Knights Landing: Physisch mit 76 Kernen, weitere Details und erste Benchmarks

Intel hat im Rahmen des Symposiums Hot Chips 27 mehr Details zur neuen Auflage des Xeon Phi mit dem Codenamen Knights Landing veröffentlicht. Physisch sind auf dem CPU-Die 76 Kerne, für bessere Yields maximal 72 aktiv. Ebenfalls mit dabei sind erstmals Benchmarks von Intels selbst, die eine erste Einschätzung erlauben sollen.
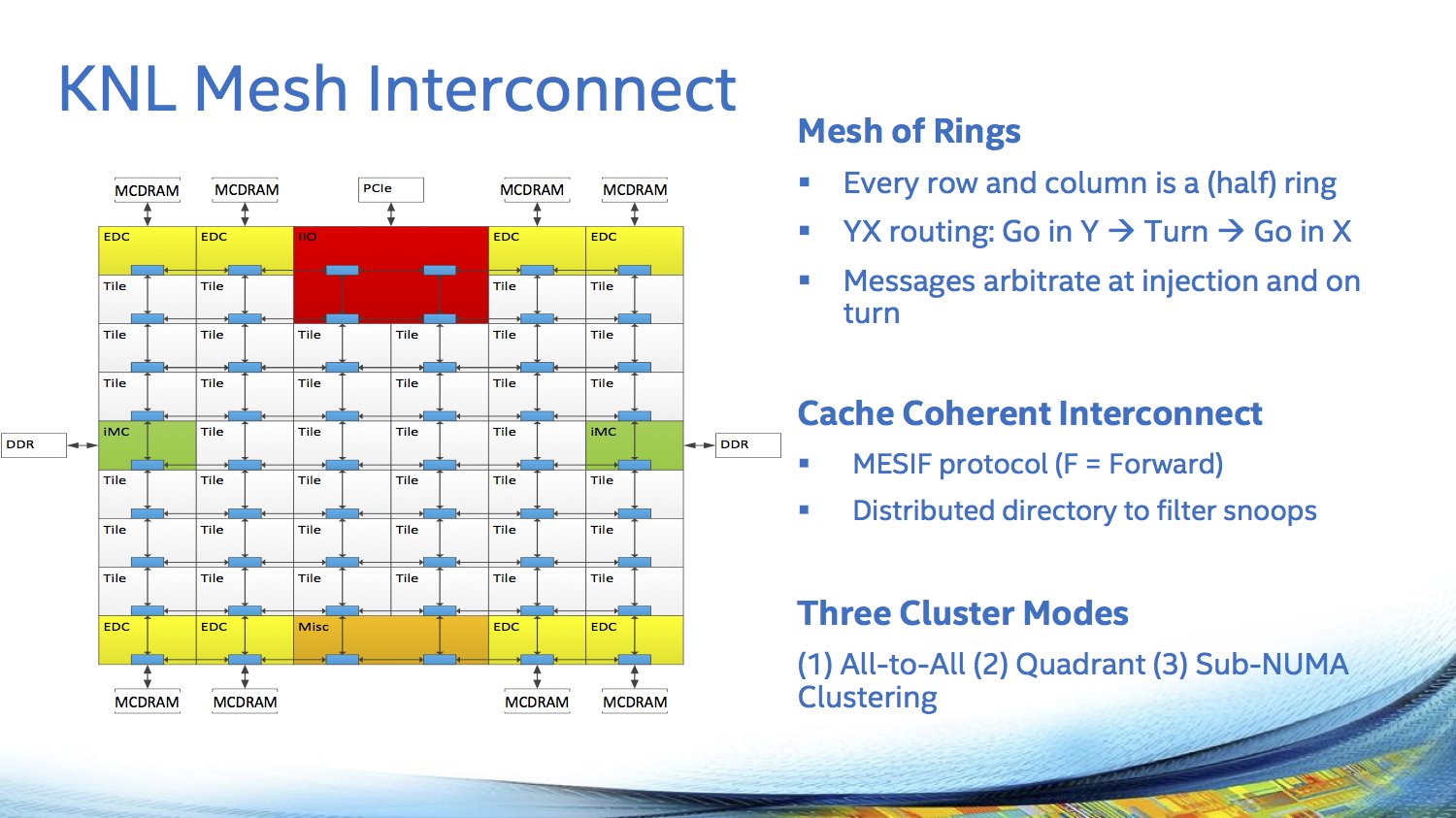
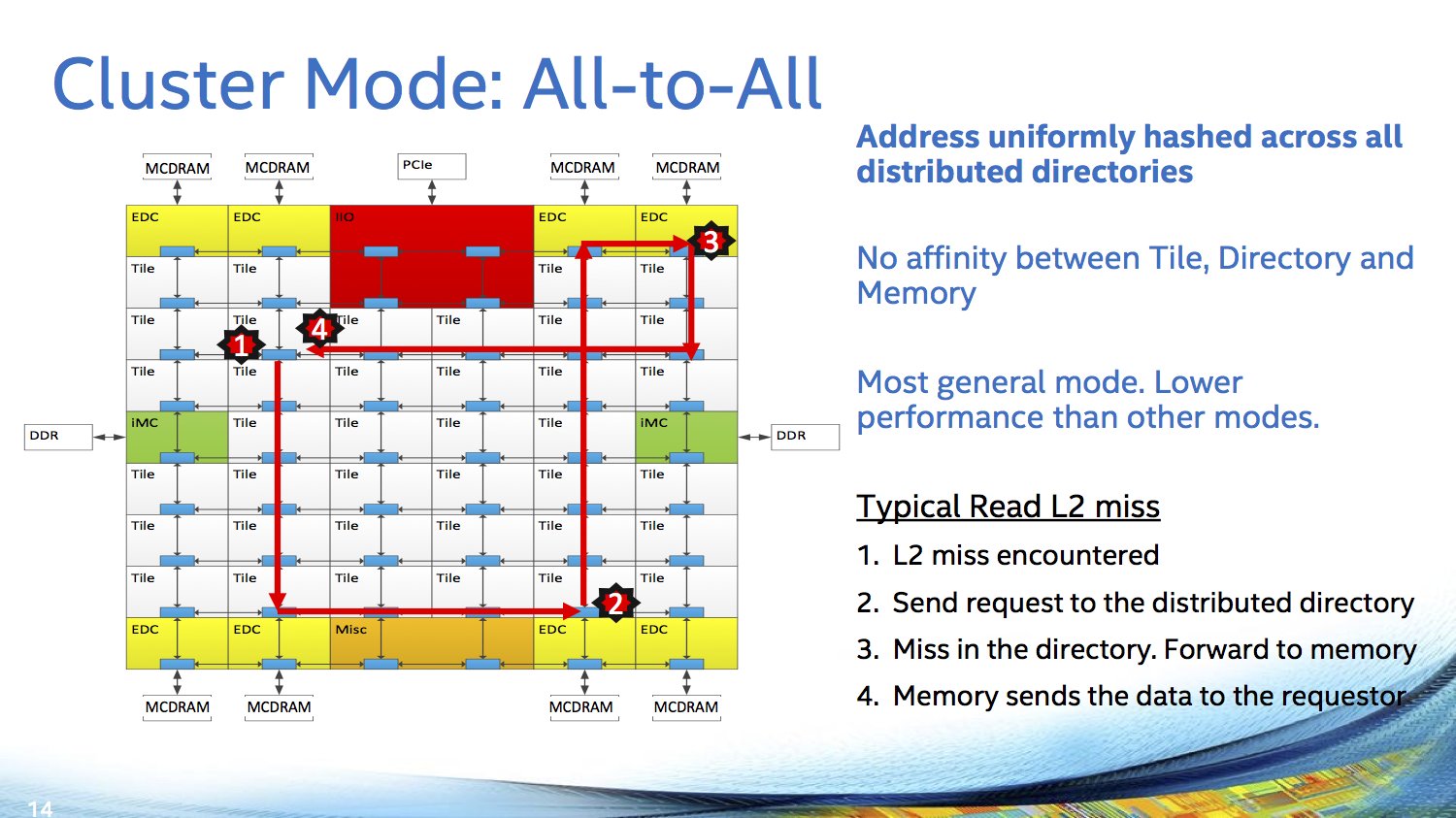
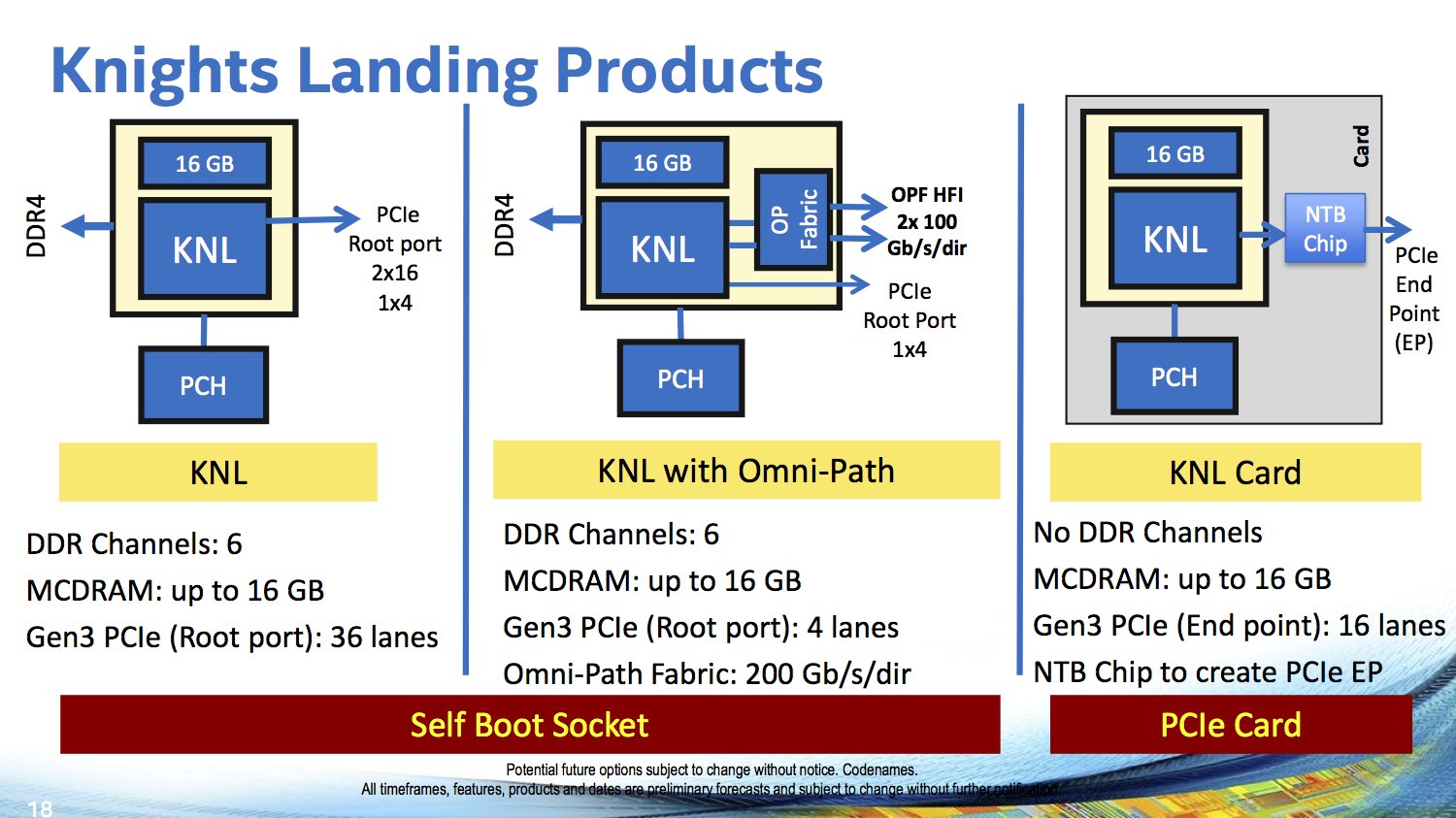
