Nvidia Volta: Tesla V100 bringt 15 TFLOPs bei 5.120 ALUs auf 815 mm²

Nvidias CEO Jensen Huang hat soeben auf der derzeit stattfindenden Hausmesse GTC Details über die kommende Volta-Architektur mitsamt entsprechender GPU bekannt gegeben. Das an den HPC-Markt gerichtete Tesla-Flaggschiff GV100 misst überraschend hohe 815 mm² und birgt 5.120 ALUs mit einer Leistung von 15 TFLOPS (FP32).
Als Prozess gibt Nvidia für den GV100, so heißt die GPU hinter der Tesla V100, die 12-nm-Fertigung bei TSMC an, wobei es sich um einen optimierten 16-nm-Prozess handelt. Ebenso erstaunliche 21,1 Milliarden Transistoren fasst die GPU. Als Eckdaten für die Performance der Tesla V100 spricht Nvidia von 15 TFLOPS FP32-Leistung sowie der halben FP64-Performance von 7,5 TFLOPS. Das Single-Precision- zu Double-Precision-Verhältnis liegt also erneut bei 2:1. Entsprechend beträgt die Boost-Taktrate des GV100 1.455 MHz. Damit liegt die theoretische Rechenleistung des professionellen Volta etwa 41 Prozent über der des professionellen Pascal, dem Tesla P100.
Als Speicher kommen erneut vier HBM2-Stacks mit jeweils vier Gigabyte zum Einsatz. Die Speichergröße beträgt also erneut 16 Gigabyte. Der achtfach gestapelte HBM2-Speicher scheint damit zunächst exklusiv AMDs kommender Vega-GPU in der professionellen Ausführung vorbehalten zu sein. Nvidia spricht von einer Bandbreite von 900 GB/s, sodass der Speicher mit rund 875 MHz angesteuert werden muss. Die Bandbreite ist damit um etwa 21 Prozent gestiegen. Zudem gibt es 320 Textureinheiten. Entsprechend kann der GV100 auch Grafik ausgeben, es handelt sich nicht um einen reinen HPC-Chip. Als weitere Eckdaten nennt Nvidia ein 20 Megabyte großes Register File sowie einen insgesamt 16 Megabyte umfassenden Cache. Die professionelle Verbindung zu anderen Tesla V100 oder auch zu CPUs, NVLink genannt, ist in neuer Generation erneut dabei. Die Bandbreite beträgt 300 Gigabyte in der Sekunde und arbeitet damit etwa doppelt so schnell wie im Vorgänger. Die TDP ist erneut mit 300 Watt angegeben.
Die Tesla V100 nutzt eine teildeaktiverte GV100-GPU
Ein von Nvidia freigegebener Blogeintrag geht etwas genauer auf die erste Volta-GPU ein. Demnach nutzt die Tesla V100 sogar nur eine teildeaktivierte GV100-GPU. Denn dieser hat eigentlich 5.376 FP32- und 2.688 FP64-ALUs sowie 336 Textureinheiten.
