Nvidia Hopper: H100 treibt KI-Supercomputer im ExaFLOPS-Zeitalter an

Benannt nach der Informatikerin Grace Hopper, ist Hopper Nvidias nächste GPU-Architektur, die neue Herausforderungen im Datacenter meistern soll. Eine neue Transformer Engine kann entsprechende Deep-Learning-Architekturen beschleunigen. H100 ist die erste Hopper-GPU, die ExaFLOPS-Leistung zum Standard machen soll.
Auf Volta und Ampere lässt Nvidia zum Start der heutigen GTC 2022 die neue Hopper-Architektur folgen, die im dritten Quartal dieses Jahres in ersten Produkten fürs Datacenter zum Einsatz kommen soll. Hopper ist als reine Enterprise-Lösung vorgestellt worden, neue Grafikkarten für Consumer, deren Architektur “Ada (Lovelace)“ heißen soll, sind zur GTC traditionell außen vor. Zum Auftakt der GPU Technology Conference wurde Hopper in Grundzügen mit den wichtigsten Neuerungen vorgestellt.
H100-GPU als erster Abkömmling der GH100
Nvidia bezeichnet Hopper als nichts weniger als den fortschrittlichsten Chip der Welt. Dabei ist zwischen dem Vollausbau GH100 und dem ersten veröffentlichten Produkt H100 zu unterscheiden. Analog zur Ankündigung von Ampere vor zwei Jahren, als der Vollausbau GA100 und die A100 Tensor Core GPU als erstes darauf basierendes Produkt angekündigt wurden, nutzt H100 nicht alle Komponenten von GH100. Vollständige Spezifikationen beider Ausbaustufen wird erst das bis dato noch nicht veröffentlichte Whitepaper für Hopper liefern.

80 Mrd. Transistoren, TSMC 4N, HBM3, 700 Watt
H100 ist ein Chip mit 80 Milliarden Transistoren und entstammt einer für Nvidia angepassten Custom-Fertigung in „4N“ bei TSMC. Alle Gerüchte, Hopper könnte auf einem Multi-Chip-Package basieren, haben sich nicht bestätigt.
80 Mrd. sind knapp 48 Prozent mehr Transistoren, als bei A100 zum Einsatz kamen. Angaben zu Die Size, SMs, CUDA Cores, Tensor Cores, Takt und weiteren Merkmalen stehen noch aus. Bereits bestätigt wurde allerdings der Einsatz von 80 GB HBM3, nachdem Ampere noch HBM2 und in einer späteren Ausbaustufe HBM2e nutzte. Die Speicherbandbreite soll mit HBM3 auf 3 TB/s steigen. Hopper erhält zudem schnellere Anbindungen: NVLink der 4. Generation als direkte Verbindung zwischen mehreren GPUs arbeitet jetzt mit 900 GB/s statt 600 GB/s und PCIe wechselt bei Hopper von Generation 4.0 auf 5.0 um 128 GB/s statt 64 GB/s zu bewältigen.
4.000 TFLOPS für FP8
Erste Angaben zur Rechenleistung von Hopper macht Nvidia ebenfalls. Im Fokus liegt dabei vor allem die um den Faktor 6 gesteigerte Leistung von 4.000 TFLOPS für FP8-Berechnungen. Wichtig in diesem Zusammenhang ist die eingangs erwähnte Transformer Engine – dazu später im Artikel mehr. Bei FP16 kommt H100 auf 2.000 TFLOPS, für TF32 sind es 1.000 TFLOPS und für FP64 nennt Nvidia 60 TFLOPS.
| H100 | vs. A100 | |
|---|---|---|
| FP8 | 4.000 TFLOPS | 6x |
| FP16 | 2.000 TFLOPS | 3x |
| TF32 | 1.000 TFLOPS | 3x |
| FP64 | 60 TFLOPS | 3x |
Effizienz steigt trotz Mehrverbrauch
Die höhere Rechenleistung geht mit einer abermals höheren TDP einher. Für ein SXM-Modul mit H100 nennt Nvidia 700 Watt. Zur Erinnerung: Die A100 Tensor Core GPU wird von Nvidia mit 400 Watt spezifiziert. Das entspricht einer Steigerung um 75 Prozent. In Relation zur gebotenen Leistung fällt die Effizienz dennoch deutlich besser aus.

