Raytracing in Spielen VI: Weitere Raytracingansätze und Fazit
3/3AMDs Ansatz für Hardware-Raytracing
AMD hatte Mitte 2019 in einem Patent einen Ansatz für Echtzeit-Raytracing in Hardware beschrieben, der von dem von Nvidia verfolgten abweicht. Darin werden die Berechnungen für Raytracing in die Texturprozessoren der Shader integriert. Für Überraschung sorgte ein Entwickler der Xbox Series X mit AMD-GPU zwei Monate später, als er von dedizierten RT-Kernen bei AMD sprach, was auf den ersten Blick einer integrierten Lösung widerspricht. Die folgende Analyse war bei Erscheinen des Artikels in 2020 noch Spekulation, hat sich mittlerweile aber als korrekt herausgestellt.


Der BVH-Algorithmus benötigt einen guten Zugriff auf Cache und VRAM bei hoher Bandbreite. Als ausgegliedertes Element, wie es der RT-Kern bei Nvidia ist, bedeutet dies Flächenverbrauch durch eine zusätzliche Speicheranbindung. AMD beschreibt, dass der Texturprozessor, der für das Abrufen der Texturen beim Shading zuständig ist, bereits eine optimale Anbindung an den Speicher besitzt. Er ist dadurch prädestiniert, den BVH-Algorithmus speichereffizient auszuführen. Der zweite Schritt für Raytracing, die Schnittstellenbestimmung, wird im Anschluss durch eine neue Recheneinheit, die sogenannten „Ray Accelerator“, durchgeführt. Dieser ist eine Fixed-Function-Einheit, also wie bei Nvidia ein ASIC, der in den Texturprozessor integriert wird. Diese Einheit war damals diejenige sein, die vom Xbox-Entwickler als dedizierte Recheneinheit für Raytracing bezeichnet wurde.

Das unterscheidet Nvidias und AMDs Ansatz
Der Ansatz von AMD unterscheidet sich von Nvidias Vorgehensweise in zwei Dingen. Zum einen führt die neue Recheneinheit nur einen anstelle von zwei Schritten der Raytracing-Pipeline aus. Dadurch kann dieser Bereich kleiner ausfallen, was Chipfläche spart. Zum anderen wird das Scheduling, also die Entscheidung, welche Schritte wann unternommen werden, vermehrt von der Shader-Einheit ausgeführt. Der Texturprozessor arbeitet stets nur den Strahlendurchgang durch eine Box-Ebene in der BVH ab und liefert das Ergebnis (Strahlen-Schnittstelle bzw. weitere Boxen, die durchlaufen werden müssen) zurück an die Shader-Einheit. Dies geschieht auf die gleiche Weise, wie bisher Texturen bereitgestellt wurden, und kann deshalb die bestehende Infrastruktur der Shader weiterverwenden. Danach entscheidet die Shader-Einheit, welche Schritte als Nächstes erfolgen, und erlaubt Entwicklern so eine bessere Kontrolle über den Rechenaufwand, der für Raytracing aufgebracht werden soll. Auch wie viele Sekundärstrahlen weiterverfolgt werden sollen, wird durch die Shader-Einheit bestimmt.

Durch diesen Aufbau haben AMDs Grafikkarten einen Vorteil, wenn für den Strahlenflug wenig Entscheidungen getroffen werden müssen. Ist die Geometrie also verhältnismäßig einfach und sind wenige Sekundärstrahlen erforderlich, kann AMDs Ansatz auf kleinem Raum eine verhältnismäßig große Leistung erbringen. Ist die Szene bestückt mit hochkomplexer Geometrie, zeigt Nvidias Ansatz seine Stärke.
Hardware-Raytracing bei Intel
Mittlerweile ist auch Intel im Grafikkartenmarkt angekommen und unterstützt ebenfalls Raytracing. Dabei geht Intel von Anfang an einen ähnlichen Weg wie Nvidia und beschleunigt alle Raytracing-Berechnungen in einer eigens dafür entwickelten Einheit, der Ray Tracing Unit (RTU).
