Nvidia Ampere: A100 ist für KI eine 20 Mal schnellere GPU

tl;dr: Nvidia hat erste Details zur neuen GPU-Architektur Ampere verraten. Als Nachfolger von Volta richtet sich Ampere mit GA100 zu Anfang an den Einsatz im Datacenter für das KI-Training und Inferencing. Die erste Ampere-GPU A100 soll in diesem Szenario 20 Mal so schnell sein wie Volta. Das erste Produkt ist das DGX A100.
Nvidia Ampere ist erst einmal nicht für Spieler
Nvidias neue GPU-Architektur Ampere beerbt die 2017 vorgestellte Volta-Architektur und ist damit erneut ein Produkt für das Datacenter – nicht für Spieler. Ampere wird auch den Weg in Spieler-PCs schaffen, jedoch in einer deutlich anderen Konfiguration. Dazu passt es, dass die GA100-GPU (Details: Nvidia Ampere: Die GA100-GPU im Vollausbau analysiert) und deren erste Ableitung A100 kein Raytracing unterstützt – zumindest hat Nvidia dies kein einziges Mal erwähnt und auch das Schaubild weist sie nicht aus.
Erste Details zur Ampere-Architektur, zur ersten Ampere-GPU A100 und zu den ersten Produkten wie dem DGX A100 KI-System hat Nvidia-CEO Jensen Huang heute im Rahmen einer aufgezeichneten GTC-Keynote verraten, da aufgrund der COVID-19-Pandemie die Hausmesse in San José ausfallen musste. Ein technischer Deep Dive in die neue GPU-Architektur wird für den Verlauf der kommenden Woche erwartet.
Nvidia wächst mit den Aufgaben
Ampere sei für den exponentiell wachsenden Ressourcenbedarf des Trainings neuronaler Netze und das Inferencing im Datacenter entwickelt worden, erklärt Nvidia. Im Vergleich zu früheren neuronalen Netzen wie ResNet-50 für das maschinelle Sehen, das zur Vorstellung von Volta vor drei Jahren im Einsatz war, weise das von Nvidia für Lesekompetenz entwickelte Megatron-BERT eine 3.000 Mal höhere Komplexität auf.
Diese neuen und stetig komplexeren neuronalen Netze ermöglichen auf Nutzerseite immer mehr den Alltag durchdringende Anwendungen, etwa KI-Assistenten wie Alexa, den Google Assistant oder Siri. Aber auch klassische Suchanfragen im Internet, Empfehlungen beim Online-Shopping, Diagnostik im medizinischen Sektor, Bilderkennung oder Cyberabwehr werden über moderne neuronale Netze ermöglicht. Diese Anwendungen unterstützen Millionen simultaner Anfragen und müssen jedem Nutzer kurzzeitig einen kleinen Anteil der Rechenleistung des Datacenters für KI-Beschleunigung zur Verfügung stellen.
Das Datacenter von heute ist nicht ausgelastet
Diese Trends der immer komplexeren neuronalen Netze, steigenden Anzahl an Nutzern und daraus resultierend steigenden KI-Interaktionen pro Tag haben laut Nvidia zu fragmentierten Rechenzentren geführt, die mit Ampere wieder in ihrer Komplexität reduziert werden sollen. Aktuell bestünden Datacenter zum Beispiel aus Storage-Servern, CPU-Servern, KI-Training-Servern etwa auf Basis von Volta, Inferencing-Servern etwa auf Basis von Tesla T4 sowie Servern für allgemein GPU-beschleunigte Aufgaben, die Volta im schnell zu verbauenden Kartenformat mit PCIe-Anschluss nutzen. Die Art und Menge der benötigten Rechencluster sei angesichts der verschiedenen Anwendungen und je nach Tageszeit unterschiedlichen Anforderungen nur schwer für die Betreiber vorhersehbar, argumentiert Nvidia, sodass eine Optimierung für hohe Auslastung und kosteneffizienten Betrieb des Datacenters kaum möglich sei.