-
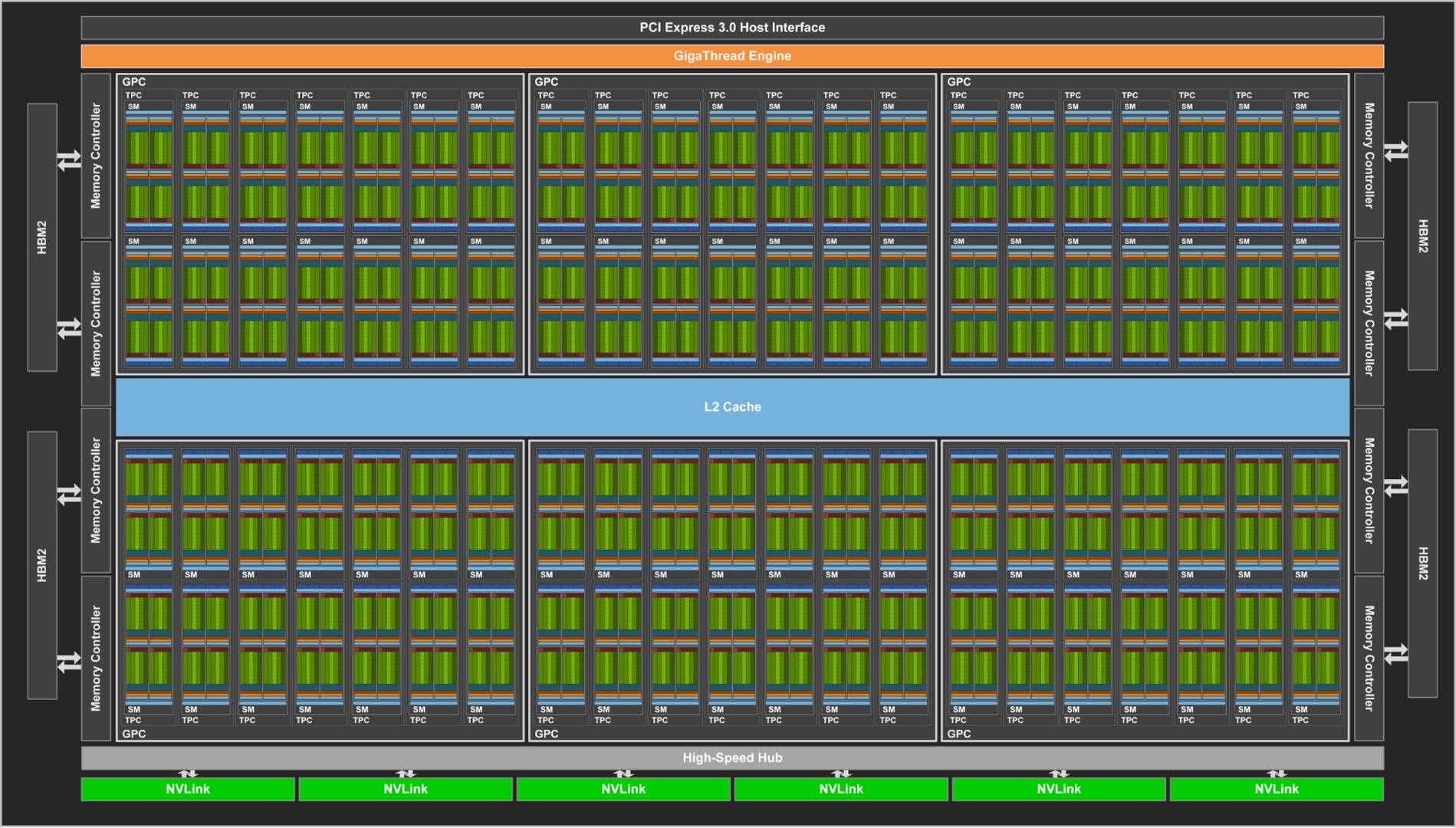 Die GV100-GPU (Vollausbau) (Bild: Nvidia)
Die GV100-GPU (Vollausbau) (Bild: Nvidia)
Der eigentliche Rohaufbau vom GV100 ähnelt dem vom GP100. So trägt jeder Streaming Multiprocessor immernoch 64 ALUs, nur gibt es auf dem GV100 84 SMs anstatt 60 – dadurch die 5.120 ALUs. Es gibt 42 Texturcluster mit jeweils 4 TMUs. Interessant ist, dass Nvidia beim GV100 ausschließlich von FP64-, FP32- sowie von INT-32- und FP16-Berechnungen spricht. Von INT8 ist dagegen, anders als beim GP100, keine Rede mehr. Vielleicht fehlt dies aber auch einfach nur in dem Blogeintrag. Jeder der acht Speichercontroller verfügt über einen 768 Kilobyte großen L2-Cache, der insgesamt also 6.144 Kilobyte groß und damit 50 Prozent größer ist als auf dem GP100.
