
Turing TU102, -104, -106: Die Technik der Nvidia GeForce RTX 2080 Ti, 2080 & 2070

tl;dr: Nvidias neue Grafikkarten der GeForce-RTX-Serie setzen auf die GPUs TU102, TU104 und TU106 mit Turing-Architektur. Deren Anpassungen und Neuerungen gegenüber Pascal sind umfangreich und gehen über das viel beworbene und viel diskutierte Echtzeit-Raytracing weit hinaus. ComputerBase gibt einen Überblick mit Einschätzung.
Turing auf Nvidias GeForce RTX
Nvidias neue Turing-Architektur löst auf GeForce RTX 2070, GeForce RTX 2080 und GeForce RTX 2080 Ti nach zwei Jahren den Vorgänger Pascal bei den Spieler-GPUs ab. Vorgestellt wurde die neue Architektur Ende August zur Gamescom in Köln, eine Woche nachdem Nvidia erste Quadro-Grafikkarten mit Turing präsentiert hatte. Zu kaufen geben wird es GeForce RTX 2080 Ti und RTX 2080 ab dem 20. September. Die GeForce RTX 2070 folgt im Oktober.
Turing ist mehr als Pascal + Echtzeit-Raytracing
Viele Details zur neuen Architektur der GPUs waren bis heute noch unbekannt. Bei der offiziellen Vorstellung der drei neuen Grafikkarten ging es in erster Linie um Raytracing und damit um die neue Funktion der GPUs, die auch den Wechsel in der Bezeichnung von GTX auf RTX zur Folge hat. RTX heißt auch Nvidias Umsetzung der neuen DXR-Technik in DirectX 12, die Echtzeit-Raytracing in Spielen mit Hilfe eines Rasterizer-Raytracing-Hybrides möglich machen soll. Elf Spiele sind bis jetzt mit Raytracing angekündigt worden, Battlefield V (Raytracing im Video) wird Ende November vermutlich den Anfang machen.
Doch auch wenn Raytracing das aktuelle Hype-Thema bei den neuen Grafikkarten ist, beinhaltet Turing noch deutlich mehr Anpassungen gegenüber Pascal. Sie betreffen nicht nur neue Funktionen oder den neuen Speichertyp GDDR6, auch die klassische Rendering-Pipeline wurde deutlich überarbeitet.
Weil die ersten GeForce-RTX-Grafikkarten zu ihren Lebzeiten höchstwahrscheinlich hauptsächlich Rasterizer-Spiele berechnen werden, sind diese Neuerungen zwar weniger namhaft, werden für viele Spieler aber am Ende die relevanteren sein.
Wie diese Anpassungen und Neuerungen genau aussehen, legt ComputerBase auf den nachfolgenden Seiten ausführlich dar. Und auch der Vergleich der drei ersten Turing-GPUs TU102, TU104 und T106 auf den Grafikkarten GeForce RTX 2080 Ti, 2080 und 2070 ist Teil dieses Artikels.
Tests und Benchmarks folgen
Testergebnisse und damit auch Benchmarks gibt es heute hingegen noch nicht. Entgegen der Tradition hat sich Nvidia dafür entschieden, heute nur das Embargo über die Technik hinter Turing fallen zu lassen. Die Motivation scheint klar: Turing ist mit den Tensor- und RT-Cores für AI und Raytracing mehr als nur Pascal und damit Maxwell in schneller. Turing ist ein großer Bruch. Und diese Botschaft würde in einem Test ohne Spiele, die die neuen Funktionen unterstützen, untergehen, was der technischen und preislichen Positionierung von RTX über GTX nicht zugute käme.
Drei GPUs: TU102, TU104 und TU106 im Vergleich
Nvidia bricht bei GeForce RTX mit noch einer lange gepflegten Tradition: In den letzten Generationen basierten die drei schnellsten Modelle auf zwei GPUs, bei Turing sind es drei.
Während bei Pascal die GeForce GTX 1070 und die GeForce GTX 1080 auf den GP104 setzen, wenn auch unterschiedlich aktiv genutzt, nutzt die GeForce GTX 1080 Ti den größeren GP102. Turing nutzt auf den drei schnellsten Modellen hingegen gleich drei GPUs: Den TU102 auf der GeForce RTX 2080 Ti, den TU104 auf der GeForce RTX 2080 und den TU106 auf der GeForce RTX 2070. Der dritte Chip war bis jetzt eigentlich immer für die x060-Modelle reserviert.