Nach dem IDF 2015 ohne große Neuheiten zum Thema Xeon Phi hat sich Intel der Zielgruppe entsprechend auf dem Symposium für High-Performance-Chips etwas umfangreicher geäußert. Doch auch hier kommt die bei Intel derzeit beliebte stückweise Informationsverteilung zum Einsatz, denn zur integrierten Fabric Omni-Path (früher auch Omni-Scale oder Storm Lake genannt) wird der Hersteller erst am morgigen Tag auf der Hot Interconnect 23, einer weiteren Veranstaltung aus diesem Bereich, mehr sagen. Oberflächliche Details gibt es aber bereits: Intern über 32 der insgesamt 36 PCIe-Lanes, die Knights Landing bietet, angebunden, wird das Gesamtpaket zu einem Multi-Chip-Package, versteckt unter einem großem Heatspreader.


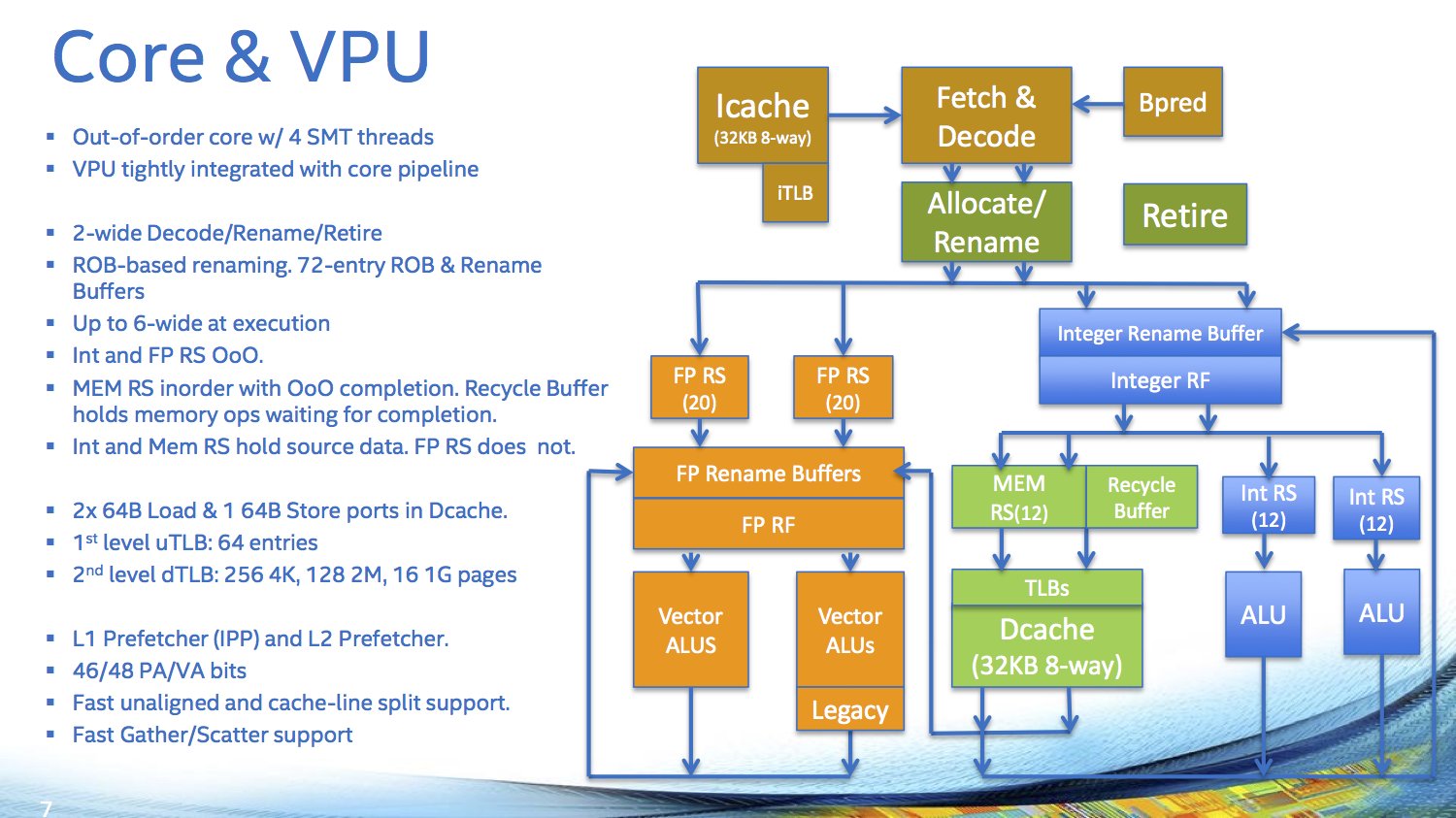
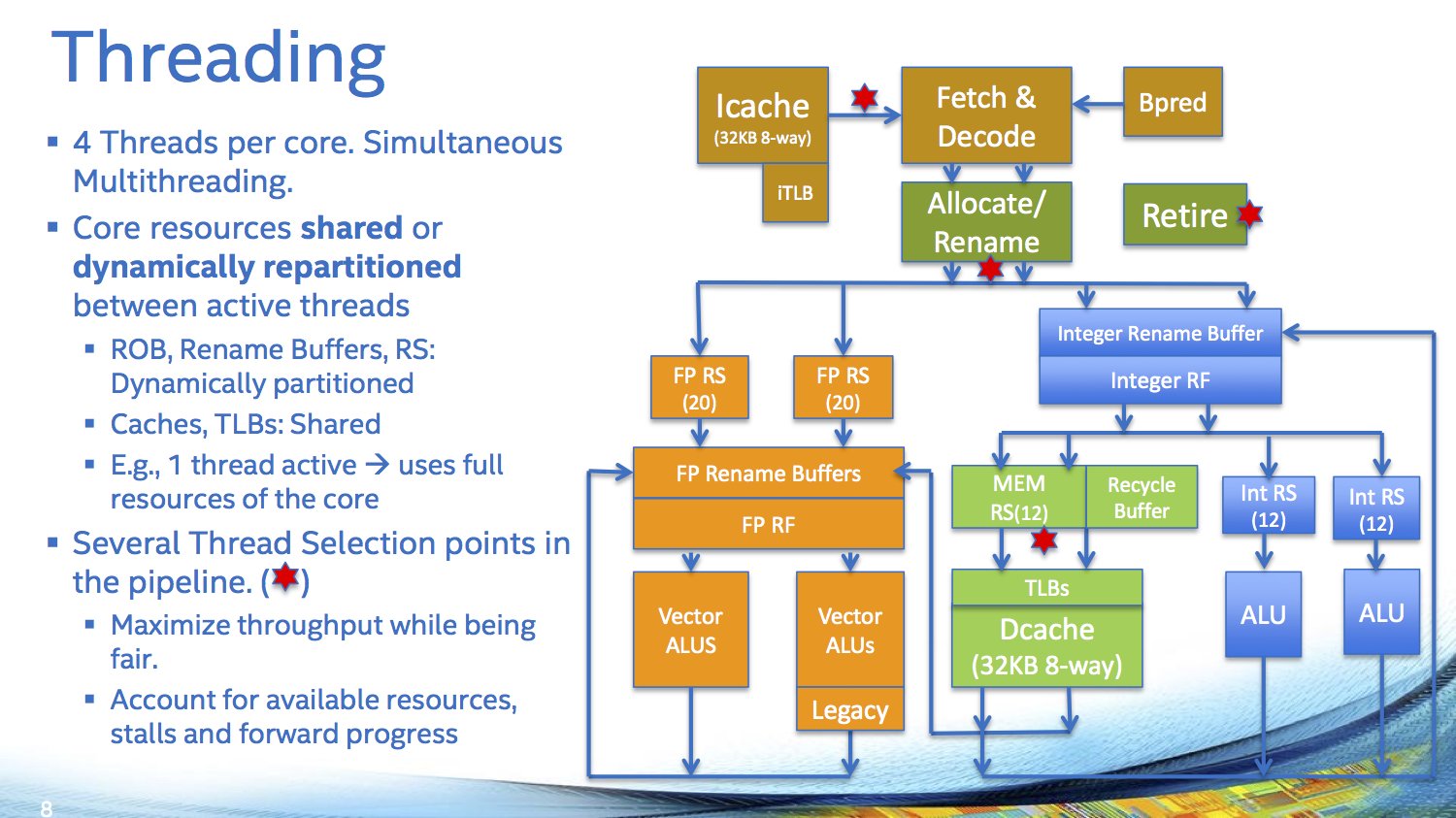
Zur Architektur hat sich Intel bereits in den letzten Monaten geäußert, nun aber noch etwas mehr Details genannt. Dabei betont der Chefarchitekt Avinash Sodani erneut, dass es sich auf dem Papier zwar um Silvermont-Prozessorkerne aus der Atom-Serie handelt, diese jedoch massiv angepasst und überarbeitet wurden – und eigentlich einen neuen Codenamen verdient hätten. Erst am Rande in kleiner Runde gab Sodani bekannt, dass von maximal 76 physischen Kernen aus Gründen der Ausbeute an funktionsfähigen Chips pro Wafer (Yield) bei dem 8-Milliarden-Transistoren-Design auf knapp 700 mm² jedoch immer höchstens 72 aktiv sind. Diese werden dank 4-fachem Hyper-Threading bis zu 288 Threads bereitstellen können. Neu ist die „Kern-Reserve“ nicht, IBM machte dies bereits im Jahre 2010 mit dem BlueGene/Q vor, bei dem von 18 physischen Kernen maximal 16 oder 17 aktiv genutzt werden konnten. Intel hat zudem auch aus dem letzten Xeon Phi gelernt, die seinerzeit maximal möglichen 61 Kerne waren gerade zu Beginn sehr selten anzutreffen, meistens wurde die 57-Kern-Version verbaut.