Ampere soll viel schneller und flexibler sein
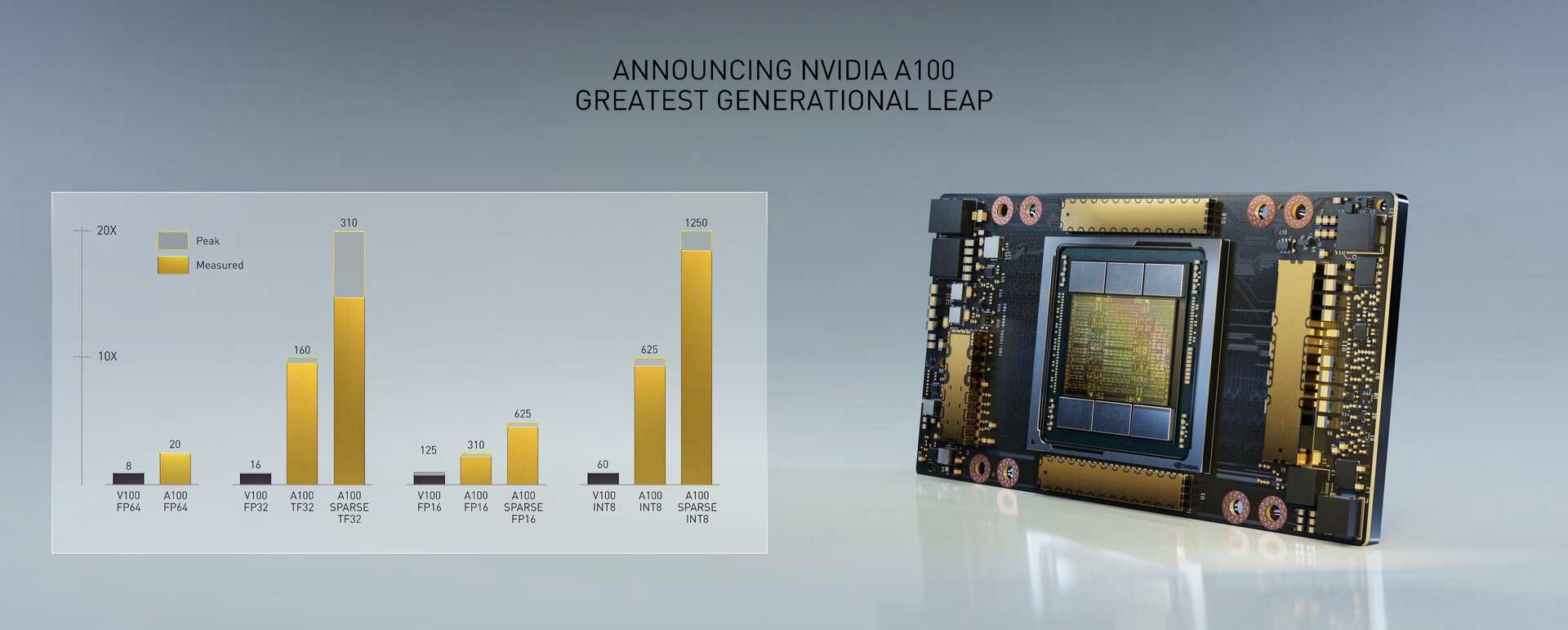
Mit Ampere will Nvidia deshalb nicht nur die Leistung massiv steigern, sondern auch eine flexible Architektur für austauschbare Anwendungsfälle in einem dynamischen Datacenter schaffen, das für die unterschiedlichsten modernen Szenarien gewappnet ist. In puncto Leistung verspricht Nvidia unter gewissen Voraussetzungen eine 20 Mal höhere KI-Leistung als bei Volta – der bisher größte Sprung zwischen zwei Generationen GPU-Architektur bei Nvidia. Ampere vereint darüber hinaus das KI-Training und die Inferencing-Beschleunigung zu einer Architektur. In Sachen Skalierbarkeit lässt sich ein Server als eine riesige GPU nutzen oder in mehr als 50 dedizierte Instanzen unterteilen.
GA100-GPU mit 54,2 Milliarden Transistoren
Die erste GPU der neuen Ampere-Architektur ist die GA100. Die GA100 wird wie Volta bei TSMC, nun aber im N7-Verfahren mit Immersionslithografie (DUV) gefertigt und weist 54,2 Milliarden Transistoren auf einer Fläche vo 826 mm² auf. Das sind bei annähernd gleicher Fläche (815 mm²) wie bei der Volta-GPU GV100 mehr als doppelt so viele Transistoren (21,1 Milliarden). Die GV100-GPU wird ebenfalls bei TSMC, aber im 12-nm-FFN-Verfahren gefertigt. Mit 54,2 Milliarden Transistoren auf 826 mm² ist die GA100-GPU der laut Nvidia weltweit größte 7-nm-Chip. Jeder GA100-GPU stehen 48 GB HBM2 von Samsung mit einer Speicherbandbreite von 1,9 TB/s zur Seite – das sind über 100 Prozent mehr als die 900 GB/s von Volta bei der GV100. Die GPU-zu-GPU-Kommunikation findet bei Ampere über den zweimal schnellere NVLink der 3. Generation mit 600 GB/s statt. Mehr Details zum GA100 im Bericht Nvidia Ampere: Die GA100-GPU im Vollausbau analysiert.