Die Entscheidung überrascht umso mehr, wenn die Größenunterschiede der GPUs der beiden Serien miteinander verglichen werden. Denn zwischen TU106 und TU102 liegen nur 69 Prozent Flächenzuwachs, während GP102 135 Prozent größer als GP106 ist.
| GPU | Im Einsatz auf | Fertigung | Größe | Flächenzuwachs zur kleineren GPU |
Transistoren | Packdichte* |
|---|---|---|---|---|---|---|
| TU102 | GeForce RTX 2080 Ti | 12 nm | 754 mm² | +38 % | 18,6 Mrd. | 24,67 |
| TU104 | GeForce RTX 2080 | 12 nm | 545 mm² | +22 % | 13,6 Mrd. | 24,95 |
| TU106 | GeForce RTX 2070 | 12 nm | 445 mm² | – | 10,9 Mrd. | 24,49 |
| Zum Vergleich | ||||||
| GP102 | GeForce GTX 1080 Ti | 16 nm | 471 mm² | +50 % | 12,0 Mrd. | 25,48 |
| GP104 | GeForce GTX 1080 & 1070 | 16 nm | 314 mm² | +57 % | 7,2 Mrd. | 22,93 |
| GP106 | GeForce GTX 1060 | 16 nm | 200 mm² | – | 4,4 Mrd. | 22,00 |
| *In Mio. Transistoren pro mm² | ||||||
Alle drei Turing-GPUs werden im 12-nm-Verfahren bei TSMC gefertigt. Und alle drei GPUs sind sehr groß und komplex. Der TU102 kommt auf satte 18,6 Milliarden Transistoren und ist mit 754 mm² mit Abstand die größte Spieler-GPU, die es jemals gegeben hat. Der GP102 erscheint mit 471 mm² dagegen regelrecht winzig. Der TU104 kommt auf immer noch komplexe 13,6 Milliarden Transistoren bei einer Chipgröße von 545 mm². Der TU106 bietet immer noch 10,87 Milliarden Transistoren bei 445 mm². Damit ist die kleinste Turing-GPU kaum kleiner als der größte Pascal-Ableger für Spieler.
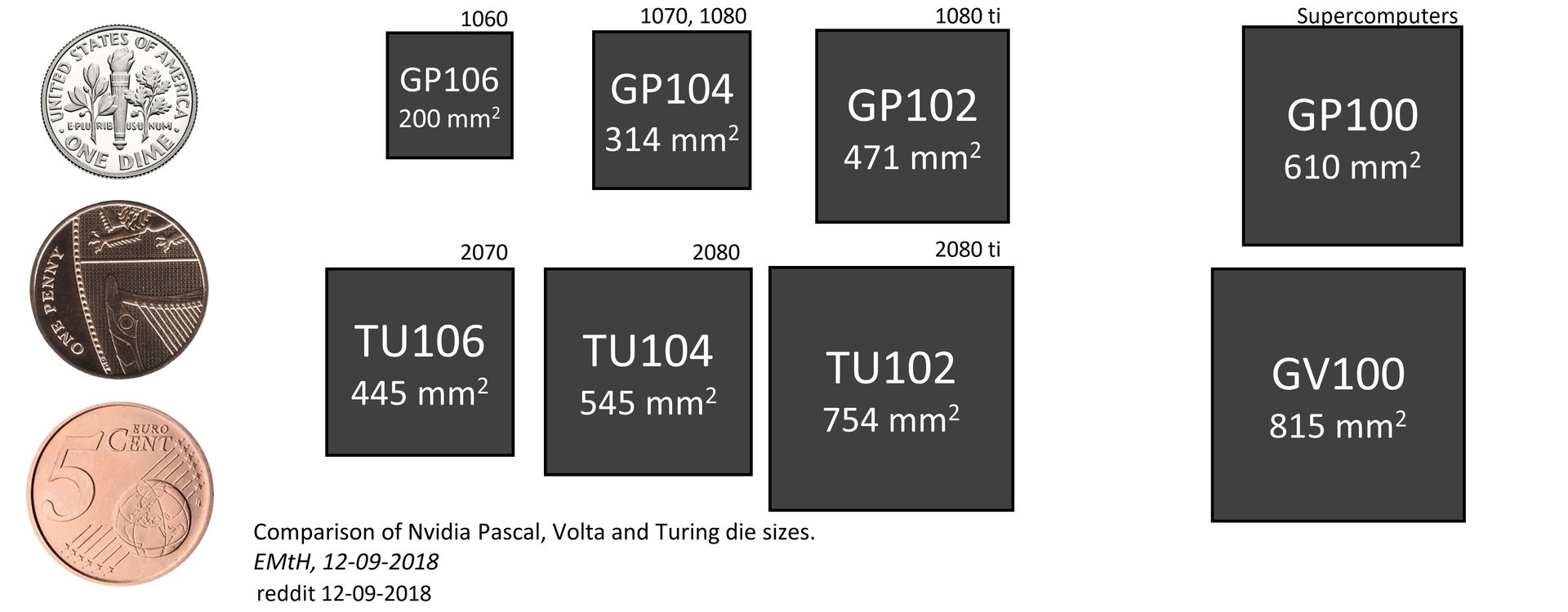
Interessant ist, dass Turing pro mm² Fläche nicht pauschal mehr Transistoren unterbringt als Pascal, obwohl der Fertigungsprozess es zulassen würde. Mit über 25 Millionen Transistoren pro Quadratmillimeter ist der GP102 im Vergleich der am dichtesten gepackte Chip. Offensichtlich waren Nvidia andere Aspekte wie höhere Taktraten wichtiger als mehr dichter gepackte Chips auf einem Wafer unterzubringen.
