Dojo: Tesla zeigt eigenen D1-Chip und ExaFLOPS-Supercomputer

Für das Training künstlicher neuronaler Netze setzt Tesla derzeit noch auf Beschleuniger von Nvidia. Mit dem Dojo und den eigens entwickelten Prozessoren „D1“ baut sich Tesla derzeit aber einen eigenen Supercomputer auf, der mehr Leistung bei weniger Verbrauch und Platzbedarf liefern soll. Dojo soll über 1 ExaFLOPS erreichen.
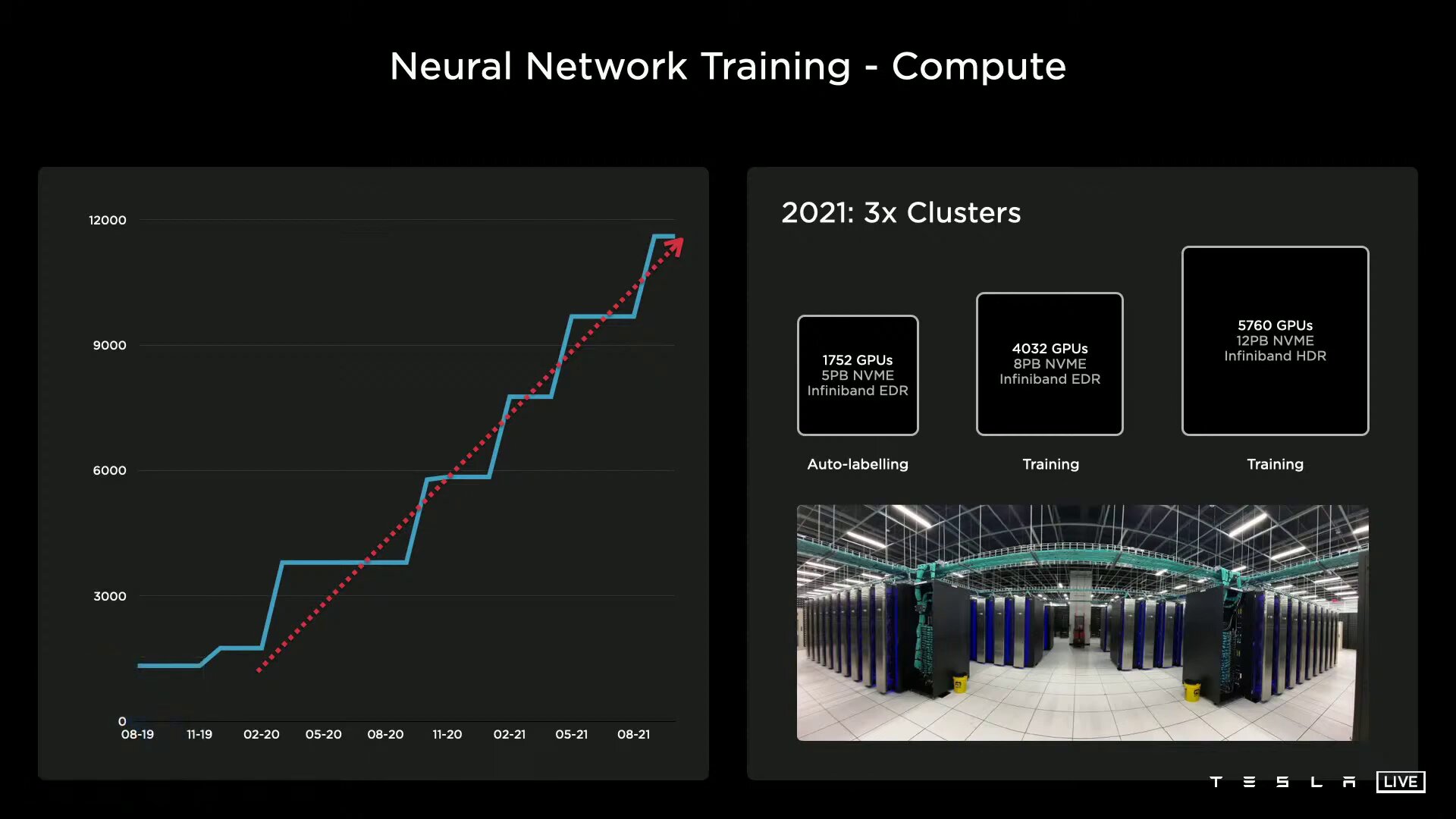
Eigens entwickelte Hardware steht nach dem Full Self-Driving Computer (FSD) im Auto auch im Datacenter von Tesla an. In beiden Bereichen zieht Nvidia den Kürzeren, denn langfristig gesehen sollen die Ampere-Beschleuniger von eigenen Tesla-Prozessoren abgelöst werden. Für das Training künstlicher neuronaler Netze setzt Tesla derzeit noch auf drei Cluster, die mit in Summe 11.544 Nvidia-GPUs arbeiten. Für das automatisierte Labeling kommt ein kleineres Cluster mit 1.752 GPUs, 5 PB NVMe-Storage und InfiniBand-Adaptern für die Vernetzung der Komponenten zum Einsatz, während zwei größere Cluster, einmal mit 4.032 GPUs und 8 PB NVMe-Storage sowie einmal mit 5.760 GPUs und 12 PB NVMe-Storage, für das Training mit in Summe 9.792 GPUs verantwortlich sind.
