AMD Ryzen 5000 im Test: 5950X, 5900X, 5800X & 5600X sind Hammer 2.0

tl;dr: Ryzen 5000 mit Zen 3 hält, was AMD verspricht: Ryzen 9 5950X, 5900X, Ryzen 7 5800X und Ryzen 5 5600X schlagen im Test Intel Core auch in Spielen. Die Redaktion analysiert AMDs neue „Hammer-CPU“ in umfassenden Benchmarks inklusive Blick auf IPC, Taktverhalten, (IF-)OC und Stromverbrauch.
Die Redaktion hat die vergangenen Wochen genutzt, um die Testergebnisse sukzessive um weitere Prozessoren zu erweitern. Bei den Anwendungs-Benchmarks finden sich jetzt alle vier neuen Ryzen 5000 im jeweiligen Eco-Mode in den Benchmarks wieder, bei den Spiele-Benchmarks wurden sechs weitere Prozessoren, darunter fünf ältere Modelle, aufgenommen. Neu in den Spiele-Benchmarks enthalten sind:
- AMD Ryzen 3 3300X (4K/8T)
- AMD Ryzen 7 2700X (8K/16T)
- AMD Ryzen 5 2600X (6K/12T)
- Intel Core i7-8700K (6K/12T)
- Intel Core i7-7700K (4K/8T)
- Intel Core i5-7600K (4K/4T)
Die Aufnahme älterer CPUs in den Spiele-Testparcours unterstreicht zum einen noch einmal, welchen Sprung Ryzen 5000 mit Zen 3 gegenüber Ryzen 3000 hingelegt hat. Zum anderen zeigt sich, wie schwer es mittlerweile Vier-Kern-CPUs in aktuellen Spielen haben: Ohne Hyper-Threading liegt der Core i5-7600K weit abgeschlagen auf dem letzten Platz und auch dem Core i7-7700K mit Hyper-Threading bleibt bei den Frametimes nur der vorletzte Platz.
So wird der Eco-Mode aktiviert
Der Eco-Modus lässt sich bei Ryzen auf manchen Mainboards direkt im BIOS aktivieren, auf anderen ist er nach Aktivierung von Presicion Boost Overdrive im BIOS dann im Tool Ryzen Master als Profil auswählbar.
| Prozessor | Standard | Eco-Modus | ||
|---|---|---|---|---|
| TDP | max. Verbrauch | TDP | max. Verbrauch | |
| Ryzen 9 5950X | 105 Watt | 142 Watt | 65 Watt | 88 Watt |
| Ryzen 9 5900X | 105 Watt | 142 Watt | 65 Watt | 88 Watt |
| Ryzen 7 5800X | 105 Watt | 142 Watt | 65 Watt | 88 Watt |
| Ryzen 5 5600X | 65 Watt | 76 Watt | 45 Watt | 60 Watt |
Die dritte Zen-CPU-Architektur-Generation als Basis der 4. Generation Ryzen-CPUs betrat Anfang Oktober mit einem neuerlichen Paukenschlag die Bühne: AMD sah die eigenen CPUs in allen Disziplinen und damit auch in Spielen jetzt vor Intel. Nach der fulminanten Ankündigung vor einigen Wochen soll sich ab sofort jeder von den hochgesteckten Zielen überzeugen können, denn ab sofort sind die vier Prozessoren der neuen Familie Ryzen 5000 im Handel zu bekommen – und das Embargo für den Test ist gefallen.
ComputerBase hat sich zum Start direkt mit allen vier Modellen befasst, nur zwei kamen von AMD. Umfangreiche Tests auf zwei Plattformen, ein vollständig überarbeiteter Spiele-Parcours mit Nvidia GeForce RTX 3080 als schnelle GPU in Tests von 720p bis 2160p und viele Sondertests auch zur IPC-Entwicklung seit Zen 1, dem Taktverhalten unter Last, Übertaktung des Infinity-Fabric auf jenseits von 2.000 MHz und vieles mehr runden die Betrachtung ab.

