Intel Xeon SP: Mit Skylake-SP auf der Purley-Plattform gegen AMD Naples
2/3Die Architektur im Detail
Die Purley-Plattform wird Heimat für zwei Prozessorfamilien: Skylake und Cascade Lake. Cascade Lake wird im folgenden Jahr unter anderem Unterstützung für 3D XPoint bieten. Dies hatte Intel überraschenderweise bereits vor dem Start der heute veröffentlichten ersten Modelle offenbart – einmal mehr sorgen Verzögerungen für Verzug im ursprünglichen Plan.

Skylake-SP basiert auf Skylake
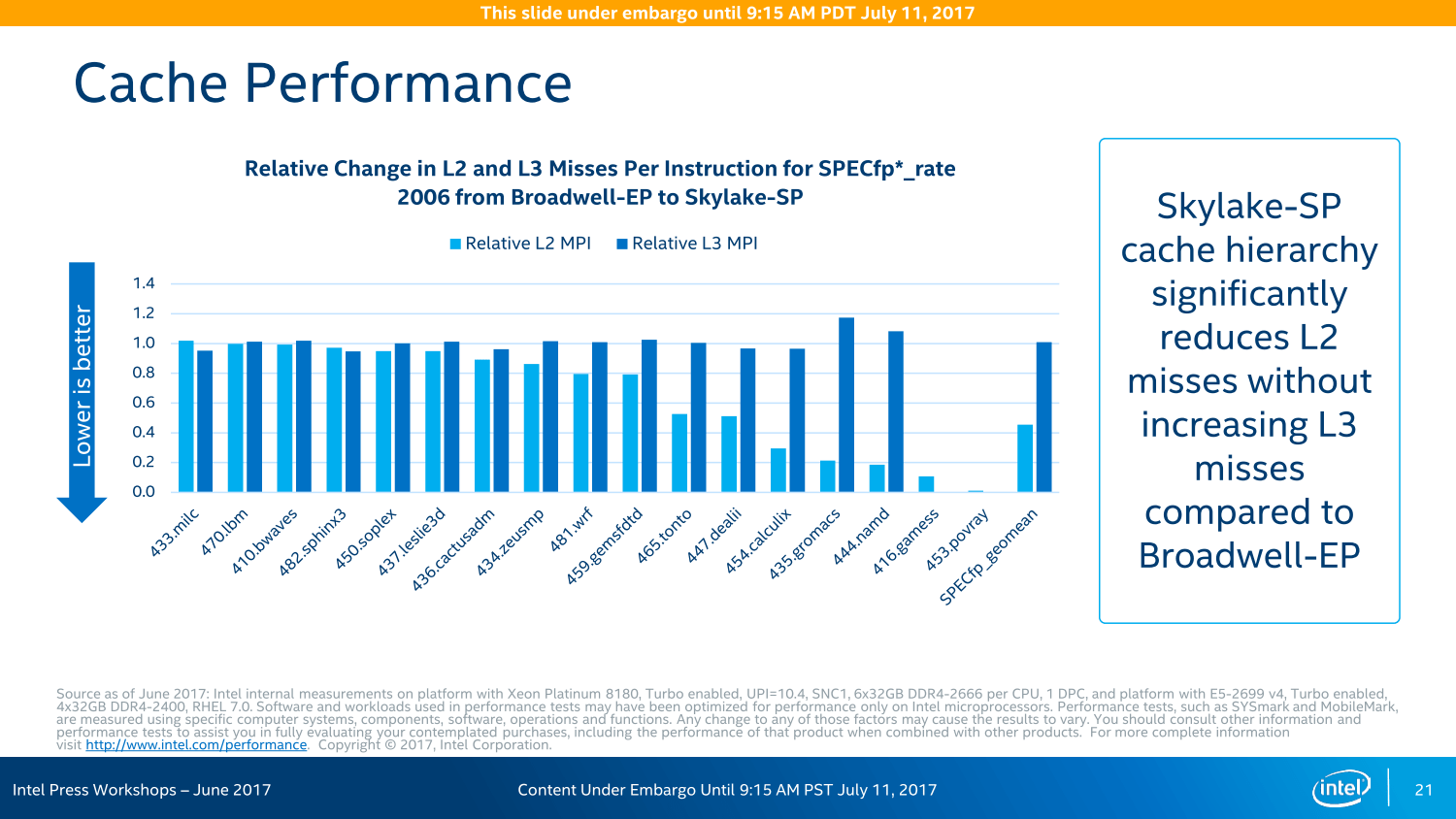
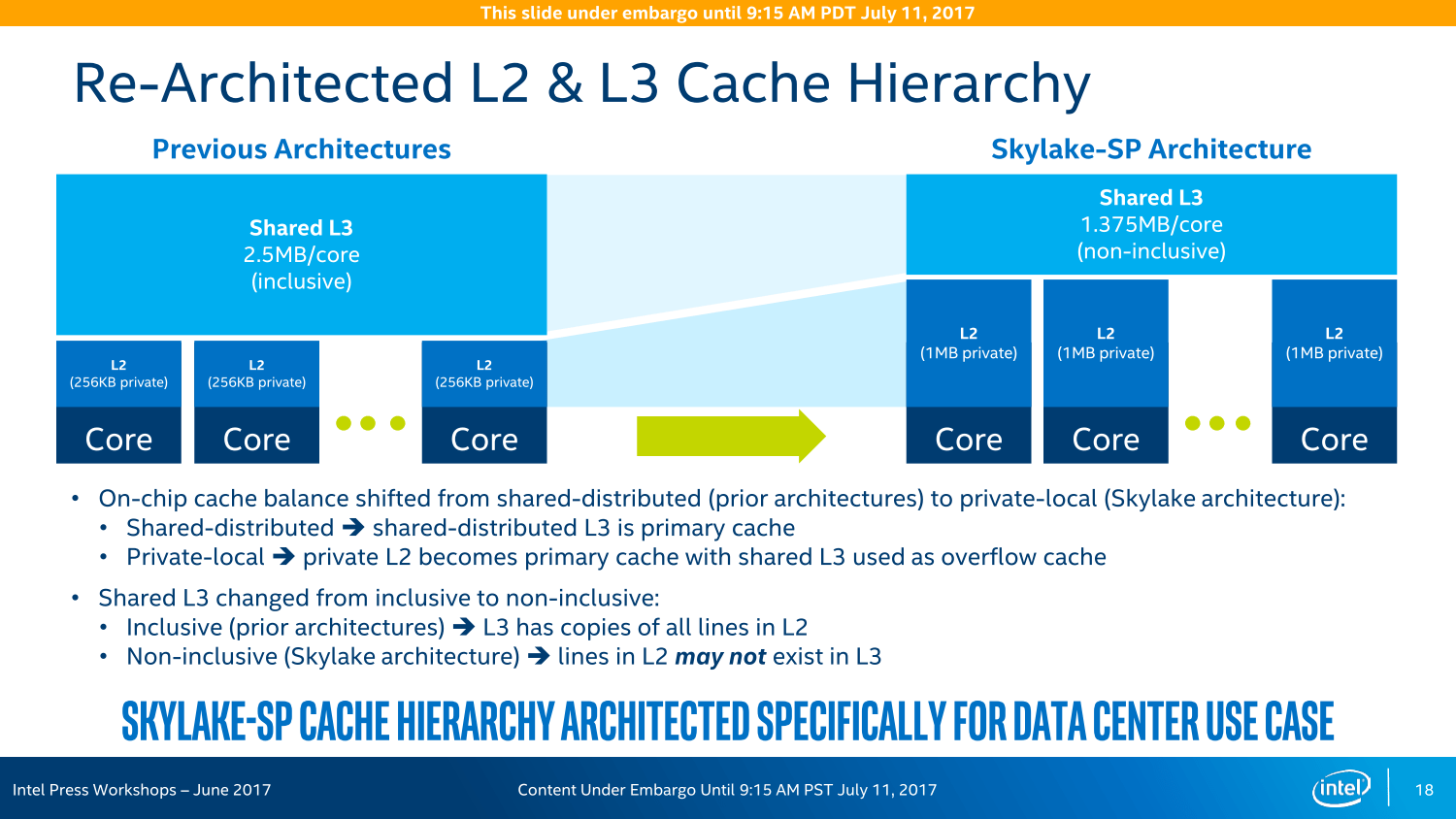
Heute startet das Produkt mit den Prozessoren auf Basis der Skylake-Architektur. Diese übernimmt alle Fortschritte der bereits aus dem Desktop- und Notebook-Bereich bekannten Architektur: Der original Skylake-Kern wird fast 1:1 mitgenommen, die zusätzlichen 768 KByte L2-Cache pro Kern sind beispielsweise separat hinzugefügt worden, auch eine zweite AVX-512-Einheit wurde „angeflanscht“. Insbesondere der zusätzliche L2-Cache in den größeren Blöcken lässt sich deshalb auch sehr gut auf dem Die-Shot erkennen.