-
 Nvidia A100-GPU (Bild: Nvidia)
Nvidia A100-GPU (Bild: Nvidia)

A100, GA100 und GV100 im ersten Überblick
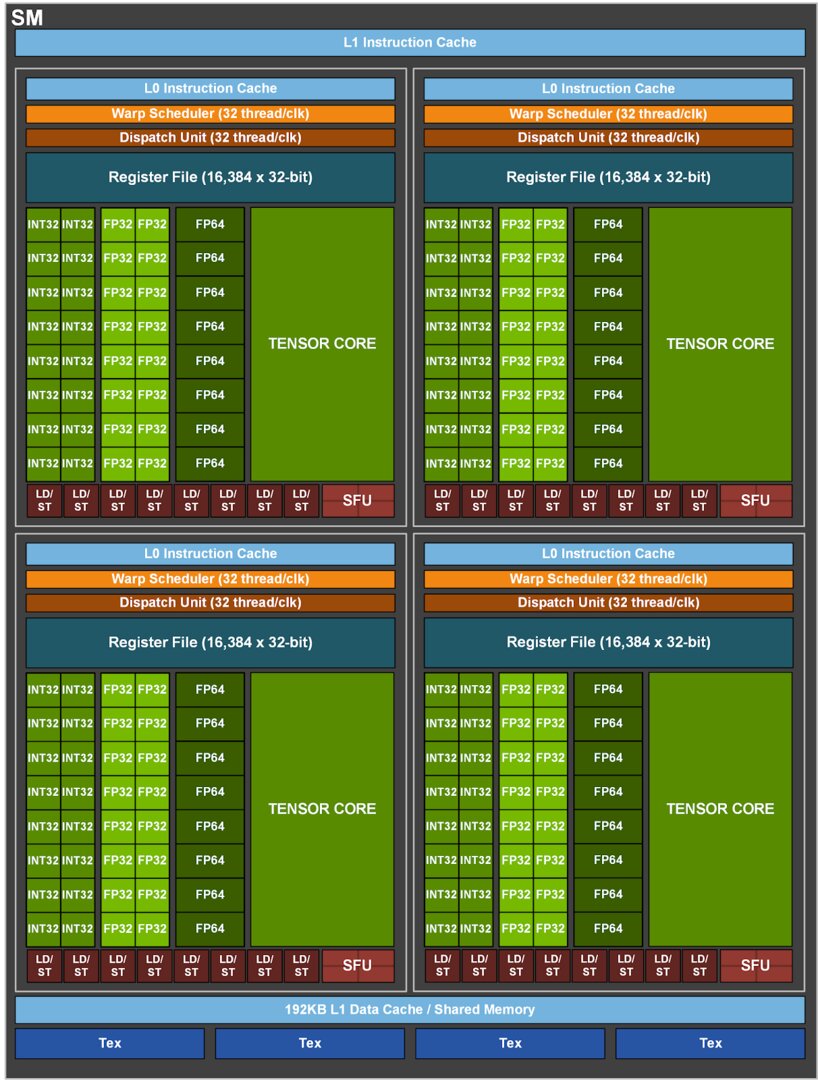
Die vom Vollausbau GA100 abgeleitete und dabei deutlich beschnittene A100 Tensor Core GPU des SXM4-Moduls ist mit 432 Tensor Cores der 3. Generation ausgestattet, bietet 108 Ampere-Streaming-Multiprocessors (SMs) und somit 24 mehr als der Vollausbau bei GV100 mit ihren Volta-SMs. Jeder SM der A100 kommt auf 64 FP32-CUDA-Cores und 32 FP64-CUDA-Cores.