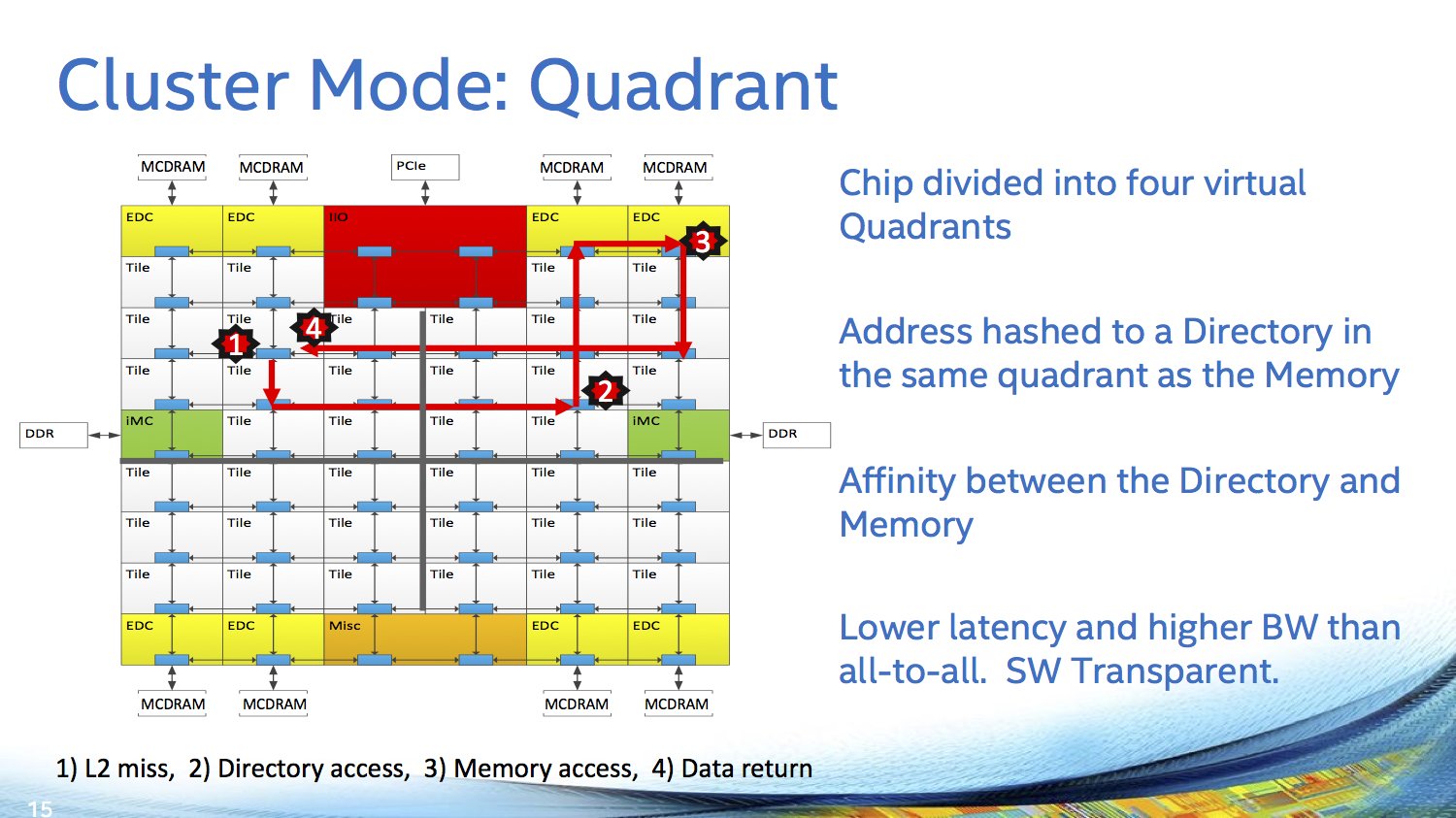
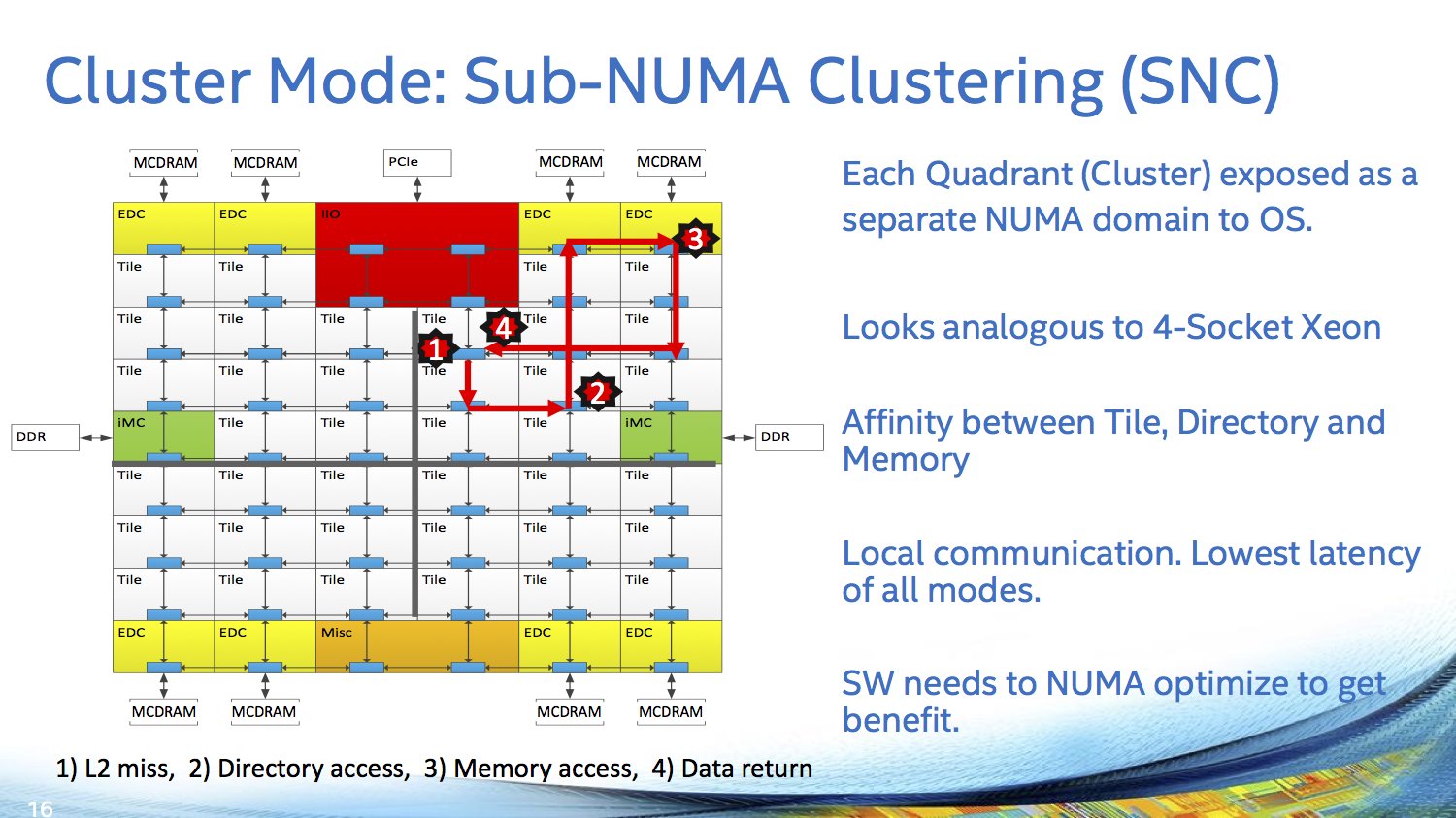
Jeweils zwei Kerne werden bei Knights Landing mit einem Megabyte L2-Cache und vier VPUs zu einem Tile zusammengeschlossen – das Schaubild zeigt dabei bereits zuvor nicht kommunizierte 38 Tiles und somit 76 Kerne. Die Vector Processing Units (VPU) sind die ersten mit Unterstützung für AVX-512, welches