Außerdem geht Intel einen Schritt weiter und nutzt eine Methode namens Asynchronous Raytracing, die auch patentiert wurde. Dabei steht eine Recheneinheit namens Thread Sorting Unit (TSU) dafür bereit, die Rechenergebnisse nach dem Strahlenflug neu zu sortieren, so dass sie besonders effektiv weiterverarbeitet werden können.
Das Problem, dass damit gelöst wird ist die so genannten Strahlendivergenz, zu der es kommt, wenn Strahlen zwar vom gleichen Punkt und damit Shader starten, aber die Ergebnisse nicht gemeinsam berechnet werden können. Das hat laut Intels Patent drei mögliche Ursachen:
- Strahlen, die vom gleichen Punkt aus gestartet sind, brauchen unterschiedlich lange, bis ein Ergebnis vorliegt (Traversal Divergence)
- Strahlen, die vom gleichen Punkt aus gestartet sind, benötigen am Ende unterschiedliche Berechnungen für das Endergebnis (Execution Divergence)
- Strahlen, die vom gleichen Punkt aus gestartet sind, treffen nachher auf unterschiedliche Polygone und benötigen deswegen viele unterschiedliche Texturen (Data Acces Divergence)
-
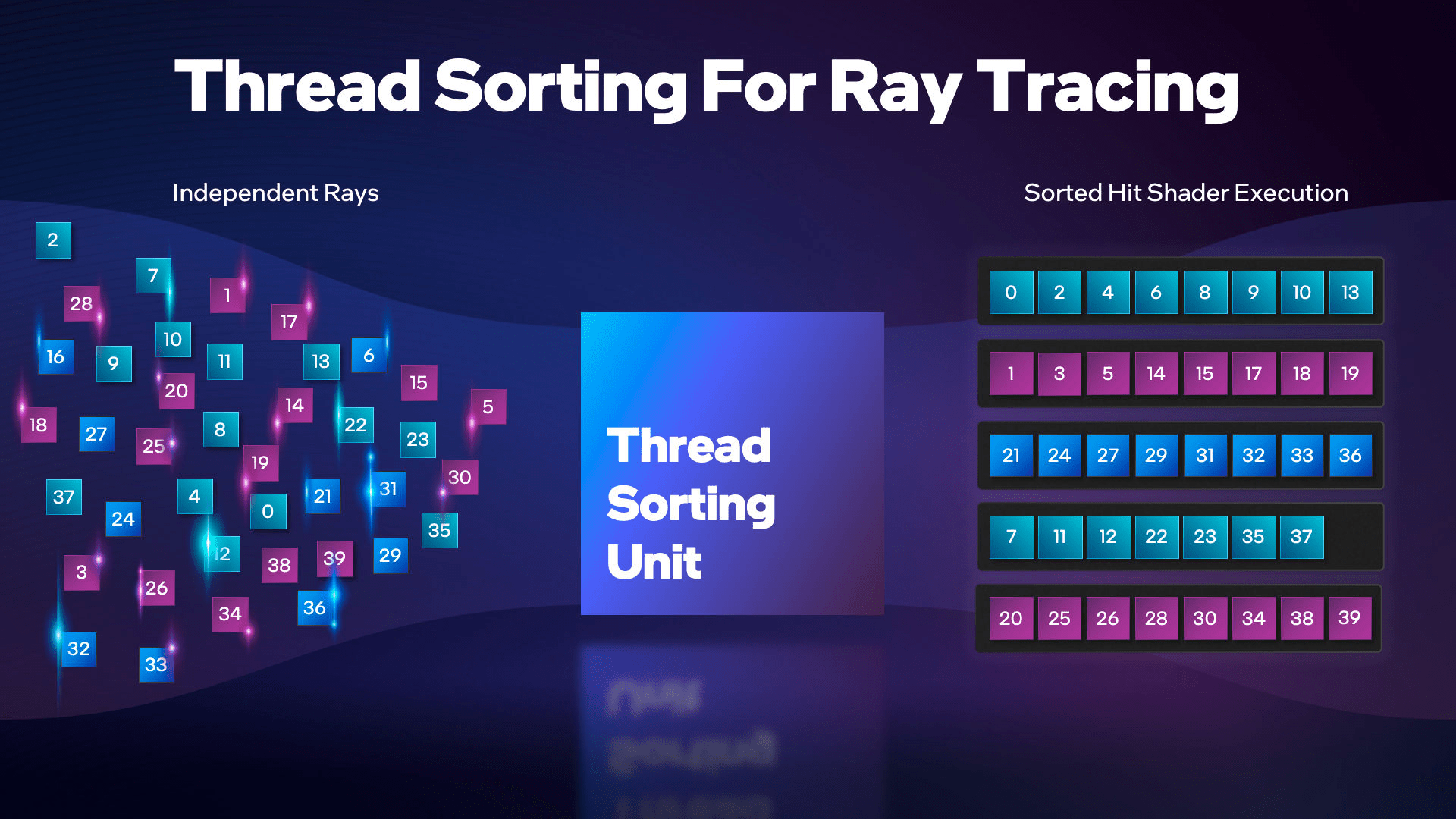 Weitere Informationen zu Raytracing auf Intels Arc-Grafikkarten (Bild: Intel)
Weitere Informationen zu Raytracing auf Intels Arc-Grafikkarten (Bild: Intel)

Asynchrones Raytracing löst die strikte Trennung zwischen dem Ergebnis des Strahlenflugs und den Ausführungseinheiten, die den Strahlenflug gestartet haben. Theoretisch besitzen Intels Grafikkarten dadurch einen Vorteil bei sehr komplexen Spielszenen mit Echtzeit-Raytracing und sollten in der Leistung weniger einbrechen.
