RTX-3000-Technik im Detail: Floating Point ist Amperes Liebling

tl;dr: Nvidia hat für GeForce RTX 3090, 3080 und 3070 beachtliche Leistungszuwächse in Aussicht gestellt. Wie die Ampere-GPUs das bewerkstelligen sollen und was es mit der mehr als verdoppelten Anzahl Shader auf sich hat, hat der Hersteller jetzt im Vorfeld des Testembargos erklärt. Von großer Bedeutung sind die FP32-ALUs.
Woher kommen Shader- und Leistungssprung?
Die GA102-GPU bietet auf dem neuen Flaggschiff GeForce RTX 3090 eine irrwitzige Anzahl an aktiven ALUs. Nvidia nennt satte 10.496 CUDA-Cores und eine theoretische Rechenleistung von 35,7 FP32-TFLOPS, was gegenüber der GeForce RTX 2080 Ti ein Plus von 141 respektive 166 Prozent bedeutet – innerhalb einer Generation. Und selbst die beiden kleineren Modelle überstrahlen das alte Topmodell noch. Dabei war in der Gerüchteküche lange Zeit von der Hälfte der Shader die Rede, selbst Pressemitteilungen von Boardpartnern beinhalteten sie noch.
Nach ersten Erklärungen über Reddit hat Nvidia jetzt auch im Rahmen eines virtuellen Tech Days erklärt, wie die Streaming Multiprocessors (SM) von Ampere gegenüber Turing umgebaut wurden, um die jetzt angegebene Anzahl und die daraus abgeleiteten TFLOPS zu rechtfertigen. Der Basisaufbau von Ampere ist dabei identisch zum Vorgänger, nur einige Details haben sich geändert – und die sind entscheidend. Weitere Änderungen betreffen die RT- sowie die Tensor-Cores, die nun zudem bereit für 8K DLSS sind.
Ampere mit gravierenden Änderungen im SM
Am Grundgerüst hat Nvidia festgehalten: Die GPU ist immer noch in mehrere Graphics Processor Cluster (GPC) unterteilt, die das Rechenwerk der GPU beinhalten. Darunter fallen die Streaming Multiprocessors (SM) mit den eigentlichen Recheneinheiten, die Texture Processing Cluster (TPC) mit den Textureinheiten, die Geometrieeinheiten für zum Beispiel Tessellation und neuerdings auch die ROPs.
Gravierende Veränderungen hat es innerhalb des Grundgerüstes gegeben. Der SM von Ampere ist deutlich gegenüber dem von Turing aufgewertet worden. Ein SM bei Turing setzt sich primär aus 64 FP32-ALUs für Gleitkomma-Berechnungen sowie 64 INT32-ALUs für Ganzzahlen-Berechnungen zusammen, die wiederum in vier Blöcke zu je 16 FP32- und 16 INT32-ALUs aufgeteilt sind. Die FP- und die INT-ALUs können gleichzeitig arbeiten.
| RTX 3090 | RTX 3080 | RTX 3070 | RTX 2080 Ti | |
|---|---|---|---|---|
| GPU | GA102 | GA104 | TU102 | |
| GPC | 7 | 6 | 6 | 6 |
| SM | 82 | 68 | 46 | 68 |
| FP32-ALUs pro SM („Cuda Cores“) | 128 | 64 | ||
| FP32-ALUs („Cuda Cores“) | 10.496 | 8.704 | 5.888 | 4.352 |
| INT32-ALUs pro SM | 64 | |||
| INT32-ALUs | 5.248 | 4.352 | 2.944 | 4.352 |
| RT-Kerne | 82 2nd Gen | 68 2nd Gen | 46 2nd Gen | 68 1st Gen |
| Tensor-Kerne | 328 3rd Gen | 272 3rd Gen | 184 3rd Gen | 544 2nd Gen |
Auf Ampere gibt es weiterhin 64 reine FP32-ALUs pro SM, aber anstelle der 64 reinen INT32-ALUs nun 64 weitere, die wie die anderen 64 ALUs ebenso Floating-Point- und zusätzlich Integer-Berechnungen durchführen können – allerdings nicht parallel. Nach wie vor ist ein Ampere-SM in 4 Blöcke aufgeteilt, mit einem separaten Datenpfad für 16 FP32 und 16 weitere FP32/INT32-ALUs.