D1-Chip kommt auf 50 Milliarden Transistoren
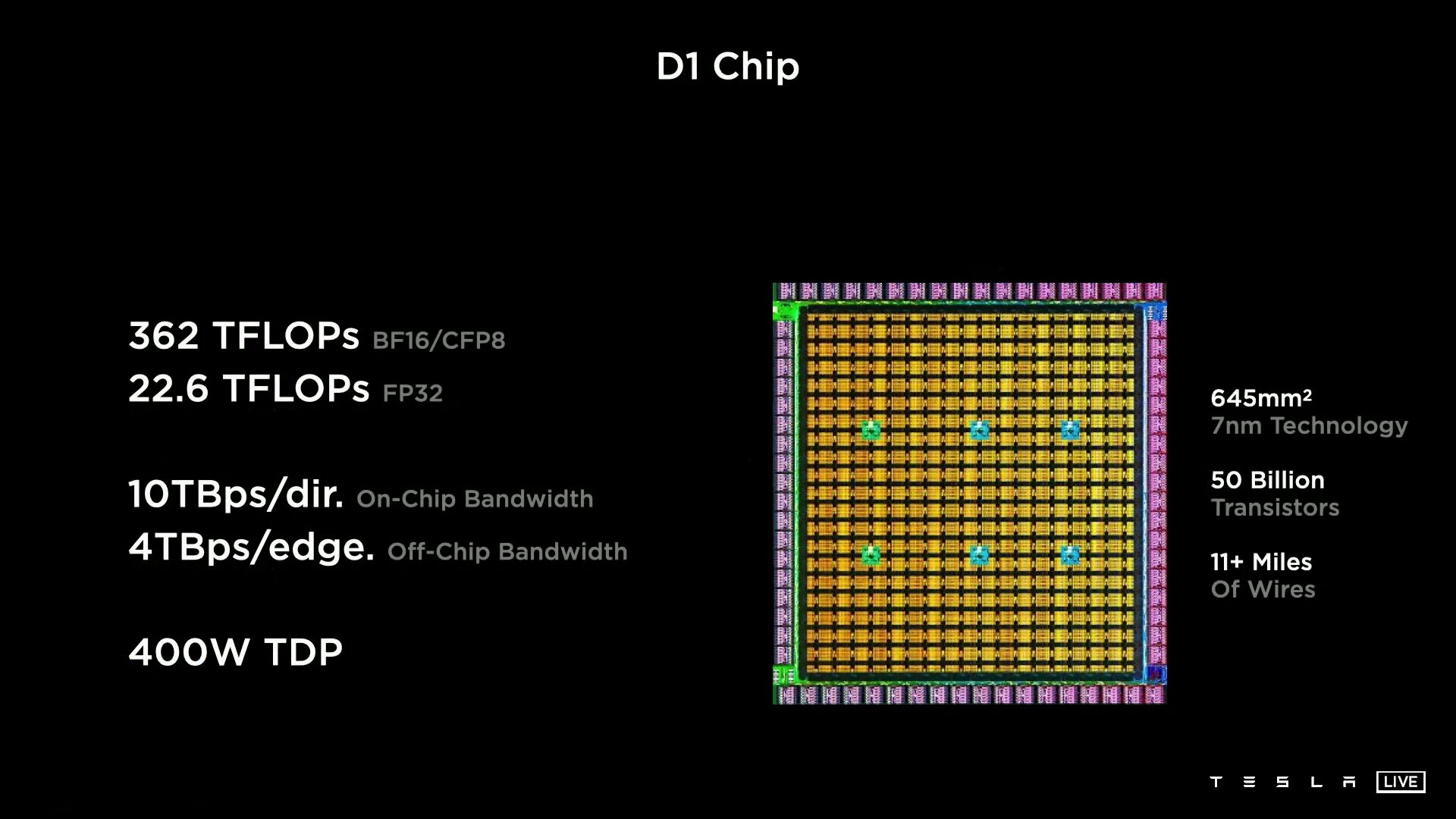
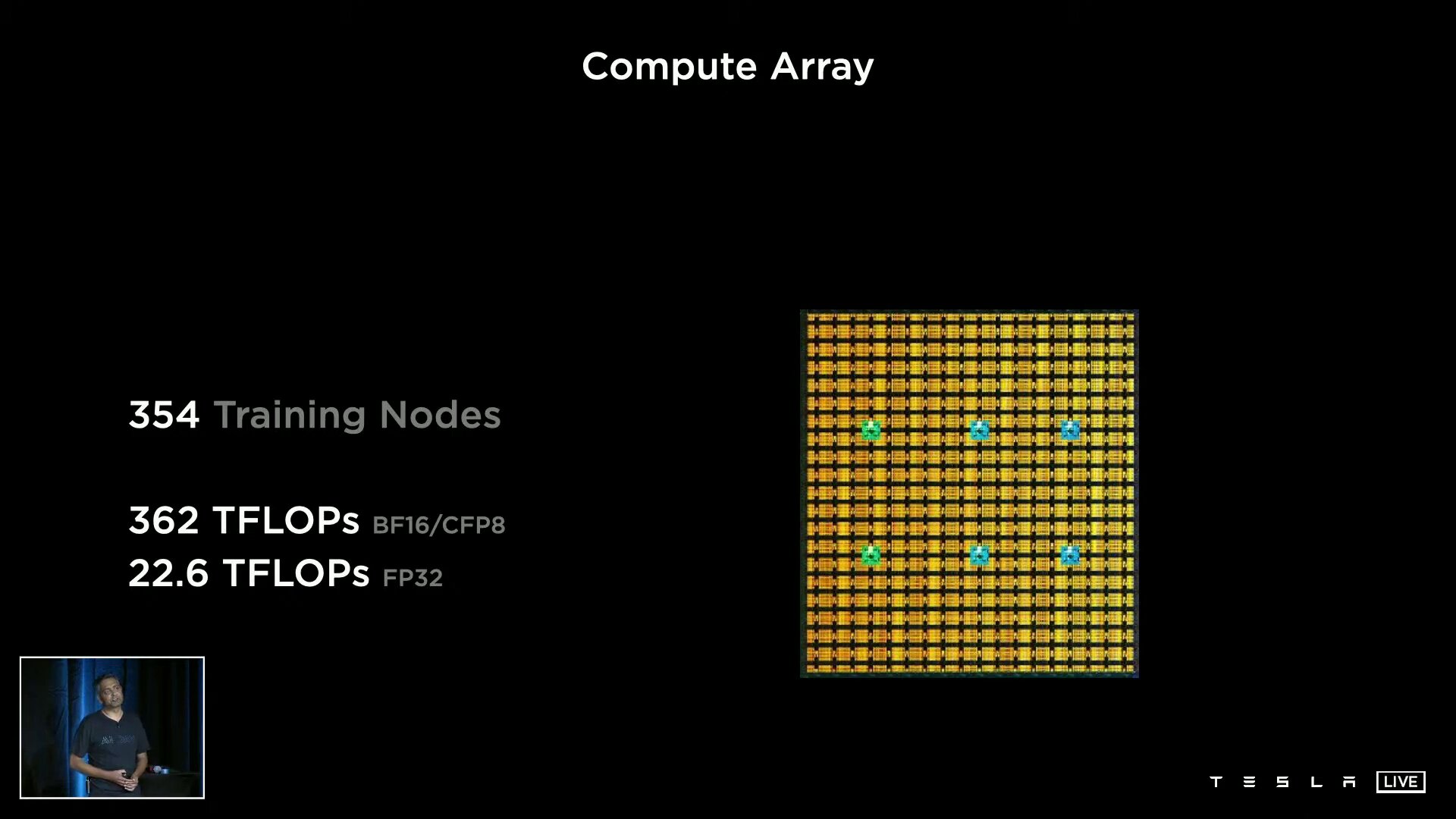
Mit „Project Dojo“ will sich Tesla eine eigene Supercomputer-Architektur aufbauen. Herzstück ist der eigens entwickelte D1-Chip mit 50 Milliarden Transistoren aus 7-nm-Fertigung auf einer Fläche von 645 mm². Der Prozessor liefert eine Rechenleistung von 362 TFLOPS bezogen auf BF16 und CFP8 (Configurable Floating Point 8) und 22,6 TFLOPS für FP32. Tesla gibt die TDP des Chips mit 400 Watt an.