Außerdem erlauben die von Intel herausgegebenen Daten einen Vergleich der RT-Leistung pro Recheneinheit mit der von AMDs RDNA 2.
| Parameter | Intel Alchemist | AMD RDNA 2 |
|---|---|---|
| Strahlenflug (Box Intersections) | 12 | 4 |
| Strahlentreffer (Polygon Intersections) | 1 | 1 |
| Daten sind pro Recheneinheit pro Clock | ||
Wie der Vergleich zeigt, hat Intel einen stärkeren Beschleuniger für den Strahlenflug, während es bei den Strahlentreffern einen Gleichstand gibt.
Nvidia gibt zwar an, jede Generation die Berechnung der Strahlentreffer pro RT_Core zu verdoppeln, vergleichbaren Daten hat der Hersteller aber bisher keine veröffentlicht. Bei RDNA 3 hat auch AMD keine exakten Daten genannt, weswegen es möglich ist, dass ein einzelner Ray Accelerator von AMD bei gleichem Takt weiterhin so schnell ist wie zuvor. Wie sich die Karten im direkten Vergleich schlagen hängt allerdings zusätzlich von der Anzahl der Cores, der Taktrate und der restlichen Architektur ab.
Neuerungen mit Nvidias GeForce RTX 4000
Nvidia hatte im Jahr 2022 bei der RTX-4000er-Serie Verbesserungen zu Raytracing im Gepäck. So wird auch bei Nvidia die Reihenfolge der Berechnungen von Raytracing umsortiert, allerdings gibt es dafür keine eigene Recheneinheit. Außerdem muss die Funktion vom Spieleentwickler eingesetzt werden. Nvidia nennt die Technologie Shader Execution Reordering (SER) und erreicht mit ihr im Test der Redaktion in Portal with RTX 10 Prozent mehr FPS.
