Intel-Arc-Grafikkarten: Details zu den Gaming-GPUs mit Alchemist-Architektur

Intel hat erste technische Details zur Alchemist-Architektur bekanntgegeben, auf der die GPUs der Gaming-Grafikkarten der Intel-Arc-Serie basieren werden. Auch wenn handfeste Eckdaten oder Benchmarks noch fehlen, wird ersichtlich, in welche Richtung es mit der Technik geht – und wie sehr sich Intel an Nvidia orientiert hat.
Es wird mehrere Alchemist-GPUs geben
Wer hier und heute schon die komplette Vorstellung oder gar Benchmark-Ergebnisse erwartet, der wird enttäuscht. Das war nach der Ankündigung, die ersten Produkte der Arc-Serie werden erst Anfang 2022 erscheinen, aber auch nicht zu erwarten. Nichtsdestoweniger hatte Intel auf einer Veranstaltung am Mittwoch in Berlin ein paar Neuigkeiten im Gepäck.
So bestätigte Intel, dass es mehr als eine GPU (Intel nennt sie SoC) auf Basis der Alchemist-Architektur geben wird. Diese werden nicht bei Intel selbst, sondern bei TSMC im N6-Prozess und damit in einer moderneren Fertigung als AMDs RDNA-2-Generation (N7P) gefertigt. Über Größe und Komplexität der Chips ist bis jetzt noch nichts bekannt, dafür jedoch ein wenig, wie es unter der Haube aussehen wird. Auch die Alchemist-Architektur ist dabei im Kern ein Xe-Derivat, auch wenn es auf den ersten Blick nicht so aussieht.
Alchemist trägt Xe in sich
Denn Intel hat die Namensgebung der einzelnen Elemente für Alchemist geändert um zu verdeutlichen, dass sich die Architektur von den bisherigen IGPs unterscheidet, bleibt im Kern aber genau bei diesem Begriff.
Der grobe Aufbau ähnelt dem bei AMD und Nvidia sehr
Das Herz der Alchemist-Architektur ist der von Intel erstmals so getaufte Xe-Core. Der Xe-Core ist das Äquivalent zu einem Streaming-Multiprocessor bei Nvidia (SM), einer Compute Unit bei AMD (CU) oder eines Subslices nach Intels alter Nomenklatur (EU).
Der Xe-Core besteht unter anderem aus 16 Vector-Engines, die wiederum in 8 Gruppen zu je 2 Vector-Engines unterteilt sind. Wie die Vector-Engines genau aussehen, verrät Intel noch nicht. Intel nennt zum Beispiel noch nicht die Anzahl der „Execution Units“, sprich der einzelnen FP32-ALUs in der Engine.
Wenn man von den spekulierten 4.096 FP32-ALUs für Intels zukünftigen Arc-Flaggschiff ausgeht und den derzeit bekannten Alchemist-Aufbau darüber legt, müsste eine Vector-Engine allerdings aus 8 FP32-ALUs und ein Xe-Core damit aus 128 FP32-ALUs bestehen. Das wären doppelt so viele wie in einer CU von AMD RDNA 2 und exakt so viele wie bei Nvidias SM auf Ampere.

Intels XMX- sind Nvidias Tensor-Kerne
Pro Vector-Engine gibt es darüber hinaus eine eigene Matrix-Engine, die sich um die Beschleunigung von Matrizen-Berechnungen kümmert – nach Nvidias Namensgebung ist eine Matrix-Engine schlicht ein Tensor-Core. Intel hat sie XMX-Core getauft. 16 XMX-Cores sind in Alchemist pro Xe-Core vorgesehen, in der Flaggschiff-GPU könnte es demzufolge bis zu 512 solcher Einheiten geben (Nvidia GA102: 328 „3rd Gen“).
Xe SS ist Intels DLSS
Auf den Matrix-Engine wird Intels eigenes KI-Upsampling XeSS (mehr Details) laufen, darüber hinaus können auch andere KI-Anwendungen beschleunigt werden.