Floating Point ist Amperes bester Freund
Ein SM von Turing kann also maximal 64 FP32- und 64 INT32-Berechnungen gleichzeitig durchführen. Ein SM von Ampere dagegen entweder 128 FP32- oder 64 FP32- und 64 INT32-Berechnungen – je nachdem, welchen Workload die Anwendung an die Grafikkarte verteilt. Je nach Szenario weist ein Ampere-SM also dieselbe Rechenleistung wie ein Turing-SM auf (wenn FP und INT gleichzeitig berechnet werden), oder die doppelte Rechenleistung (wenn nur FP berechnet wird). Das ist der Grund, warum sich die theoretische FP32-Rechenleistung bei Ampere gegenüber Turing mehr als verdoppelt hat und Nvidia in Bezug auf die Anzahl der FP32-ALUs jetzt von der doppelten Anzahl CUDA-Cores redet.
Wie viel mehr Leistung durch diese Anpassung in der Praxis ankommt, hängt im Wesentlichen von zwei Faktoren ab. Der erste ist die Anwendung selbst.
Angenommen, ein Spiel verlangt primär nach Gleitkomma-Berechnungen, wird ein Ampere-SM deutlich rechenstärker als ein Turing-SM sein. Gibt es dagegen verhältnismäßig viele Ganzzahlen-Berechnungen, nähert sich die Rechenleistung an. Von gleich schnell bis doppelt so schnell ist theoretisch alles möglich und es kann durchaus passieren, dass die Anwendung, die Turing aufgrund verhältnismäßig vieler INT-Berechnungen besonders gut schmeckt, Ampere eher weniger liegt, während die Titel, in denen Turing kaum bis gar nicht von den zusätzlichen INT-Einheiten profitiert, Ampere besonders gut liegen. Langsamer als ein Turing-SM ist ein Ampere-SM aber in keinem Fall.
-
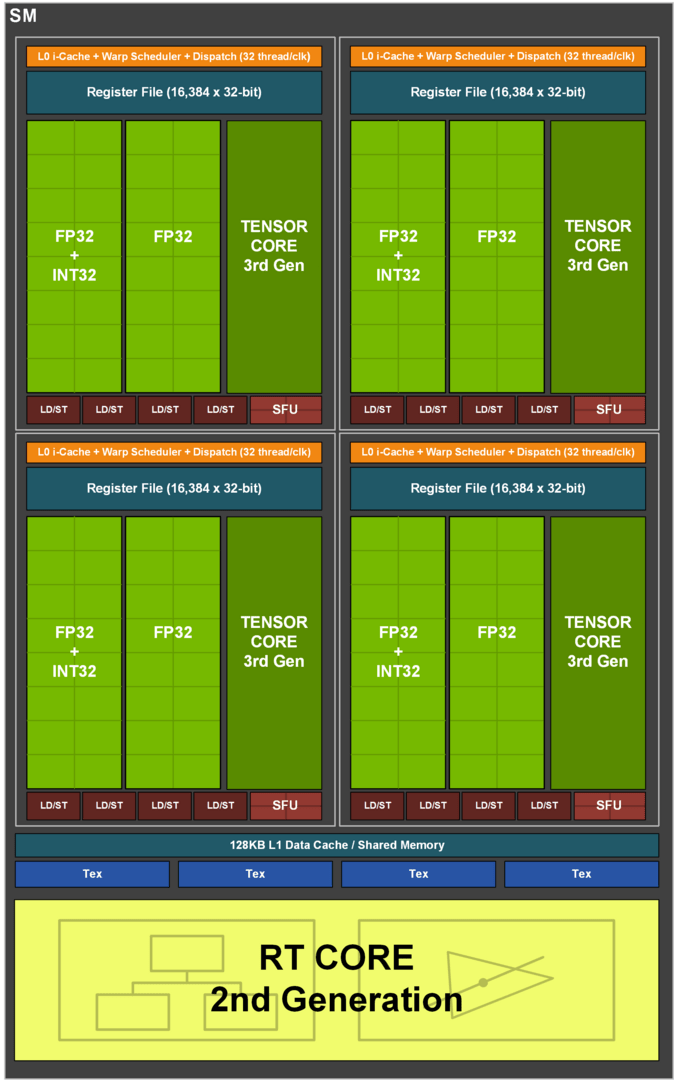 Ein SM von Ampere (Bild: Nvidia)
Ein SM von Ampere (Bild: Nvidia)

Komplexe SMs brauchen Arbeit
Der zweite Aspekt betrifft die Auslastung. Nvidia ändert zwischen den Generationen gerne die Granularität der Streaming Multiprocessors, zuletzt sank die Komplexität deutlich. Hatte ein SM auf Kepler noch 192 FP32-ALUs, waren es ab Maxwell nur noch 128 ALUs. Für Pascal blieb es dabei und bei Turing wurde die Zahl auf 64 ALUs reduziert. Ampere geht nun wieder auf 128 ALUs hoch. Erfahrungsgemäß ist das besser für die maximale Rechenleistung, aber eine Herausforderung für die Auslastung.
