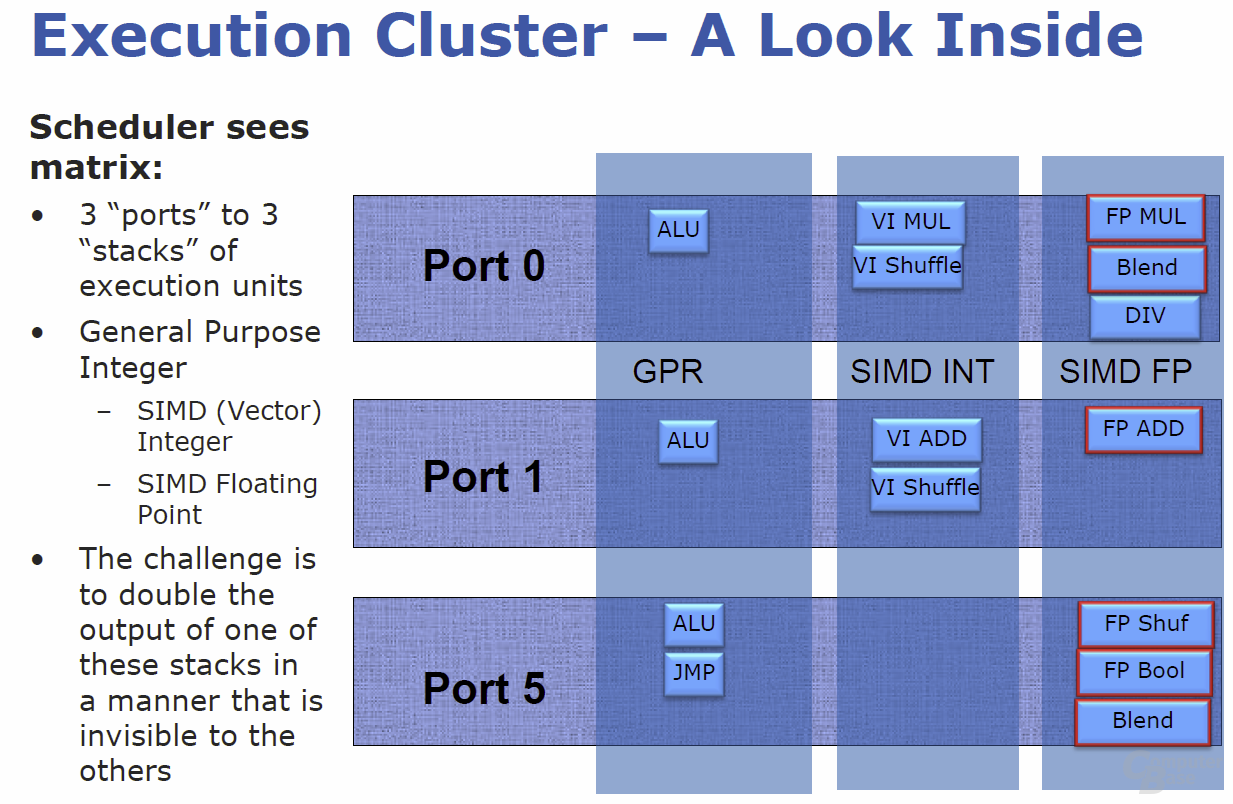
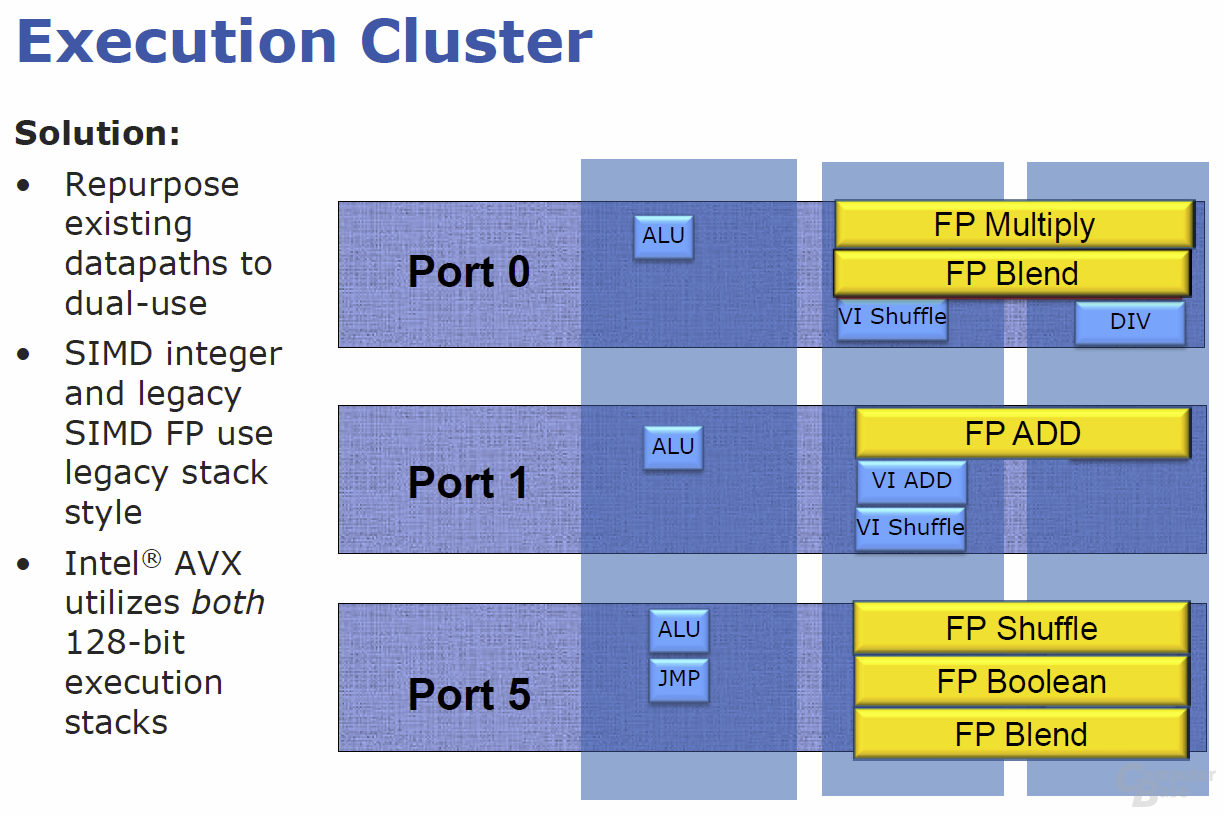
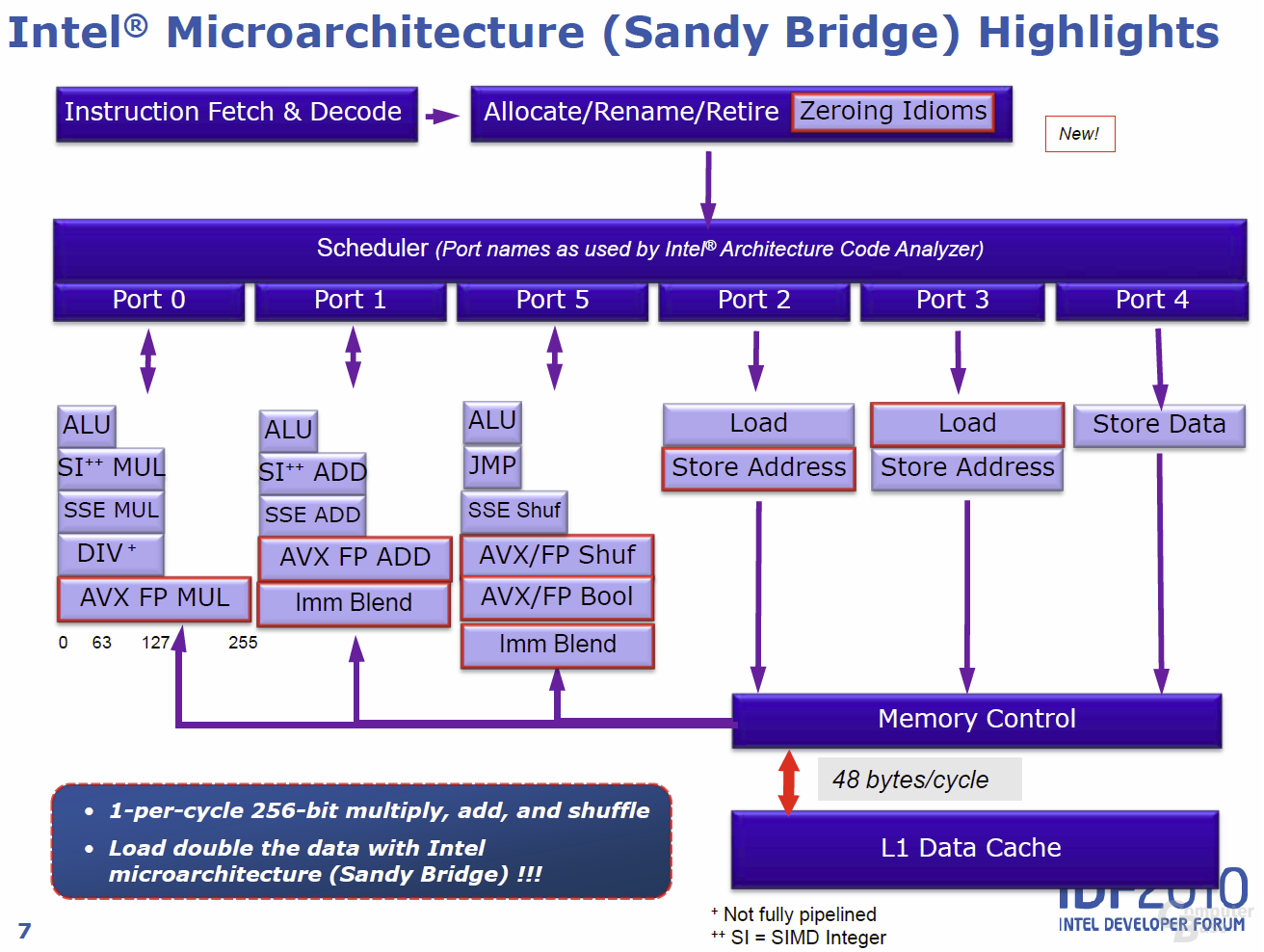



Die Ports 0, 1 und 5 der „Execution Unit“ bieten jeweils drei Ausführungsblöcke für Integer-, SIMD-Integer- und Gleitkomma-Operationen. Während „Nehalem“ jedem Block seine spezielle Aufgabe zuweist, wurden die Execution-Cluster in „Sandy Bridge“ so designt, dass die hinter einem Port liegenden Funktionseinheiten auch gemeinsam an einem AVX-Befehl arbeiten können. Statt zweier autark arbeitender Integer- und Float-Point-Multiplikationseinheiten gibt es in „Sandy Bridge“ nun zum Beispiel einen Funktionsblock (an Port 0), der bei Int und FP anpackt – dies bei Bedarf auch 256 Bit (AVX) breit. Damit ist es am Ende möglich, in einem Zyklus eine AVX-Multiplikation, eine AVX-Addition, einen AVX-Shuffle sowie eine AVX-Lade-Operation durchzuführen.
Bei „Sandy Bridge“ heißt es also: Je Funktionseinheit und Takt können wahlweise 1× 128 Bit (SEE) oder 1× 256 Bit (AVX) breite Befehle verarbeitet werden. Die erwartete Konkurrenz in Form von AMD ist hier geschickter:„Bulldozer“ spricht in einem Zyklus wahlweise volle 256 oder 2× 128 Bit pro Takt an – die Flex-FP genannte Einheit teilen sich jedoch zwei Cores innerhalb eines „Bulldozer“-Moduls.