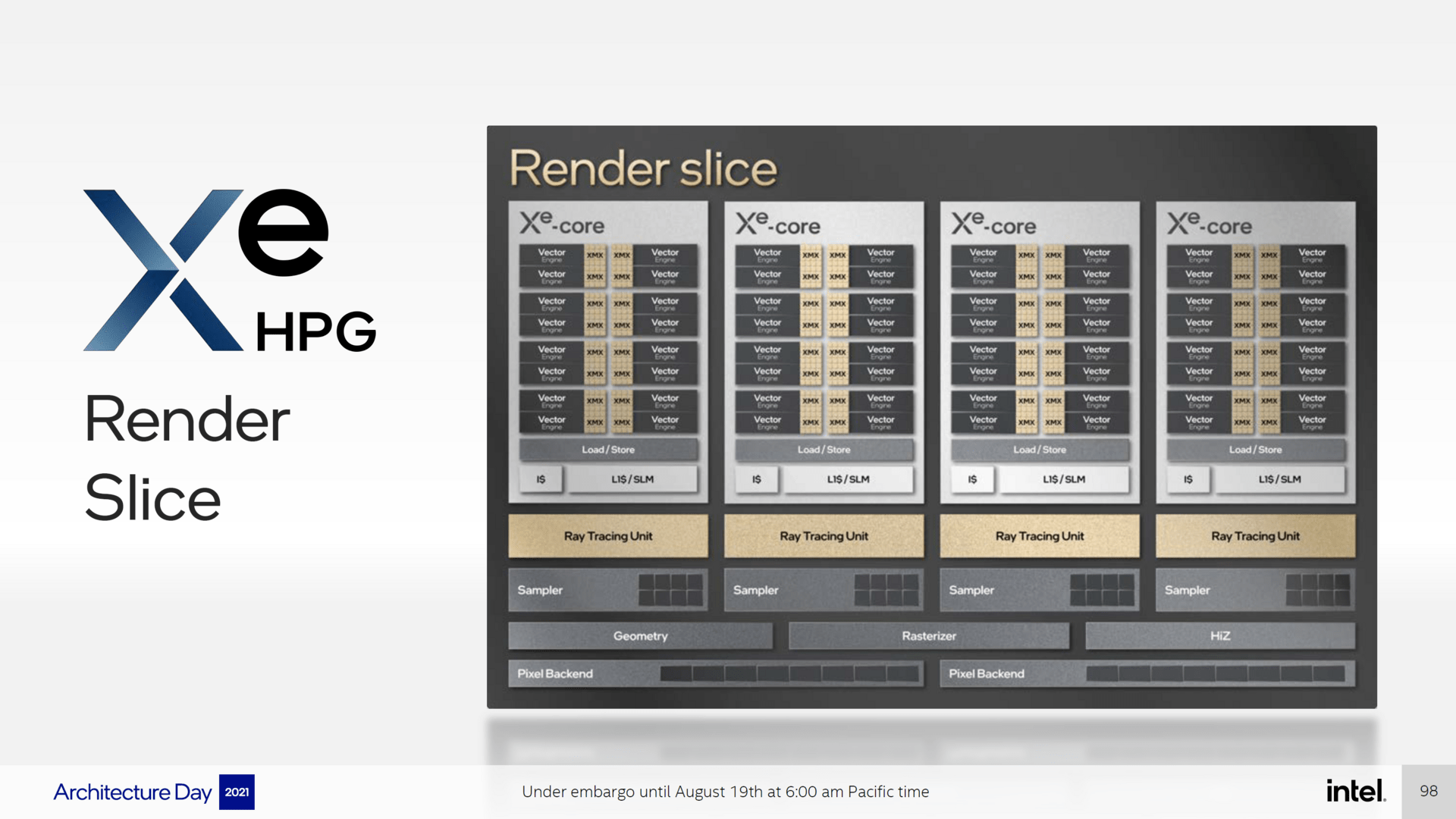
Zu guter Letzt besteht ein Xe-Core noch aus Load/Store-Einheiten und einem L1-Cache. Je vier Xe-Cores sind in Alchemist zu einem so genannten Render-Slice zusammengefasst, die Intel vorher schlicht Xe-Slice genannt hat. Bei AMD lässt sich ein Render-Slice am besten mit einer Shader Engine vergleichen, bei Nvidia mit einem Graphics Processor Cluster.
Neben den Xe-Cores beinhaltet ein Render-Slice zwei Pixel-Backends mit je 8 Einheiten und damit 16 ROPs, was bei einer voll aktivierten GPU vermutlich auf 128 ROPs hinaus läuft (Nvidia GA102: 112). Darüber hinaus gibt es einen Rasterizer, eine Geometrie-Einheit und 4 „Sampler-Einheiten“ mit je 8 Einheiten. Dabei handelt es sich vermutlich um die Textureinheiten, was auf 32 TMUs pro Render-Slice und vermutlich maximal 256 TMUs (Nvidia GA102: 328) auf der GPU hinauslaufen würde.
