Grace Superchip: Nvidias 144-Kern-ARM-CPU-Modul nutzt zwei Chips

Vor einem Jahr hatte Nvidia auf der GTC 2021 die Entwicklung eigener CPUs auf ARM-Basis in Aussicht gestellt und in diesem Zusammenhang ein Modul mit darauf verlöteter CPU und GPU gezeigt. Zur GTC 2022 kündigt Nvidia jetzt die Entwicklung einer weiteren Lösung an, die zwei der ARM-CPUs auf einem Package ohne GPU nutzt.
Nvidias ARM-Architektur hört auf den Namen Grace, Nvidias nächste GPU-Architektur für AI-Datacenter auf den Codenamen Hopper. Beides leitet sich von Grace Hopper ab, einer US-amerikanischen Informatikerin und Computerpionierin.
Grace Hopper Superchip: ARM-CPU + GPU (600 GB)
Dass auf dem Modul mit Grace-CPU vor einem Jahr eine Hopper-GPU steckte, verriet Nvidia damals noch nicht. Zur GTC 2022, auf der auch Hopper enthüllt wurde, ändert sich das: Nvidia bezeichnet das im vergangenen Jahr gezeigte CPU-GPU-Gespann als „Grace Hopper Superchip“, nennt erstmals die Summe von 600 GB Grafikspeicher pro Modul „für die größten AI-Modelle“ und stellt parallel den „Grace Superchip“ vor.
-
 Grace Hopper Superchip und Grace Superchip im Vergleich (Bild: Nvidia)
Grace Hopper Superchip und Grace Superchip im Vergleich (Bild: Nvidia)

Grace Superchip: ARM-CPU + ARM-CPU
Der Grace Superchip vereint zwei von den schon vor einem Jahr gezeigten Grace-CPUs ohne GPU auf einer Platine. Jede CPU soll 72, das Gespann damit 144 ARM-Kerne der Neoverse-Architektur besitzen.