Außerdem beschleunigt Nvidia die Berechnung von Raytracing bei Texturen, die teilweise transparent sind. Während normalerweise jeder Strahlentreffer an die Shader übergeben werden muss, um festzustellen, ob die entsprechende Stelle transparent ist oder nicht, hilft bei Nvidia jetzt die Opacity Micromap Engine im RT-Core. Sie erstellt für Texturen mit transparenten Bereichen, wie Blätter oder Flammen, neue Dreiecke die in „transparent“, „undurchsichtig“ oder „unbekannt“ unterteilt werden. Nur bei „unbekannt“ handelt es sich um eine schwierige Stelle, meist an den Rändern, die die Shader prüfen müssen. Bei „transparent“ wird der Strahl in gleicher Richtung weitergeschickt, während bei „undurchsichtig“ direkt das farbgebende Shading aufgerufen wird.
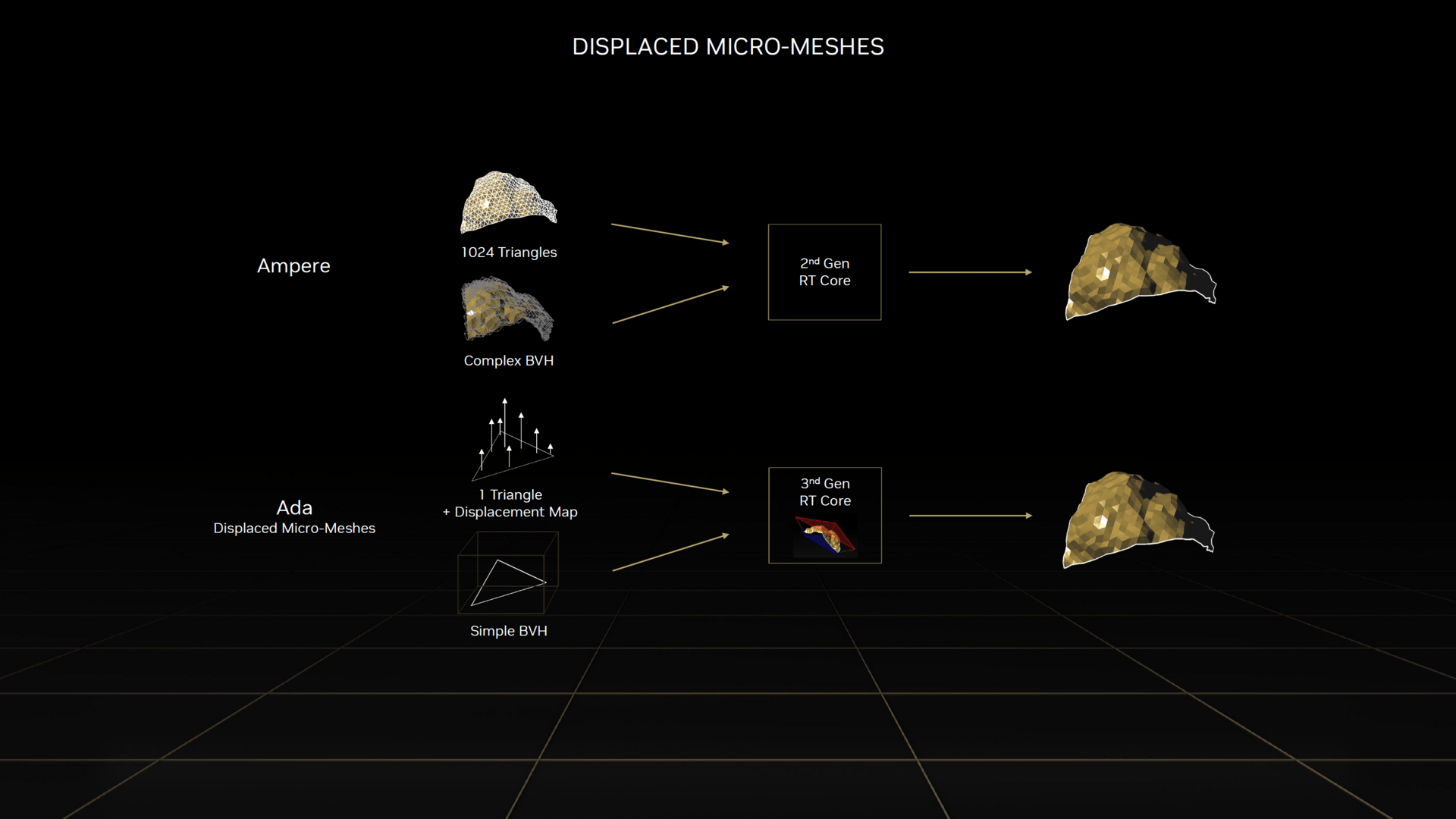
Zuletzt vereinfacht Nvidia den Bau der BVH-Struktur mithilfe von Displaced Micro-Meshes (DMM). Dabei werden die Polygone hochdetaillierter Objekte in grobe und feine Polygone unterteilt. Die groben werden zur Erstellung der BVH-Struktur genutzt, während die feinen Details in einer Displacement Map ähnlich wie bei Tesselation gespeichert werden. Dadurch muss bei der Erstellung und Berechnung der BVH-Struktur weniger Rechenleistung aufgebracht werden.