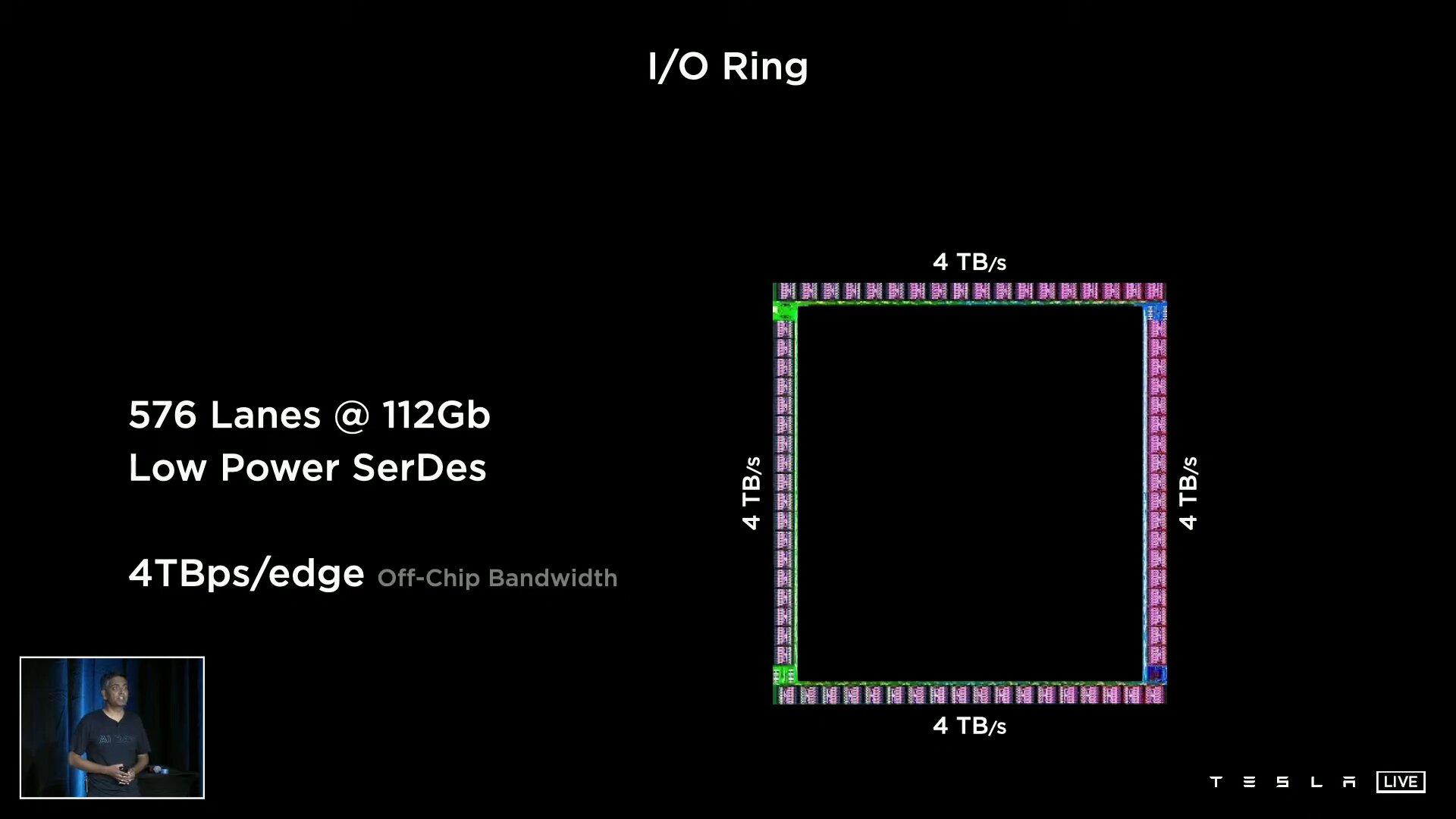
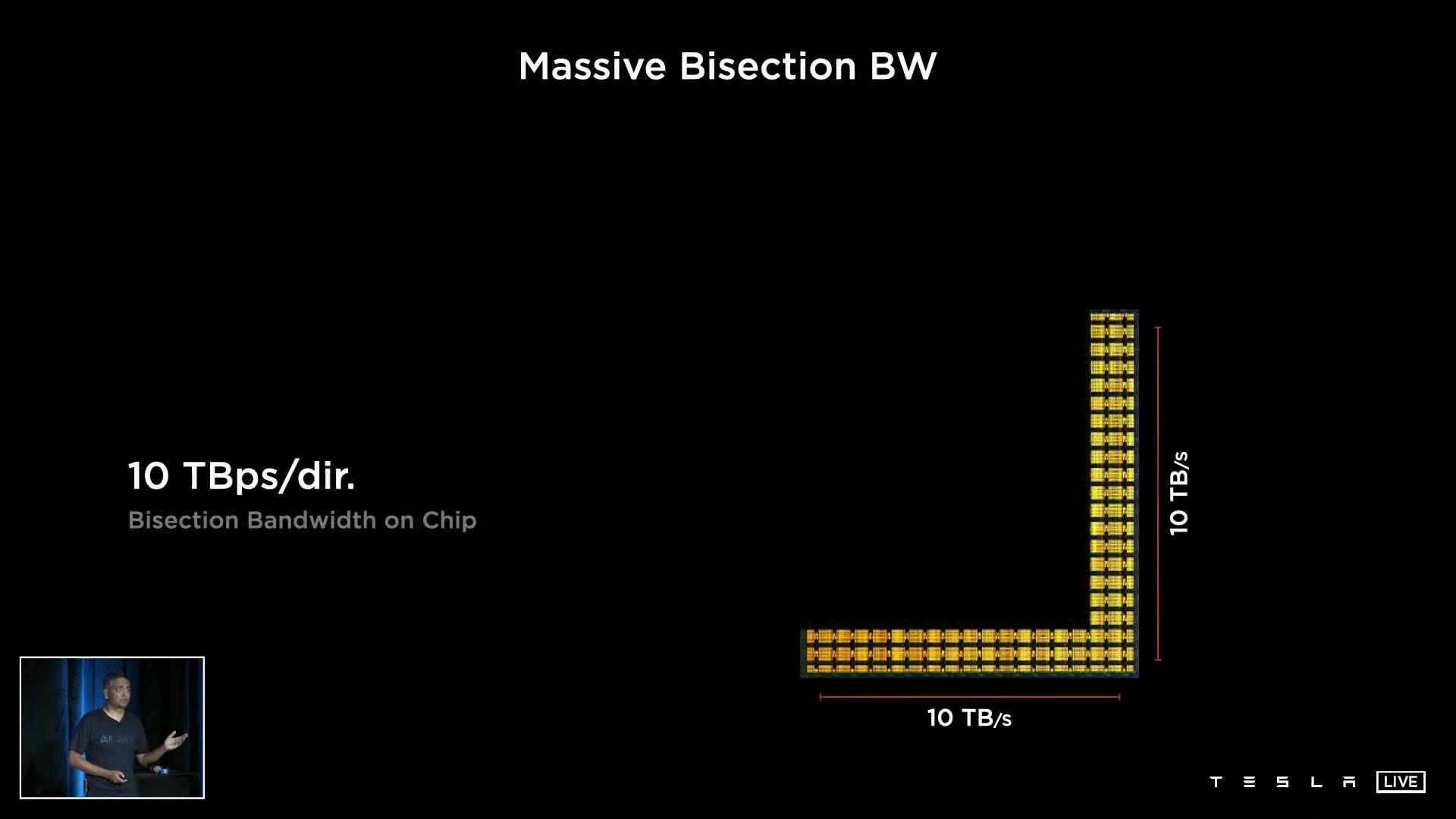
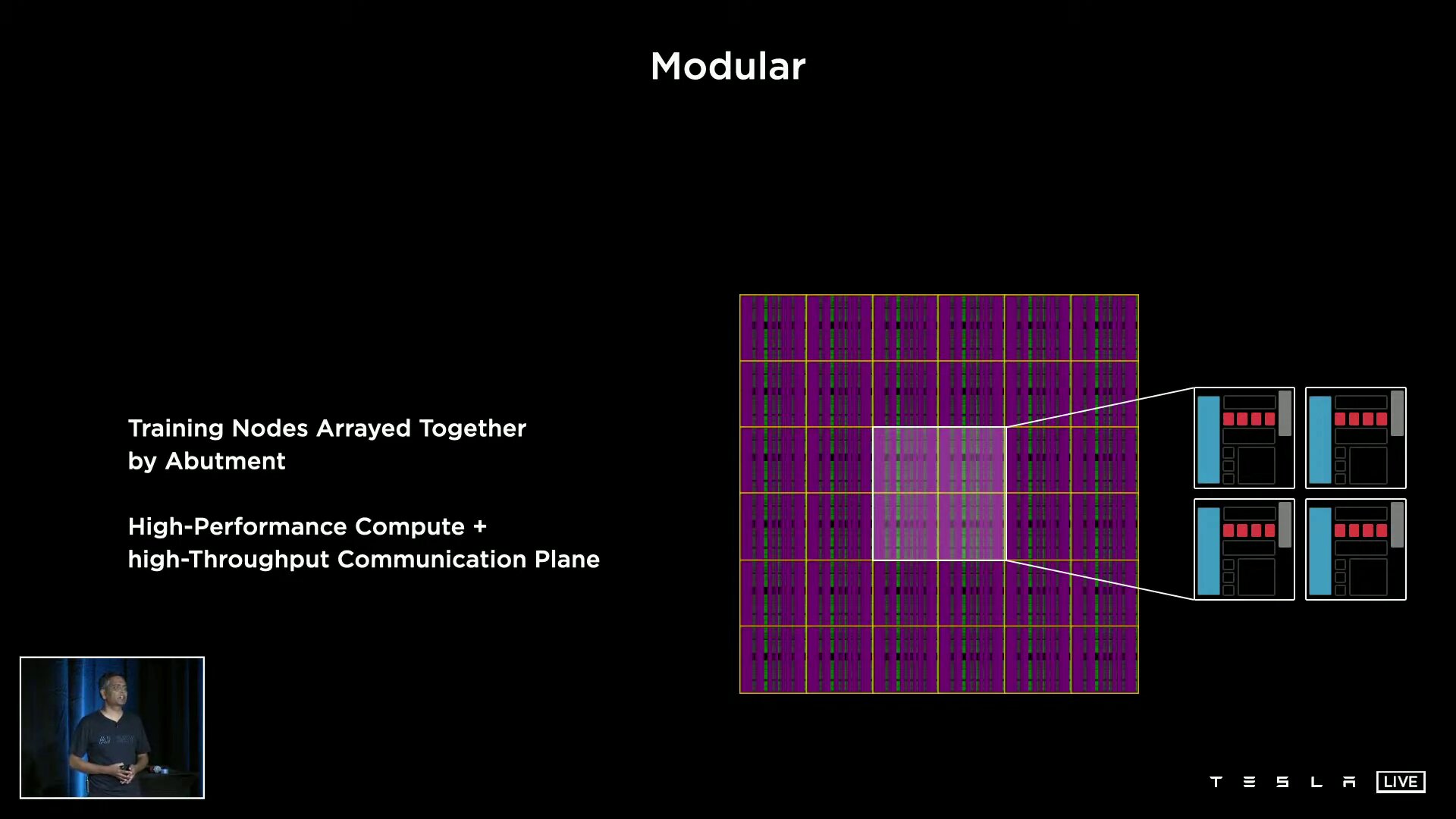
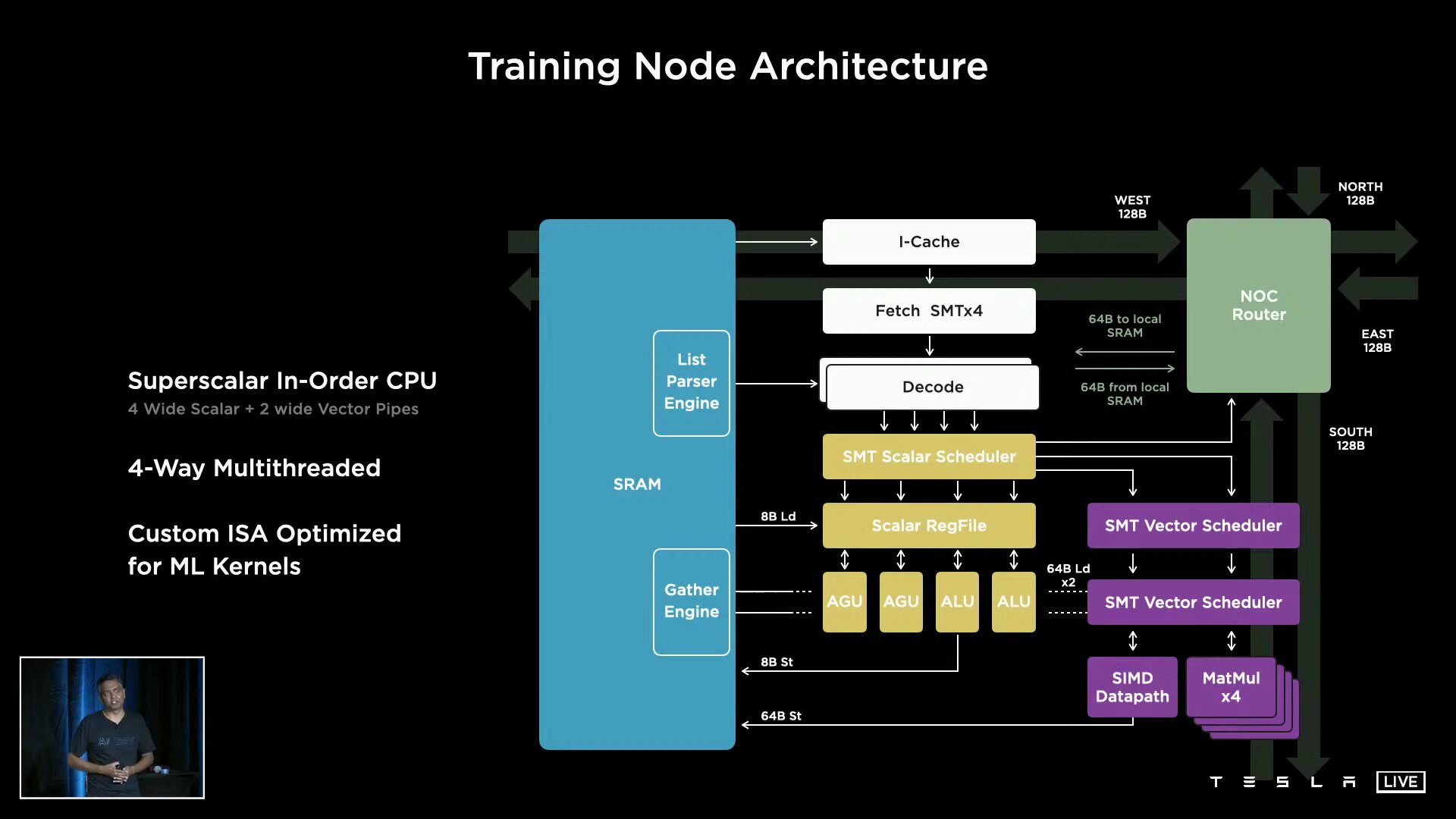
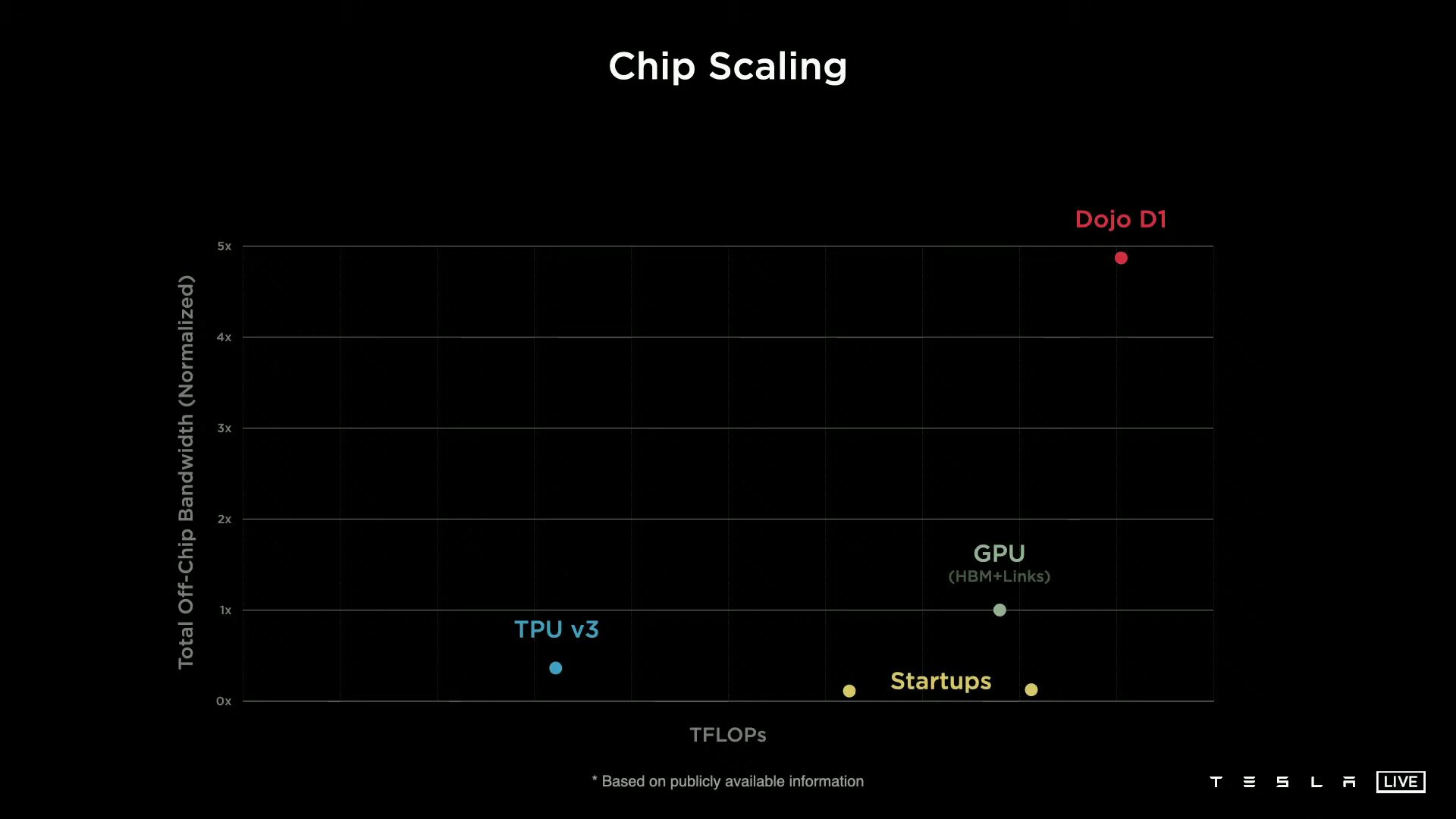
Ein D1 besteht aus 354 Training Nodes, die wiederum jeweils eine 64-Bit-Superscalar-CPU mit vier Kernen beheimaten, die