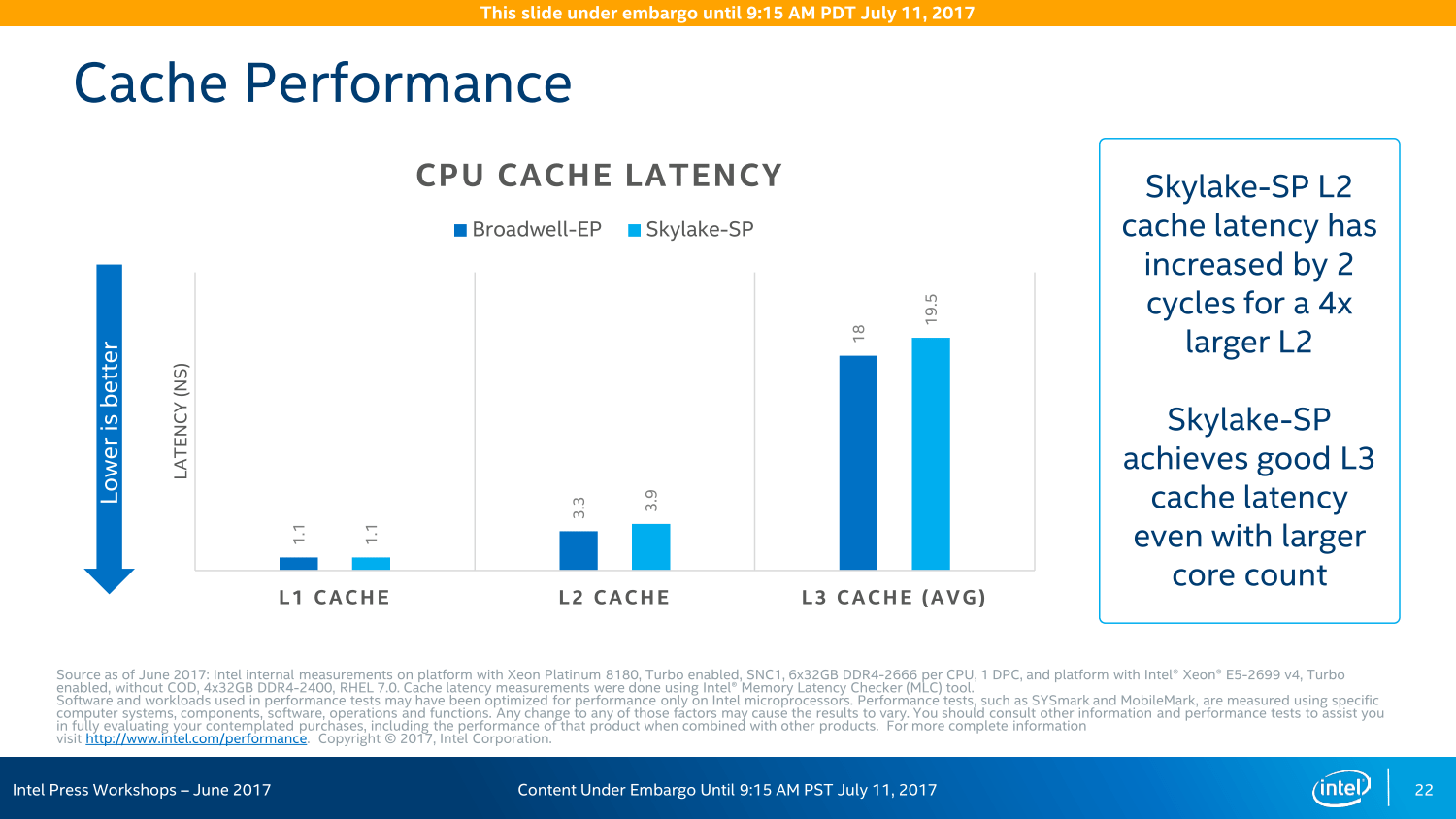
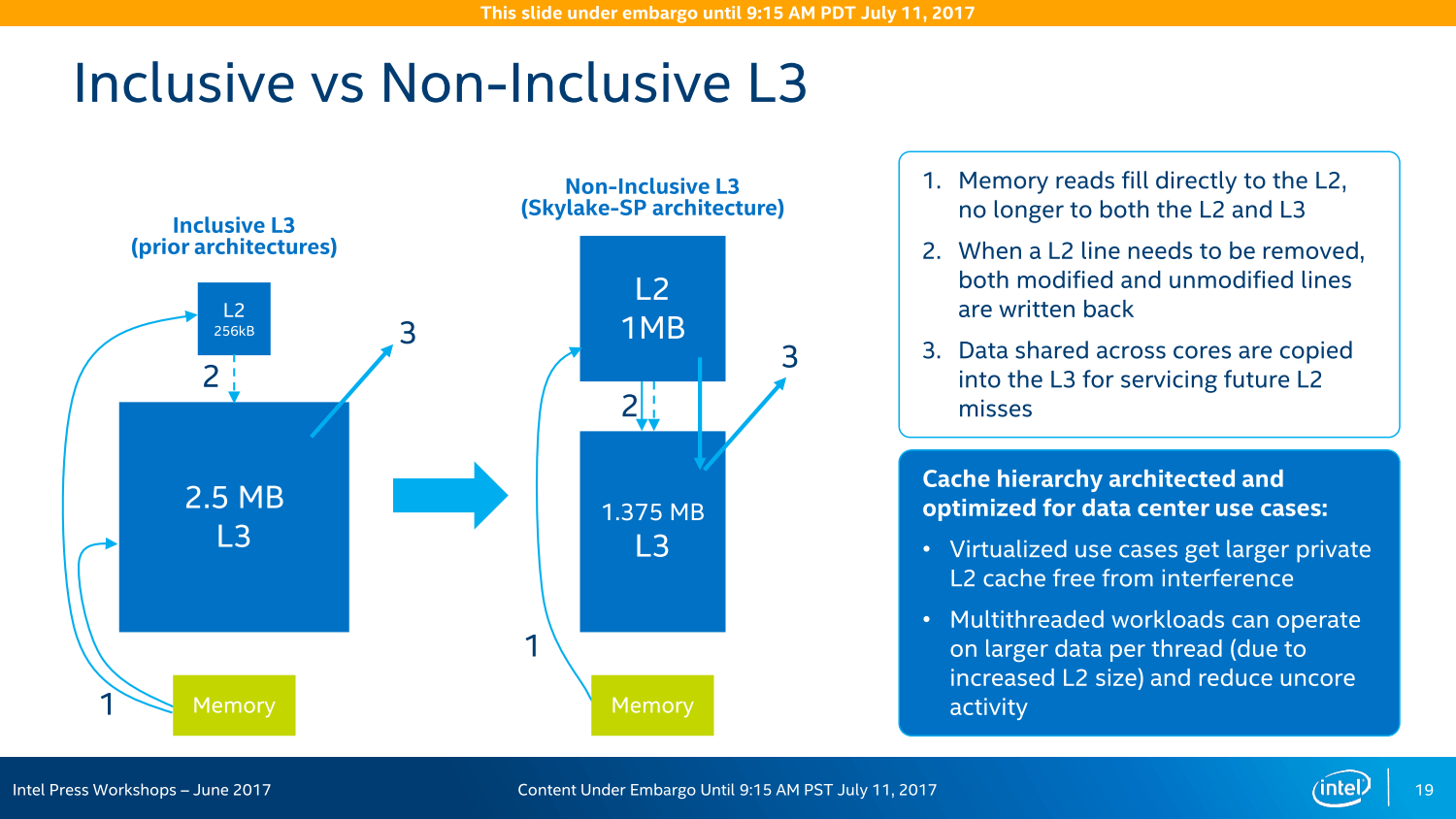
Während Intel Mitte Juni auf einer Veranstaltung in den USA betonte, dass beim AVX-512-Einsatz keine Unterschiede bei der Leistung existieren sollten, egal ob Port 0/1 oder Port 5 die Aufgabe übernehmen, sind es beim L2-Cache zwei zusätzliche Zyklen, wenn auf den neuen „externen“ Speicher zurückgegriffen wird. Doch unterm Strich soll die Rechnung trotzdem aufgehen. Der insgesamt 1 MByte große L2-Cache pro Kern soll zusammen mit dem ebenfalls gewachsenen L1-Cache in vielen Anwendungen helfen und mehr Leistung bieten, während der gleichzeitig kastrierte L3-Cache keine so großen negativen Auswirkungen haben soll. Natürlich ist dies nicht überall der Fall, wie die Desktop-Ableger Core i7 und Core i9 zeigen: Dort macht die neue Cache-Hierarchie und das Mesh-Interconnect Core X mit Skylake-X in Spielen einen Strich durch die Rechnung.
-
 Intel Xeon Architecture Deep Dive (Bild: Intel)
Intel Xeon Architecture Deep Dive (Bild: Intel)
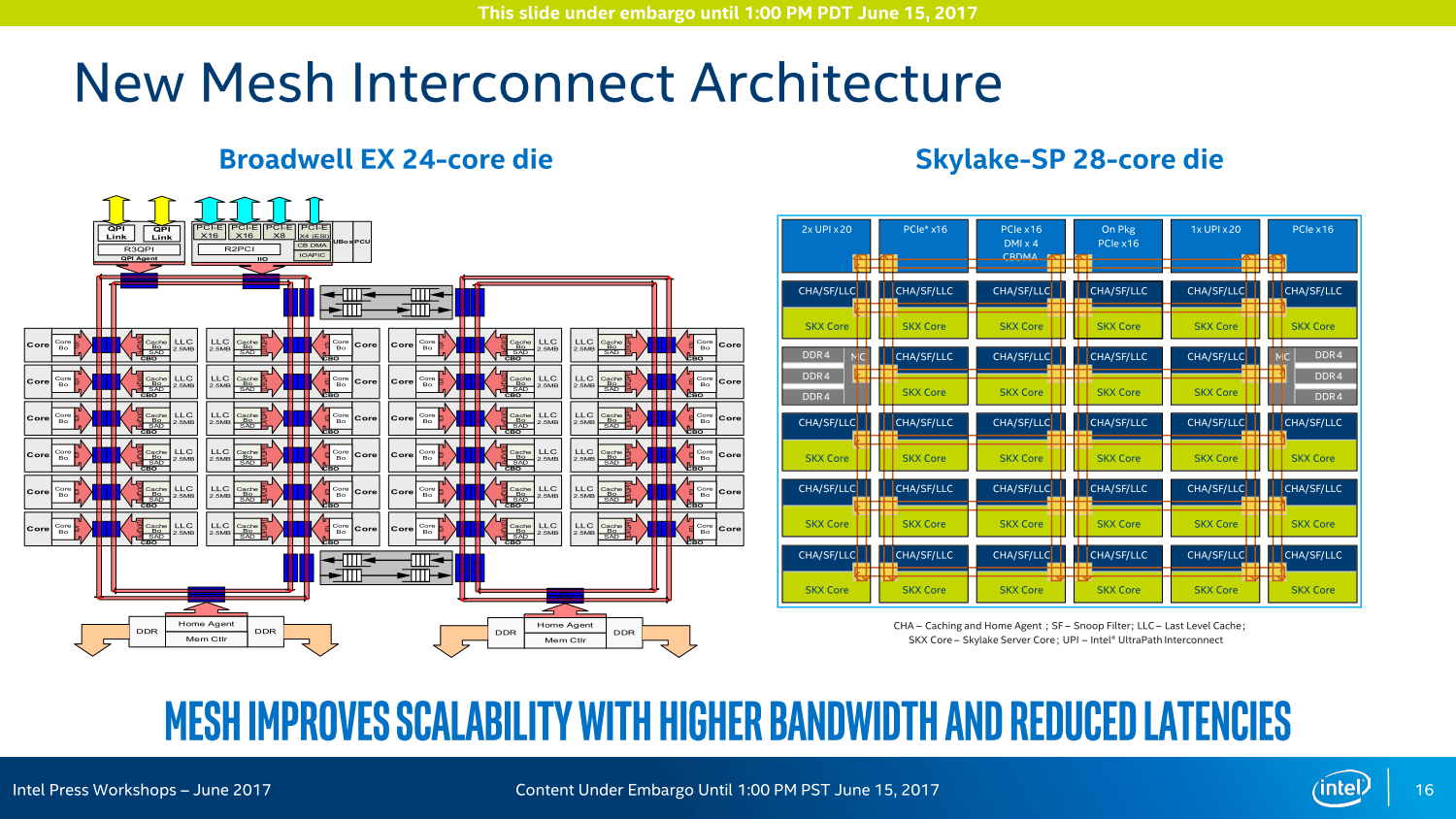
