Nvidia Tesla P100: Pascal-Flaggschiff jetzt als 250-Watt-PCIe-Lösung

Zum Auftakt der ISC 2016 in Frankfurt/Main hat Nvidia das aktuelle Tesla-Flaggschiff P100 als PCI-Express-Variante vorgestellt. Die bisher ausschließlich für NVLink bereitgestellte 300-Watt-Lösung wird dafür leicht in der Leistung angepasst, um die typische HPC-Grenze von 250 Watt nicht zu sprengen.
Die grundlegenden Spezifikationen der Tesla P100 sind aber identisch. Basis ist der 610 mm² große und 15,3 Milliarden Transistoren fassende Pascal-Chip GP100 mit 3.584 aktiven ALUs, dem maximal 16 GByte HBM2 zur Seite gestellt werden. Die TDP-Einschränkung auf maximal 250 Watt führt jedoch zu leicht gesenkten Taktraten und damit einer etwas geringeren Leistung. Während die NVLink-Versionen bei 300 Watt TDP bis zu 10,6 TFLOPS bei einfacher Genauigkeit (SP, FP32) bieten, sind es bei der PCI-Express-Version nur noch 9,3 TFLOPS. Das Verhältnis von SP/DP bleibt bei 2:1, bei doppelter Genauigkeit (DP, FP64) sind deshalb 4,7 statt 5,3 TFLOPS und bei HP-Anwendungsfällen (Half Precision, FP16) 18,7 statt 21,2 TFLOPS.
Neben der Variante mit 16 GByte HBM2 am 4.096 Bit breiten Speicherinterface und der daraus resultierenden Bandbreite von 720 GByte pro Sekunde wird Nvidia auch eine 12-GByte-Version auflegen. Deren Bandbreite wird dann allerdings deutlich zurückgehen, 540 GByte pro Sekunde werden vom Hersteller genannt. Wie das NVLink-Modell setzt aber auch die PCIe-Version auf „Unified Memory“, sodass die CPU auf den GPU-Speicher zugreifen kann und umgekehrt.

Laut Nvidia werden die neuen PCIe-Karten für OEMs ab dem vierten Quartal ausgeliefert. Zuvor werden sie jedoch bereits Kunden von größeren Systemen und Supercomputern zur Verfügung gestellt. Im April hatte Nvidia