Eine große Rolle für eine bessere Auslastung spielen der Shared Memory und der L1-Cache in jedem Streaming Multiprocessor, die nun doppelt so schnell arbeiten wie auf Turing. Der L1-Cache hat auf der GeForce RTX 3080 eine Bandbreite von 219 GB/s, auf der GeForce RTX 2080 Super sind es nur 116 GB/s. Gleichzeitig ist der Cache mit 128 KB anstatt 96 KB bei Ampere 33 Prozent größer. Beides soll dafür sorgen, dass die ALUs zu jederzeit etwas zu berechnen haben.
Die ROPs sind nun im GPC integriert
Bis Turing waren die ROPs immer am Speicherinterface angeschlossen, weshalb ihre Anzahl mit dem Interface schrumpfte oder wuchs. Das ändert sich bei Ampere, dort sind die ROPs ebenfalls im GPC untergebracht. Pro GPC gibt es 2 ROP-Partitions, die jeweils 8 ROPs enthalten.
Das ist auch der Grund, warum es auf Ampere mehr ROPs als bis jetzt angenommen gibt. Bisher konnte man für die GeForce RTX 3090 auf Basis der alten Vorgehensweise von 96 ROPs ausgehen. Pro 32-Bit-Speicherinterface eine ROP-Partition ergäbe bei 12 Interfaces eben jene 96 ROPs. Weil von nun an stattdessen pro GPC zwei ROP-Partitions verbaut sind und der GA102 über deren sieben verfügt, gibt es auf dem GA102 14 Partitions und damit 112 ROPs, die auf dem Consumer-Flaggschiff auch alle aktiviert sind.
Auf der GeForce RTX 3080 ist dagegen ein GPC und damit eine ROP-Partition abgeschaltet, was 96 ROPs übrig lässt, auf dem GA104 der GeForce RTX 3070 sind es ebenso 6 GPCs mit 96 ROPs. Die ROPs an sich sind dabei genauso leistungsstark wie bei der konventionellen Anordnung, der Grund für den Umbau ist die bessere Skalierbarkeit.
Der Rohaufbau im Detail
Der große Gaming-Ampere-Chip GA102 verfügt über 7 GPCs mit je 12 SMs. Bei der GeForce RTX 3090 sind aber nicht alle SMs aktiviert, weil der Chip 10.752 trägt (7 GPC * 12 SM * 128 ALUs), die GeForce RTX 3090 aber nur 10.496 ALUs bietet. Zwei SMs sind deaktiviert.