Modelle, Preise, Verfügbarkeit und Taktangaben
Vier Modelle bringt AMD zum Start von Ryzen 5000 mit Zen 3 auf den Markt. Die Staffelung ist dabei klar, jeweils einen Prozessor mit 16, 12, 8 oder 6 Kernen gibt es. Dabei geht zwar vorerst die Vielfalt der Vorgängergeneration verloren, doch AMD betont, dass die Neulinge quasi obendrauf gesetzt werden. Vor allem im Einstiegsbereich bleiben die bisherigen Prozessoren also noch die erste, weil einzige Wahl. Über die kommenden Monate dürften kleinere CPUs folgen. Auch preislich ist das wünschenswert, denn unter 300 Euro gibt es zum Start kein Zen 3.
Der gestiegene Einstiegspreis ist auf den Ryzen 5 5600X zurückzuführen, der das Portfolio mit 299 Euro UVP eröffnet. Einen Ryzen 5 5600 für etwas über 200 Euro gibt es vorerst nicht. Auch Ryzen 7 5800X und Ryzen 9 5900X haben höhere Listenpreise als ihre Vorgänger zum Start, da diese bereits deutlich im Preis gefallen sind, ist der Aufpreis zu Beginn groß. Kostspielig bleibt das Topmodell, dessen Preis AMD mit „Weil es nichts vergleichbares gibt.“ einordnet. Interessanterweise ist es trotzdem die einzige CPU, deren UVP in Deutschland leicht gefallen ist – in den USA ist der Preis 50 US-Dollar höher.
| Kerne/Threads | Takt Basis / Turbo | L3 | TDP | Preis (Marktstart) | |
|---|---|---|---|---|---|
| Ryzen 9 5950X | 16/32 | 3,4 / 4,9 GHz | 64 MB | 105 W | 799 Euro |
| Ryzen 9 3950X | 16/32 | 3,5 / 4,7 GHz | 64 MB | 105 W | 819 Euro |
| Ryzen 9 5900X | 12/24 | 3,7 / 4,8 GHz | 64 MB | 105 W | 549 Euro |
| Ryzen 9 3900XT | 12/24 | 3,8 / 4,7 GHz | 64 MB | 105 W | 529 Euro |
| Ryzen 9 3900X | 12/24 | 3,8 / 4,6 GHz | 64 MB | 105 W | 529 Euro |
| Ryzen 7 5800X | 8/16 | 3,8 / 4,7 GHz | 32 MB | 105 W | 449 Euro |
| Ryzen 7 3800XT | 8/16 | 3,9 / 4,7 GHz | 32 MB | 105 W | 419 Euro |
| Ryzen 7 3800X | 8/16 | 3,9 / 4,5 GHz | 32 MB | 105 W | 429 Euro |
| Ryzen 7 3700X | 8/16 | 3,6 / 4,4 GHz | 32 MB | 65 W | 349 Euro |
| Ryzen 5 5600X | 6/12 | 3,7 / 4,6 GHz | 32 MB | 65 W | 299 Euro |
| Ryzen 5 3600XT | 6/12 | 3,8 / 4,5 GHz | 32 MB | 95 W | 259 Euro |
| Ryzen 5 3600X | 6/12 | 3,8 / 4,4 GHz | 32 MB | 95 W | 265 Euro |
| Ryzen 5 3600 | 6/12 | 3,6 / 4,2 GHz | 32 MB | 65 W | 209 Euro |
Takt: Eher mehr denn weniger als angegeben
Gegenüber dem jeweiligen Vorgänger liegen die neuen CPUs beim Takt nur 100 bis 200 MHz höher, im Alltag könnte der Zuwachs allerdings größer ausfallen. Der Grund: AMDs offizielle Angaben sollen konservativ gesetzt sein – tendenziell ist in der Praxis also mehr möglich.