speziell für die 8×8-Matrizenmultiplikation und die Formate FP32, BFP16, CFP8, INT32, INT16 und INT8 ausgelegt ist. Training Nodes sind modular aufgebaut und können laut Tesla in alle Richtungen über ein „Low Latency Switch Fabric“ mit einer On-Chip-Bandbreite von 10 TB/s miteinander verknüpft werden. Um den D1 spannt Tesla einen I/O-Ring mit 576 Lanes à 112 Gbit/s für eine Off-Chip-Bandbreite von 4 TB/s pro Seite.
Skalierbarkeit ohne Flaschenhals
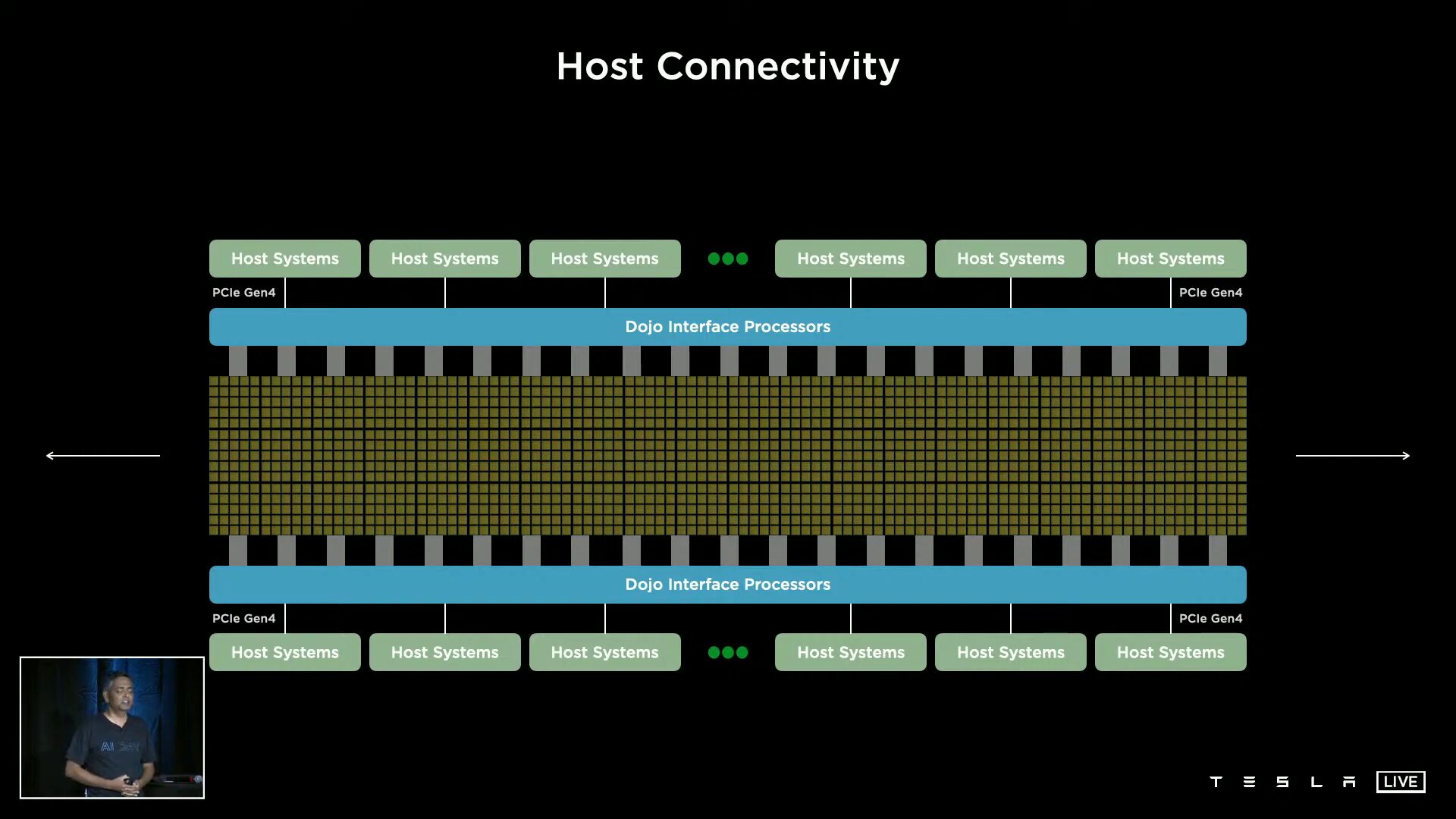
Vorteil der hohen Bandbreite sei die damit mögliche Skalierbarkeit ohne Flaschenhals. Tesla kann beispielsweise 1.500 D1-Chips und somit 531.000 der Training Nodes ohne Einschränkungen miteinander verknüpfen. Auf zwei Seiten dieser D1-Konfiguration kommen „Dojo Interface Processors“ zum Einsatz, die zwar nicht weiter von Tesla erläutert wurden, aber die auf der einen Seite ein Fabric zu den D1 und auf der anderen Seite PCIe Gen4 zu den Hosts im Datacenter aufweisen.