-
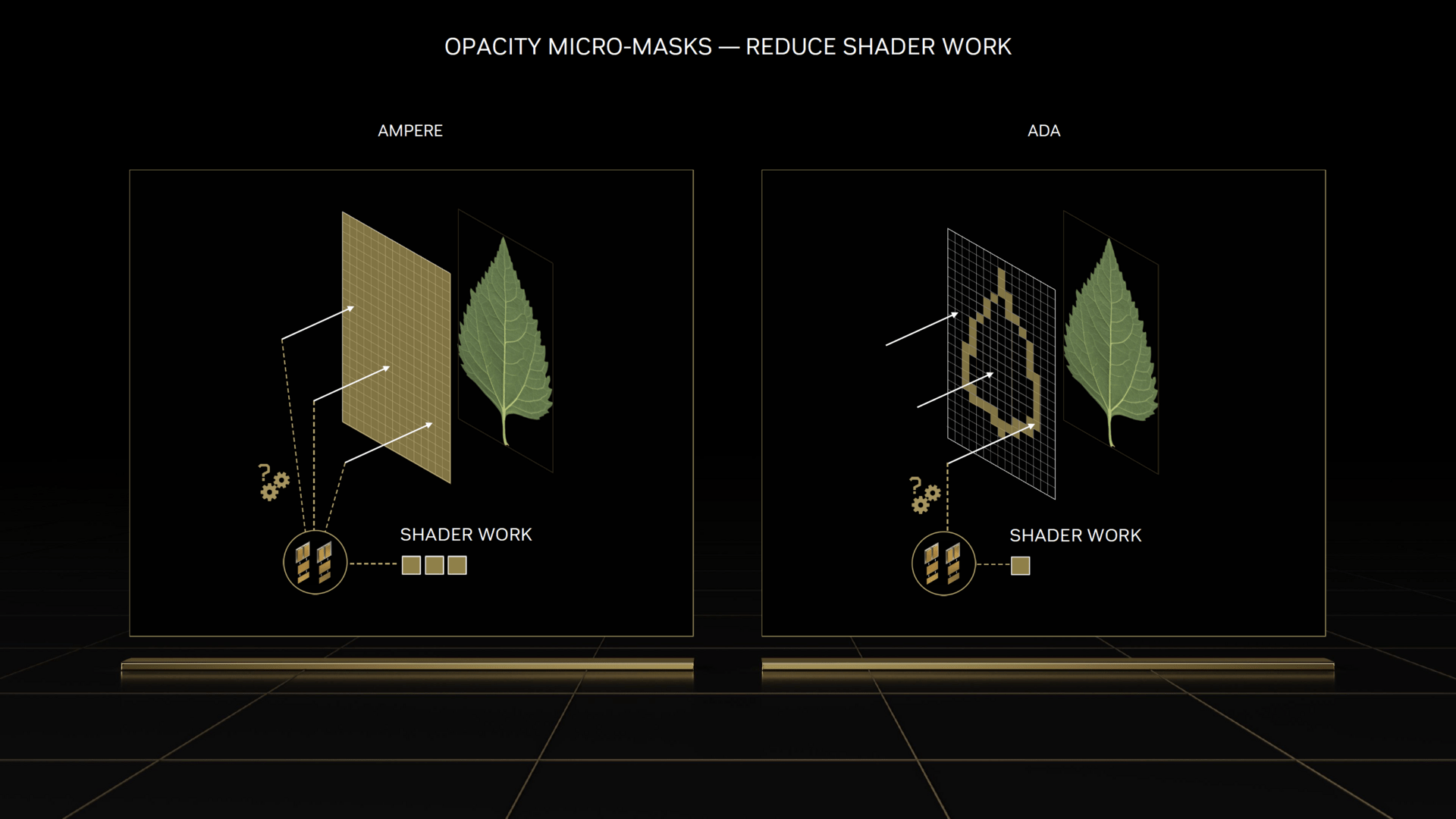 Neue RT-Features von Ada (Bild: Nvidia)
Neue RT-Features von Ada (Bild: Nvidia)
Neuerungen mit AMD Radeon RX 7000
AMD liefert bei ihrer neuen Grafikkarten-Generation ebenfalls Verbesserungen beim Raytracing. So kann die Durchquerung einer BVH-Substruktur frühzeitig abgebrochen werden, wenn die Struktur an der entsprechenden Stelle komplett transparent ist. Dafür wird eine Funktion von DirectX-Raytracing namens Ray Flags genutzt.
Außerdem wird bei Strahlenflug die Reihenfolge, welche BVH-Boxen im Raum wie geprüft werden, angepasst. Neben der Standardmethode (closest first) gibt es jetzt eine optimierte Methode für RT-Schatten (largest first) und eine für RT-Reflexionen (Closest Midpoint).
Auch AMD nutzt eine Sortierfunktion, um die Reihenfolge der RT-Berechnungen zu optimieren. Mittels eines zweistufigen Scheduling-Algorithmus werden die Berechnungen bei Strahlendivergenz zusammengeführt. Ob diese Funktion vergleichbar mit denen der anderen beiden Hersteller ist, ist allerdings schwer einzuordnen.
Zu guter Letzt wird die Strahlengeneration beschleunigt, indem jetzt 50% mehr Strahlen abgeschossen werden können. Dadurch wird die Auslastung der Recheneinheiten erhöht, wenn mangels Strahlen Leistung brach liegt.
-
 AMDs second-gen raytracing (Bild: AMD)
AMDs second-gen raytracing (Bild: AMD)


Fazit
Im Jahr 2007 wurde auf ComputerBase zum ersten Mal intensiv über Raytracing berichtet. Seit 2018 wird diese Technologie schließlich in Hardware unterstützt und in Spielen implementiert. Nvidia, AMD und Intel, aber auch Qualcomm und MediaTek bieten inzwischen Hardware-Raytracing-Einheiten in ihren Chips an. Um den hybriden Ansatz von gleichzeitiger Rasterisierung und Raytracing zu ermöglichen, müssen die Architekturen von Grafikkarten deutlich erweitert und angepasst werden. Was bisher bekannt ist, wurde in diesem Artikel zusammengefasst. Bei relevanten zukünftigen Entwicklungen wird dieser Artikel abermals auf den aktuellen Stand gebracht werden.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.