Bei Ryzen 2000 und insbesondere Ryzen 3000 sah das anders aus: Der angepriesene maximale Boost-Takt wurde in vielen Systemen nicht einmal bei geringer Last, geschweige denn in klassischen Single-Core-Last-Szenarien erreicht. Erst die Mischung aus BIOS-Updates und optimierter Treiberunterstützung sorgte Wochen später für beruhigte Gemüter, wenngleich der angegebene Takt oft nicht dauerhaft unter Last anlag. In Bezug auf Ryzen 5000 erklärte Joe Marci als CTO aller AMD-Produkte nun, dass „jede CPU das liefern wird, was ausgewiesen ist – und darüber hinaus gehen kann“.
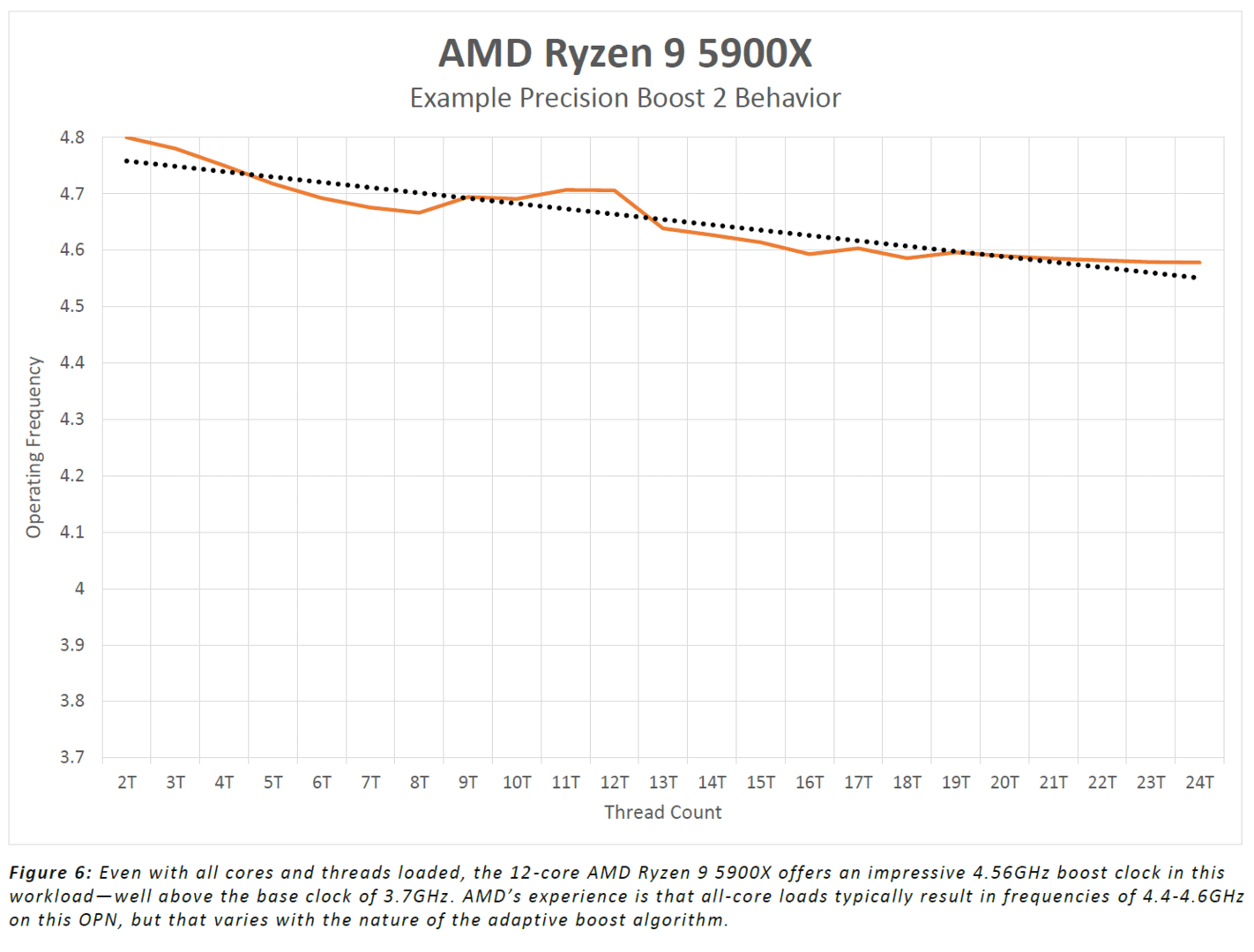
So viel sei an dieser Stelle schon verraten: Im Test haben es alle vier neuen CPUs geschafft, das unter Beweis zu stellen – bis hinauf zum Topmodell Ryzen 9 5950X mit über 5,0 GHz unter Single-Core-Last.