-
 D1-Chip (Bild: Tesla)
D1-Chip (Bild: Tesla)



Training Tile mit 28 Litern Volumen und 9 PetaFLOPS
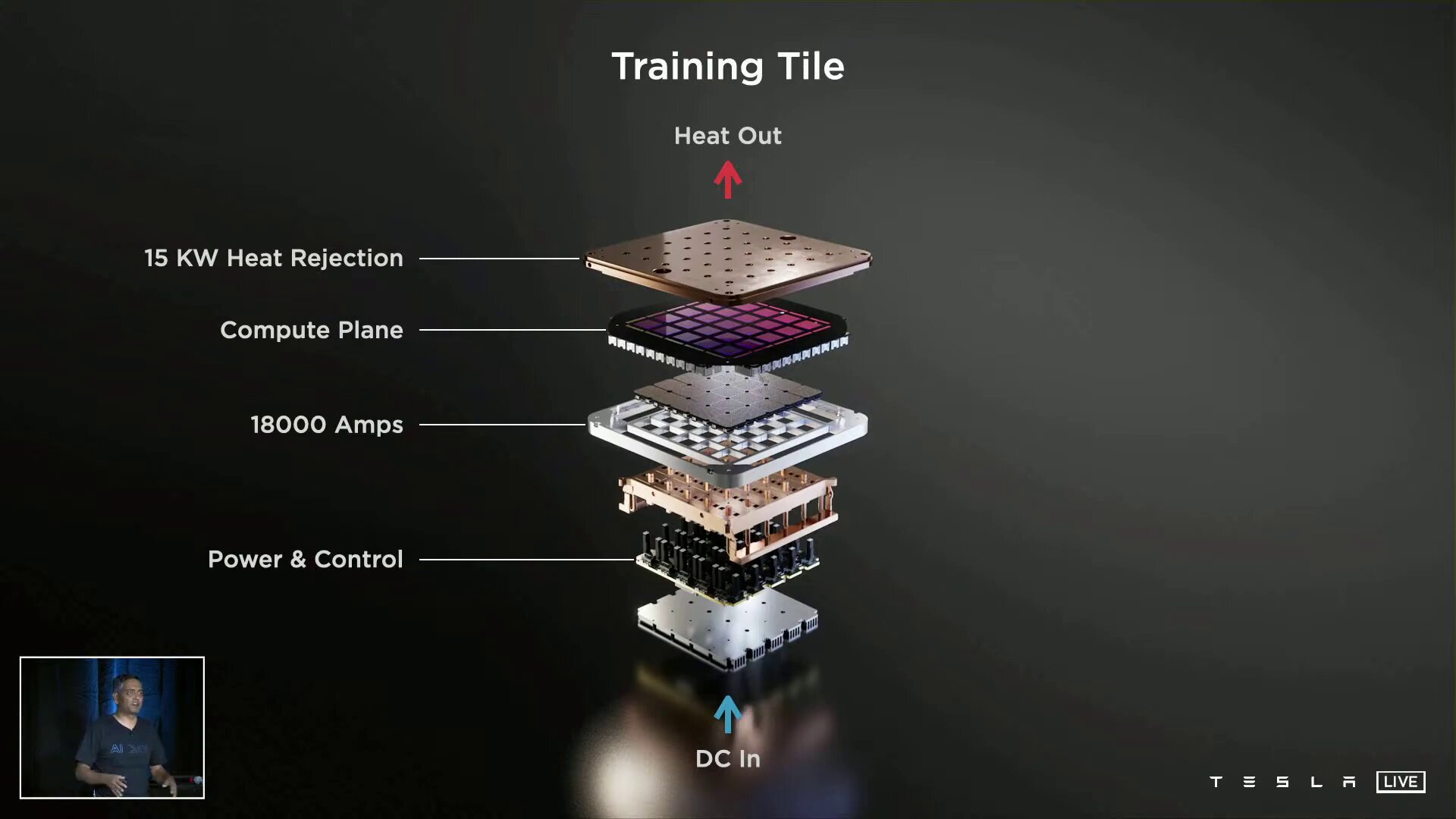
Die insgesamt 1.500 D1-Chips sind allerdings nicht direkt miteinander verknüpft, sondern werden in 5 × 5 Einheiten auf einem sogenannten Training Tile zusammengefasst. Training Tile ist dann auch die Maßeinheit, die Tesla für den gesamten Dojo-Supercomputer nutzt. 25 D1-Dies werden in einem Fan-Out-Wafer-Prozess (vermutlich von TSMC) zu einem Training Tile kombiniert, das wiederum einen eigenen I/O-Ring mit 9 TB/s in vier Richtungen und somit eine Bandbreite von 36 TB/s aufweist. Tesla nennt das Training Tile das aktuell größte „organische Multi-Chip-Modul“ in der Industrie. Für das Design habe Tesla vollständig neue Tools entwickeln müssen, die es zuvor nicht gegeben habe. Ein Training Tile aus 25 D1 liefert 9 PetaFLOPS BF16 oder CFP8.