zusammen mit Cray angekündigt, beispielsweise den schnellsten Supercomputer Europas, den Piz Daint des Swiss National Supercomputing Center (CSCS) in Lugano, durch ein Upgrade mit Pascal-GPUs von Nvidia und neueren Intel-Prozessoren mehr als doppelt so schnell zu machen.
Fokus auf Deep Learning mit einem neuen SDK
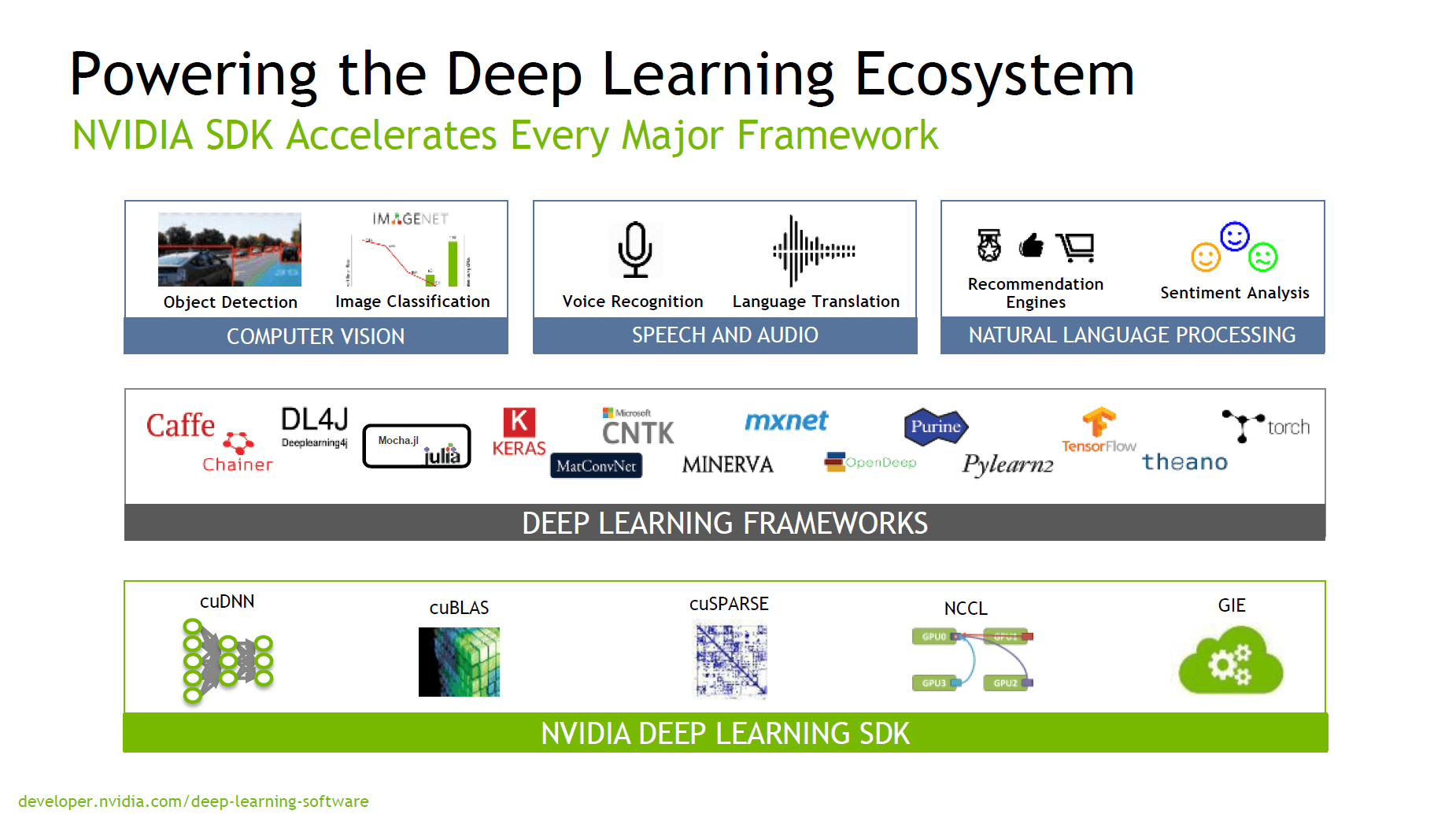
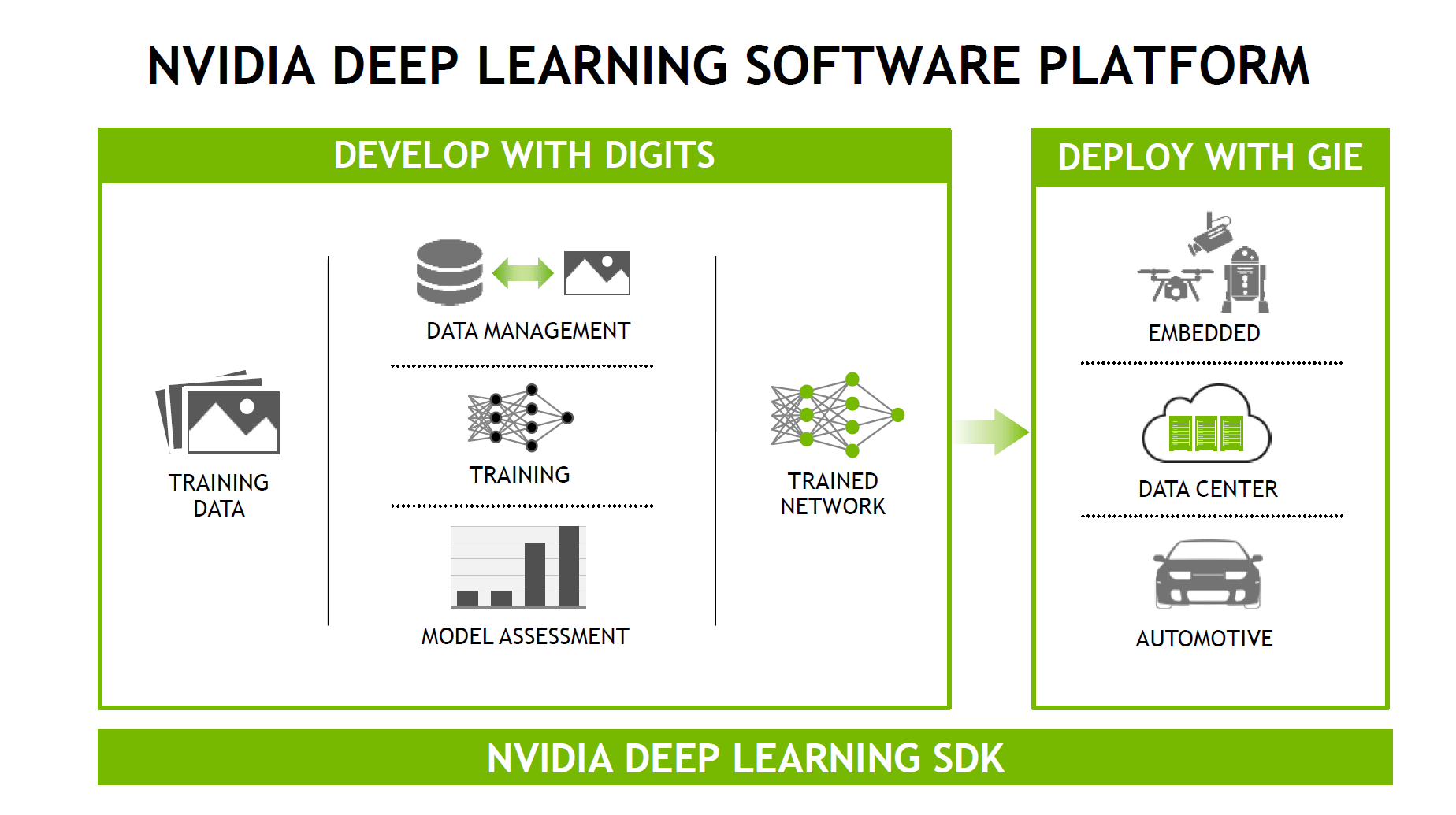
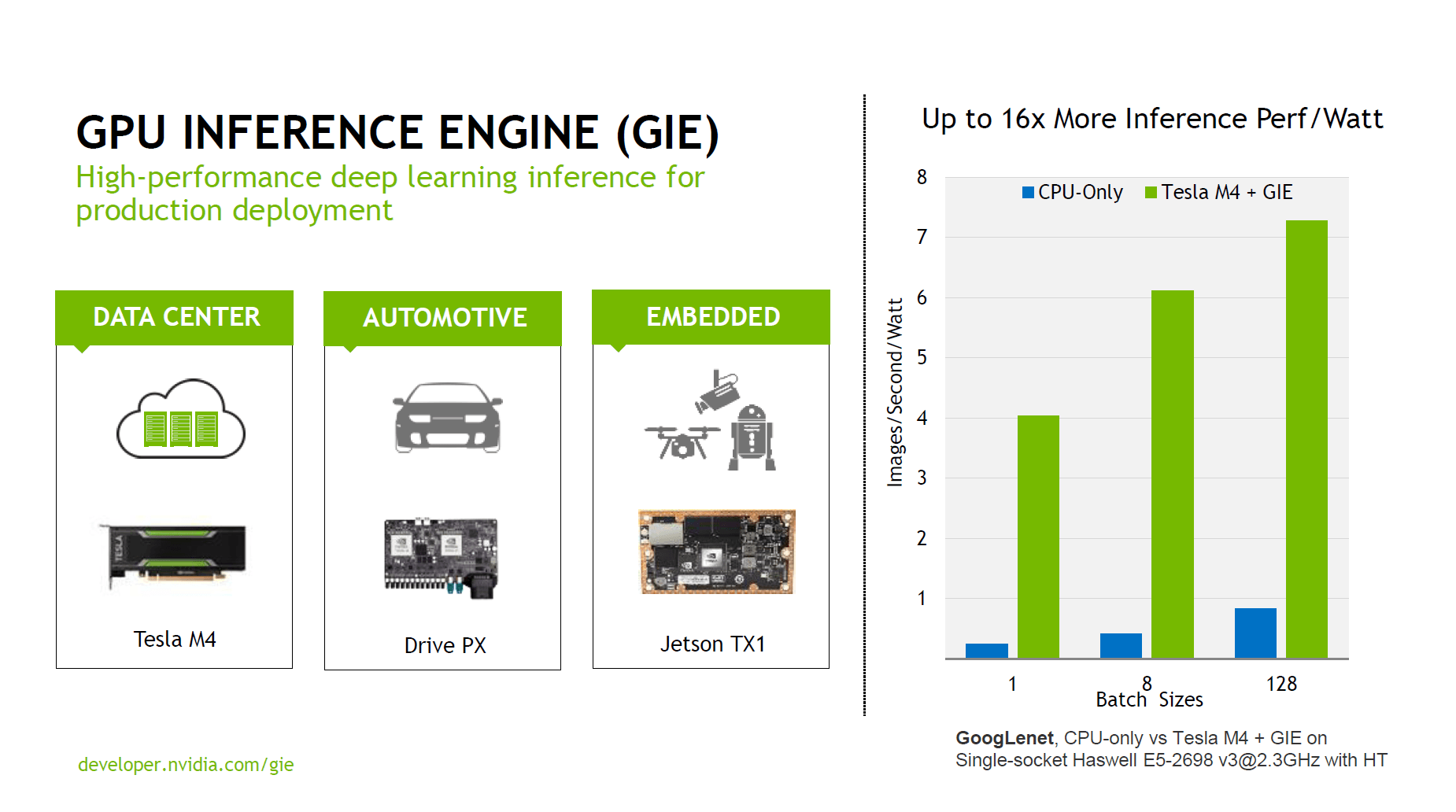
Passend zur HPC-Konferenz hat Nvidia ihr neues Deep-Learning-SDK angekündigt. Nvidia versteht dies als Rundum-sorglos-Paket, welches seit über drei Jahren in der Entwicklung ist. Neben der Unterstützung für alle aktuellen Frameworks bewirbt Nvidia den Werkzeugkasten mit regelmäßigen Updates und einer Tag-1-Unterstützung aller kommenden Nvidia-GPUs.
-
 Nvidia Deep-Learning-SDK (Bild: Nvidia)
Nvidia Deep-Learning-SDK (Bild: Nvidia)