Warum Ryzen 5000 statt Ryzen 4000?
Warum hat AMD den Produktnamen Ryzen 4000 bei den reinen CPUs im Vergleich zu den Renoir-APUs übersprungen? Eben genau deshalb, weil Ryzen 4000 jetzt schon wieder im Markt für Notebooks und in OEM-Desktops zugegen ist, allerdings auf Basis von Zen 2, und mit dem Schritt auf Zen 3 diesem Treiben endlich einmal ein Ende gesetzt wird.

Dabei waren laut AMD auch banale Aspekte zu berücksichtigen: Was wirft Google aus, wenn man Ryzen 4000 sucht und doch eigentlich eine neue CPU haben möchte? Zu viele Falschmeldungen vermutlich, musste selbst AMD eingestehen. Die Zeit war also reif für den großen Sprung, den Zen 3 auch als Produkt verdient haben soll: Ryzen 5000.
Das Versprechen: Überall Platz 1
Nicht weniger als CPUs, die Intel überall überlegen sind, hat AMD mit Ryzen 5000 in Aussicht gestellt. Vor acht Jahren war das noch ein Traum, erklärt AMDs Technical Marketing Director Robert Hallock. Jetzt soll es soweit sein, denn Gaming lag im Fokus der Entwicklung.
Jede der vier neuen Ryzen-5000-CPUs soll so die beste Lösung in ihrer Klasse sein. Aus 40 Spielen in Full-HD-Auflösung gewinnt der Ryzen 9 5900XT laut AMD 30 Titel gegen Intels Flaggschiff Core i9-10900K – mit einer RTX 2080 Ti. Wird die Grafikkarte auf eine RTX 3080 aufgewertet, gewinnt AMDs Lösung gegenüber Intels Prozessor mehr an Leistung als der Gegenspieler – ein Blick in die Zukunft. Das gilt auch beim Blick auf die 720p-Auflösung – mindestens gleichwertige, in sechs von acht Fällen sogar höhere Leistung will AMD gegenüber Intel bieten. Und nicht nur für die großen Modelle, auch die kleinen sollen mehr als nur mitspielen.