Warum gibt es drei GPUs?
Nvidia sagt nicht, warum Turing drei GPUs für drei Grafikkarten nutzt, wo Pascal mit zwei GPUs ausgekommen ist. Spekulationen reichen von zu guten Yield-Raten, die nicht genug teildeaktivierte größere GPUs für die kleineren Grafikkarten abwerfen, bis hin zu zu schlechten Yield-Raten, deren Ausschuss auf dem Wafer Nvidia mit kleineren GPUs zu kontern versucht. Fazit: Die Hintergründe sind nicht bekannt.
Die GeForce-RTX-Serie im Detail
TU102, TU104 und TU106 kommen auf Spieler-Grafikkarten zuerst auf GeForce RTX 2080 Ti, 2080 und 2070 zum Einsatz. Und bevor sich der Artikel den Eigenheiten der Architektur widmet, wirft die Redaktion zuerst einen Blick auf diese zum Start angekündigten neuen Grafikkarten mit Turing und deren Unterschiede.
Was ist mit einer GeForce RTX 2060?
Ob es weitere Grafikkarten mit Turing geben wird, darüber liegen bisher noch keine Informationen vor. Dass Nvidia unterhalb der GeForce RTX 2070 weiter mit Pascal plant, kann allerdings nicht ausgeschlossen werden. Die Vermutung, dass diese Grafikkarten dann weiter GeForce GTX lauten werden, steht im Raum. Eine GeForce GTX 2060 könnte, sofern die GeForce RTX 2070 die GeForce GTX 1070 deutlich schlägt, beispielsweise auf deren GP104 setzen, um gegenüber einer GeForce GTX 1060 aufgewertet zu werden.
GeForce RTX 2080 Ti mit TU102 vs. GTX 1080 Ti
Die vorerst leistungsstärkste Spieler-Grafikkarte mit Turing ist die GeForce RTX 2080 Ti mit TU102. Die GPU ist auf dieser Grafikkarte im Vergleich zum Chip auf Quadro RTX 8000 und 6000 aber nicht komplett aktiviert. Das ist von der GeForce GTX 1080 Ti mit GP102 bekannt.
Von den 4.608 Shadereinheiten sind auf der GeForce RTX 2080 Ti noch 4.352 aktiv. Vier SM mit je 64 Shadereinheiten bleiben bei der schnellsten Gaming-Version abgeschaltet – das entspricht einem Abschlag von sechs Prozent. Darüber hinaus gibt es 288 Textureinheiten (vier TMUs pro SM, 272 TMUs auf der RTX 2080 Ti).
