Instinct MI100: Die schnellste FP32/FP64-Karte kommt von AMD

Mit der Instinct MI100 greift AMD im HPC-Segment Nvidias A100 an. Den Fokus rückt der Hersteller dabei primär auf FP32 und FP64, wobei die neue Profi-Karte bei FP64 die weltweit schnellste Lösung sein soll. Die Vergleiche zu Nvidias Ampere-Generation sind trotzdem nicht einfach, denn Nvidia sucht ihre Stärken im Int8-Bereich.
AMD geht mit dem neuen Monster die andere Richtung. Mit über 11,5 TFLOPs in FP64-Umgebungen bietet sie fast 20 Prozent mehr Leistung als Nvidias A100 mit 9,7 TFLOPS, in FP32-Anwendungen verdoppelt sich der Wert wie üblich, 23,1 TFLOPs erreicht AMDs neue Instinct MI100, Nvidias A100 steht bei 19,5 TFLOPs.
Doch spätestens ab hier wird das Bild verwaschen, denn nun gibt es diverse Spezialfälle und Umgebungen. AMD gibt beispielsweise FP32 (Matrix) mit 46,1 TFLOPs an, Nvidia hingegen mit TF32 (als neuer Standard für FP32-Operationen) 160 TFLOPS. Geht es weiter zu INT4/INT8 sitzt AMD bei 184,6 TOPS, Nvidia mit ihren speziellen Tensor Cores liegt mit 624 TOPS massiv in Front. Und wenn gar die Sparsity-Beschleunigung genutzt wird, verdoppeln sich die Zahlen bei Nvidia noch einmal.
Am Ende sind MI100 und A100 also schnell zwei Lösungen für unterschiedliche Märkte.
-
 AMD Instinct MI100 (Bild: AMD)
AMD Instinct MI100 (Bild: AMD)



AMD vertraut bei der MI100 noch einmal auf die Vega-Architektur, die von nun an jedoch unter CDNA läuft. Damit ist der Split ganz offiziell, Gaming-Lösungen und Profi-Grafikkarten sollen zukünftig getrennt entwickelt werden. Natürlich wird auf das jeweilige Know-How des anderen zurückgegriffen, doch hinsichtlich des anvisierten Marktes angepasst.
CDNA ist eine reine Compute-Lösung und verzichtet vollständig auf die sogenannte fixed-function hardware, hat deshalb unter anderem keinerlei Video-Einheiten und somit keine Grafikausgänge. Hardwarebeschleunigung für Video-Inhalte bleibt jedoch vorhanden, denn diese wird mitunter auch im HPC-Umfeld gebraucht.
Unlike the graphics-oriented AMD RDNA family, the AMD CDNA family removes all of the fixed-function hardware that is designed to accelerate graphics tasks such as rasterization, tessellation, graphics caches, blending, and even the display engine. However, the AMD CDNA family retains dedicated logic for HEVC, H.264, and VP9 decoding that is sometimes used for compute workloads that operate on multimedia data, such as machine learning for object detection. Removing the fixed-function graphics hardware frees up area and power to invest in additional compute units, boosting performance and efficiency.
-
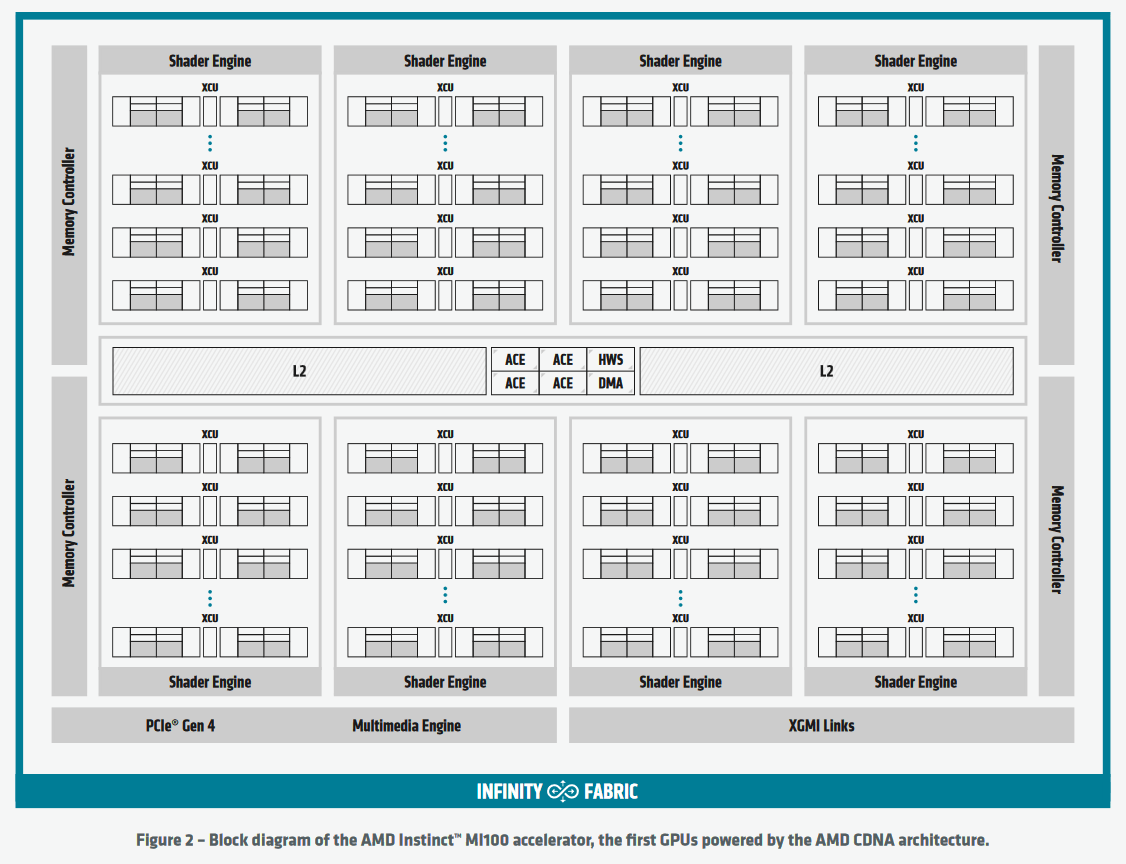 AMD MI100 – Blockdiagramm (Bild: AMD)
AMD MI100 – Blockdiagramm (Bild: AMD)
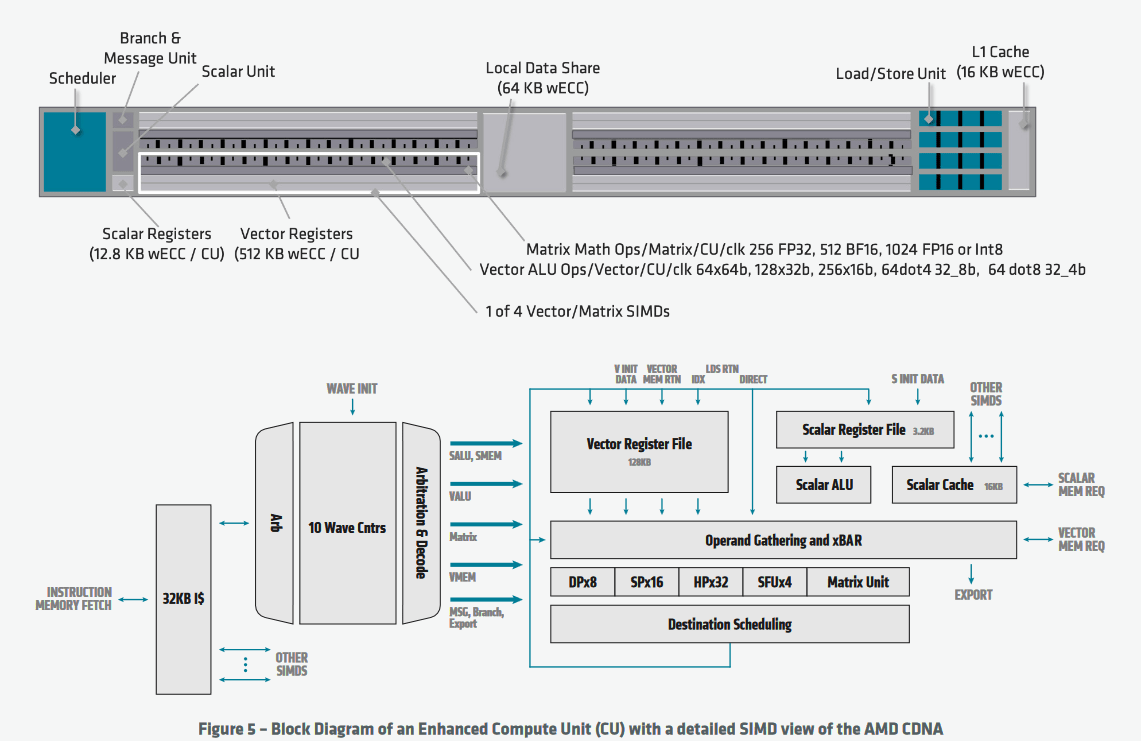