| Nvidia A100 Tensor Core GPU | Nvidia GA100 | Nvidia GV100 | |
|---|---|---|---|
| Architektur | Ampere | Volta | |
| Fertigung | TSMC N7 | TSMC 12FFN | |
| Transistoren | 54,2 Milliarden | 21,1 Milliarden | |
| Die Size | 826 mm² | 815 mm² | |
| SMs | 108 | 128 | 84 |
| FP64 CUDA Cores | 3.456 | 4.096 | 2.688 |
| FP32 CUDA Cores | 6.912 | 8.192 | 5.376 |
| Tensor Cores | 432 | 512 | 672 |
| GPU-Takt | 1.410 MHz | 1.450 MHz | |
| FP64-Performance (Peak) | 9,7 TFLOPS | 7,8 TFLOPS | |
| FP32-Performance (Peak) | 19,5 TFLOPS | 15,7 TFLOPS | |
| FP16-Performance (Tensor-Peak) | 312 TFLOPS | 125 TFLOPS | |
| INT8-Performance (Tensor-Peak) | 624 TOPS | 62 TOPS | |
| Speicher | 40 GB HBM2 | 48 GB HMB2 | 32 GB HBM2 |
| Speichertakt | 1.250 MHz | 880 MHz | |
| Speicherinterface | 5.120 Bit | 6.144 Bit | 4.096 Bit |
| Bandbreite | 1,6 TB/s | 1,9 TB/s | 900 GB/s |
| TDP | 400 Watt | 300 Watt | |
| Interconnect | NVLink 600 GB/s PCIe 4.0 64 GB/s |
NVLink 300 GB/s PCIe 3.0 32 GB/s |
|
Wenn Nvidia von einer 20 Mal höheren Rechenleistung für Ampere im Vergleich zu Volta spricht, bezieht sich das Unternehmen damit auf die standardmäßig für KI-Training und Inferencing genutzten Tensor Cores und deren Matrizen-Rechenoperationen (MAD) für FP32 und INT8. Für FP32 wird eine Rechenleistung von in der Spitze 312 TFLOPS angegeben, bei INT8 sind es 1.248 TOPS – in beiden Fällen also rund 20 Mal mehr als bei der GV100 auf Basis der Volta-Architektur. Für die Double-Precision-MAD FP64 liegt die Leistung der Tensor Cores bei 19,5 TFLOPS und somit beim 2,5-fachen von Volta.
-
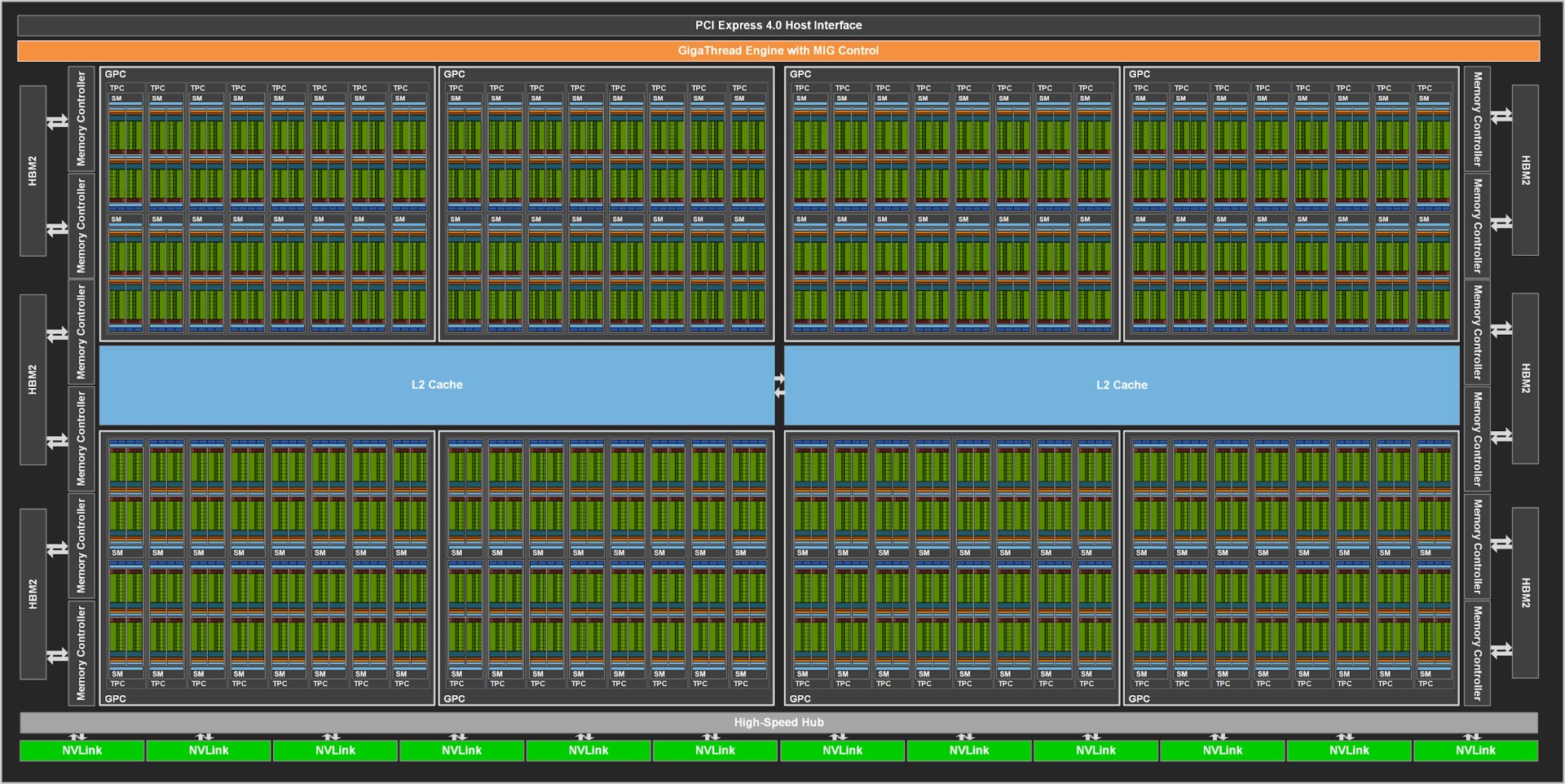 GA100 Vollausbau mit 128 SMs (Bild: Nvidia)
GA100 Vollausbau mit 128 SMs (Bild: Nvidia)