-
 Nvidia GeForce RTX 2080 Ti Founders Edition
Nvidia GeForce RTX 2080 Ti Founders Edition











Exklusiv zugreifen kann die GeForce RTX 2080 Ti auf 544 von 576 aktiven Tensor-Cores und 68 von 72 aktiven RT-Cores. Die Leistung der Grafikkarte im Echtzeit-Raytracing soll damit um den Faktor 10 höher liegen als wenn auf der GeForce GTX 1080 Ti die herkömmlichen ALUs dafür Verwendung finden.
| TU102 Vollausbau |
GeForce RTX 2080 Ti (Founders Edition) |
GeForce GTX 1080 Ti | Δ 2080 Ti vs. 1080 Ti | |
|---|---|---|---|---|
| Architektur | Turing | Turing | Pascal | – |
| Transistoren | 18,6 Milliarden | 18,6 Milliarden | 12 Milliarden | +55 % |
| Fertigung | 12 nm TSMC | 12 nm TSMC | 16 nm TSMC | – |
| Chipgröße | 754 mm² | 754 mm² | 471 mm² | +60 % |
| GPCs | 6 | 6 | 6 | ±0 % |
| FP32-Shader | 4608 | 4352 | 3584 | +21 % |
| INT32-Shader | 4608 | 4352 | – | – |
| Tensor-Kerne | 576 | 544 | – | – |
| Raytracing-Kerne | 72 | 68 | – | – |
| Basis-Takt | – | 1.350 MHz | 1.480 MHz | -9 % |
| Boost-Takt | – | 1.545 MHz (1.635 MHz) |
1.582 MHz | -2 % |
| FP32-Leistung | – | 13,4 TFLOPS (14,2 TFLOPS) |
11,3 TFLOPS | +19 % |
| INT32-Leistung | – | 13,4 TIPS | – | – |
| FP16-Leistung | – | 26,9 TFLOPS (28,5 TFLOPS) |
11,3 TFLOPS | +138 % |
| FP16-Leistung über Tensor | – | 107,6 TFLOPS (113,8 TFLOPS) |
– | – |
| Raytracing-Leistung* | – | 10 Gigarays/s 10 Gigarays/s |
1,1 Gigarays/s | +900 % |
| Textureinheiten | 288 | 272 | 224 | + 21 % |
| ROPs | 96 | 88 | 88 | ±0 % |
| Speicherausbau | – | 11.264 MB GDDR6 | 11.264 GDDR5X | ±0 % |
| Speichertakt | – | 7.000 MHz | 5.500 MHz | +27 % |
| Speicherinterface | 384 Bit | 352 Bit | 352 Bit | ±0 % |
| Speicherbandbreite | – | 616 GB/s | 484 GB/s | + 27 % |
| TDP | – | 250 Watt (260 Watt) |
250 Watt | ±0 % |
Die GeForce RTX 2080 Ti hat also mehr Shader und mehr TMUs als die GeForce GTX 1080 Ti und bietet neue Einheiten exklusiv. Mit 96 ROPs auf der GPU und 88 aktiven ROPs auf der GeForce RTX 2080 Ti bleibt deren Anzahl hingegen gleich. Dasselbe gilt für die Breite des Speicherinterfaces. TU102 bietet 384 Bit (zwölf 32-Bit-Controller), von denen auf der RTX 2080 Ti aber nur 352 Bit aktiv sind. Und auch beim Speicherausbau hat es keine Änderungen gegeben, mehr als 11 GB gibt es nicht. Der Speicher arbeitet hingegen mit einem Takt von 7.000 MHz. Es kommt erstmals neuer GDDR6-Speicher von Micron zum Einsatz. 27 Prozent mehr Speicherbandbreite sind die Folge.
Der Basis-Takt der GeForce RTX 2080 Ti beträgt 1.350 MHz. Der Boost-Takt ist mit 1.545 MHz angegeben, wobei Nvidias eigene Founders Edition mit 1.635 MHz arbeitet. Die TDP beträgt unverändert 250 Watt, die Founders Edition kommt auf zehn Watt mehr. Wer den neuen VirtualLink-Anschluss für VR nutzt, muss weitere 35 Watt hinzu rechnen.