Transformer Engine beschleunigt riesige KI-Modelle
Ampere sollte vor zwei Jahren den exponentiell wachsenden Ressourcenbedarf des Trainings neuronaler Netze und das komplexere Inferencing im Datacenter angehen. Die von Nvidia eingeführte Schlüsseltechnologie damals war die Sparsity-Beschleunigung für eine bis zu 20 Mal höhere KI-Leistung. Hopper setzt die Spezialisierung auf stetig komplexere Deep-Learning-Architekturen mit der neuen Transformer Engine von Hopper konsequent fort, die in die 4. Generation der Tensor Cores integriert wurde.
Die Transformer Engine bei Hopper wurde speziell für die Deep-Learning-Architektur der Transformer entwickelt. Die Transformer sind in jüngster Zeit der dominierende Bestandteil neuronaler Netze geworden. Diesen Durchbruch haben sie ihrer Eigenschaft zu verdanken, dass sie – anders als ältere rekurrente neuronale Netze – sequentielle Daten parallel statt sequentiell verarbeiten können, was das Training riesiger Modelle in vergleichsweise kurzen Zeiträumen ermöglicht. Transformer kommen zum Beispiel zum Einsatz, um Text von einer Sprache in eine andere zu übersetzen. Auch im medizinischen Umfeld etwa bei der Proteinsequenzierung oder in verschiedenen Bereichen der Computer Vision kommen Transformer zum Einsatz.
Ampere stößt bei Transformern an die Grenzen
Ampere stößt bei Transformern allerdings bereits an die Grenzen der Architektur, erklärte Nvidia zur GTC. Während Non-Transformer-Modelle in den letzten zwei Jahren nur um den Faktor 8 in Größe und Komplexität gewachsen seien, liege dieser Faktor bei Transformer-Modelle in derselben Zeitspanne bei 275 – ein wahrlich riesiger Nachteil. Um diese hochkomplexen Modelle durch das Training mit ungelabelten Daten immer genauer zu machen, wird eine enorme Rechenleistung benötigt, die selbst einem Supercomputer wie dem von Nvidia betriebenen Selene eine Berechnungszeit von anderthalb Monaten am Beispiel von Megatron-Turing NLG 530B abverlangt.
Nvidia teilt in FP8 und FP16 auf
Die Transformer Engine beschleunigt diese Berechnungen, indem diese in FP8 und FP16 unterteilt werden. Tensor-Core-Operationen in FP8 haben naturgemäß den doppelten Datendurchsatz wie solche in FP16. Die Herausforderung für Nvidia ist jedoch, die Genauigkeit des größeren numerischen Formats mit dem Performance-Zugewinn des kleineren, schnelleren Formats zu kombinieren. Eine von Nvidia entwickelte Heuristik soll den dynamischen Wechsel zwischen FP8 und FP16 und der damit verbundenen Präzision für jeden Layer des Modells managen. Details dazu sind für einen Deep Dive zur Hopper-Architektur im weiteren Verlauf der GTC zu erwarten.
Hopper beseitigt zwei Flaschenhälse
Neben den immer längeren Berechnungszeiten selbst mit modernster Hard- und Software ist ein weiteres Problem, dass die Zuwächse in puncto Leistung nicht mehr wie gewünscht mit der Anzahl der hinzugefügten GPUs skalieren. Hopper soll beide Baustellen beheben, indem zum einen die Transformer Engine den Flaschenhals direkt auf der GPU und zum anderen die neue NVLink-Generation den Flaschenhals unter den einzelnen Nodes im Datacenter beseitigt. Während die GPUs innerhalb eines Nodes mittels NVLink mit 900 GB/s statt nur 128 GB/s über PCIe 5.0 kommunizieren, lassen sich mittels NVLink Switch bis zu 256 GPUs in eine SuperPOD mit dem neuen DGX H100 kombinieren, deren Bandbreite laut Nvidia bei Faktor 9 gegenüber einem SuperPOD mit DGX A100 liege, die noch mit Quantum-1 InfiniBand verbunden wurden.
DGX H100 nutzt acht H100
DGX H100 ist nach der H100-GPU das erste System von Nvidia, in dem die Hopper-Architektur zum Einsatz kommen wird. DGX H100 ist der direkte Nachfolger des DGX A100 und nimmt acht H100 auf, die 32 PFLOPS (FP8) und 0,5 PFLOPS (FP64) KI-Leistung zur Verfügung stellen. Ein solcher Node kommt auf 640 GB HBM3.
-
 Nvidia DGX H100 (Bild: Nvidia)
Nvidia DGX H100 (Bild: Nvidia)