CUDA Cores spielen untergeordnete Rolle
Währen die KI-Leistung über die Tensor Cores massiv steigt und der Fokus der Architektur auf diesem Bereich zu liegen scheint, wächst die klassische FP64- und FP32-Leistung der CUDA Cores weniger dramatisch. In der Spitze sind es 9,7 TFLOPS für FP64 (+ 24 Prozent) und 19,5 TFLOPS für FP32 (+ 24 Prozent).
Die A100 arbeitet mit moderatem Takt
Anhand der Anzahl der Ausführungseinheiten und der theoretischen Peak-Performance lässt sich die Taktrate der A100 berechnen, auch wenn Nvidia offiziell keine nennt. Demnach liegt diese bei etwa 1.410 MHz. Dabei ist es aber noch unklar, ob die A100 nur kurzfristig über diesen Wert hinaus arbeiten kann oder ob dies das Maximum darstellt.
Nvidia berechnet FP32 schneller über TF32
Die 20 Mal höhere Rechenleistung ist das Ergebnis der 3. Generation Tensor Cores mit neuer Sparsity-Beschleunigung – dazu später mehr. Die 3. Generation Tensor Cores unterstützt TF32 als neues von Nvidia eingeführtes Zahlenformat für Multiply-Add-Rechenoperationen. Bei TF32 stehen wie bei FP32 8 Bit für den Exponenten und wie bei FP16 10 Bit für die Mantisse zur Verfügung. Nvidia will damit ein neues hybrides Format schaffen, um mit 8 Bit großen Variablen wie bei Single-Precision FP32 mit der 10 Bit Genauigkeit von Half-Precision wie bei FP16 umgehen zu können. TF32 kommt bei Ampere standardmäßig für die Beschleunigung von Single-Precision FP32 in Kombination mit der neuen Sparsity-Beschleunigung zum Einsatz. Entwickler sollen laut Nvidia weiterhin Single-Precision FP32 als Input nutzen können und auch weiterhin Single-Precision FP32 als Output erhalten. Am Code sollen für die neue KI-Beschleunigung keine Veränderungen vorgenommen werden müssen.