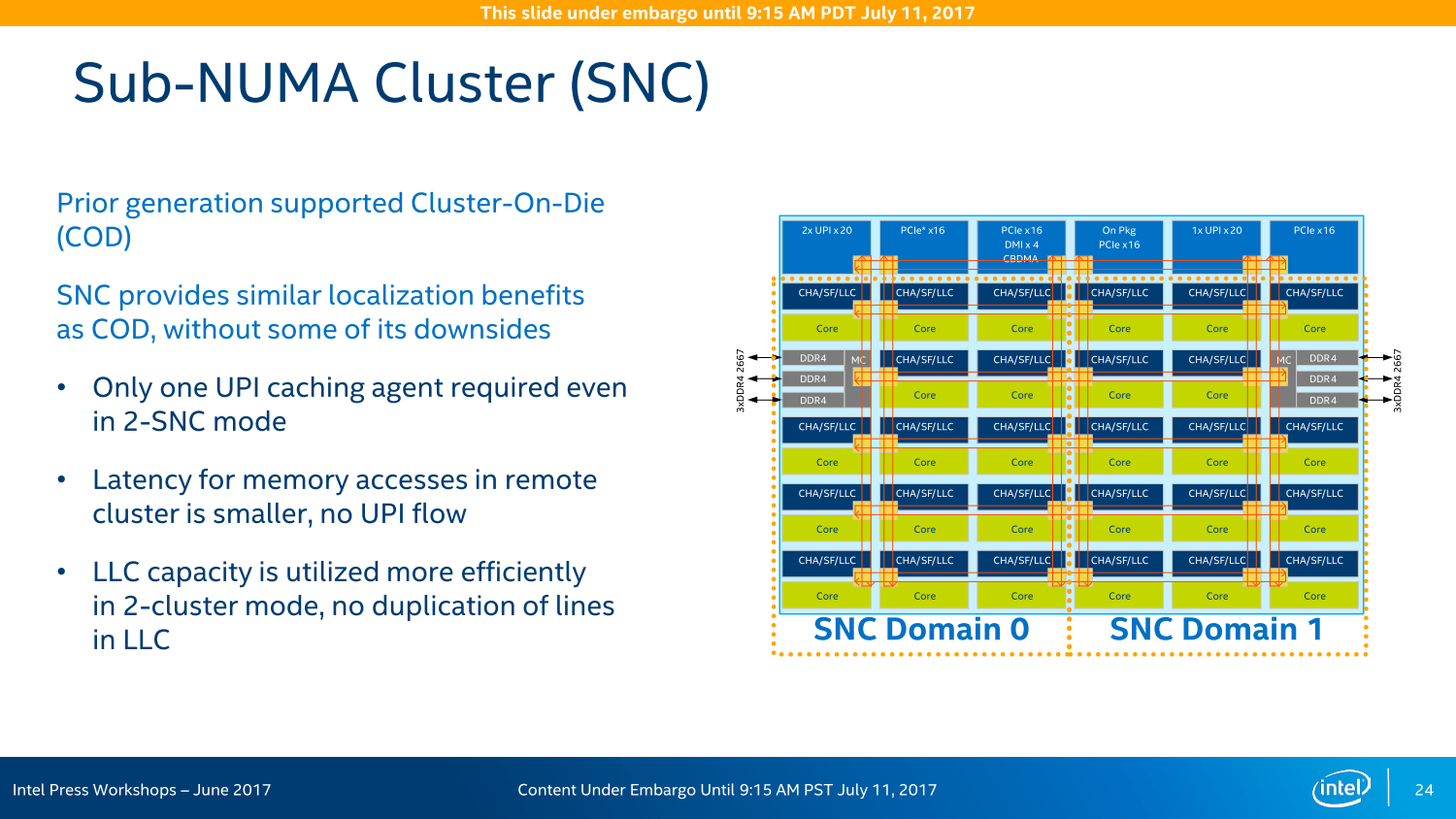
Das Mesh-Interconnect sorgt für die Kommunikation und den Datenaustausch
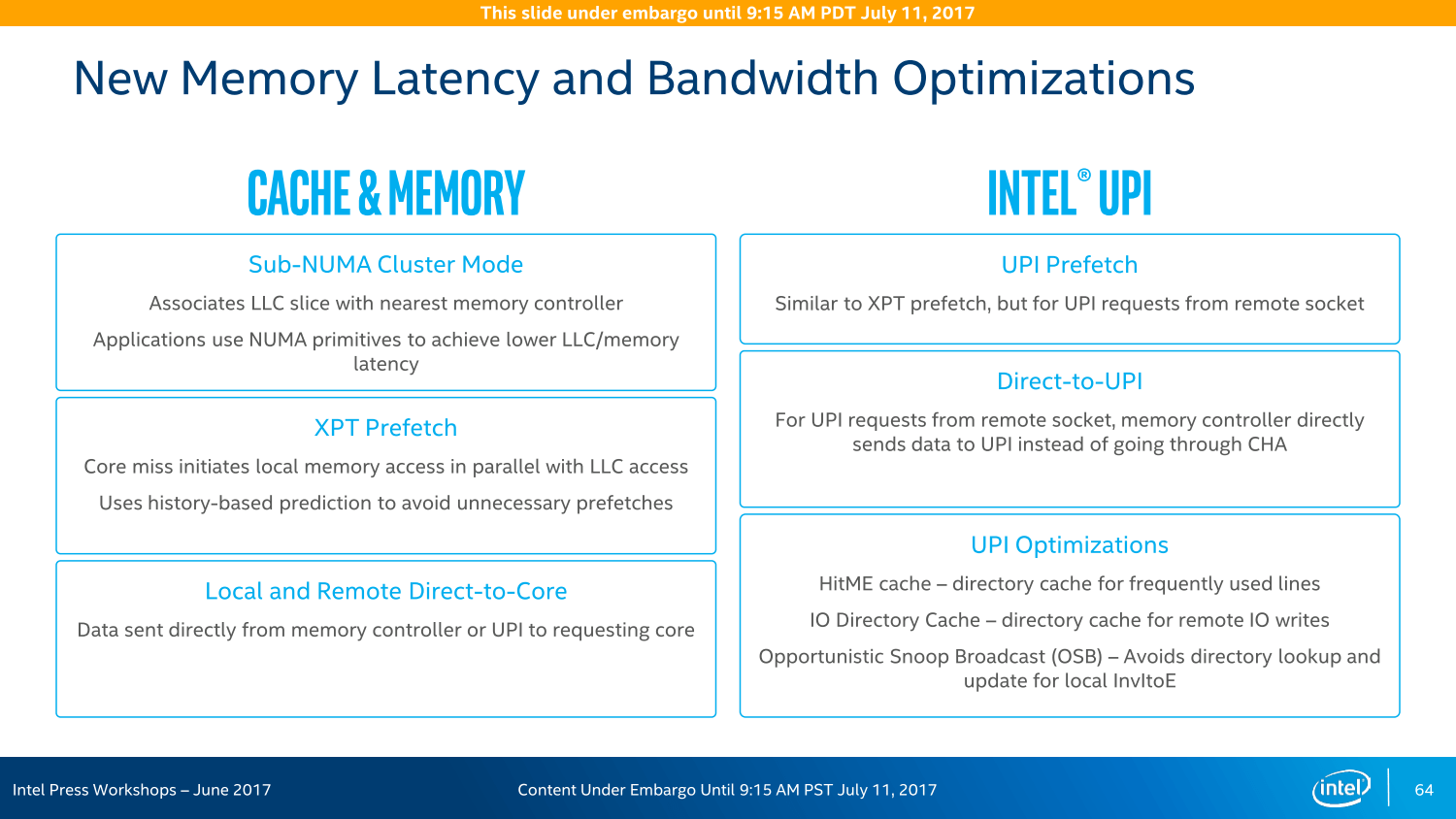
Das Mesh-Interconnect ist die gewichtigste Neuerung bei den Server-Varianten mit Skylake-Kernen. Wie bereits vor einigen Wochen angedeutet, hat Intel diese Technologie bei Xeon Phi bereits ausprobiert, nun kommt es großflächig zum Einsatz. Das Ziel: Eine deutlich höhere Bandbreite bei geringerer Leistungsaufnahme zur Kommunikation zwischen den Kernen, der Ring-Bus in mehrfacher bi-direktionaler Ausführung sei bei Broadwell-EP/EX am Ende gewesen.
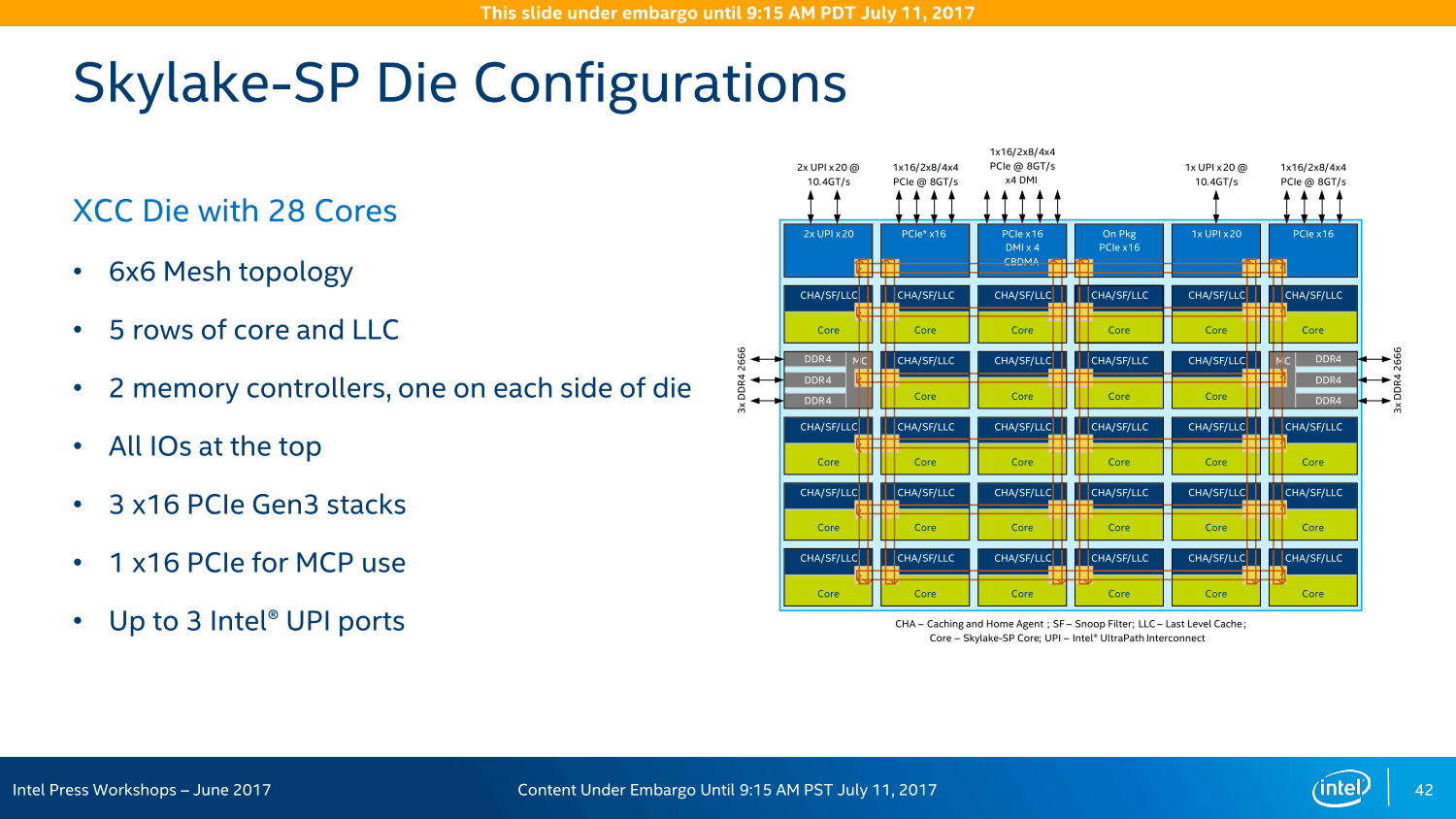
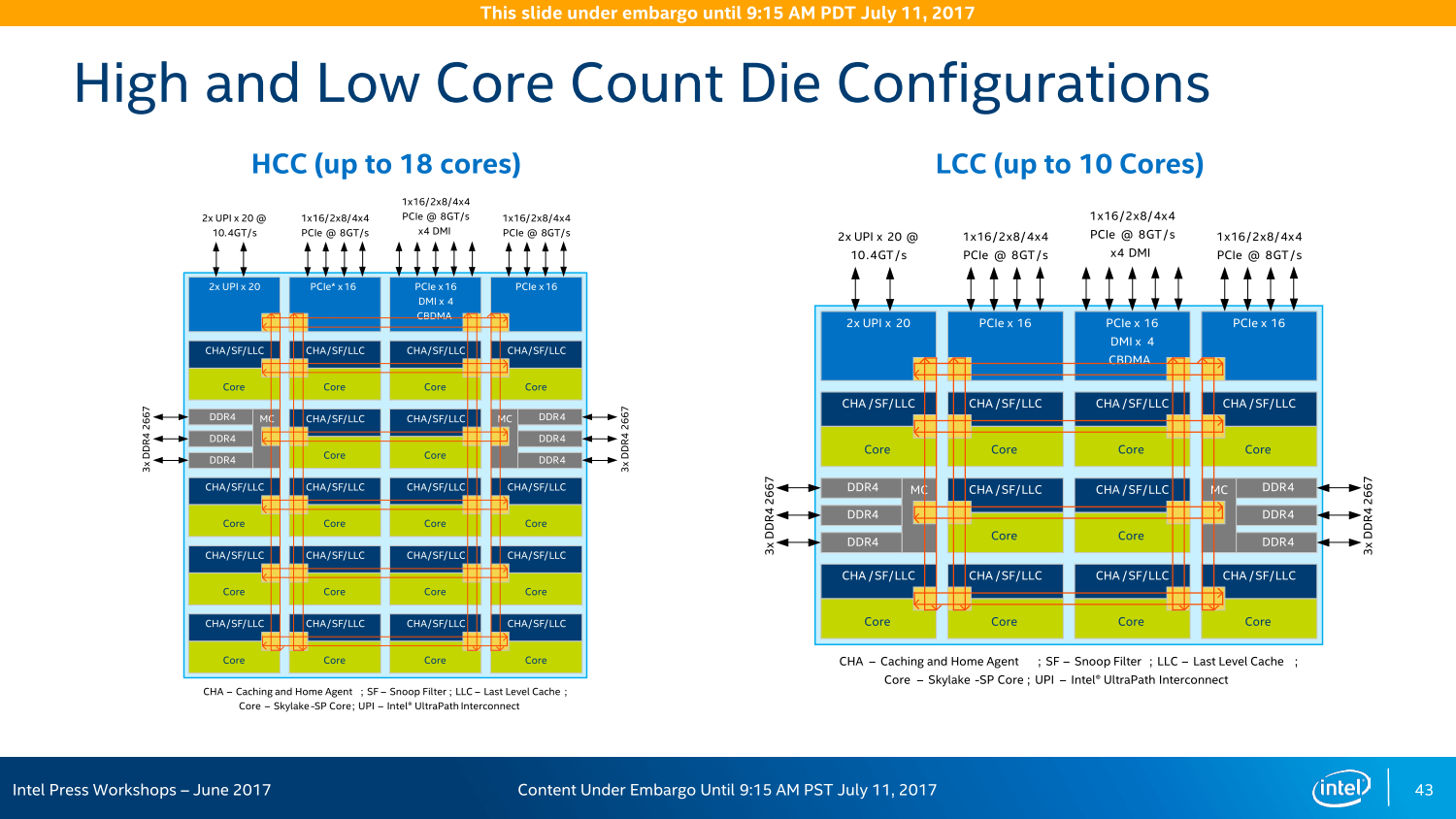
Unterschiedliche Kerne: XCC, HCC und LCC
Im Flaggschiff (XCC, eXtreme Core Count) mit bis zu 28 Kernen gibt es fortan eine 6 × 6-Anordnung: Fünf Reihen sind für Kerne und Caches vorgesehen und umfassen auch die beiden Speichercontroller. Alle I/O-Anschlüsse sind an der Oberseite aufgereiht, wozu in erster Linie die 48 PCIe-Lanes aber auch die neuen UPI-Ports in dreifacher Ausführung zählen.