-
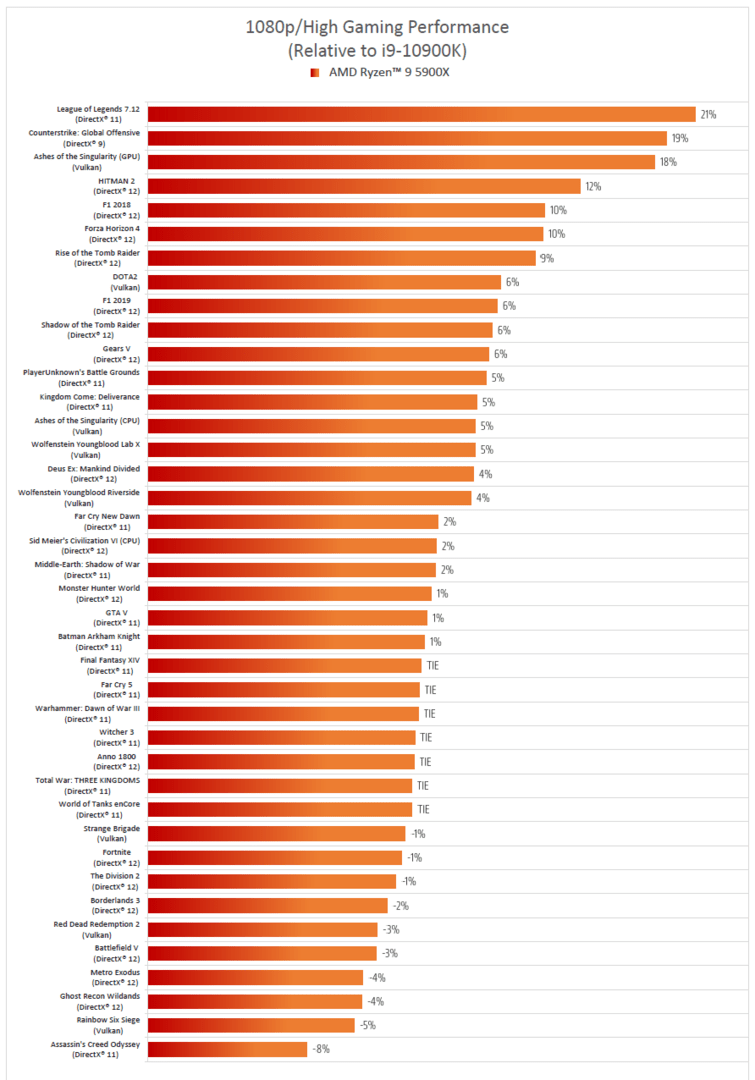 Gaming-Leistung laut AMD für Ryzen 9 5900X gegen Intel Core i9-10900K (Bild: AMD)
Gaming-Leistung laut AMD für Ryzen 9 5900X gegen Intel Core i9-10900K (Bild: AMD)
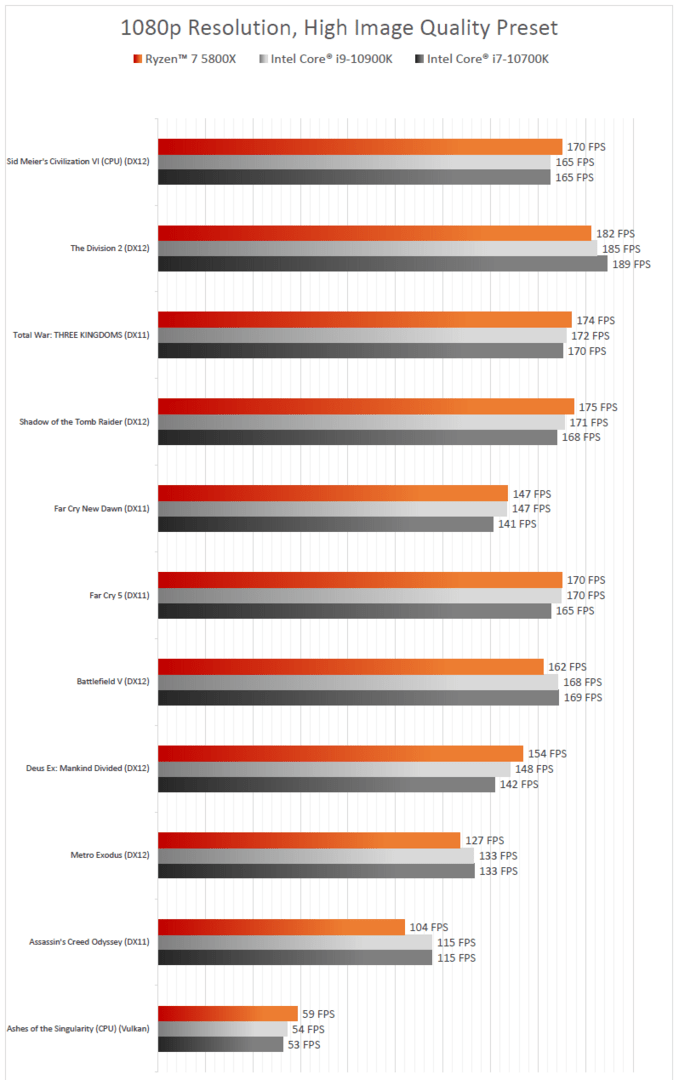
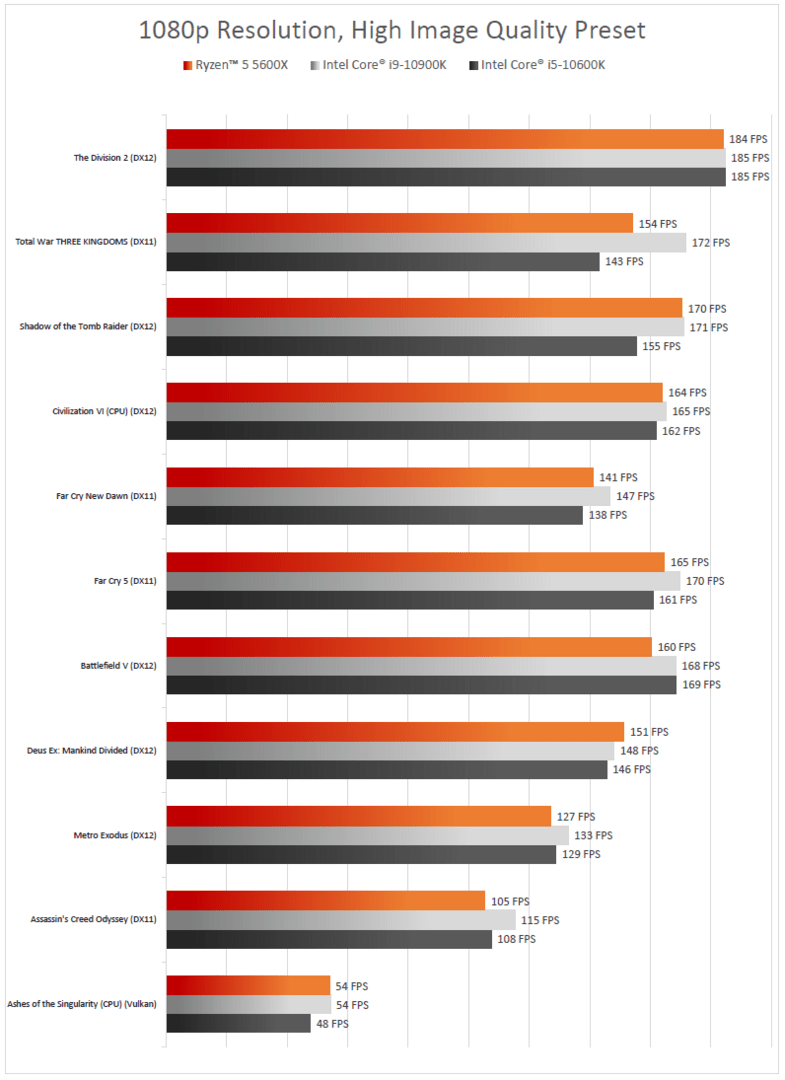
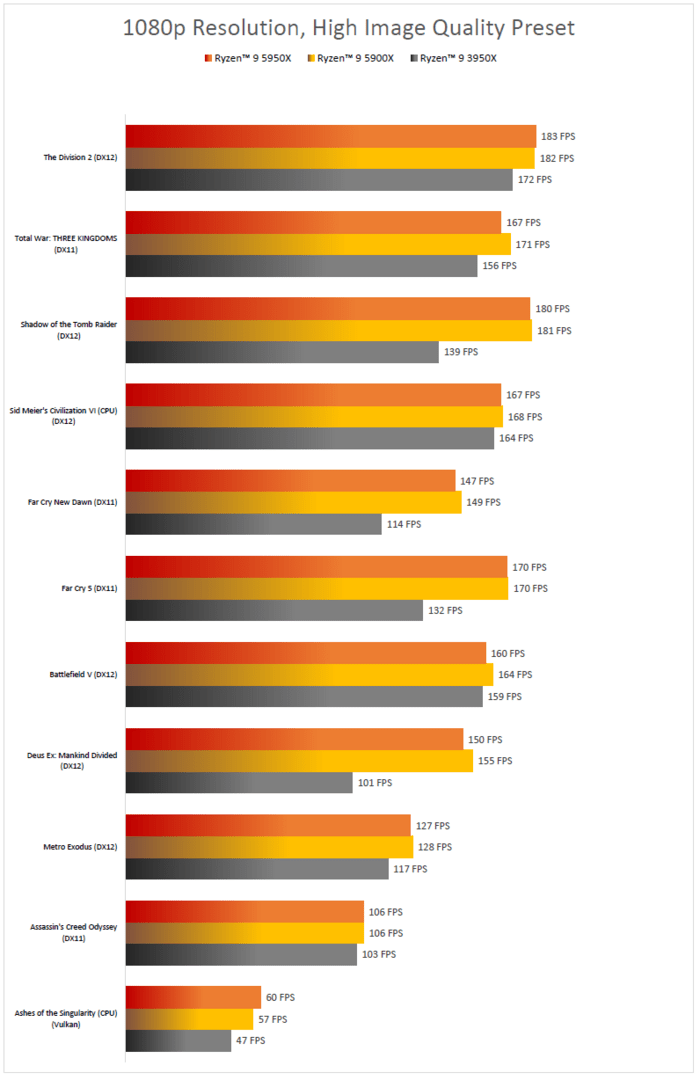
So wurde Ryzen 5000 getestet
Um AMDs Ankündigungen standesgemäß nachzugehen, hat ComputerBase Ryzen 5000 ausgiebig und in Teilen mit brandaktuellen Benchmarks unter Zuhilfenahme aktueller Grafikkarten getestet.
Alle vier Ryzen 5000 im Test
ComputerBase standen für den Test vorab alle vier neuen CPUs zur Verfügung. Von AMD wurden die zwei großen Modelle Ryzen 9 5950X und Ryzen 9 5900X unter NDA zur Verfügung gestellt, von Caseking kamen Ryzen 7 5800X und Ryzen 5 5600X.
Alle in diesem Artikel präsentierten Spiele-Benchmarks, IPC- und Taktanalysen wurden im Oktober/November 2020 neu erstellt. Alle Rechner setzten auf das aktuelle Windows 10 2004 mit allen aktuellen Updates inklusive aller Sicherheitspatches, die Mainboards waren mit dem jeweils aktuellsten BIOS ausgestattet.
Auch die Anwendungs-Benchmarks zu den neuen Ryzen 5000 sowie alle IPC- und Taktanalysen in Benchmarks wurden auf dem aktuellen Software-Stand getestet, ältere CPUs in den Anwendungs-Benchmarks hingegen noch auf Basis von Windows 10 1909.
Alle Plattformen wurden, sofern möglich, mit den identischen Speicher-Timings betrieben. Als RAM-Takt kam in den Standardbenchmarks die jeweilige Vorgabe des Herstellers zum Einsatz.