auch nur bei den Xeon Phi in dieser Form geboten wird – ein Fakt, der ebenfalls bereits seit 2013 bekannt ist.
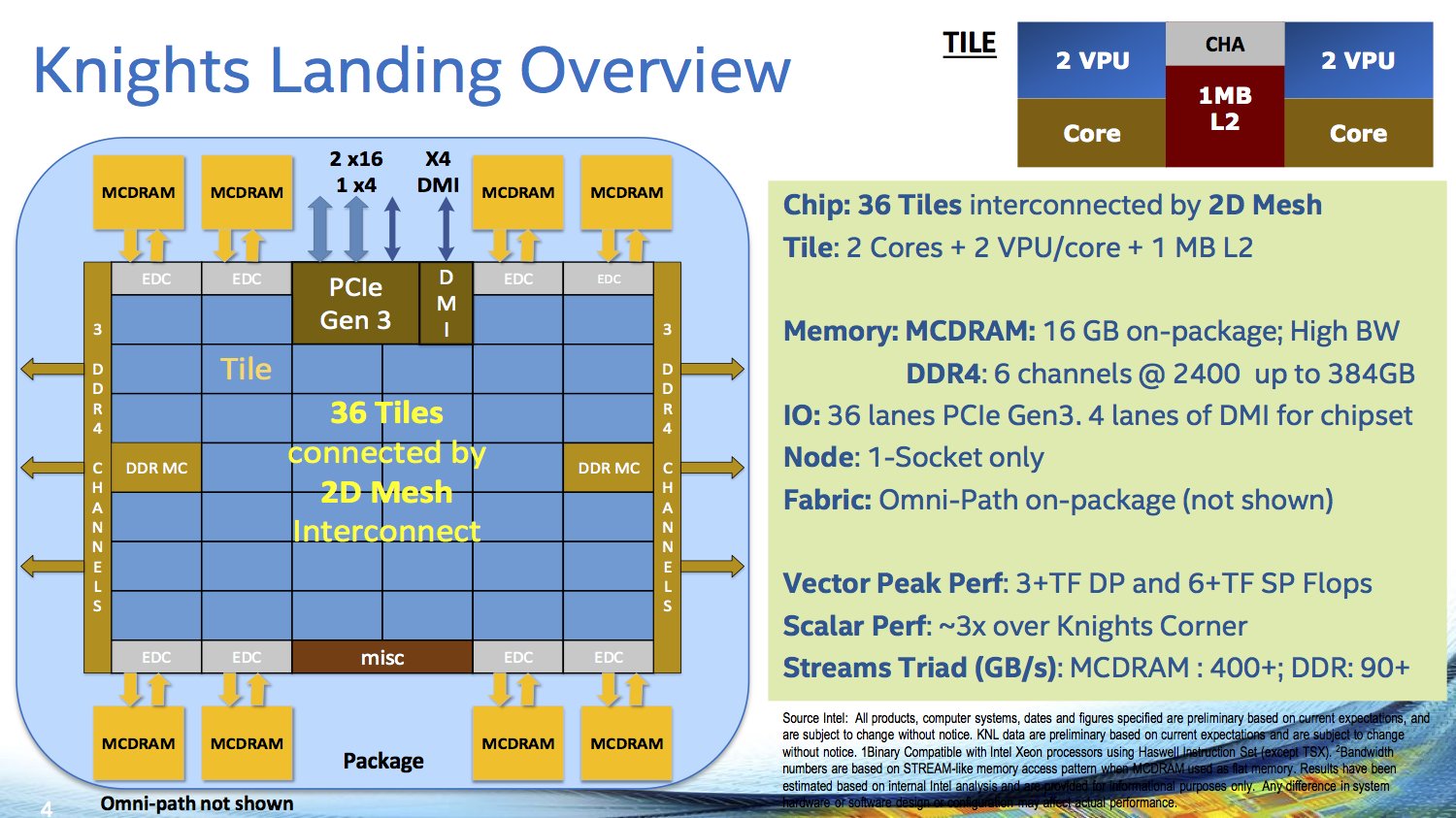

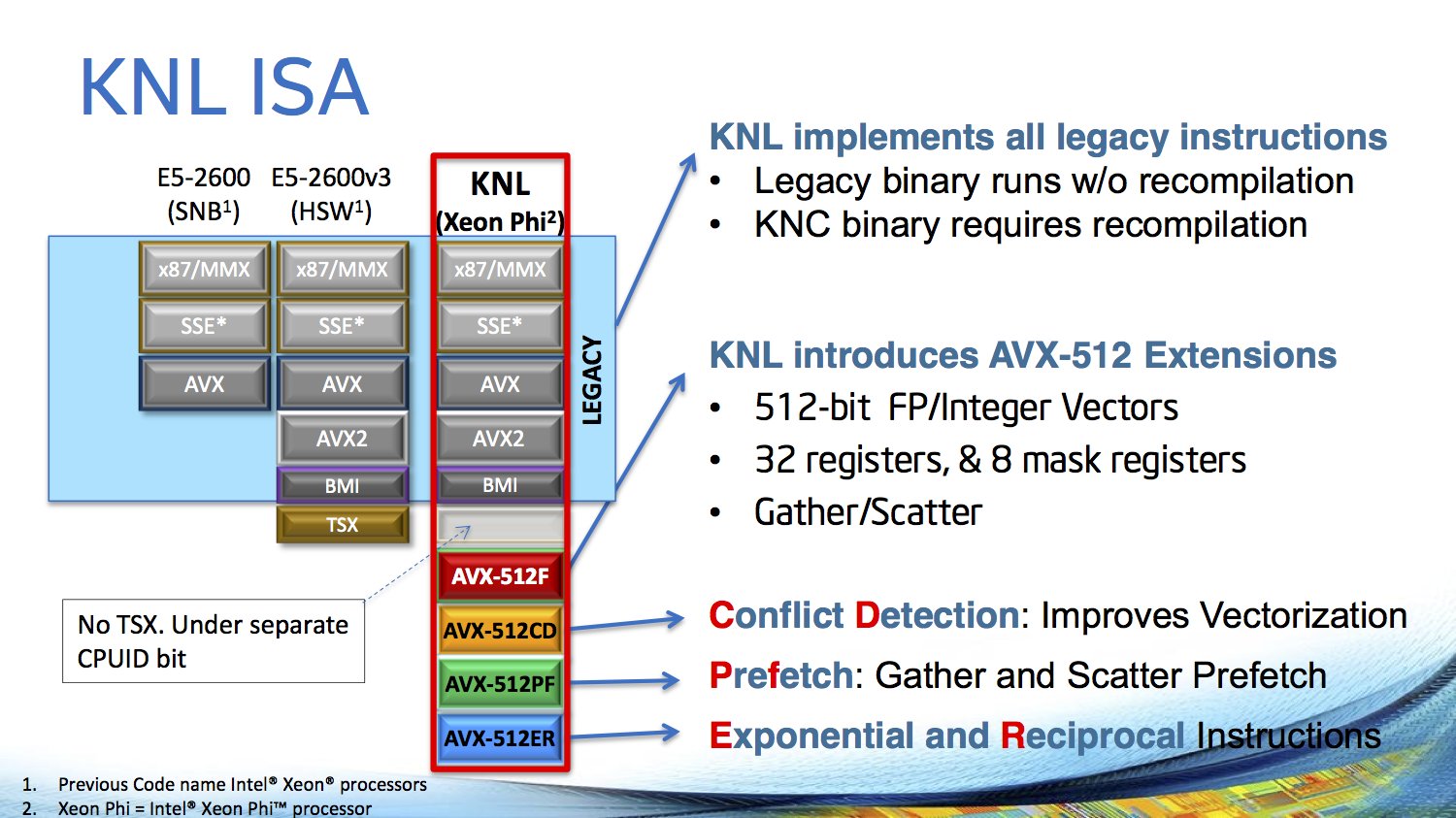
Dem Speicher kommt bei Knights Landing eine besondere Bedeutung zu. 16 GByte von Microns Hybrid Memory Cube (HMC) sind direkt auf dem Package untergebracht, der je nach Einsatzgebiet angesprochen werden kann. Einerseits als riesiger Last-Level-Cache vor dem bis zu 384 GByte großen DDR4-Speicher, alternativ aber auch direkt als zweiter Speicher neben dem DDR4, der von Entwicklern aber weiterhin separat adressiert werden kann. Interessant sind dann die Zwischenlösungen: 25 oder 50 Prozent des HMC können wahlweise als Cache oder zweiter Speicher genutzt werden.