Beim High Core Count (HCC) mit mehr als 10 und maximal 18 Kernen ändert sich der Aufbau in der Form, dass die mittleren beiden Spalten „entfernt“ werden, eine 4 × 6-Anordnung entsteht, dem zum Opfer fallen ein Mal UPI, PCIe & Co sind aber weiterhin im Maximalausbau vertreten. Beim LCC (Low Core Count) mit maximal zehn Kernen werden dann noch die Reihen von unten her gestutzt, es entsteht ein Aufbau nach dem Schema 4 × 4. Die Features entsprechen weiterhin dem HCC-Aufbau.
Wie groß die einzelnen Dies sind und wie viele Transitoren sie fassen, bleibt neuerdings ein Betriebsgeheimnis. Intel erklärt, dass daraus ohnehin nur falsche Schlussfolgerungen gezogen würden. Das deutet letztendlich allerdings auf tendentiell größere Dies mit einer geringeren Anzahl an Transistoren im Vergleich zu den Mitbewerbern hin – genau damit hatte AMD bereits geworben.
-
 Intel Xeon Architecture Deep Dive (Bild: Intel)
Intel Xeon Architecture Deep Dive (Bild: Intel)
Mesh-Interconnect mit Latenzen abhängig vom Weg
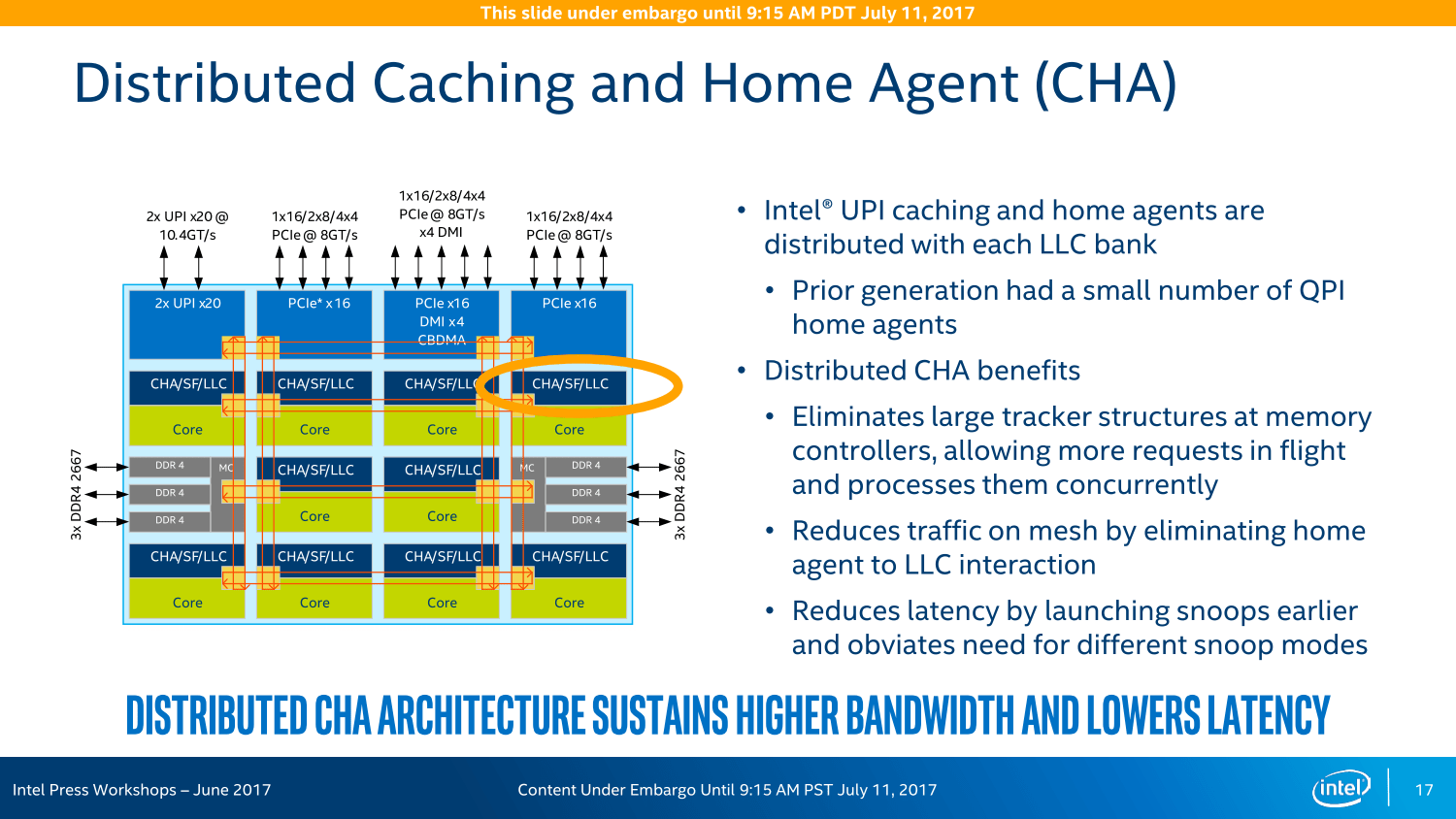
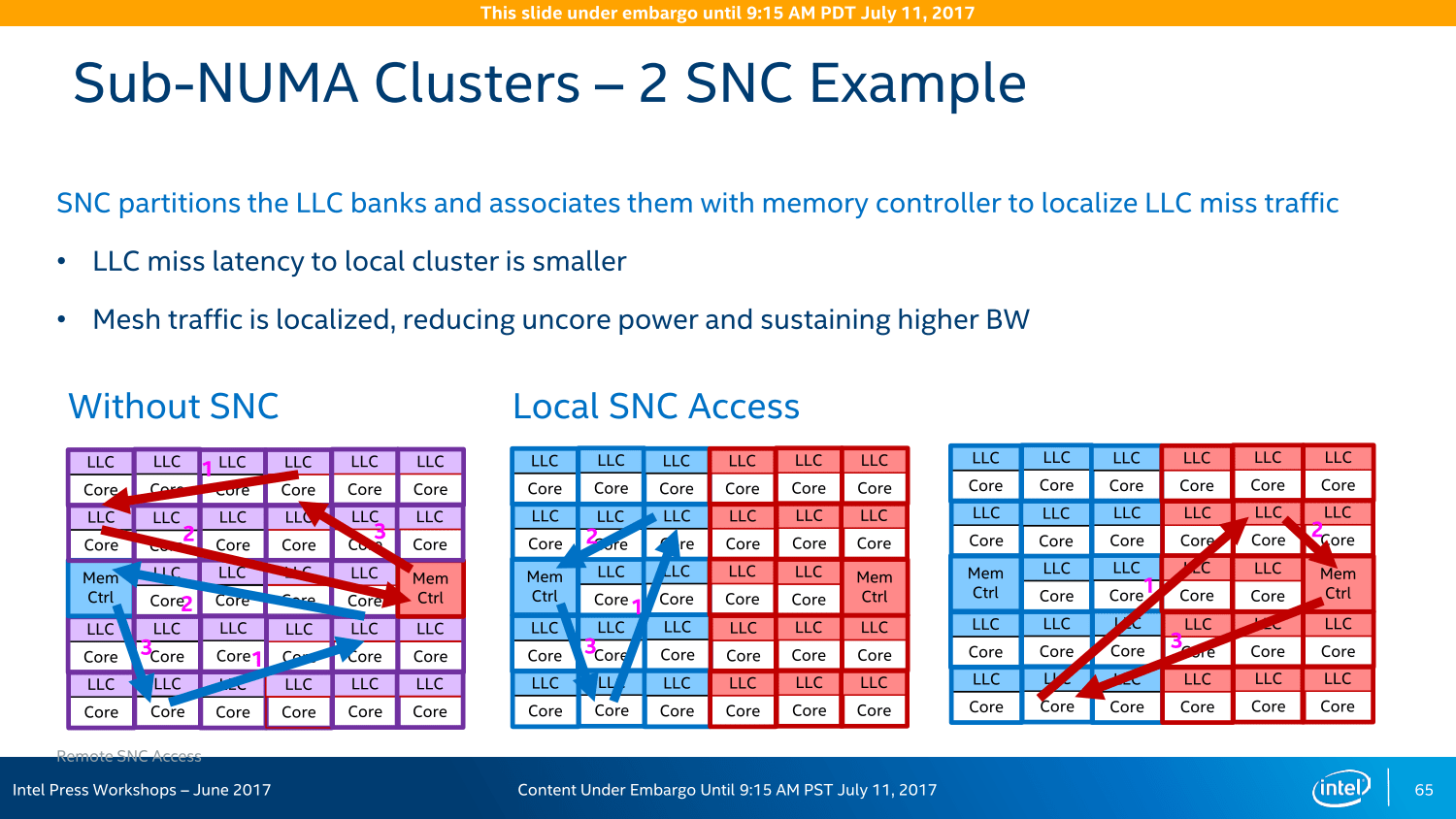
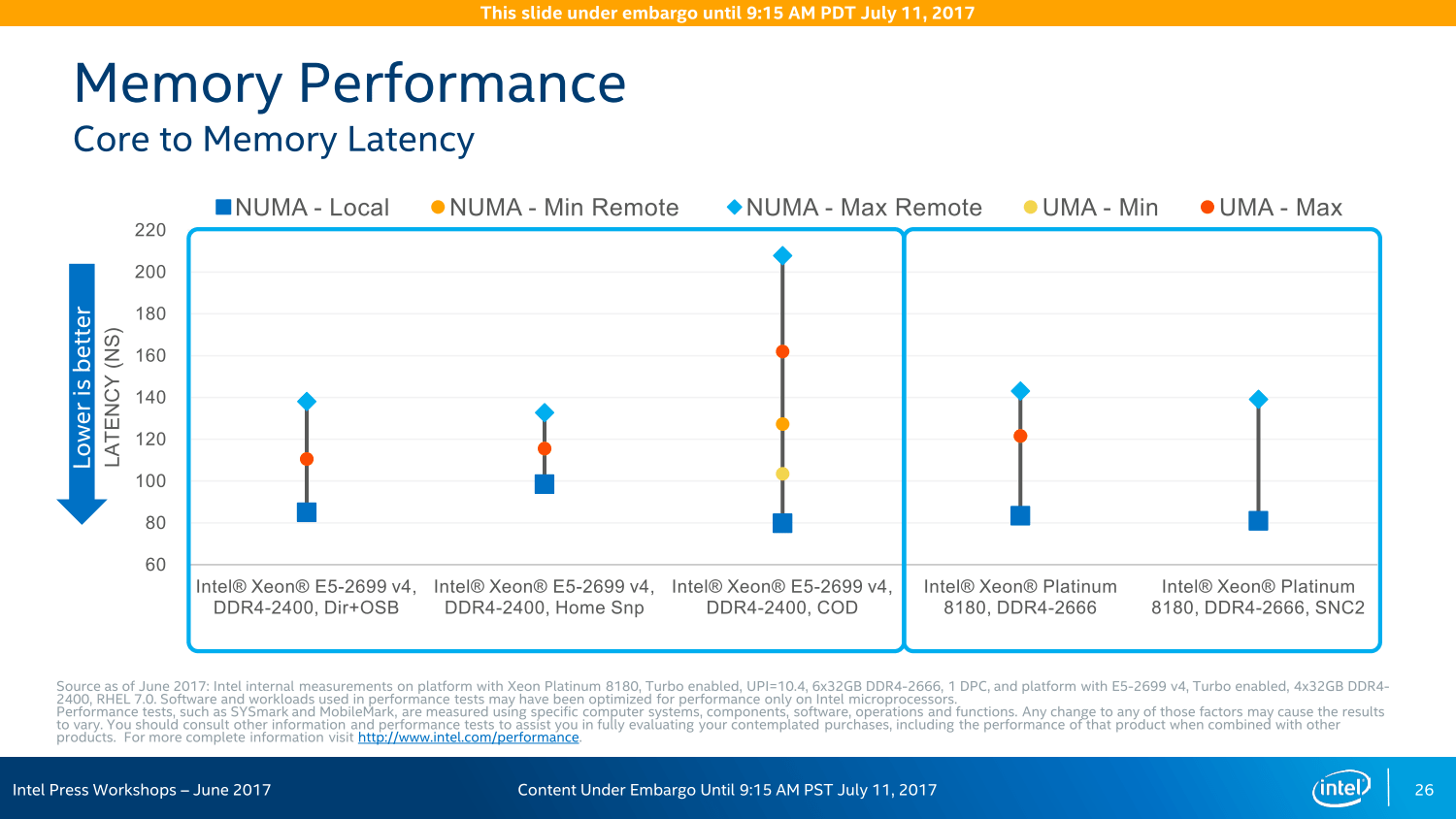
Am Ende ist es alles eine Frage der Latenzen und Taktzyklen. Intel betont, dass diese anders ausfallen als bei den Vorgängern. Das Mesh-System arbeitet immer mit einem Takt von 1,8 bis 2,4 GHz, alle Abfragen/Auslieferungen sind multidirektional ausgelegt und nehmen so immer den kürzesten Weg. Dieser dauert je nach Entfernung aber eine gewisse Zeit: Vertikal mit jeder Reihe ein Cycle, vom Kern zum L3-Cache sind es maximal vier Cycles. Horizontal sieht das anders aus, dort wandern die Daten teilweise über längere Strecken, die Rechnung läuft nach dem Schema 1+3+1+3+ ... ab. Der LCC-Ableger hat demnach unter Umständen eine höhere Performance, weil die Wege kürzer sein können. Um dem wiederum entgegenzuwirken, gibt es die Option auf eine Cluster-Bildung in den größeren Varianten.