Kühlung kann 15 Kilowatt abführen
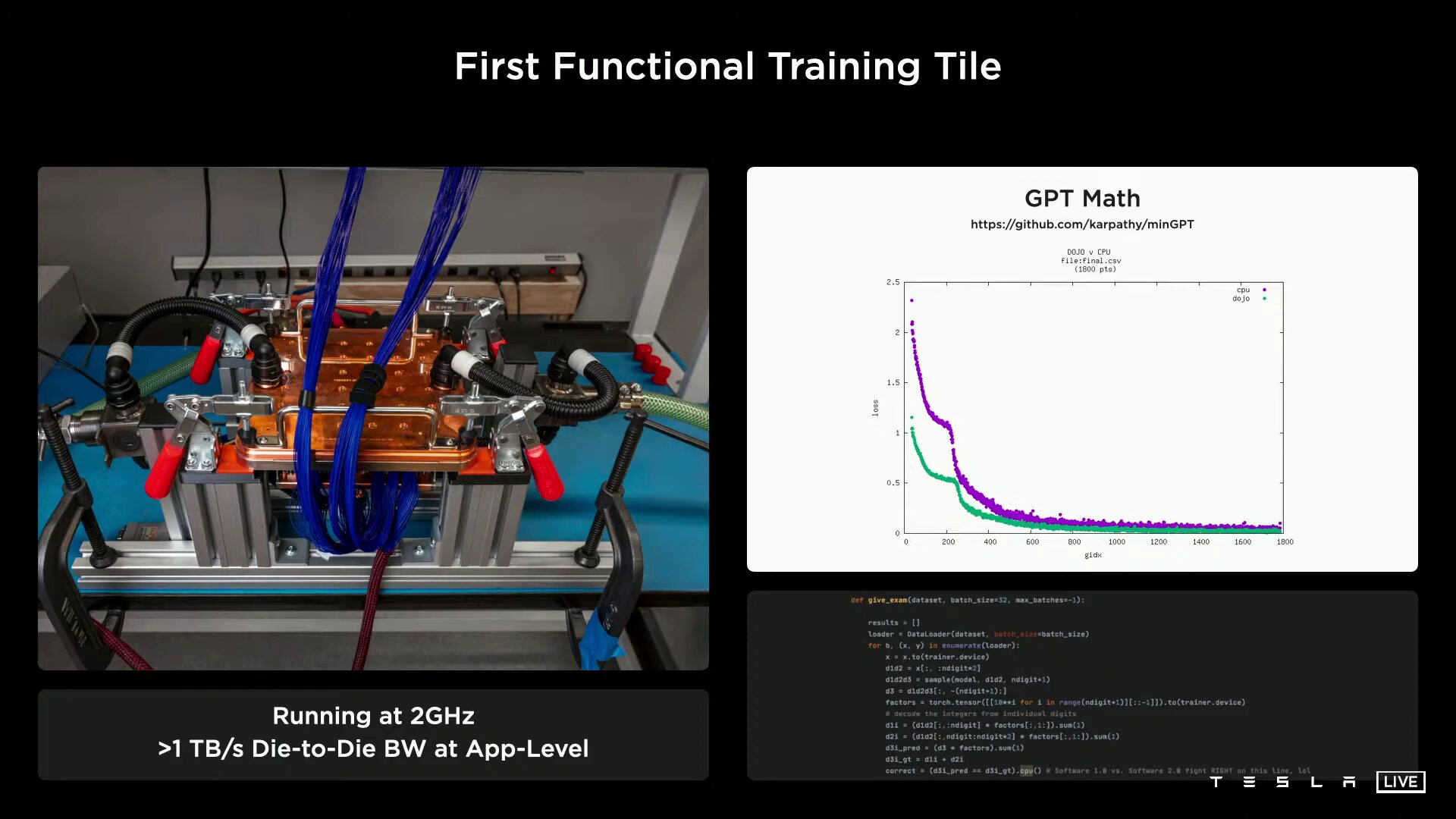
Die Energieversorgung erfolgt vertikal über ein selbst entwickeltes Spannungsreglermodul, das direkt auf den Fan-Out-Wafer aufgebracht wird. Neben dem elektronischen Aufbau mit einer 52 Volt DC-Spannungsversorgung hat Tesla auch den gesamten mechanischen Aufbau inklusive Kühlung eigenständig entwickelt. Letztere muss eine Abwärme von mindestens 25 × 400 Watt nur für D1 abführen können, inklusive der weiteren Komponenten ist die Lösung aber für 15 Kilowatt ausgelegt. Das fertige Modul habe ein Volumen von unter einem Kubikfuß, erklärt Tesla, was etwa 28 Litern entspricht. Letzte Woche habe Tesla ein erstes funktionsfähiges Training Tile bei einer Taktrate von 2 GHz mit eingeschränkter Kühlung auf einem Bench-Table zu Testzwecken in Betrieb genommen.
-
 Training Tiles (Bild: Tesla)
Training Tiles (Bild: Tesla)












Im ExaPOD stecken 120 Tiles für 1,1 ExaFLOPS an BF16-Leistung
Die Training Tiles wiederum fasst Tesla in Trays zu 2 × 3 Tiles und davon wiederum zwei in einem Cabinet (Schrank) zusammen, sodass pro Serverschrank mehr als 100 PetaFLOPS bei einer bidirektionalen Bandbreite von 12 TB/s zur Verfügung stehen. Das Endprodukt ist schließlich der fertige Dojo-Supercomputer „ExaPOD“ mit 120 Training Tiles verteilt über 10 Cabinets und mit insgesamt 3.000 D1-Chips, die wiederum in Summe 1.062.000 Nodes aufweisen. Die gesamte Rechenleistung gibt Tesla mit 1,1 ExaFLOPS für BF16/CFP8 an, der Rechner gewinnt also nicht das weltweite Exascale-Rennen, welches primär an FP64-Anwendungen ausgerichtet ist. Dennoch steht er bei Fertigstellung für den weltweit schnellsten KI-Training-Supercomputer mit viermal höherer Leistung, 30 Prozent höherer Leistung pro Watt und fünfmal kleinerer Grundfläche – bei gleichen Kosten wie bisher mit Nvidia.
-
 3 × 2 Training Tiles × 2 Trays pro Cabinet (Bild: Tesla)
3 × 2 Training Tiles × 2 Trays pro Cabinet (Bild: Tesla)



Ihr habt die Wahl: Macht mit bei den Reader's Choice Awards 2025 und bestimmt eure Hersteller des Jahres!