Intel präsentiert fünf Modelle des Xeon Phi „Knights Corner“
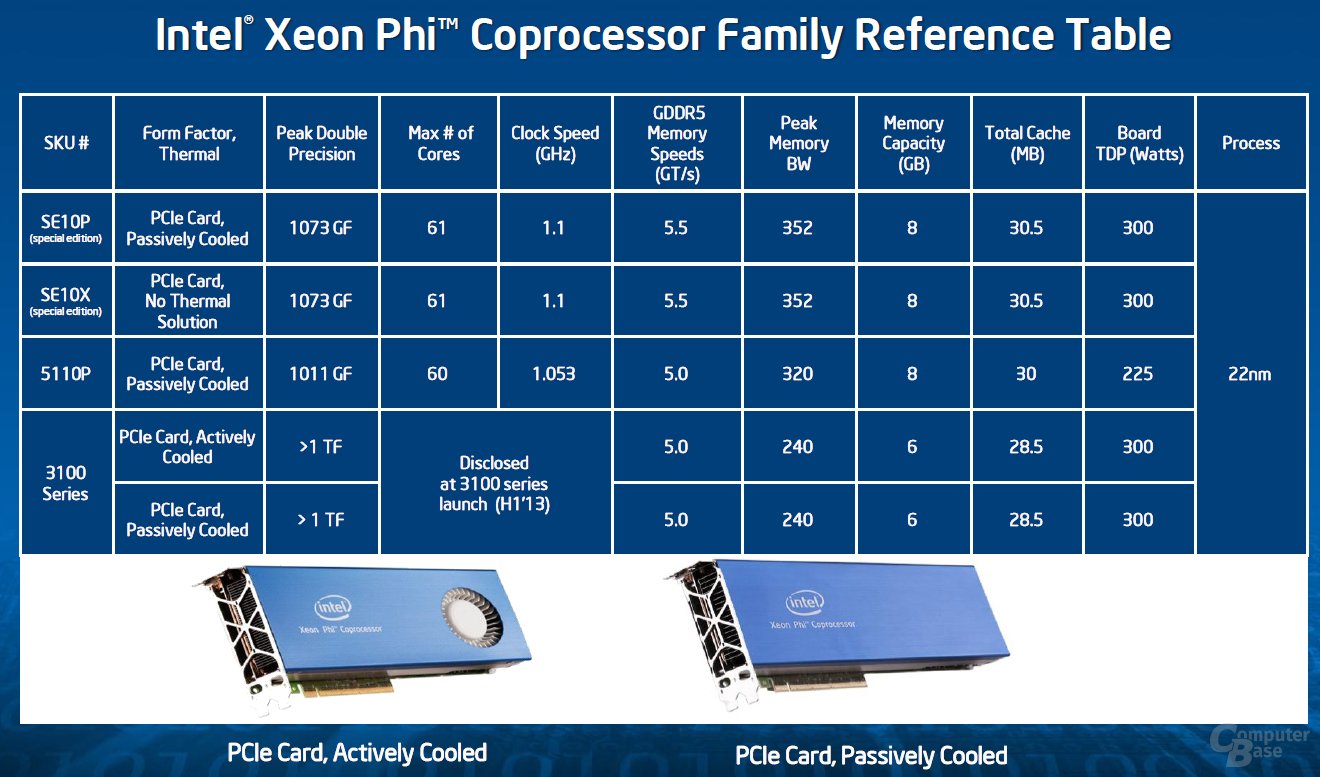
Nachdem Intel im Juni dieses Jahres den Vorhang für die „Knights Corner“ als Xeon Phi öffnete und Ende des Sommers dann weitere technische Details präsentierte, sind jetzt die finalen Spezifikationen für den Handel preisgegeben worden. Diese sehen zwei Produktgruppen vor, woraus fünf Modelle gezogen werden.
Zwei Hauptgruppen stellt Intel bei den Xeon Phi vor, die Modelle der 3100-Serie sowie die Xeon Phi 5110P. Bei den Xeon Phi 3100 soll es zwei Ableger geben, die jedoch erst im kommenden Jahr in den Handel kommen sollen. Der größte Unterschied zu den Flaggschiffen wird die Anpassung des Speicherinterfaces und des zur Verfügung stehenden GDDR5-Speichers mit ECC-Unterstützung. Im Schnitt werden die Modelle 60 Kerne (maximal möglich wären 62) haben, die Unterstützung von Quad-SMT (Simultaneous Multithreading) macht daraus 240 Threads.

Aus der Modellreihe Xeon Phi 5110P wird dann jedoch noch einmal eine hochgezüchtete Variante herausgezogen, die als zwei „Special Edition“ separat vermarktet werden. Der wesentliche Unterschied bei den beiden Modellen, die auf Kundennachfrage separat entwickelt wurden, ist, dass man überall noch etwas mehr herausholt (ein zusätzlicher Kern, höherer Takt, gesteigerte Speicherbandbreite), dies am Ende aber auch mit der deutlich gesteigerten TDP auf 300 Watt bezahlt, während die normalen Xeon Phi 5110P mit 225 Watt spezifiziert sind.