UPI löst QPI ab, Speichercontroller wächst
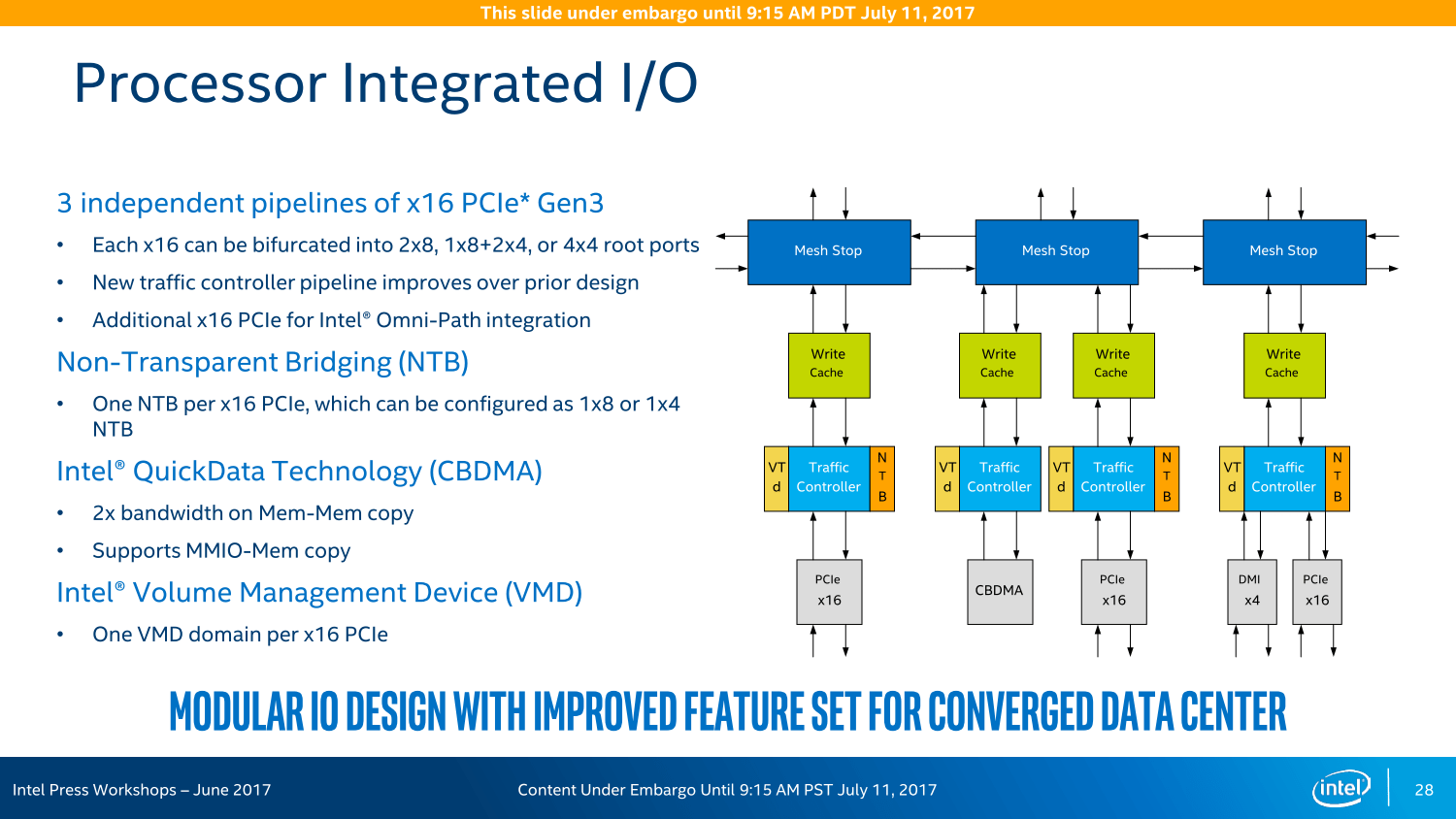
Der Nachfolger des Quick Path Interconnect (QPI) als Kommunikationsweg zwischen den Prozessoren in einem System ist Ultra Path Interconnect (UPI). Dieser ist aber nicht nur eine leistungsstärkere Version des Vorgängers mit nun 10,4 statt bisher maximal 9,6 GT/s, er ist von Grund auf neu entwickelt worden. Damit wird laut Intel ein weiterer Flaschenhals der Plattform beseitigt, denn UPI bietet nicht nur höhere Bandbreite sondern verbraucht auch deutlich weniger Energie.
-
 Intel Xeon Architecture Deep Dive (Bild: Intel)
Intel Xeon Architecture Deep Dive (Bild: Intel)
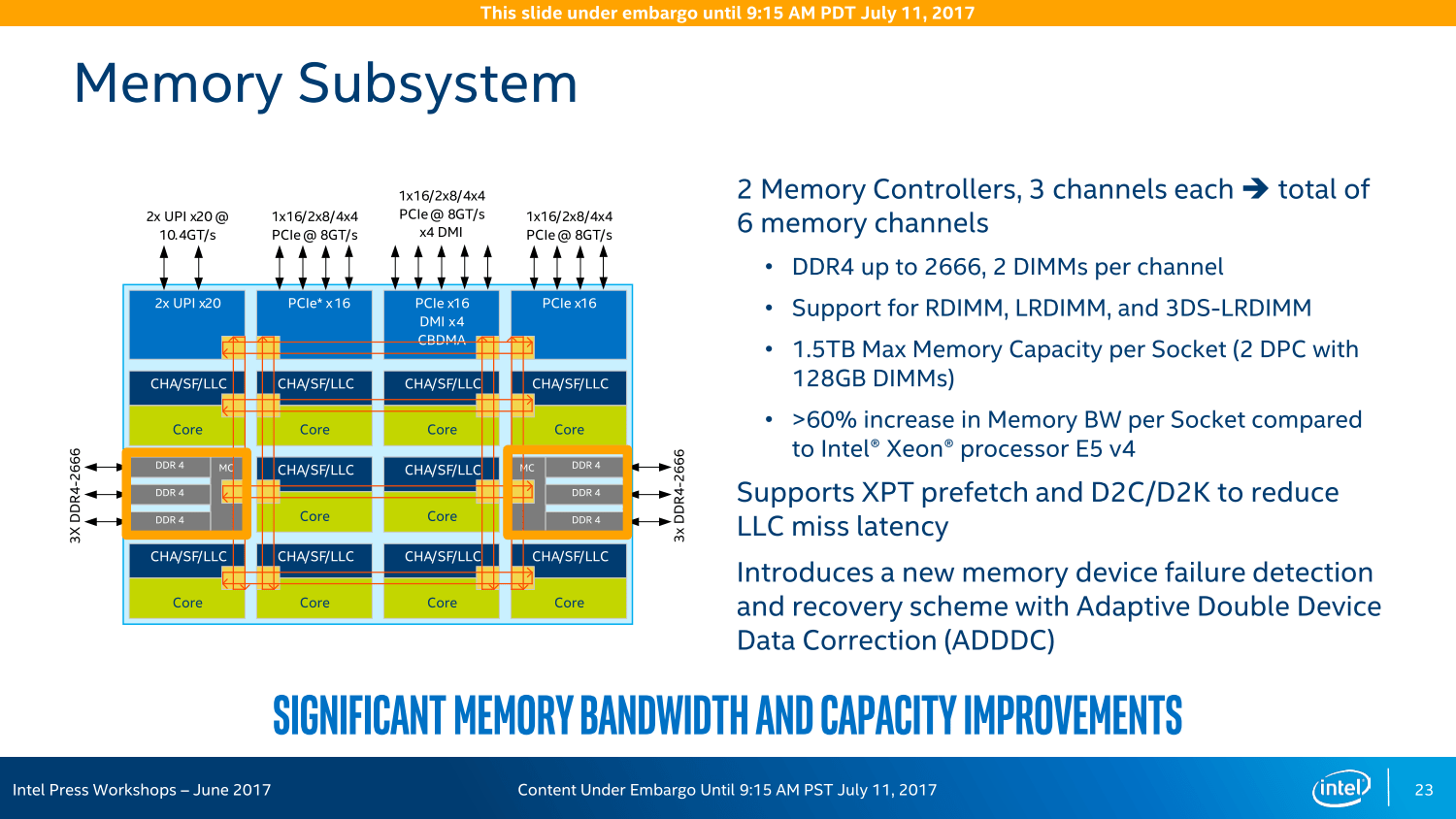
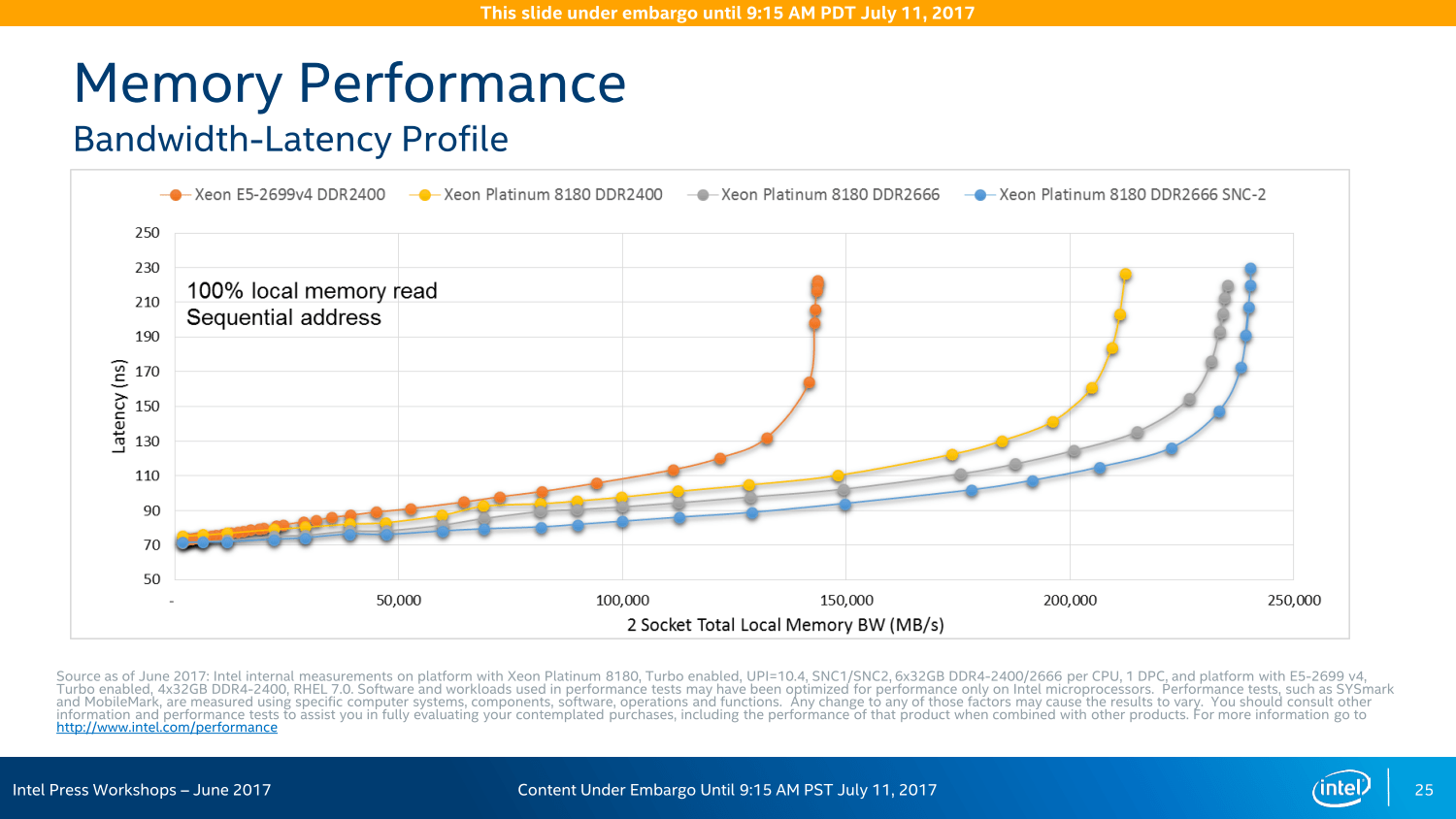