Separate Raytracing-Einheiten mit viel Beschleunigung
Da es sich bei Alchemist um eine DirectX-12-Ultimate-Architektur handelt, muss auch Raytracing in Hardware beschleunigt werden können, die bisher verfügbaren Xe-GPUs konnten das noch nicht.
Ein Render-Slice auf Alchemist verfügt jetzt wiederum über 4 RT-Einheiten, wobei es sich wie bei Nvidia um separate Einheiten handelt. Die vermutlich maximal 32 RT-Einheiten (Nvidia GA102: 82) können dabei das Ray-Traversal, die Triangle-Intersection und die Bounding Box Intersection beschleunigen, womit Intels RT-Einheiten denen von AMD auf jeden Fall überlegen sein sollte, denn diese kümmern sich nur um das Ray-Traversal und die Triangle-Intersection.
Nvidias RT-Einheit kümmern sich wiederum auch um die Erstellung der kompletten BVH-Struktur (Exkurs: Raytracing in Spielen VI: So werden Strahlen von GPUs beschleunigt), von der ein Teil auch die von Intel genannte Bounding-Box-Intersection-Berechnung ist. Ob Intels RT-Core sich wie Nvidias RT-Core um die komplette Erstellung der BVH-Struktur kümmert, ist aktuell noch unklar, ComputerBase geht zur Zeit aber davon aus und versucht zeitnah eine Bestätigung zu erhalten.
-
 Raytracing-Beschleunigung auf Alchemist (Bild: Intel)
Raytracing-Beschleunigung auf Alchemist (Bild: Intel)


GPU-Topmodell mit 8 Render-Slices
Da ein Render-Slice nicht genügend Rechenleistung für eine Spieler-Grafikkarte bereitstellen würde, kann Intel bei der schnellsten Alchemist-Ausbaustufe deren acht verbauen. Das würde 512 Vector- und Matrix-Engines und 32 RT-Einheiten ergeben. Diese werden von einer Global-Dispatch-Einheit mit Daten versorgt und können untereinander über einen L2-Cache miteinander kommunizieren. Letzterer ist mittels einer High Bandwith Memory Fabric an den Render Slices angeschlossen. Vermutlich gilt das auch für das Speicherinterface, zu diesem schweigt sich Intel aber noch aus.
50 % mehr Performance pro Watt als bei DG1
Aussagen zur Performance gibt es von Intel noch nicht, zur Energieeffizienz hat man sich jedoch knapp geäußert. Demnach soll Xe-HPG (High Performance Gaming alias Alchemist) gegenüber Xe-LE (Low Energy) in diskreter Form und damit als Grafikkarte DG1 um 50 Prozent mehr Performance pro Watt liefern. Das wird dadurch ermöglicht, dass bei gleicher Spannung ein 50 Prozent höherer Takt erzielt werden können soll. Da es zum Desktop-DG1 jedoch wenig Erfahrungswerte gibt, ist es schwer, diese Angabe richtig einzuordnen.
Weitere Details zur Alchemist-Architektur nennt Intel zum aktuellen Zeitpunkt noch nicht. Da sich der Marktstart auf das 1. Quartal 2022 verzögert, gibt es auch noch genügend Zeit bis zum Release zu überbrücken.
Nach Alchemist sollen laut Intel die Architekturen Battlemage als Xe² HPG, Celestial als Xe³ HPG und Druid als Xe⁴ HPG folgen, doch selbst Spekulationen gibt es zu diesen noch nicht.