GeForce RTX 2080 mit TU104 vs. GTX 1080
Unter der GeForce RTX 2080 Ti steht die GeForce RTX 2080 im Portfolio. Auch deren TU104-GPU ist teildeaktiviert, bei GP104 auf GeForce GTX 1080 ist das nicht der Fall. Auch am Aufbau der GPU ändert sich im Vergleich zu TU102 etwas: Es gibt zwar immer noch sechs Graphics Processing Clusters (GPC) mit je einer Raster-Engine, allerdings gibt es nur noch vier Texture Processing Clusters (TPC) pro GPC. Damit besteht TU104 aus 48 SM mit insgesamt 3.072 ALUs. Auf der GeForce RTX 2080 wurden 2 SM deaktiviert, sodass 46 SM und somit 2.944 ALUs und 184 TMUs bleiben.
-
 Nvidia GeForce RTX 2080 Founders Edition
Nvidia GeForce RTX 2080 Founders Edition
















Damit bietet der TU104 auf der GeForce RTX 2080 automatisch auch nur noch 368 aktive Tensor-Cores und 46 aktive Raytracing-Kerne. Die GPU erreicht so laut Nvidia noch 8 Gigarays pro Sekunde.
Die Anzahl der ROPs liegt bei 64 und das Speicherinterface ist 256 Bit breit. Beide Werte sind auf Quadro und GeForce identisch. Die Speichergröße liegt bei 8.192 MB und ist damit auch in dieser Klasse unverändert zum Vorgänger.
| TU104 Vollausbau |
GeForce RTX 2080 (Founders Edition) |
GeForce GTX 1080 | Δ 2080 vs. 1080 | |
|---|---|---|---|---|
| Architektur | Turing | Turing | Pascal | – |
| Transistoren | 13,6 Milliarden | 13,6 Milliarden | 7,2 Milliarden | +89 % |
| Fertigung | 12 nm TSMC | 12 nm TSMC | 16 nm TSMC | – |
| Chipgröße | 545 mm² | 545 mm² | 314 mm² | +74 % |
| GPCs | 6 | 6 | 4 | +50 % |
| FP32-Shader | 3.072 | 2.944 | 2.560 | +15 % |
| INT32-Shader | 3.072 | 2.944 | – | – |
| Tensor-Kerne | 384 | 368 | – | – |
| Raytracing-Kerne | 48 | 46 | – | – |
| Basis-Takt | – | 1.515 MHz | 1.607 MHz | -6 % |
| Boost-Takt | – | 1.710 MHz (1.800 MHz) |
1.733 MHz | -1 % |
| FP32-Leistung | – | 10 TFLOPS (10,6 TFLOPS) |
8,9 TFLOPS | +12 % |
| INT32-Leistung | – | 10 TIPS (10,6 TIPS) |
– | – |
| FP16-Leistung | – | 20,1 TFLOPS (21,2 TFLOPS) |
8,9 TFLOPS | +125 % |
| FP16-Leistung über Tensor | – | 80,5 TFLOPS (84,8 TFLOPS) |
– | – |
| Raytracing-Leistung* | – | 8 Gigarays/s | 0,89 Gigarays/s | +800 % |
| Textureinheiten | 192 | 184 | 160 | +15 % |
| ROPs | 64 | 64 | 64 | ±0 % |
| Speicherausbau | – | 8.192 MB GDDR6 | 8.192 GDDR5X | ±0 % |
| Speichertakt | – | 7.000 MHz | 5.000 MHz | +40 % |
| Speicherinterface | 256 Bit | 256 Bit | 256 Bit | ±0 % |
| Speicherbandbreite | – | 448 GB/s | 320 GB/s | +40 % |
| TDP | – | 215 Watt (225 Watt) |
180 Watt | +20 % |
Der Basis-Takt der GeForce RTX 2080 liegt bei 1.515 MHz. Der Boost-Takt ist mit 1.710 MHz angegeben, bei der Founders Edition mit 1.800 MHz. Der GDDR6-Speichertakt beträgt wie beim Flaggschiff 7.000 MHz. Die TDP liegt bei 215 Watt, die Founders Edition darf sich erneut zehn Watt mehr genehmigen.
Gegenüber der GeForce GTX 1080 fallen bei der GeForce RTX 2080 neben den neuen Funktionen insbesondere die deutlich höhere Speicherbandbreite und die höhere TDP auf.