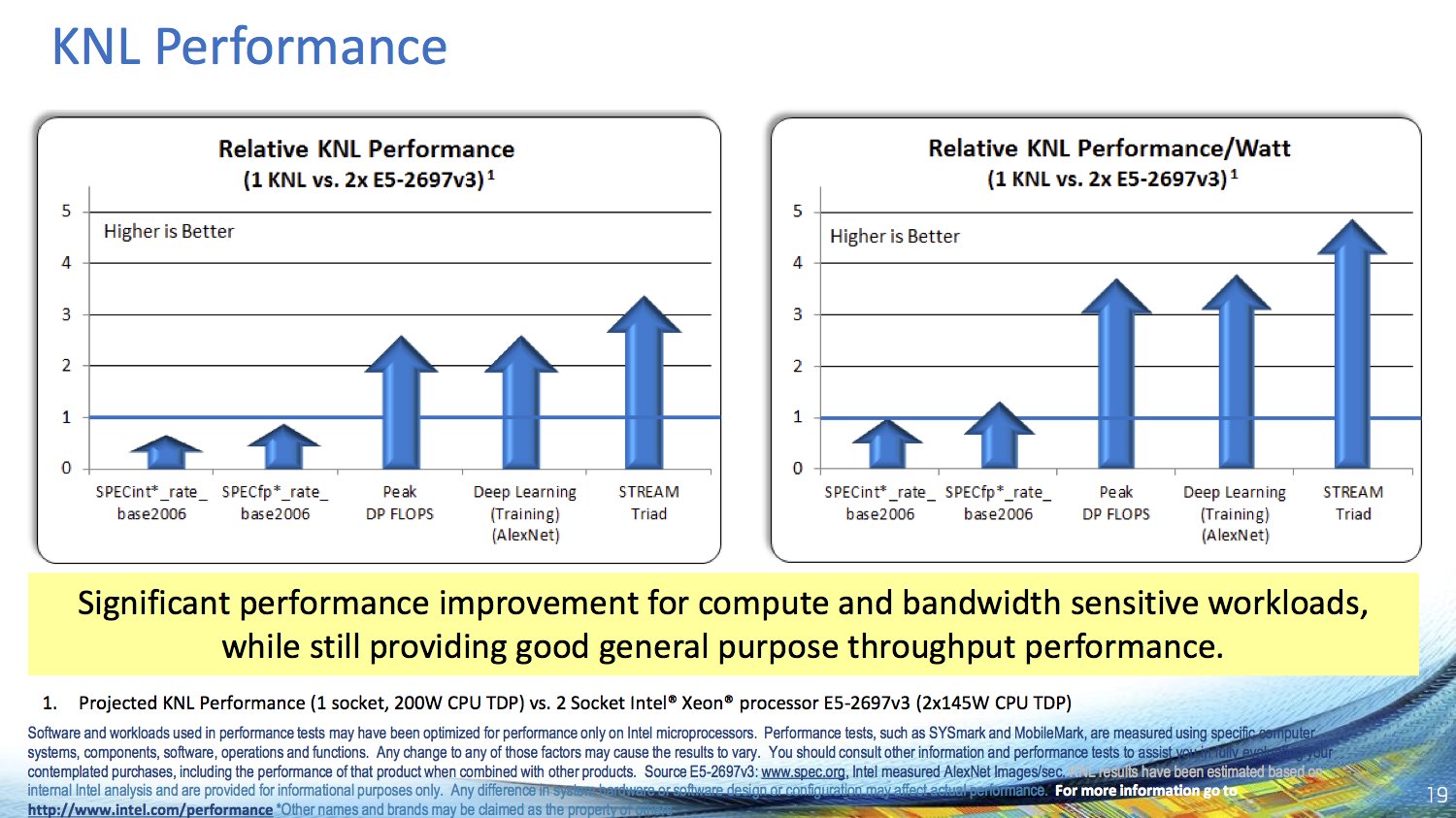
Nach der ganzen Theorie lässt Intel auch erstmals Benchmarkwerte des neuen Xeon Phi an die Öffentlichkeit. Dabei nutzt der Hersteller eine 200-Watt-Prozessor-Variante von Knights Landing mit einer unbekannten Anzahl an Kernen und vergleicht diese mit einem Dual-Sockel-System, bestehend aus zwei Xeon E5-2697 v3, die insgesamt 28 Kerne und 56 Threads bieten – allerdings bei einer TDP von 2 × 145 Watt. Die Vergleiche von Performance zu Watt sind allerdings mit größter Vorsicht zu betrachten, da diese sich nur auf die reine TDP beziehen, die im Alltag und abhängig von der Anwendung oft nur ansatzweise ausgereizt wird. Der Blick auf die relative Leistung zeigt in den Spec-Benchmarks für den Xeon Phi eine 65 bis knapp 90-prozentige Leistung des Dual-Xeon-Gespanns. Erst bei spezielleren Tests können sich die Xeon Phi von den klassischen Prozessoren absetzen.
Zum IDF 2015 in der vergangenen Woche erklärte Intel bereits, dass in diesem Jahr vermutlich nur noch ein einziges Modell als Vorzeige-Objekt vorgestellt wird – vermutlich Mitte November zur Supercomputing Conference. Anfang 2016 sollen dann weitere Ausführungen folgen; mit welchen Taktraten bei wie vielen Kernen und welcher TDP bleibt bis dahin ein Geheimnis. Derzeit laufen noch die Pre-Production-Samples im A-Stepping, der Vorgänger kam im B0-Stepping auf den Markt und wurde zügig auf B1 und später C0 aufgewertet.
-
 Intel Knights Landing im Detail (Bild: Intel)
Intel Knights Landing im Detail (Bild: Intel)