Der Speichercontroller wurde ebenfalls überarbeitet, besonders deutlich an der Erhöhung der Kanäle um 50 Prozent erkennbar. Gleichzeitig steigt auch die unterstützte Speicherfrequenz, DDR4-2666 ist über sechs Speicherkanäle in einer Größe von bis zu 1,5 TByte pro Prozessor verfügbar – allerdings nur bei ausgewählten M-Prozessoren.
Unterm Strich soll die Speicherbandbreite um über 60 Prozent gegenüber dem Vorgänger zulegen, zeitgleich kommt mit der Adaptive Double Device Data Correction (ADDDC) ein zusätzliches Feature zur Fehlerkorrektur zum Einsatz.
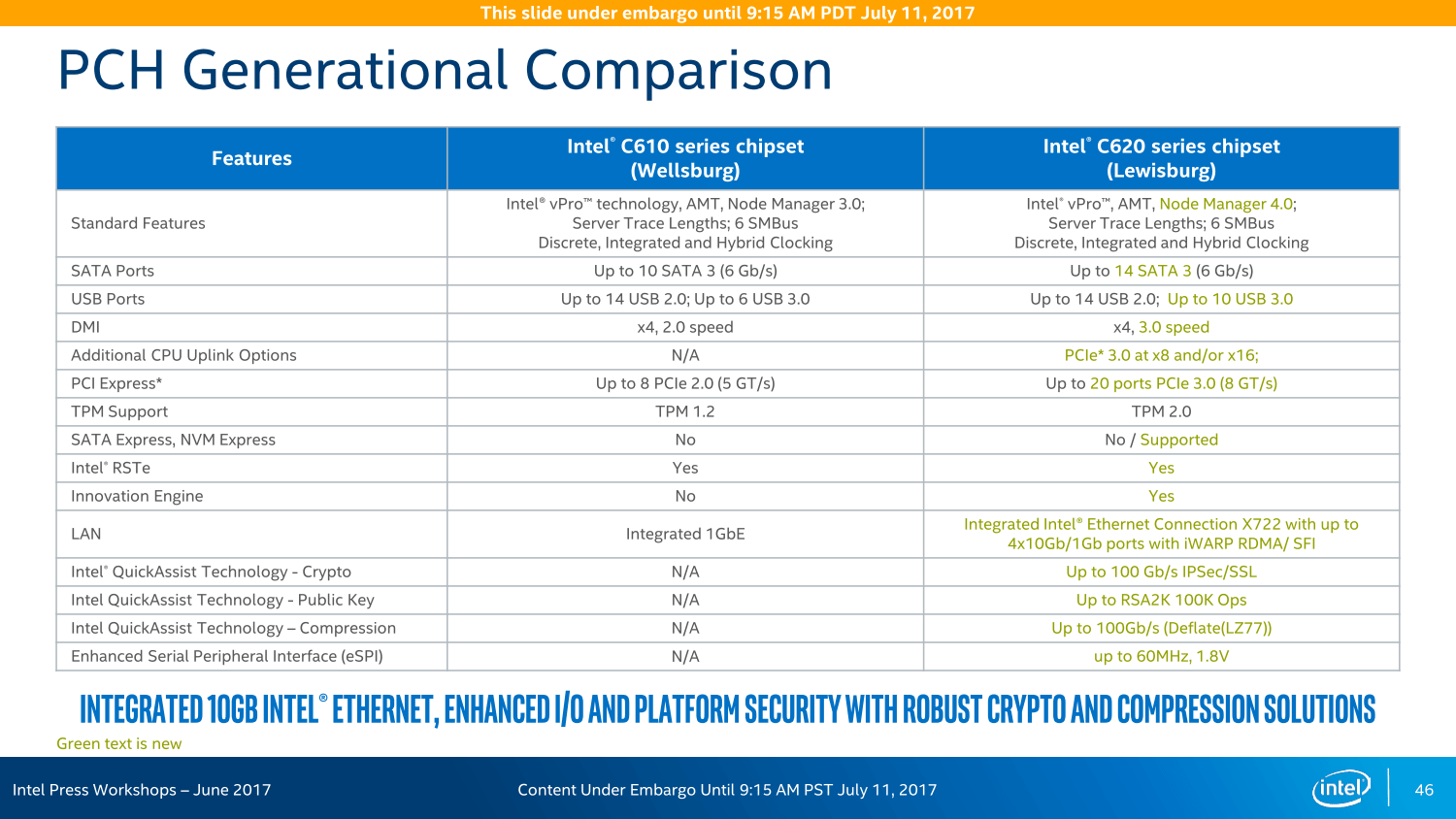
Lewisburg-Chipsatz als C620-Familie
Der Chipsatz ist ebenfalls kaum mehr mit dem Vorgänger vergleichbar, denn auch dort ist alles neu. Lewisburg stellt nun die aktuelle Entwicklung für den Servermarkt dar und wird dementsprechend auch in 14 nm gefertigt.