-
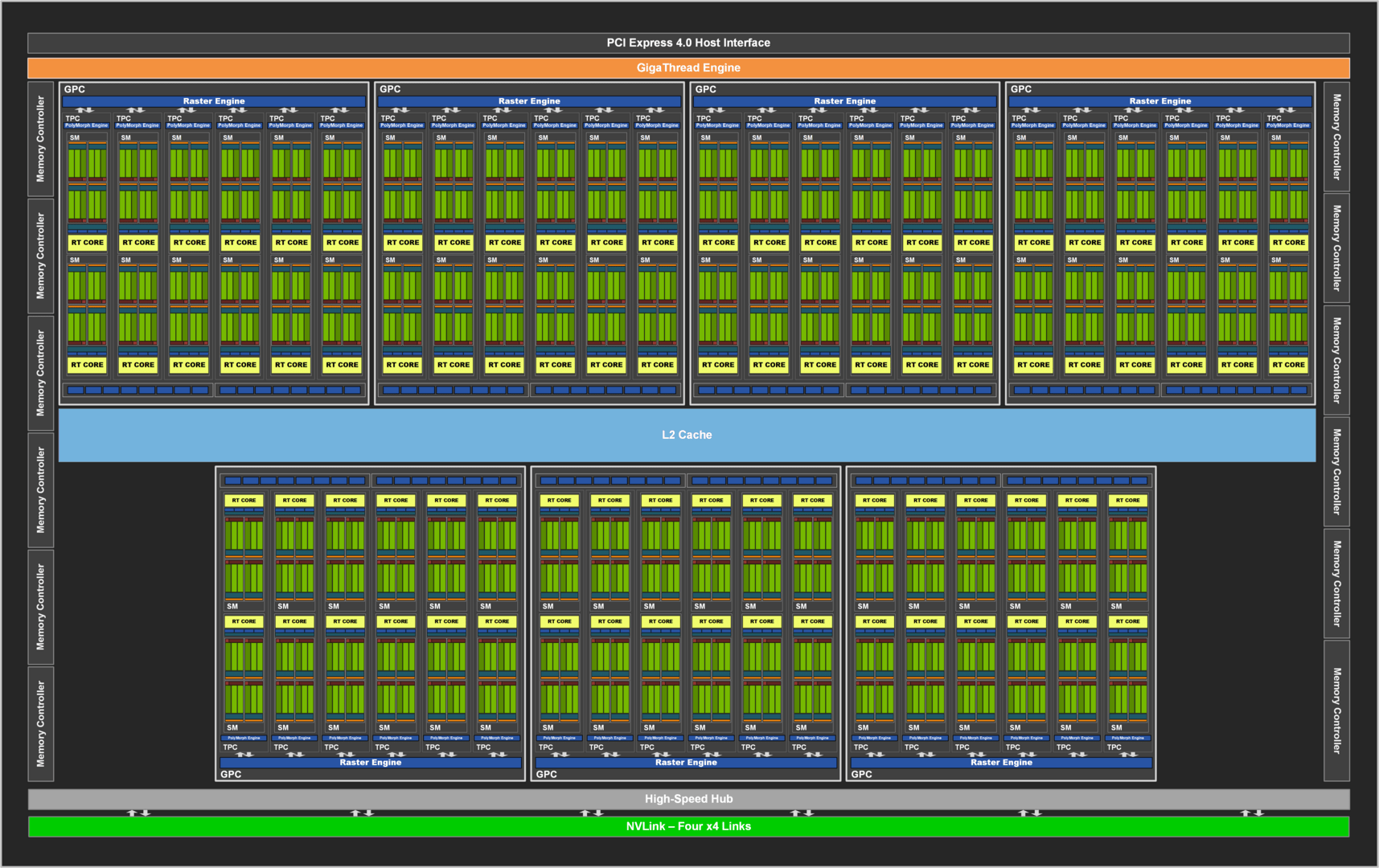 Nvidia GA102 voll aktiviert (Bild: Nvidia)
Nvidia GA102 voll aktiviert (Bild: Nvidia)
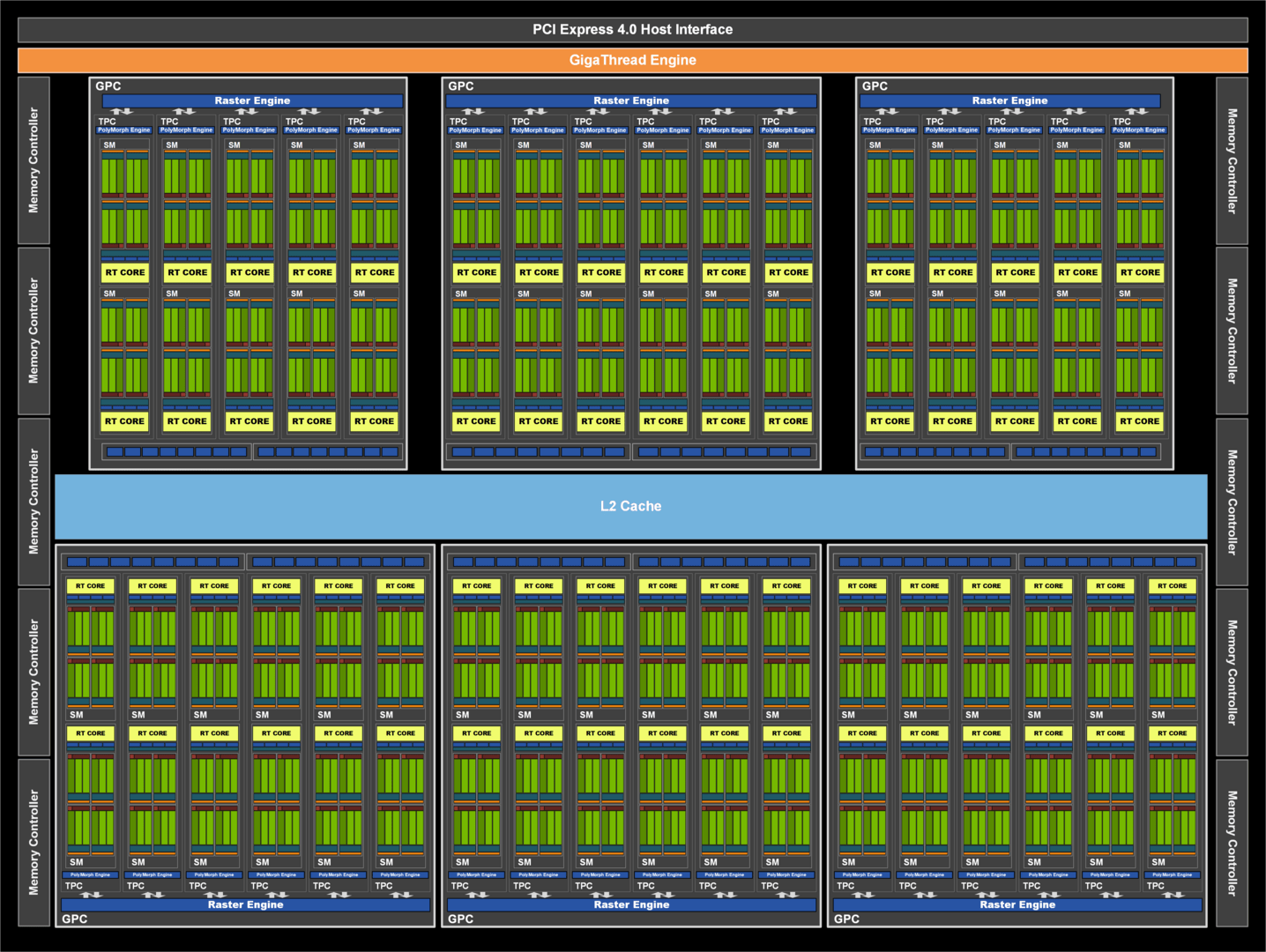
Bei der GeForce RTX 3080 mit derselben GPU ist ein GPC komplett abgeschaltet, von den verbleibenden sechs nutzen nur vier die vollen 12 SMs, zwei sind auf 10 SMs reduziert. Das ergibt mit 68 SMs 8.704 ALUs. Die GeForce RTX 3070 mit GA104-GPU nutzt genauso 6 GPCs, von deren 48 SMs aber zwei abgeschaltet sind, um auf die 5.888 ALUs zu kommen. Die zwei abgeschalteten SMs sind eine Vermutung der Redaktion, alles andere wäre aber sehr ungewöhnlich.
Der L2-Cache ist gleich groß wie bei Turing
Turings TU102-GPU bietet einen 6 MB großen L2-Cache. Zuletzt wuchs dieser von Generation zu Generation an, bei Ampere ist der schnelle Zwischenspeicher aber nicht angewachsen. Der GA104 hat einen 4 MB großen L2-Cache und der GA102 besitzt 6 MB, wobei diese aber nur auf der GeForce RTX 3090 aktiv sind. Die GeForce RTX 3080 bietet nur 5 MB, da jeder 32-Bit-Speichercontroller über 512 KB L2-Cache verfügt.
Die Effizienz ist gestiegen
Nvidia spricht bei Ampere beziehungsweise der GeForce RTX 3080 von einer um 90 Prozent besseren Leistung pro Watt im Vergleich zu Turing. Diese Aussage trifft jedoch offenbar nur dann zu, wenn beide Grafikkarten bei derselben Framerate limitiert werden – Turing ist in diesem Szenario also stärker als Ampere ausgelastet.