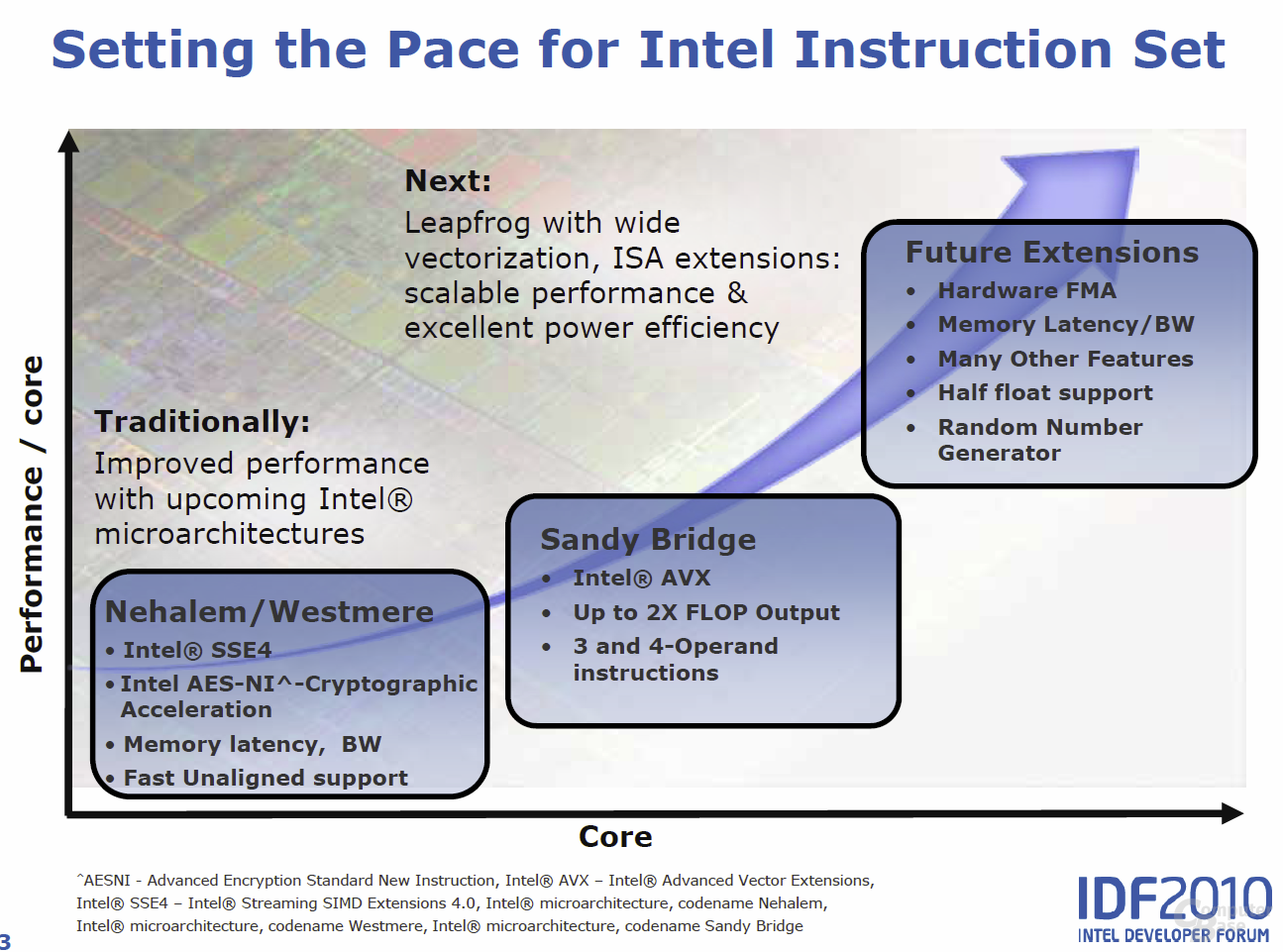
Eine echte „fehlende Option“ bei „Sandy Bridge“ in Bezug auf AVX wiegt da deshalb deutlich schwerer. Es geht um den „Fused Multiply Add“-Befehl (FMA), auf den „Sandy Bridge“ verzichten muss – den die Konkurrenz von AMD mit „Bulldozer“ aber wiederum anbieten wird. Der Vorteil einer FMA-Instruktion gegenüber einer herkömmlichen „Multiply Add“-Instruktion ist laut dem Bericht der Kollegen von HT4U, dass bei einer FMA erst am Ende der kompletten Berechnung (a*x + y) das Ergebnis gerundet wird, bei einer Multiply-Add-Instruktion hingegen bereits nach der Multiplikation und dann noch einmal nach der Addition. Außerdem werden zwei einzelne Rechenschritte auf einmal erledigt – ohne FMA sind zwei Befehle nötig, die darüber hinaus eine geringere Genauigkeit bieten. Deshalb wird die FMA-Methodik im wissenschaftlichen Bereich bevorzugt, doch „Sandy Bridge“ in der aktuellen Ausführung zielt eben auf den Mainstream-Markt und nicht das hoch wissenschaftliche Segment, in dem Server-CPUs zum Einsatz kommen. Intel wollte zu FMA keine Stellung beziehen, ließ aber schlussendlich durchblicken, dass es der weiteren Anpassungen am Prozessordesign wohl zu viel gewesen wäre. Indirekt verwies man damit auf die nächste Generation an Intel-Prozessoren, wobei damit eher „Haswell“ denn „Ivy Bridge“ gemeint sein dürfte, da „Ivy Bridge“ Ende dieses Jahres lediglich den Shrink auf 22 nm mit kleineren Anpassungen vollziehen soll.