GeForce RTX 2070 mit TU106 vs. GTX 1070
Anders als die größeren Kollegen setzt die GeForce RTX 2070 auf eine vollaktivierte GPU, aber eben die vorerst kleinste der Generation Turing: TU106. Der TU106 halbiert die GPCs (und damit die Raster-Einheiten) auf deren drei, pro GPC gibt es dann aber wieder wie auf dem TU102 sechs TPCs. Die GPU verfügt damit über 36 SM und somit über 2.304 ALUs und 144 TMUs. Darüber hinaus gibt es noch 288 Tensor- und 36 Raytracing-Kerne. 6 Gigarays pro Sekunde bleiben für Raytracing in Echtzeit übrig.
-
 Nvidia GeForce RTX 2070 FE (Bild: Nvidia)
Nvidia GeForce RTX 2070 FE (Bild: Nvidia)



Der ROP-Ausbau und das Speicherinterface sind wiederum identisch zum TU104. Der TU106 bietet entsprechend 64 ROPs und 256 Bit. Und auch die GeForce RTX 2070 setzt auf einen acht Gigabyte großen GDDR6-Speicher, der mit 7.000 MHz arbeitet. Weil die GeForce GTX 1070 nur GDDR5 mit 4.000 MHz bot, ist der Zuwachs bei der Speicherbandbreite mit 75 Prozent enorm. GeForce RTX 2070 und 2080 nehmen sich in diesem Punkt nichts mehr.
| TU106 Vollausbau |
GeForce RTX 2070 (Founders Edition) |
GeForce GTX 1070 | Δ 2070 vs. 1070 | |
|---|---|---|---|---|
| Architektur | Turing | Turing | Pascal | – |
| Transistoren | 10,8 Milliarden | 10,8 Milliarden | 7,2 Milliarden | – |
| Fertigung | 12 nm TSMC | 12 nm TSMC | 16 nm TSMC | – |
| Chipgröße | 445 mm² | 445 mm² | 314 mm² | +42 % |
| GPCs | 3 | 3 | 3 | ±0 % |
| FP32-Shader | 2.304 | 2.304 | 1.920 | +20 % |
| INT32-Shader | 2.304 | 2.304 | – | – |
| Tensor-Kerne | 288 | 288 | – | – |
| Raytracing-Kerne | 36 | 36 | – | – |
| Basis-Takt | – | 1.410 MHz | 1.506 MHz | -6 % |
| Boost-Takt | – | 1.620 MHz (1.710 MHz) |
1.683 MHz | -4 % |
| FP32-Leistung | – | 7,5 TFLOPS (7,9 TFLOPS) |
6,5 TFLOPS | +15 % |
| INT32-Leistung | – | 7,5 TIPS (7,5 TIPS) |
– | – |
| FP16-Leistung | – | 14,9 TFLOPS (15,8 TFLOPS) |
6,5 TFLOPS | +129 % |
| FP16-Leistung über Tensor | – | 59,7 TFLOPS (63 TFLOPS) |
– | – |
| Raytracing-Leistung* | – | 6 Gigarays/s | 0,65 Gigarays/s | +900 % |
| Textureinheiten | 144 | 144 | 120 | +20 % |
| ROPs | 64 | 64 | 64 | ±0 % |
| Speicherausbau | – | 8.192 MB GDDR6 | 8.192 GDDR5 | ±0 % |
| Speichertakt | – | 7.000 MHz | 4.000 MHz | +75 % |
| Speicherinterface | 256 Bit | 256 Bit | 256 Bit | ±0 % |
| Speicherbandbreite | – | 448 GB/s | 256 GB/s | +75 % |
| TDP | – | 175 Watt (185 Watt) |
150 Watt | +17 % |
Die GeForce RTX 2070 hat einen Basis-Takt von 1.410 MHz. der Turbo-Takt beträgt 1.620 MHz, bei der Founders Edition sind es 1.710 MHz. Die TDP des Einstiegs-Modell in die Turing-Welt ist mit 175 Watt und 185 Watt bei der Founders Edition angegeben.
*Anders als die restlichen Werte lassen sich die Angaben zur Raytracing-Performance nicht berechnen. Nvidia hat schlicht Benchmarks mit den Grafikkarten in verschiedenen Raytracing-Applikationen vorgenommen, die dann ein Ergebnis in Gigarays/s ausgegeben haben. Entsprechend basieren die Werte auf Messergebnissen in speziellen Raytracing-Applikationen.