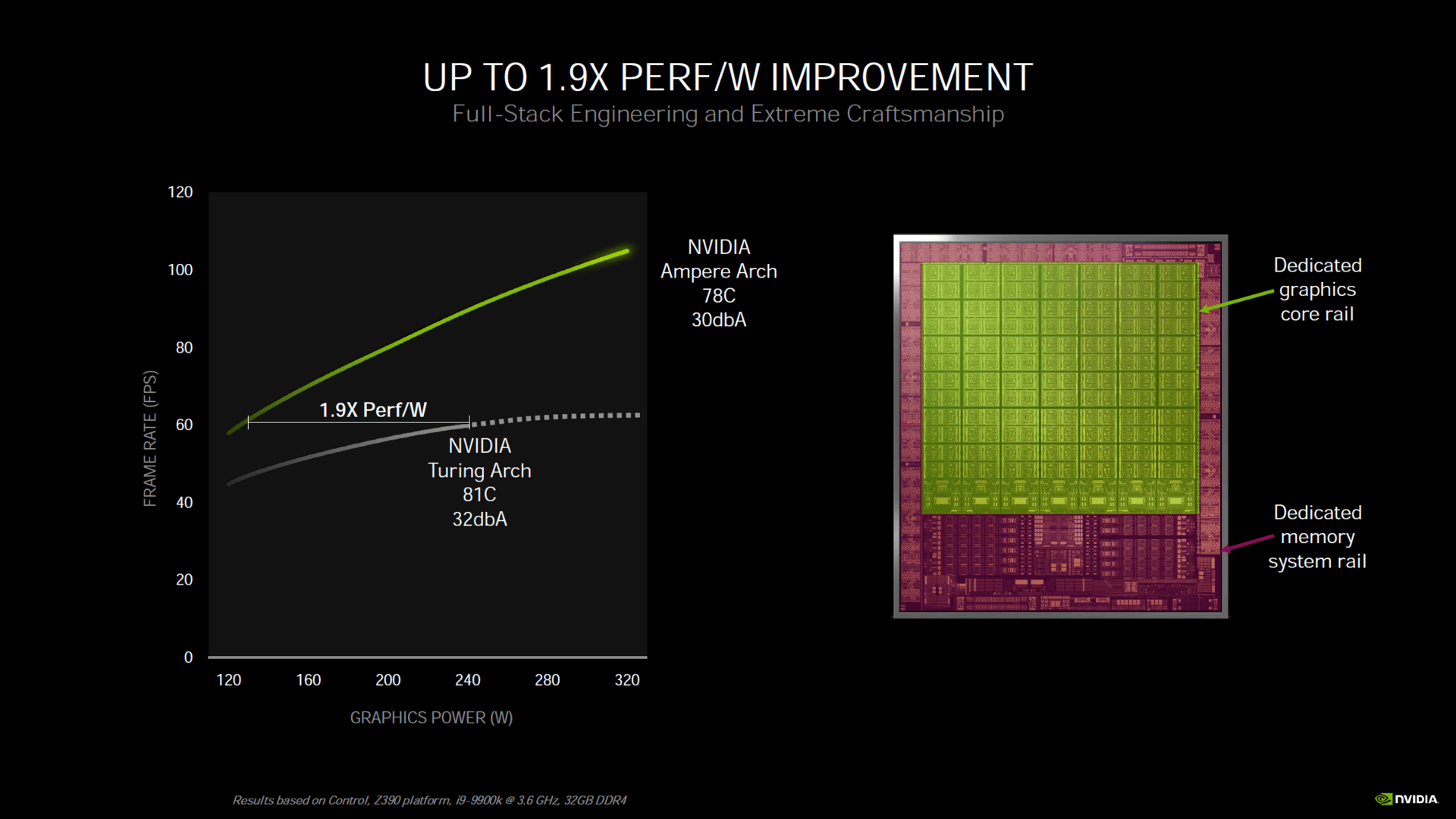
Einen Effizienzfortschritt gibt es dennoch und dafür ist nicht nur die neue Fertigung verantwortlich. Darüber hinaus haben das Rechen- und das Speichersystem zwei voneinander unabhängige Spannungsschienen erhalten. Das hat einen Vorteil: Wenn zum Beispiel die Shadereinheiten eine hohe Spannung für maximale Leistung benötigen, das Speichersystem aber wenig zu tun hat, können die Speichercontroller mit geringerer Spannung fahren – oder anders herum. Wie oft so ein Szenario eintrifft, ist unklar.