-
 Neue Standard MAD TF32 (Bild: Nvidia)
Neue Standard MAD TF32 (Bild: Nvidia)

Neuronale Netze ausdünnen
Bei der Sparsity-Beschleunigung will Nvidia die häufig nicht benötigten Verbindungen eines neuronalen Netzes, die nicht zur genauen Vorhersage beitragen, loswerden. Die dicht verwobene Matrix des neuronalen Netzes soll zu einer ausgedünnten (sparse) Matrix umgewandelt werden und effizienter sowie schneller ausgeführt werden. Die A100 und ihre Tensor Cores der 3. Generation sind für diese Sparsity-Beschleunigung optimiert worden, die bei TF32, FP16, BFLOAT16, INT8 und INT4 zum Einsatz kommt.

Das wiederum erklärt den immensen Leistungssprung für FP32 und INT8 bei Ampere, der nur dann vorliegt, wenn das neue Zahlenformat TF32 respektive die Sparsity-Beschleunigung zum Einsatz kommen. Aus 16 TFLOPS für FP32 bei der GV100-GPU werden so 160 TFLOPS für TF32 (als neuer Standard für FP32-Operationen) auf der A100-GPU. Und mit Sparsity-Beschleunigung wiederum werden daraus dann die propagierten 20 Mal höheren 312 TFLOPS mit Spare TF32. Das gleiche gilt für INT8-Operationen beim Inferencing, das von 60 TOPS bei GV100 zu 625 TOPS bei A100 und schließlich 1.248 TOPS bei A100 mit Sparse INT8 wächst. Da die neue Beschleunigung nicht bei Double-Precision FP64 greift, erklärt das auch den im Vergleich kleineren Sprung um den Faktor 2,5 auf 19,5 TFLOPS. Außerdem erklärt es, warum die A100 mit nur noch 432 statt 672 Tensor Cores bei GV100 trotzdem deutlich schneller agiert.
Vermutlich 5 HBM2-Stacks und ein Dummy
Wer rein Bild des A100 betrachtet, erkennt sechs HBM2-Stacks. Da verwundert es, wie die Hardware denn 40 GB Speicher haben soll, mit sechs Stacks wäre das nicht so ohne weiteres möglich. Nvidia äußert sich dazu noch nicht – das wird erst im Laufe der nächsten Woche geschehen – doch offenbar hat der A100 gar nicht 6 HBM2-Stacks, sondern nur deren 5 sowie einen Dummy-Stack, um den Anpressdruck des Kühlers auszugleichen. Mit 5 Stacks sowie 8 GB pro Stack kommt man auf 40 GB Speicher. Das Speicherinterface wäre damit 5.120 Bit breit (1.024 Bit pro Stack), sodass der HBM2-Speicher mit 1.250 MHz arbeiten müsste, um auf die 1,6 TB/s zu kommen.
7 dedizierte GPUs auf einer A100
Darüber hinaus ist Multi-Instance GPU (MIG) eine der wesentlichen Neuerungen der Ampere-Architektur. Jede A100 lässt sich in bis zu sieben dedizierte GPUs unterteilen, da nicht jede Anwendung die volle Leistung der gesamten GPU benötigt. Dass mehrere Instanzen auf einer GPU ausgeführt werden können, ist für Nvidia per se nicht neu, auch bei Volta ist das möglich, Ampere führt aber erstmals ein, dass jeder dieser GPUs dedizierte Hardware-Ressourcen zugewiesen werden. Jeder Instanz stehen laut Nvidia eigene Tensor und CUDA Cores, eigener Cache, eigener HBM2 und eigene Speicherbandbreite zur Verfügung, was verhindern soll, dass es zu Interferenzen unter den einzelnen GPUs kommt oder dass Anwendungen die Ressourcen ausgehen. Jede GPU-Instanz soll aus Sicht der Anwendung wie eine eigenständige GPU agieren.

NVLink arbeitet mit 600 GB/s
Während eine A100-GPU in bis zu sieben GPUs unterteilt werden kann, funktioniert dies aber auch in die entgegengesetzte Richtung und mehrere GPUs in mehreren Servern lassen sich zu einem großen Rechencluster verknüpfen. Damit sich bei diesem Vorgang kein Flaschenhals bildet, hat Nvidia die GPU-zu-GPU-Kommunikation mit einer neuen Generation NVLink von 300 GB/s auf 600 GB/s verdoppelt. Über den NVSwitch als Switch für mehrere NVLinks steht eine bidirektionale Bandbreite von bis zu 4,8 TB/s bereit, wie sie im ersten Produkt mit A100-GPU benötigt wird, dem Nvidia DGX A100.