| Plattform | Takt | Primär-Timings | Modus |
|---|---|---|---|
| AMD Ryzen 1000 | DDR4-2666 | 14-14-14-14-34-1T | Dual-Channel |
| AMD Ryzen 2000 | DDR4-2933 | 14-14-14-14-34-1T | Dual-Channel |
| AMD Ryzen 3000 | DDR4-3200 | 14-14-14-14-34-1T | Dual-Channel |
| AMD Ryzen 5000 | DDR4-3200 | 14-14-14-14-34-1T | Dual-Channel |
| AMD Ryzen Threadripper 1000 | DDR4-2666 | 14-14-14-14-34-1T | Quad-Channel |
| AMD Ryzen Threadripper 2000 | DDR4-2933 | 14-14-14-14-34-1T | Quad-Channel |
| AMD Ryzen Threadripper 3000 | DDR4-3200 | 14-14-14-14-34-1T | Quad-Channel |
| Intel Core i 10000(K) | DDR4-2666 (-2933) | 14-14-14-14-34-1T | Dual-Channel |
| Intel Core i 9000 | DDR4-2666 | 14-14-14-14-34-1T | Dual-Channel |
| Intel Core i 8000 | DDR4-2666 | 14-14-14-14-34-1T | Dual-Channel |
| Intel Core i 7000 | DDR4-2400 | 14-14-14-14-34-1T | Dual-Channel |
| Intel Core i 4000 | DDR3-1600 | 9-9-9-9-24-1T | Dual-Channel |
| Intel Core i 2000 | DDR3-1333 | 9-9-9-9-24-1T | Dual-Channel |
| Intel Core X 9000 | DDR4-2400 | 14-14-14-14-34-1T | Quad-Channel |
| Intel Core X 7000 | DDR4-2400 | 14-14-14-14-34-1T | Quad-Channel |
Bei AMD Ryzen Threadripper war der DLM-Modus aktiv, Intel Core X nutzte den Turbo 3.0.
Als Kühler wurde in den Anwendungs-Tests stets ein Noctua NH-U14S mit zwei NF-A15-Lüftern verwendet, für die Spiele-Benchmarks kam der Noctua NH-D15S zum Einsatz. Ausgewählte CPUs wurden darüber hinaus mit der EK-AIO 240 D-RGB von EKWB sowie AMDs Wraith-Boxed-Kühler getestet. Wie das nachfolgende Diagramm zeigt, sind Leistungsunterschiede unter hoher Mehrkern-Last bei Ryzen 5000 messbar, aber nicht gravierend.
Spiele-Benchmarks mit GeForce RTX 3080 FE
Um die CPU in den Spiele-Tests bestmöglich von einem GPU-Limit zu befreien, kam die Nvidia GeForce RTX 3080 Founders Edition (Test) mit dem Treiber 456.71 zum Einsatz.

Getestet wurden zehn Spiele in den drei Auflösungen 720p, 1080p und 2160p – also von „zeigt CPU-Unterschiede deutlich auf“ bis hin zu „CPU-Unterschiede im GPU-Limit“. Dabei wurde die Auswahl mit Absicht nicht nur auf Triple-A-Titel ausgelegt, auch Free2Play-Titel, die eine schiere Masse an Spielern anziehen, sind wie etwa Valorant vertreten. Aber auch das Gegenstück für maximale Prozessorlast in einem Triple-A-Titel wie Total War: Troy (Test) ist mit von der Partie.
Da zwischen Nvidia GeForce RTX 3000 und AMD Ryzen nicht genug Zeit blieb, um an die 70 Prozessoren aus dem Anwendungs-Parcours komplett neu zu vermessen, lag der Fokus im ersten Test auf Zen 3, dem Vorgänger Zen 2 sowie den Gegenspielern von Intel Core in der neuesten Ausführung Comet Lake. Die Comet-Lake-Prozessoren eignen sich aufgrund der gleichen Architektur in den letzten fünf Jahren allerdings gut, um alte Modelle abzubilden, weil neue Modelle quasi älteren Vorgängern entsprechen: Ein Core i7-10700K ist quasi ein Core i9-9900K und ein Core i5-10600K ist das, was früher einmal ein Core i7-8700K war.
Als Gaming-Grundlage für AMD-Prozessoren nutzt ComputerBase ein gehobenes Mittelklasse-Mainboard, das MSI B550 Tomahawk. Das BIOS trägt Version A45 mit AGESA ComboAM4v2 1.1.0.0 Patch C – neuer ging es vor dem Start von Zen 3 nicht. Neue Anwendungs-Benchmarks sowie Analysen werden auf dem Asus Crosshair VIII X570 Hero mit BIOS 2401 inkl. AGESA V2 PI 1.1.0.0 Patch C gefahren. Bei Intel kommt eine Z490-Lösung zum Einsatz, exakt die gleiche wie beim Start des Core i9-10900K (Test) im Mai.