Satte 120 CUs und somit 7.680 ALUs sind auf dem Chip zugegen, der mit einem Takt von 1.502 MHz gefahren wird. Angeschlossen sind vier 8 GByte große HBM2-Chips, die mit 1,2 GHz takten und so eine Bandbreite von 1,2 TByte/s bieten. Gegen Nvidias bisherige Ampere-Lösung wäre das ausreichend, doch diese haben heute mit einem 80-GByte-Flaggschiff dank HBM2e noch einmal nachgelegt. Dort wird die Bandbreite auf über 2 TByte pro Sekunde angehoben.
Die Kommunikation mit der Außenwelt der passiv gekühlten 300-Watt-TDP-Karte erfolgt über das PCI-Express-Interface nach 4.0-Standard. Drei weitere MI100-Karten in einem gleichen System werden via Infinity Fabrik Link verbunden.
-
 AMD Instinct MI100 im Quartett (Bild: AMD)
AMD Instinct MI100 im Quartett (Bild: AMD)

Preis und Verfügbarkeit
Am Ende soll auch der Preis Kunden von der neuen AMD Instinct MI100 überzeugen. Den gibt der Hersteller mit 6.400 US-Dollar an, während AMD erklärt, dass Nvidias A100 zwischen 9.800 und 11.300 US-Dollar kostet, sofern man diese im Handel erwirbt. Eine offizielle Preisgestaltung nennt Nvidia nicht.
Verbaut werden sollen die neuen HPC-Karten sowohl in Servern mit AMD Epyc als auch Intel Xeon unter anderem von Dell, Gigabyte, HPE und auch Supermicro. Die Verfügbarkeit soll noch im November gewährleistet sein.
ComputerBase hat Informationen zu diesem Artikel von AMD unter NDA erhalten. Die einzige Vorgabe war der frühest mögliche Veröffentlichungszeitpunkt.
Im Nikolaus-Rätsel 2025 geht es um einen High-End-PC und neun weitere Preise vom OLED-Display bis zum...