Wie bereits festgestellt, wird AVX zu Beginn so oder so ein ähnliches Schattendasein wie viele SSE-Befehle fristen. Denn erst mit der entsprechenden Software kann dieses Feature richtig genutzt werden. Die Grundlage dafür ist im Heimbereich etwa Windows 7 mit dem anstehenden Service Pack 1, das nach aktuellem Stand AVX unterstützt. Mit der entsprechenden Marktdurchdringung der Prozessoren von Intel, die dann im Laufe des Jahres auch noch Unterstützung von AMDs „Bulldozer“ bekommen, die ebenfalls AVX bieten werden, sollte entsprechend optimierte Software dann aber zügiger als in den Jahren zuvor bereitstehen. Aktuell konnte Intel jedoch nicht einmal frühe Testversionen irgend einer beliebigen Software aus Labortests bereitstellen, so dass bis zur ersten, wirklich brauchbaren Software inklusive AVX-Nutzung noch Monate, wenn nicht gar ein Jahr oder mehr vergehen könnten. Bis dahin ist die Intel-AVX-Webseite als Anlaufstelle für viele Fragen und Antworten wohl die erste Wahl.
Einziger, halbwegs brauchbarer Nachweis der AVX-Funktion ist derzeit über zwei der vielen Tests von SiSoft Sandra 2011 möglich. So gibt es im Segment der Kryptografie-Benchmarks neben der AES-Funktion auch noch die SHA-Variante, die von AVX profitiert. Weiterhin gibt es den Cache- und Speicherbenchmark, der ebenfalls bei AVX leichten Anklang findet. Da man die AVX-Befehle im Benchmark auch deaktivieren kann, können wir einen ersten Blick auf die Auswirkungen werfen:
23 Prozent im SHA-Benchmark sind ein deutlicher Fingerzeig, die fünf Prozent im Cache- und Speicherbenchmark gehen hingegen fast unter. Die von Intel prophezeiten bis zu 30 Prozent Performancezuwachs könnten in den Praxis also greifen. Bis davon aber für den Endkunden etwas zu spüren ist, wird noch viel Zeit vergehen.