-
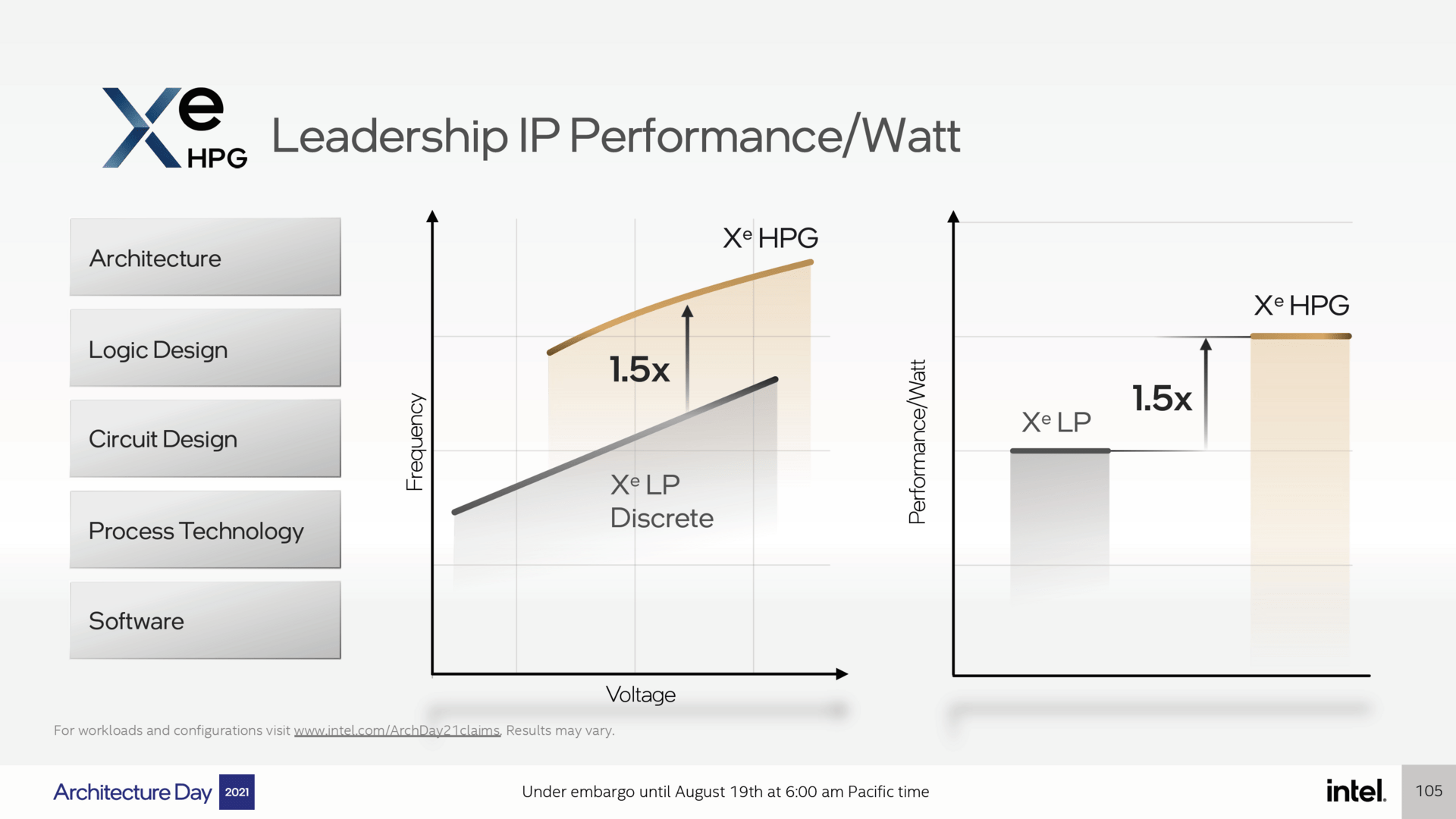 Bessere Energieeffizient von Alchemist (Bild: Intel)
Bessere Energieeffizient von Alchemist (Bild: Intel)

Details zum Treiber und neuen Treiber-Features
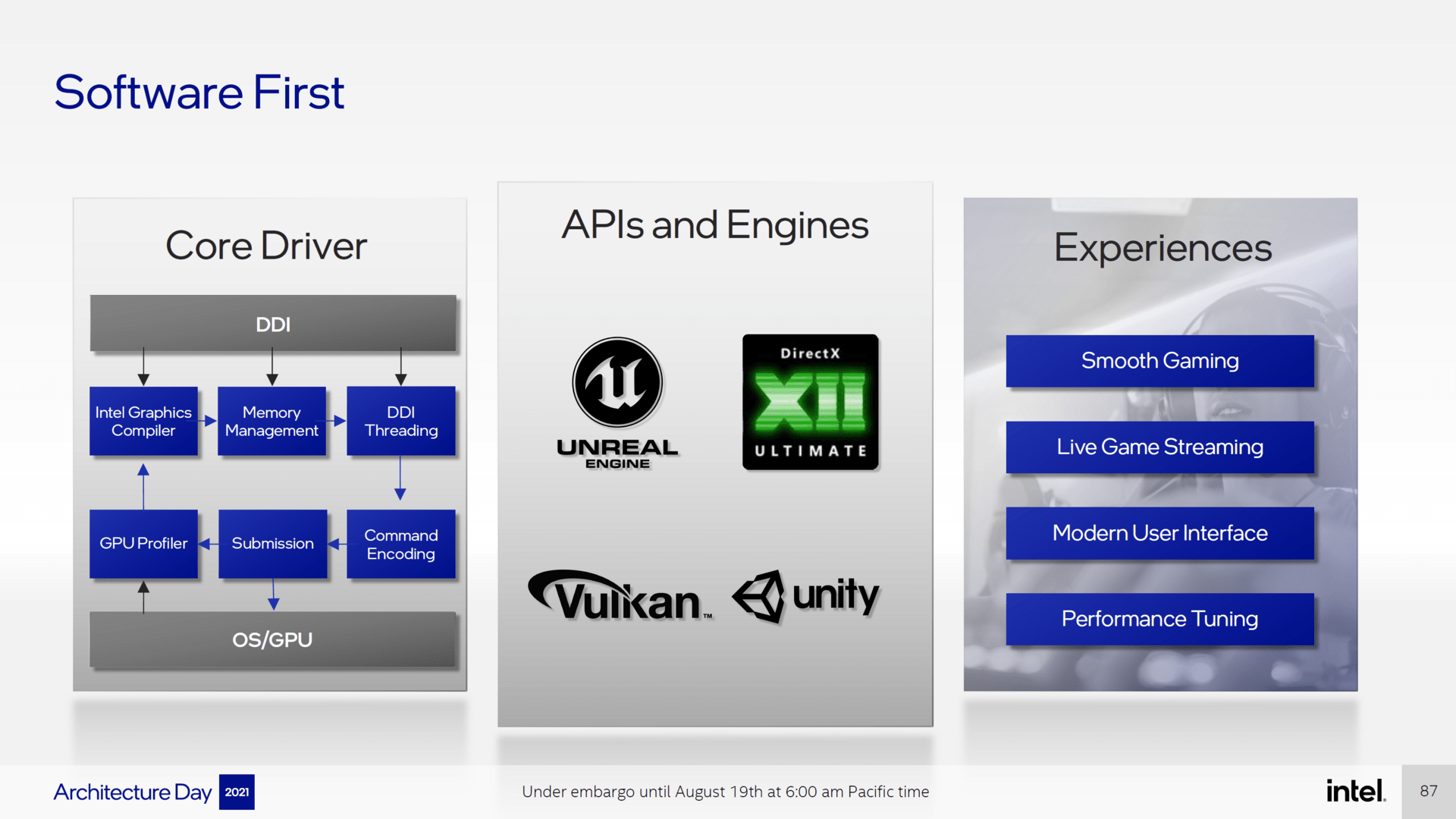
Intel hat nicht nur die Hardware für die neuen Grafikkarten massiv verändert, auch die Treiber sollen überarbeitet worden sein. So will man den „Core-Driver“ komplett überarbeitet haben, um die Performance und Stabilität gegenüber den bisherigen Treibern auf ein neues Niveau heben zu können. Der neue Treiber soll beispielsweise den Durchsatz bei CPU-limitierten Szenarien um bis zu 80 Prozent erhöhen und die Ladezeiten von Spielen um 25 Prozent reduzieren. Darüber hinaus soll es zahlreiche Optimierungen gegeben haben, um oft vorkommende Gaming-Workloads zu beschleunigen.
Neben dem Treiber soll auch das Treiber-Interface komplett überarbeitet worden sein. Hinzugekommen ist neben einer neuen Bedienoberfläche nun die Möglichkeit des Game-Streamings. Enthusiasten sollen darüber hinaus die Möglichkeit haben, die Grafikkarte im Treibermenü zu übertakten. Das erinnert an AMDs WattMan.
ComputerBase hat die Informationen zu diesem Bericht im Rahmen des Architecture Day 2021 von Intel vorab auf einem Event in Berlin unter NDA erhalten. Eine Einflussnahme des Herstellers auf die Berichterstattung fand nicht statt, eine Verpflichtung zur Veröffentlichung bestand nicht. Einzige Vorgabe war der frühestmögliche Veröffentlichungstermin.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.