Hinsichtlich der Performance hält man sich aber auch heute relativ bedeckt. Gern spricht man den Peak-Wert der Leistung an, der mit 1 TFLOP/s (Billionen Fließkommaoperationen pro Sekunde) beziffert wird. Doch der Peak-Wert wird nur selten erreicht, in realen Tests wie Linpack oder auch DGEMM liegen die GFLOP/s deutlich unter der symbolisch wichtigen Marke. Deshalb vergleicht Intel die Xeon Phi auch lieber im eigenen Haus und stellt den Vorteil gegenüber herkömmlichen Systemen dar, die nur auf Prozessoren ohne die Unterstützung von Grafikbeschleunigern basieren. Den Blick zur Konkurrenz überlässt man anderen – dieser fällt nämlich nicht mehr so rosig aus.

Auch wenn die Ergebnisse über zwei Hersteller schwerlich vergleichbar sind, dürfte Nvidias neue K20(X)-Lösung am Ende in einer ganz anderen, höheren Liga spielen. Dort liegt man immer jenseits der TFLOP/s-Marke, auch im Linpack oder DGEMM, die keine Peak-Werte ausgeben.
Die Auslieferungen der Xeon Phi 5110P für Server-Fertiger haben bereits begonnen, ab Ende Januar wird das Flaggschiff für 2.689 US-Dollar auch für „jedermann“ im Handel stehen. Später im ersten Halbjahr des kommenden Jahres wird dann die kleinere Ausgabe als Xeon Phi 3100 im Handel stehen, unter 2.000 US-Dollar sind dort angepeilt. Bereits mehr als 50 Unternehmen haben angekündigt, Xeon Phi einzusetzen.
Um die Leistung von mehr als 1 TFLOP/s zu erreichen, müssten beide Xeon Phi 3100 aber mindestens mit 1,1 GHz takten – Intel hält aber sowohl die Anzahl der Kerne als auch eben diese Ziffer noch unter Verschluss. Anhand der Cache-Bestückung (0,5 MByte pro Kern) und der groben Angabe zur Leistung kann man jedoch rechnerisch auf die besagten Mindestwerte kommen.
| Nvidia Tesla K20 |
Nvidia Tesla K20X |
AMD FirePro S9000 |
Intel Xeon Phi 3100 |
Intel Xeon Phi 5110P |
|
|---|---|---|---|---|---|
| GPU | GK110 | GK110 | Tahiti | Knights Corner | Knights Corner |
| Rechenkerne | 2.496* | 2.688* | 1.792 | 57* | 60 |
| Takt | 705 MHz* | 735 MHz* | 900 MHz | 1,1 GHz* | 1,053 GHz |
| Leistung SP/DP |
3,52/1,17 TFLOPS | 3,95/1,31 TFLOPS | 3,2/0,806 TFLOPS | 2,x/1,x TFLOPS | 2,02/1,01 TFLOPS |
| Speicherinterface | 320 Bit* | 384 Bit* | 384 Bit | 384 Bit* | 512 Bit |
| Speichertakt | 2.500 MHz* | 2.600 MHz* | 2.750 MHz | 2.500 MHz | 2.500 MHz |
| Speicherbandbreite | 208 GB/s | 250 GB/s | 264 GB/s | 240 GB/s | 320 GB/s |
| Speichergröße | 5.120 MB | 6.144 MB | 6.144 MB | 6.144 MB | 8.192 MB |
| TDP (max) | 225 Watt | 235 Watt | 225 Watt | 300 Watt | 225 Watt |
| *Schätzung unsererseits | |||||
In der neuen Ausgabe der Top500-Liste der Supercomputer kann sich ein System mit Xeon Phi auf dem siebenten Platz positionieren. Mit 11.500 Xeon E5 in Zusammenarbeit mit 1.875 Xeon-Phi-Karten wird dort eine Rechenleistung von 2,66 PetaFLOPs erreicht. Das System ist allerdings noch im Aufbau, am Ende sollen rund 7.000 „Grafikbeschleuniger“ dort einen Platz finden, womit diese allein bereits 7 PetaFLOPs an Rechenleistung bieten würden und zusammen mit den Xeon dann rund 9 PetaFLOPs erreicht werden dürften – aktuell wäre dies Platz 5. Und beim Besitzer dieses Systems greift man bereits hoch hinaus: Future generations of Intel coprocessors will be added when they become available and are expected to increase Stampede's aggregate peak performance to at least 15 petaflops. Insgesamt sind heute aber erst derer sieben Systeme mit Xeon Phi in der neuen Ausgabe der Top500 der Supercomputer gelistet.
Darunter ist mit dem „Beacon“ auch ein auf den ersten Blick eher unscheinbares System der Universität Tennessee auf dem Platz 253 gelistet, dass die höchste Effizienz im Ranking der 500 Supercomputer aufweist. Zwar liefert das System nur 110 TFLOP/s an Rechenleistung, verbraucht dafür aber lediglich 45 KW. Mit den 2,44 GFLOPS pro Watt lässt man den Spitzenreiter „Titan“ mit seinen 2,14 GFLOPS pro Watt in dieser Disziplin deutlich hinter sich.