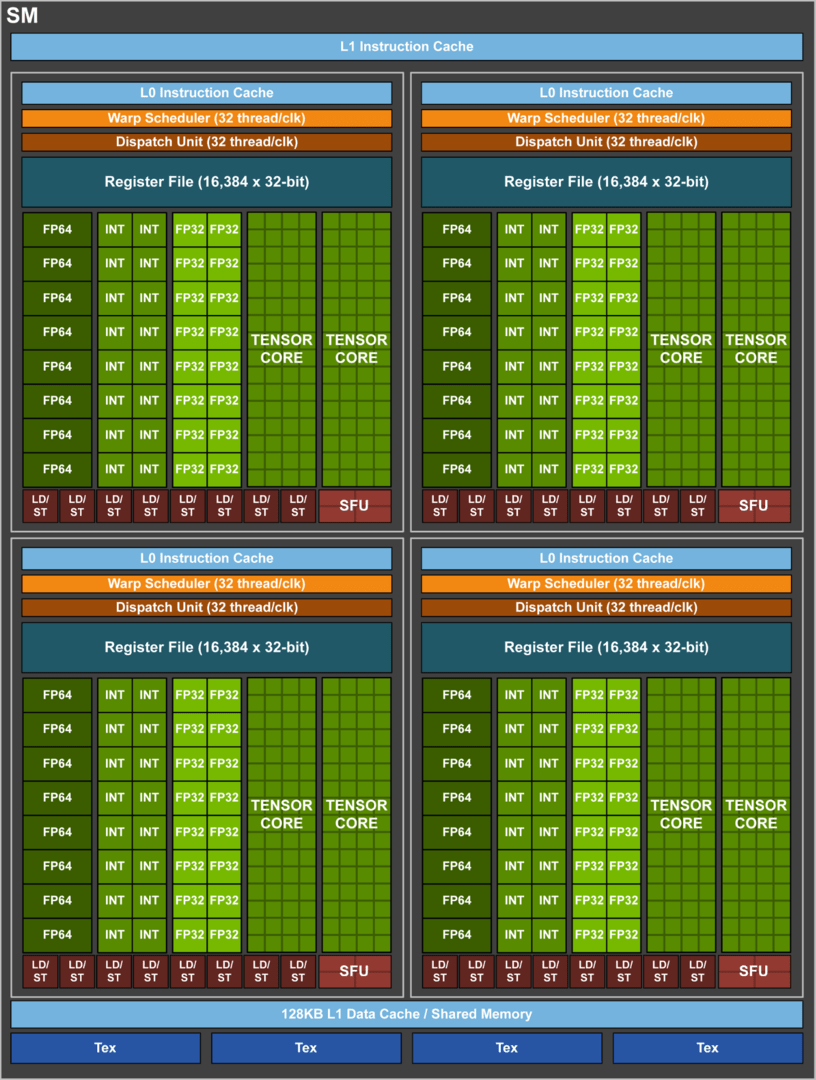
Nvidia hat den Aufbau der Streaming Multiprocessors auf Volta verändert
Und auch zur generellen Architektur gibt es Informationen. Demnach hat Nvidia die Streaming Multiprocessors gegenüber Maxwell und Pascal massiv umgebaut und für Deep-Learning-Berechnungen optimiert. Dadurch soll bei Volta auch die Energieeffizienz pro SM um 50 Prozent gegenüber Pascal ansteigen. Es gibt pro SM acht für ausschließlich neurales Training gedachte sogenannte „Tensor Cores“ (640 auf dem Tesla V100), die einen achtfach so hohen Output wie die traditionellen FP32-ALUs haben (120 „Peak Tensor Core TFLOPS“ ). Diese können durch Zusammenfassen von mehreren FP16- und FP32-Berechnungen deutlich schneller ein Ergebnis erzeugen als eine normale FP32-ALU. Die Tensor Cores können mit Hilfe eines CUDA-C++-Interfaces oder auch anderer angepasster CUDA-Libraries angesprochen werden.