Vor einem Jahr hatte Nvidia noch keine Informationen zur Anzahl der Kerne des Prozessors verlauten lassen, das präsentierte Schaubild deutet allerdings auf maximal 84 Kerne hin. Gut möglich, dass es so viele sind, der Grace Superchip pro Die aber nur 72 davon nutzt um die Ausbeute zu erhöhen. Die Kommunikation zwischen den CPUs findet über NVLink-C2C (Chip-to-Chip) statt, sie liefert 900 GB/s. Der Interconnect sei 90 Prozent flächeneffizienter als Lösungen auf Basis von PCI Express 5.0 (zum Beispiel CXL). NVLink-C2C kommt auch beim Grace Hopper Superchip sowie einem von Nvidia bis dato nicht genannten Grace 2xHopper mit zwei GPUs und einer CPU auf dem Modul zum Einsatz.
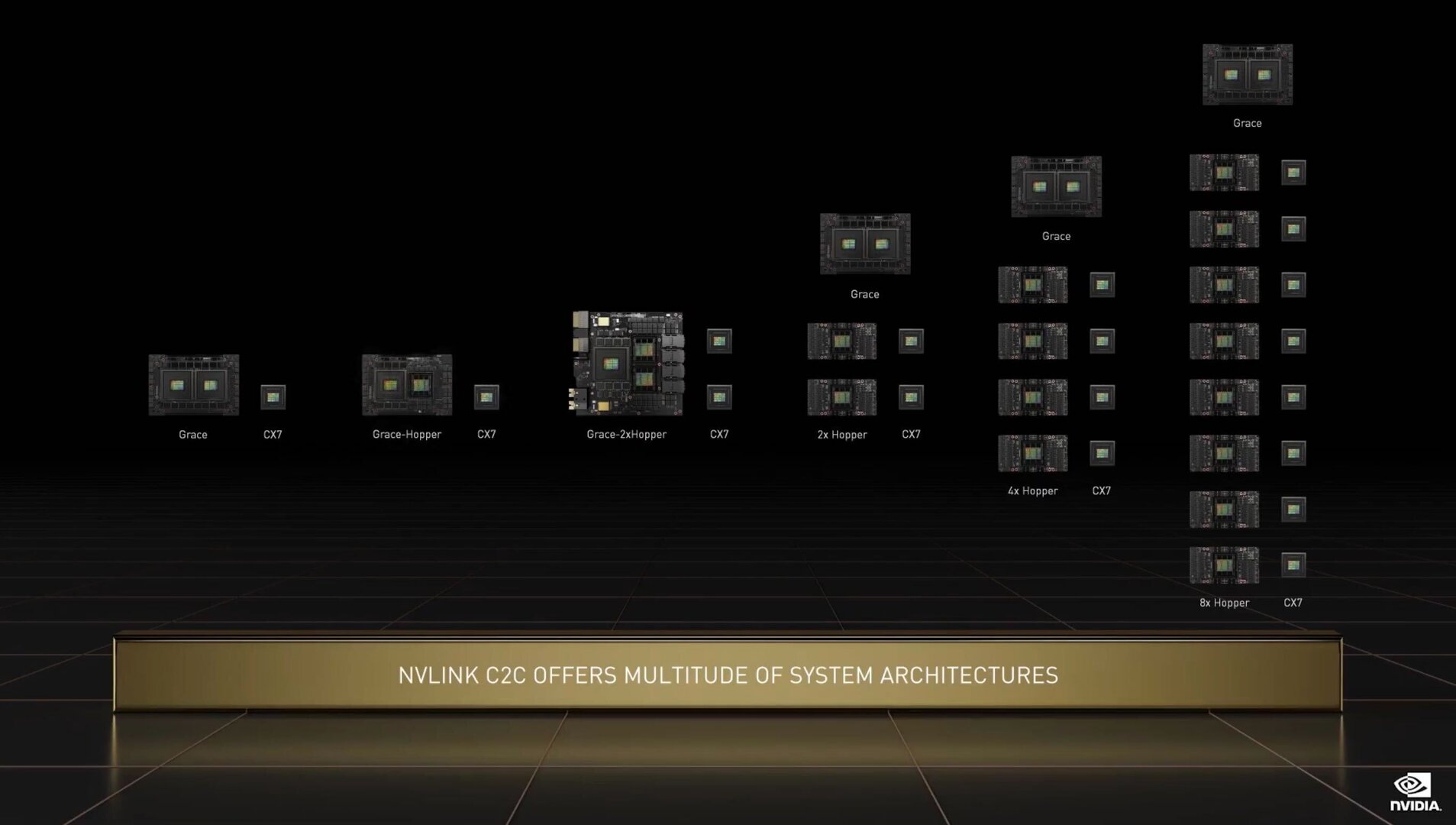
Kunden können NVLink-C2C von Nvidia „semi-custom“ anpassen lassen, solange sie ihren eigenen Chip mit einem Chip von Nvidia verbinden wollen.
Wie schnell ist Grace?
Vor einem Jahr nannte Nvidia über 300 Punkte im SPECrate2017_int_base-Benchmark als Zielvorgabe für eine Grace-CPU, für den Grace Superchip stellt Nvidia jetzt konkret 740 (370 je Chip) in Aussicht. AMD Epyc „Milan“ mit 64-Zen-3-Kernen erreicht in diesem Benchmark zwar 820 Punkte, doch muss Nvidia mit der eigenen Lösung auch gar nicht zwingend das Topprodukt der Konkurrenz schlagen, sondern die zurzeit eingesetzte Leistungsklasse. Und mit Blick auf die in der DGX Station eingesetzten CPUs von AMD sieht sich Nvidia dann auch um den Faktor 1,5 besser aufgestellt.
Wie effizient ist Grace?
Hinter der Effizienz steht derweil noch ein Fragezeichen. Nvidia spricht beim Grace Superchip von einer „industrieweit führenden Effizienz“ bei einer maximalen Leistungsaufnahme inklusive Arbeitsspeicher von „nur 500 Watt“. Grace nutzt LPDDR5X inklusive Fehlerkorrektur ECC, der über das nicht näher spezifizierte Speicherinterface auf 1 TB/s Bandbreite kommen soll. AMD Milan hat eine maximale TDP von 280 Watt ohne das DDR4-Speichersystem.
Mit Grace-CPUs, GPUs und Interconnects aus der Mellanox-Übernahme wird Nvidia in Zukunft in der Lage sein, Hochleistungsrechner – abgesehen vom Speicher – allein auf Basis eigener Komponenten zu konstruieren. Wie beim Grace Hopper Superchip ist auch für den Grace Superchip eine Markteinführung im 1. Halbjahr 2023 geplant.
ComputerBase hat die Informationen zu diesem Inhalt von Nvidia vorab unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt. Eine Einflussnahme des Herstellers auf die Meldung fand nicht statt, eine Verpflichtung zur Veröffentlichung bestand nicht.
Ihr habt die Wahl: Macht mit bei den Reader's Choice Awards 2025 und bestimmt eure Hersteller des Jahres!
- Version 512.15 WHQL: Nvidia GeForce, RTX Enterprise und Studio mit neuem Treiber
- Nvidia Jetson AGX Orin: Developer Kit mit Ampere-GPU startet für 1.999 US-Dollar
- Nvidia Hopper: H100 treibt KI-Supercomputer im ExaFLOPS-Zeitalter an
- +6 weitere News