-
 Intel Xeon Architecture Deep Dive (Bild: Intel)
Intel Xeon Architecture Deep Dive (Bild: Intel)

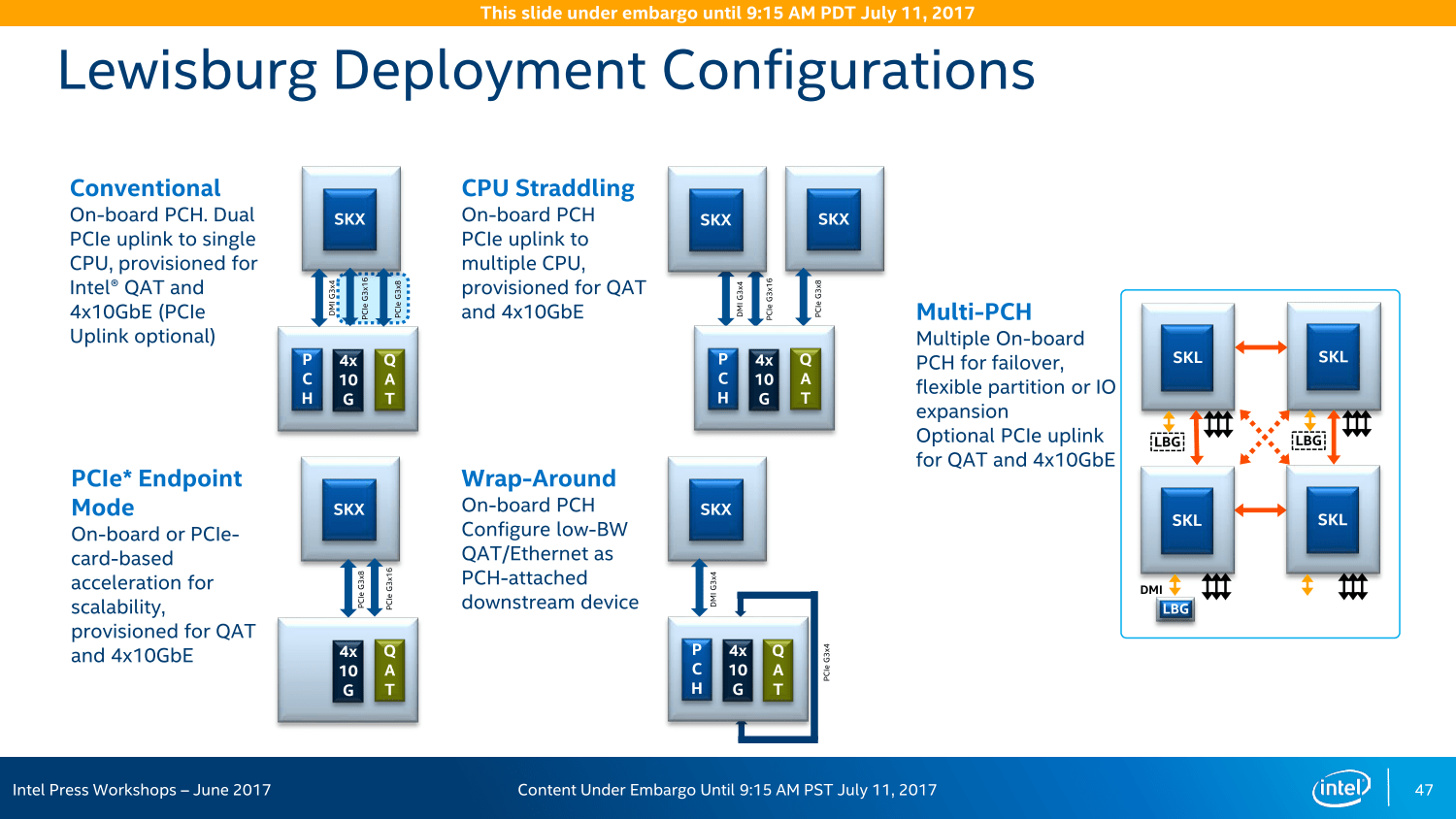
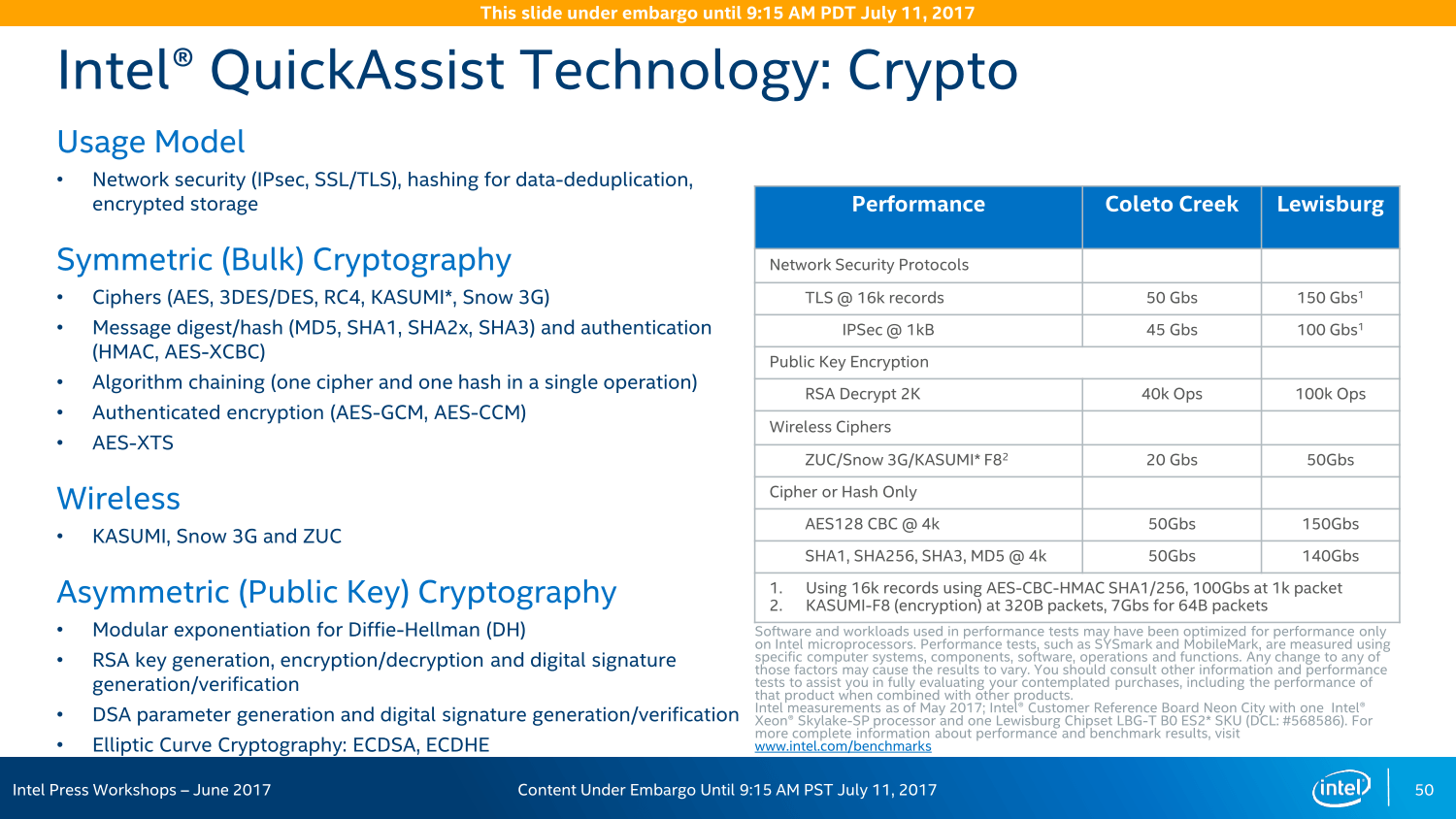
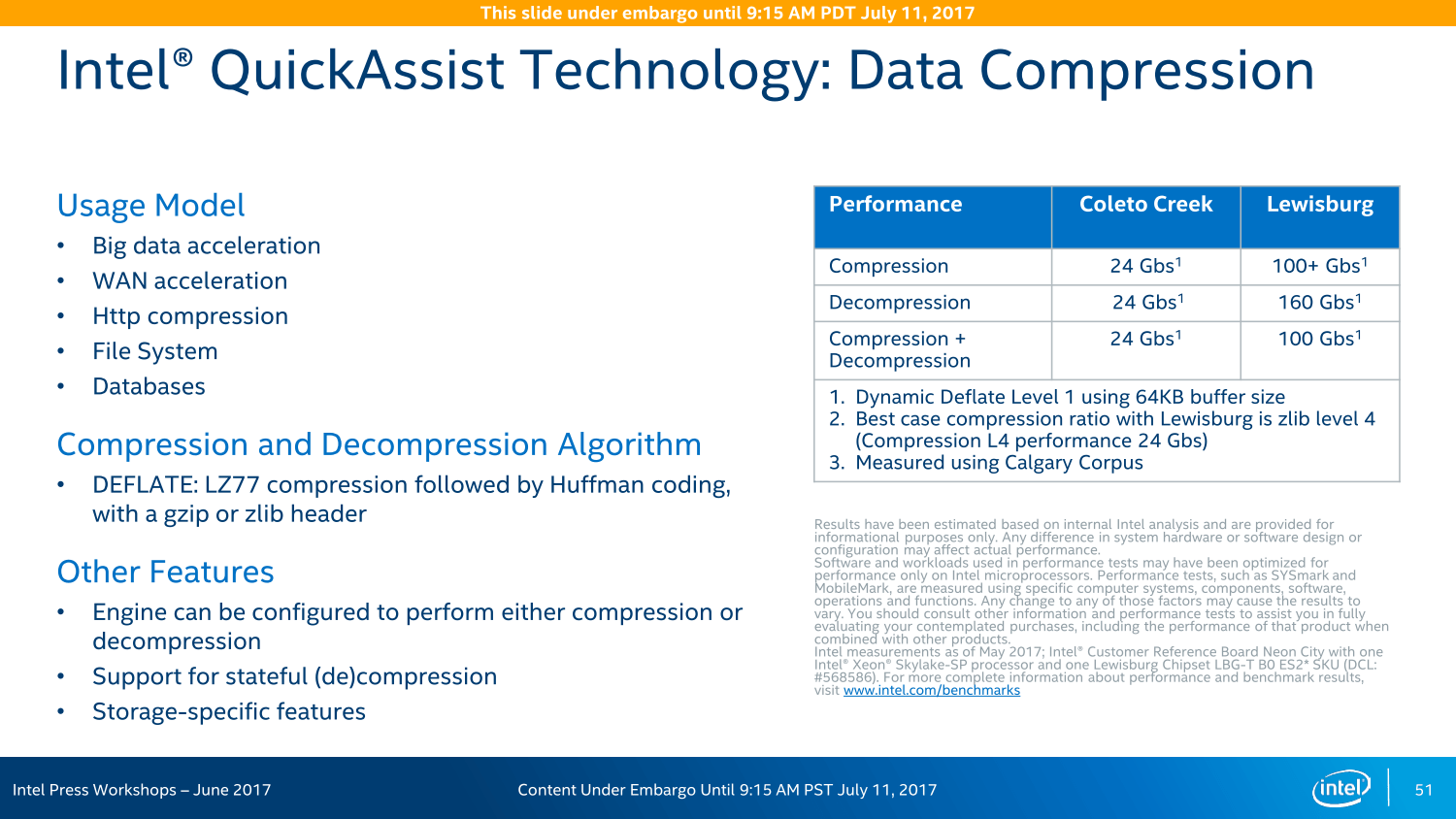

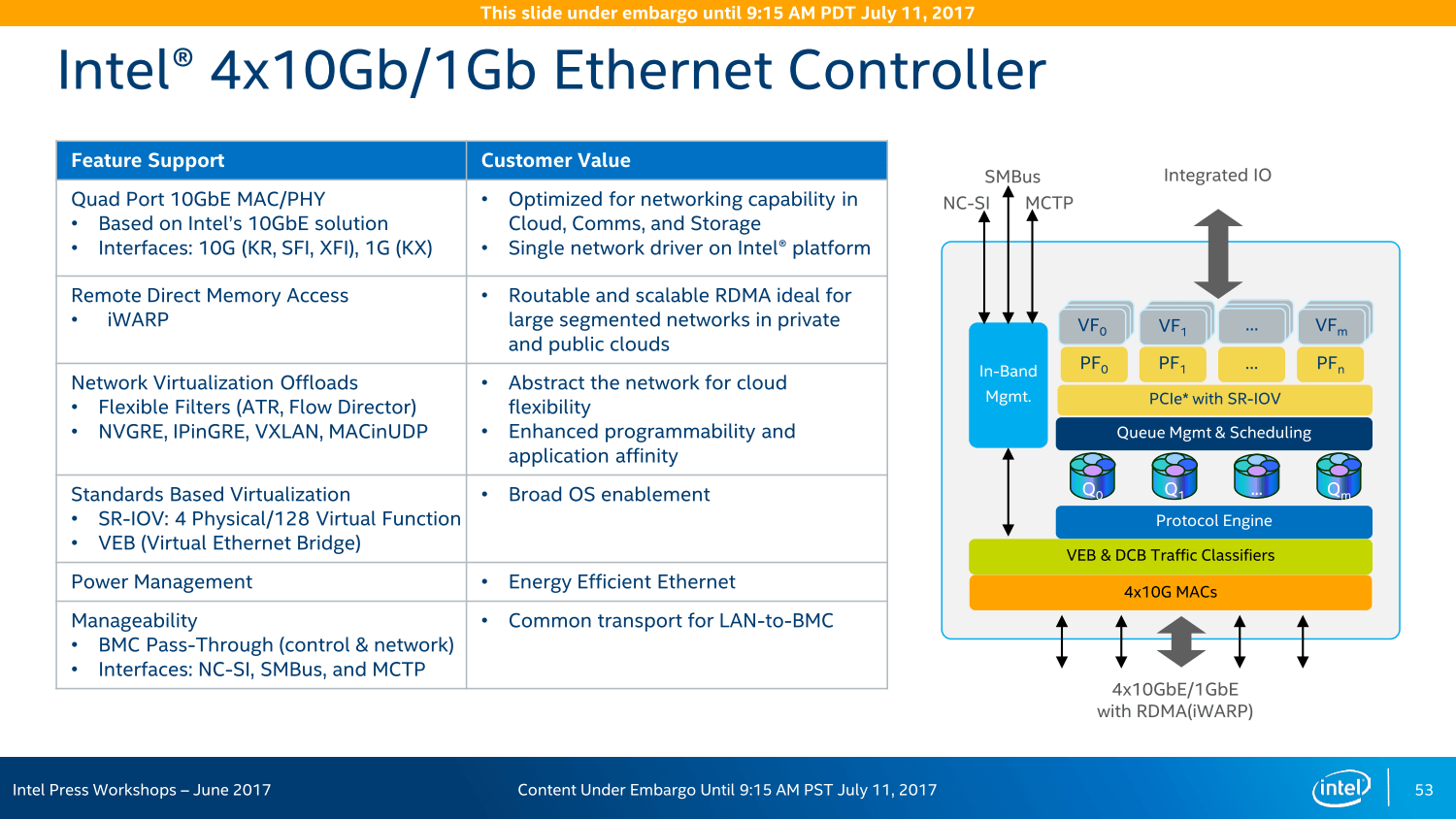
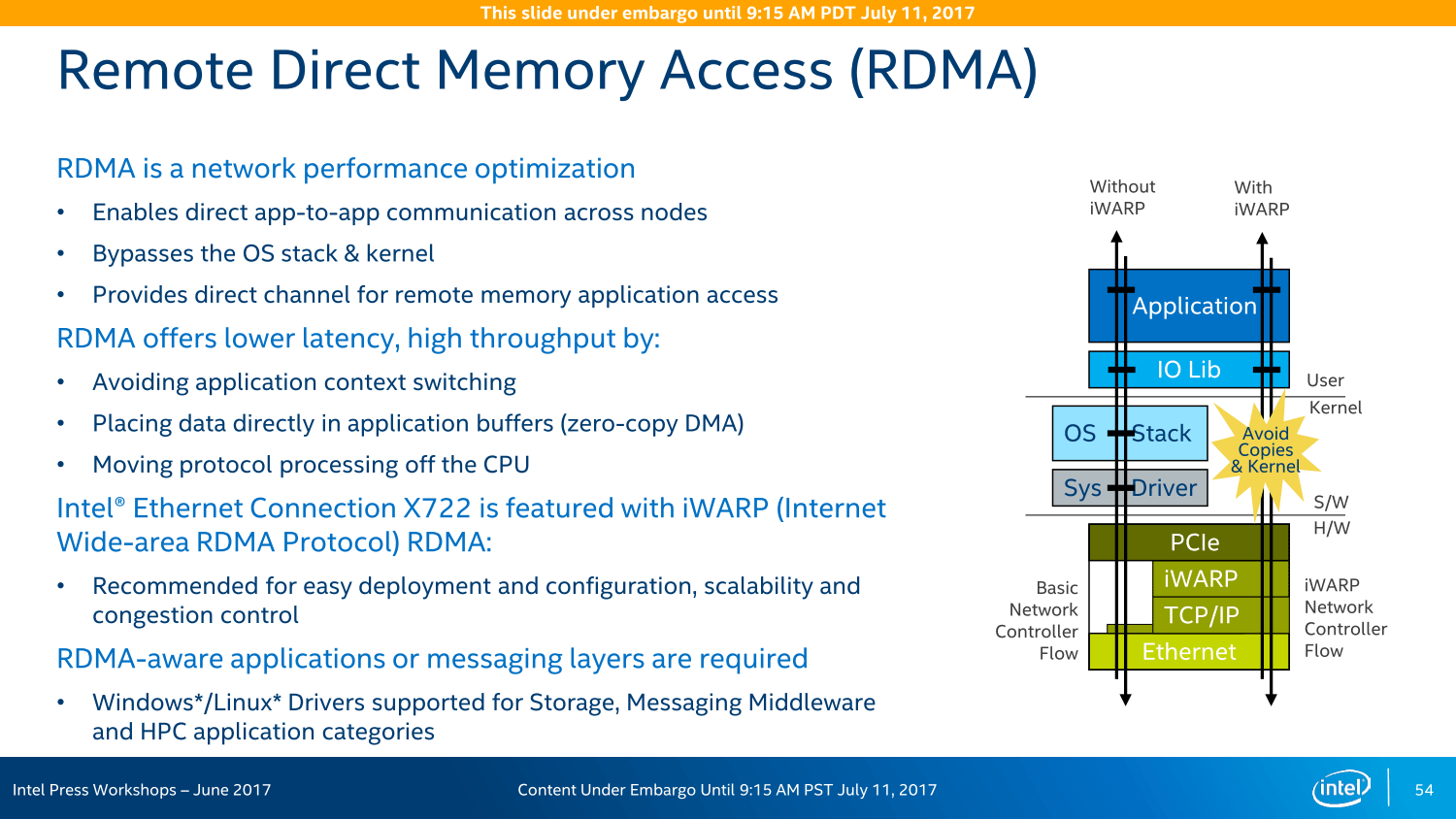


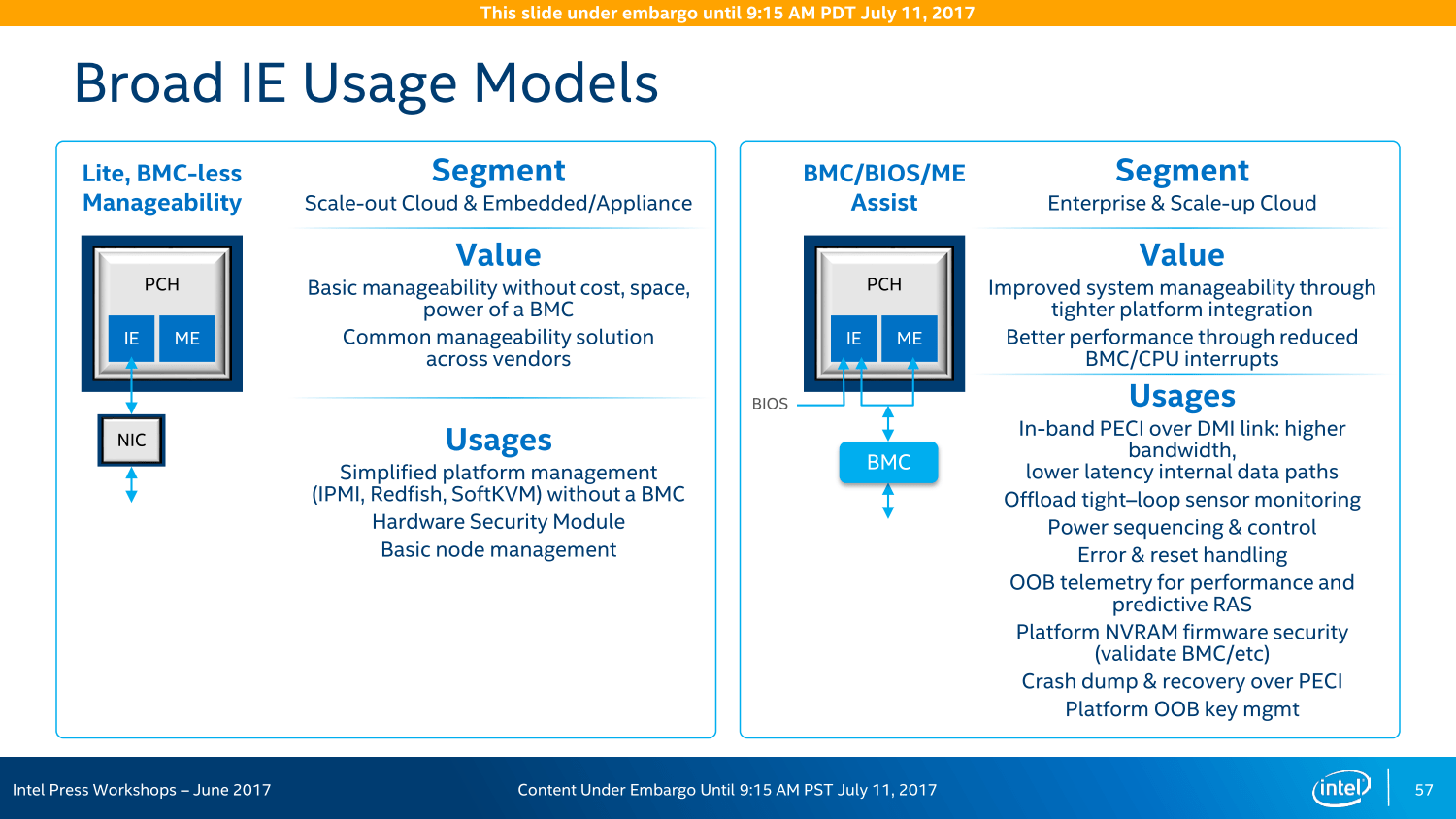
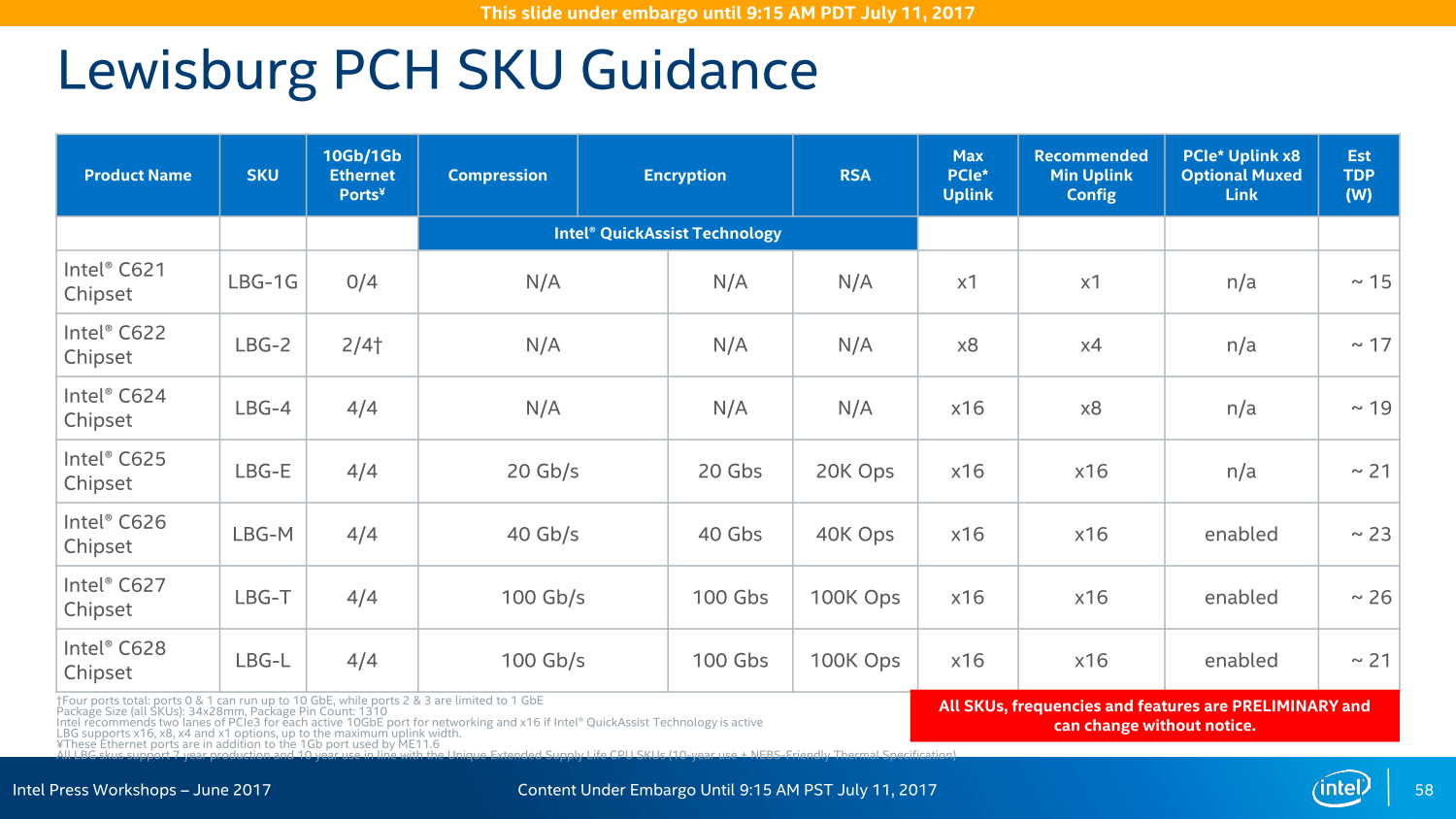


Die Variantenvielfalt ist zudem so groß wie nie zuvor: Insgesamt sieben Modelle wird es geben, wenngleich sich diese primär in ihren LAN- und Crypto-Funktionen unterscheiden, das Basispaket ist identisch. In einem Acht-Sockel-System können insgesamt vier dieser Chipsätze zusammenarbeiten und sollen so eine bisher unerreichte Konnektivität ohne zusätzliche Chips und/oder Steckkarten erreichen – ohne die PCIe-Lanes der CPU abzugreifen, wie Intel wiederholt mit Blick auf AMD Epyc betonte.
Bei PCIe vor AMD Naples
Und so bietet der Chipsatz neben den vier 10-Gigabit-LAN-Anschlüssen und bis zu 14 SATA-Ports diverse USB-Anschlüsse und weitere Features auch noch 20 PCIe-Lanes für zusätzliche Erweiterungsmöglichkeiten, ein Rückgriff auf die CPU ist nicht vonnöten. In einem Dual-Sockel-System mit 96 Lanes über die CPU und 20 weiteren über den Chipsatz liege der Vorteil der Ausstattung dann bei Intel, betonte der Hersteller im Rahmen des Workshops im Juni, da die insgesamt 128 PCIe-Lanes eines Dual-AMD-Epyc-Systems noch für viele Basis-Features genutzt werden müssten.