-
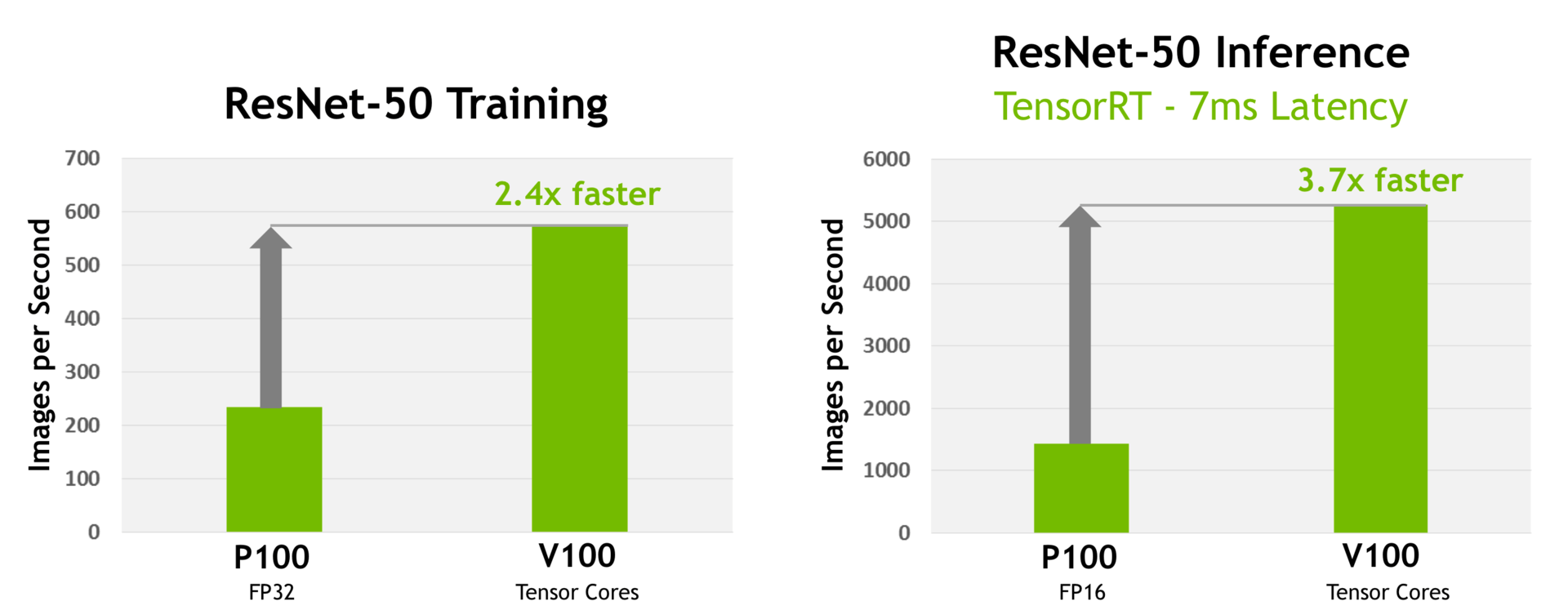
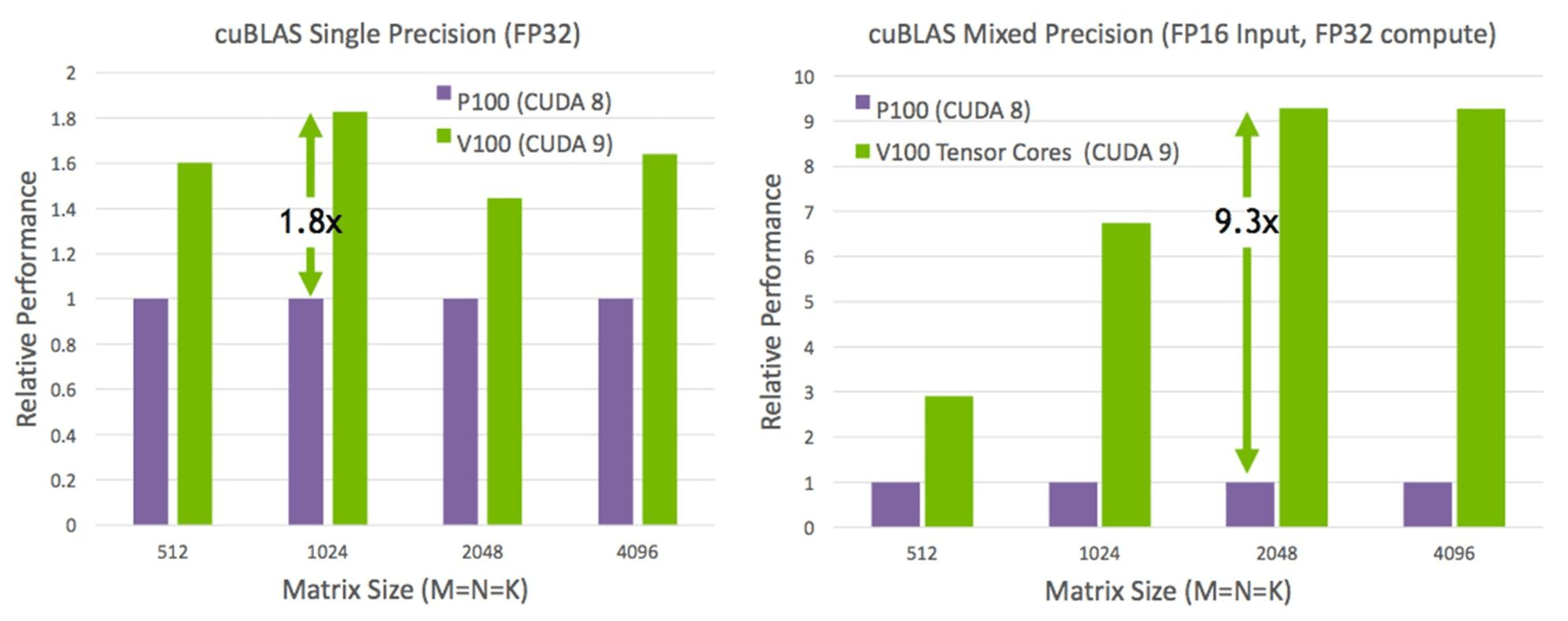 Tensor-Core-Performance (Bild: Nvidia)
Tensor-Core-Performance (Bild: Nvidia)
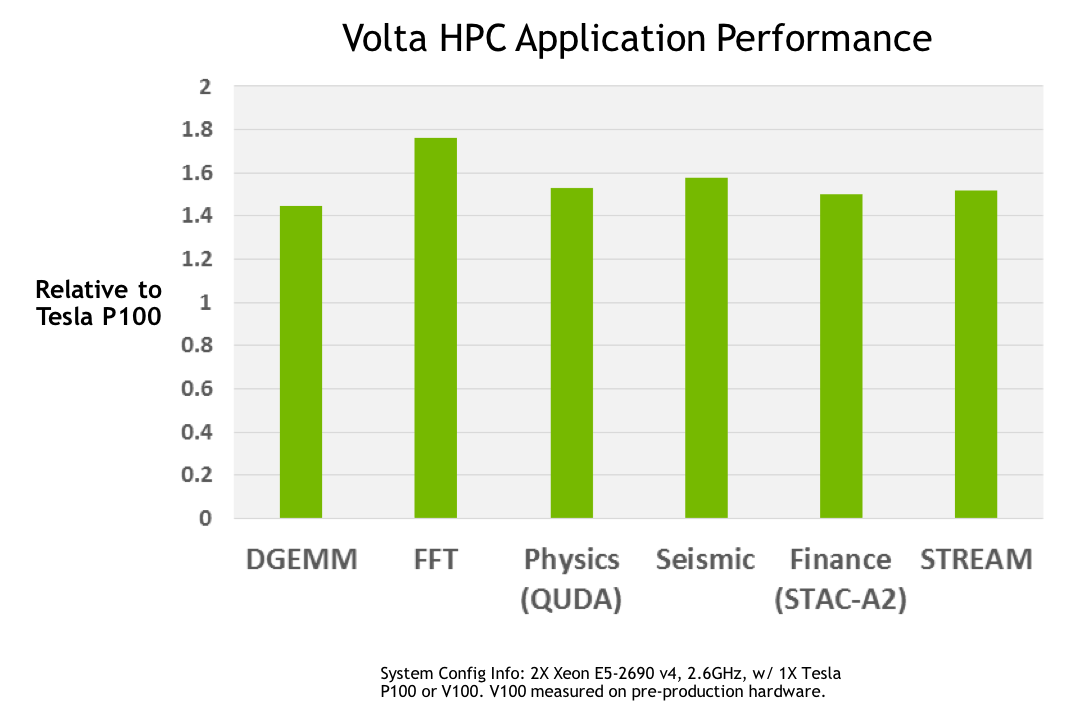
Darüber hinaus hat Nvidia bei Volta die Auslastung einer SM bei gemischten Workloads (Adressierungs- und Berechnungsaufgaben) verbessert. Auch das unabhängige Thread Scheduling soll einen Schritt nach vorne gemacht haben, um parallel laufende Threads besser synchronisieren zu können. Ein neuer kombinierter L1 Data Cache inklusive einem Shared-Memory-Subsystem soll zeitgleich die Performance erhöhen, den Programmieraufwand aber auch vereinfachen.
| Produkt | Tesla K40 | Tesla M40 | Tesla P100 | Tesla V100 |
|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GV100 (Volta) |
| Fertigung | 28 nm | 28 nm | 16 nm FinFET+ | 12 nm FFN |
| Transistoren | 7,1 Milliarden | 8,0 Milliarden | 15,3 Milliarden | 21,1 Milliarden |
| GPU-Größe | 551 mm² | 601 mm² | 610 mm² | 815 mm² |
| Streaming Multiprocessors | 15 | 24 | 56 | 80 |
| FP32-ALUs pro SM | 192 | 128 | 64 | 64 |
| FP32-ALUs (Shader) | 2.880 | 3.072 | 3.584 | 5.120 |
| FP64-ALU pro SM | 64 | 4 | 32 | 32 |
| FP64-ALUs | 960 | 96 | 1.792 | 2.560 |
| GPU Boost-Takt | 810/875 MHz | 1.114 MHz | 1.480 MHz | 1.455 MHz |
| Peak FP32-TFLOP/s | 5,04 | 6,8 | 10,6 | 15,0 |
| Peak FP64-TFLOP/s | 1,68 | 2,1 | 5,3 | 7,5 |
| Textureinheiten | 240 | 192 | 224 | 320 |
| Speicher-Interface | 384 Bit GDDR5 | 384 Bit GDDR5 | 4.096 Bit HBM2 | 4.096 Bit HBM2 |
| Speicherbandbreite | 288 GB/S | 288 GB/S | 720 GB/s | 900 GB/s |
| Speichergröße | Bis zu 12 GB | Bis zu 24 GB | 16 GB | 16 GB |
| L2-Cache | 1.536 KB | 3.072 KB | 4.096 KB | 6.144 KB |
| TDP | 235 Watt | 250 Watt | 300 Watt | 300 Watt |
Informationen zu den GeForce-Voltas gibt es noch keine
Informationen zum GeForce-Ableger von Volta gab es keine. Es muss klar sein, dass der GV100, wie auch der GP100, nicht den Weg in einen heimischen Desktop-PC finden wird. Dieser ist alleine aufgrund der Chipgröße und damit den aufzubringenden Kosten eine ausschließlich professionelle Lösung. Volta-GPUs für GeForce-Grafikkarten werden deutlich kleiner ausfallen (denkbar sind zum Beispiel 500 mm²). Im Laufe des ersten Halbjahrs 2018, möglicherweise auch noch im ersten Quartal, ist mit GeForce-Produkten auf Volta-Basis inklusive GDDR6-Speicher zu rechnen.
Die Nvidia Tesla V100 soll noch im Laufe des dritten Quartals erscheinen. Systeme anderer Anbieter mit der professionellen Lösung sollen im vierten Quartal folgen.
-
 Nvidia Tesla V100 (Bild: Nvidia)
Nvidia Tesla V100 (Bild: Nvidia)