1 ExaFLOPS FP8 mit 256 H100-GPUs
Darauf basierend lässt sich der neue SuperPOD mit 32 DGX H100 aufbauen, in dem somit insgesamt 256 H100-GPUs werkeln, die eine Rechenleistung von 1 ExaFLOPS bezogen auf FP8 dank der neuen Transformer Engine erreichen. Die 256 GPUs kommunizieren über NVLink respektive NVLink Switch außerhalb des Nodes und können mit weiteren SuperPODs über Quantum-2 InfiniBand verbunden werden. 20 TB HBM3 stecken in einem der neuen SuperPODs auf Basis der Hopper-Architektur.
Nvidia Eos Supercomputer
Der neue SuperPOD lässt sich um inkrementelle Stufen von jeweils 32 weiteren DGX-H100-Nodes ergänzen, um einen Supercomputer aufzubauen. Nvidia selbst ist der erste Betreiber eines solchen Supercomputers, der unter dem Namen Eos auf den vorherigen Selene folgt. Der Nvidia Eos setzt sich aus 18 der neuen SuperPODs zusammen, sodass 576 DGX H100 mit insgesamt 4.608 H100-GPUs für 18 ExaFLOPS FP8-Leistung respektive 9 ExaFLOPS bezogen auf FP16 oder 275 PFLOPS für FP64 zum Einsatz kommen. Eos ist ein Supercomputer, den Nvidia selbst betreibt, doch der Aufbau soll OEMs und Cloud-Partnern als Blaupause für vergleichbare Systeme dienen.
Hopper kommt auf PCIe-5.0-Karten
Hopper ist allerdings nicht nur für Systeme von Nvidia selbst wie das DGX H100 vorgesehen, sondern kann auch in „Mainstream-Servern“ zum Einsatz kommen. Dafür hat Nvidia unter anderem den Beschleuniger H100 CNX entwickelt, der mittels PCIe 5.0 Platz in Servern findet. Das besondere Merkmal des H100 CNX ist die Kombination aus H100-GPU und ConnectX-7-NIC (PDF) auf einem Board, um GPU-beschleunigtes Computing im Datacenter zu ermöglichen, ohne dabei den CPU-Flaschenhals eines traditionellen Aufbaus zu erhalten. Darüber hinaus werden mit diesem Aufbau Ressourcen auf der CPU frei, die wiederum für andere Bereiche genutzt werden können.
-
 H100 CNX (Bild: Nvidia)
H100 CNX (Bild: Nvidia)

Im dritten Quartal startet eine ganze Hopper-Familie
Nvidia Hopper ist mit der heutigen Vorstellung somit nicht nur eine neue Architektur, auf die erst später Lösungen folgen werden, sondern Nvidia will im dritten Quartal auf breiter Front damit an den Start gehen. Die H100-GPU bildet die Grundlage aller Lösungen, die vom DGX H100 bis zum DGX H100 SuperPOD und Eos Supercomputer reichen. Mit H100 CNX und einer PCIe-Variante von H100, zu der noch Details fehlen, spricht Nvidia auch diejenigen Interessenten an, die kein vollständiges System erwerben möchten. Und den DGX H100 wird es auch wieder als HGX H100 geben, der nur die Innereien zur Verfügung stellt, um das Server-Anbieter ihr eigenes Gerüst konstruieren können.

Zahlreiche Partner hat Nvidia bereits für Hopper gewonnen. Entsprechende Systeme wollen die Cloud-Anbieter Alibaba, AWS, Baidu, Google, Microsoft, Oracle und Tencent an den Start bringen, während unter den Server-Anbietern AtoS, Dell, Fujitsu, Gigabyte, H3C, Hewlett Packard, Inspur, Lenovo, Nettrix und Supermicro zu nennen sind.
Im Nachgang der GTC-2022-Keynote hat Nvidia das Whitepaper zur neuen Hopper-Architektur veröffentlicht. Neben tieferen Einblicken in die Architektur liefert es auch die im Vorfeld nicht veröffentlichten Eckdaten des Vollausbaus der GH100-GPU und der ersten zwei am Markt verfügbaren Varianten: Der H100 SXM5 als SXM5-Modul für HPC-Systeme und der H100 PCIe für PCIe-5.0-Steckkarten wie Nvidias H100 CNX.
Die Hopper-GPU GH100 im Vollausbau
Mit 814 mm² ist die Hopper-GPU GH100 kleiner als beide Vorgänger, obwohl sie mit 80 Mrd. Transistoren viermal so viele Transistoren wie GV100 und 48 Prozent mehr Transistoren als GA100 beinhaltet.
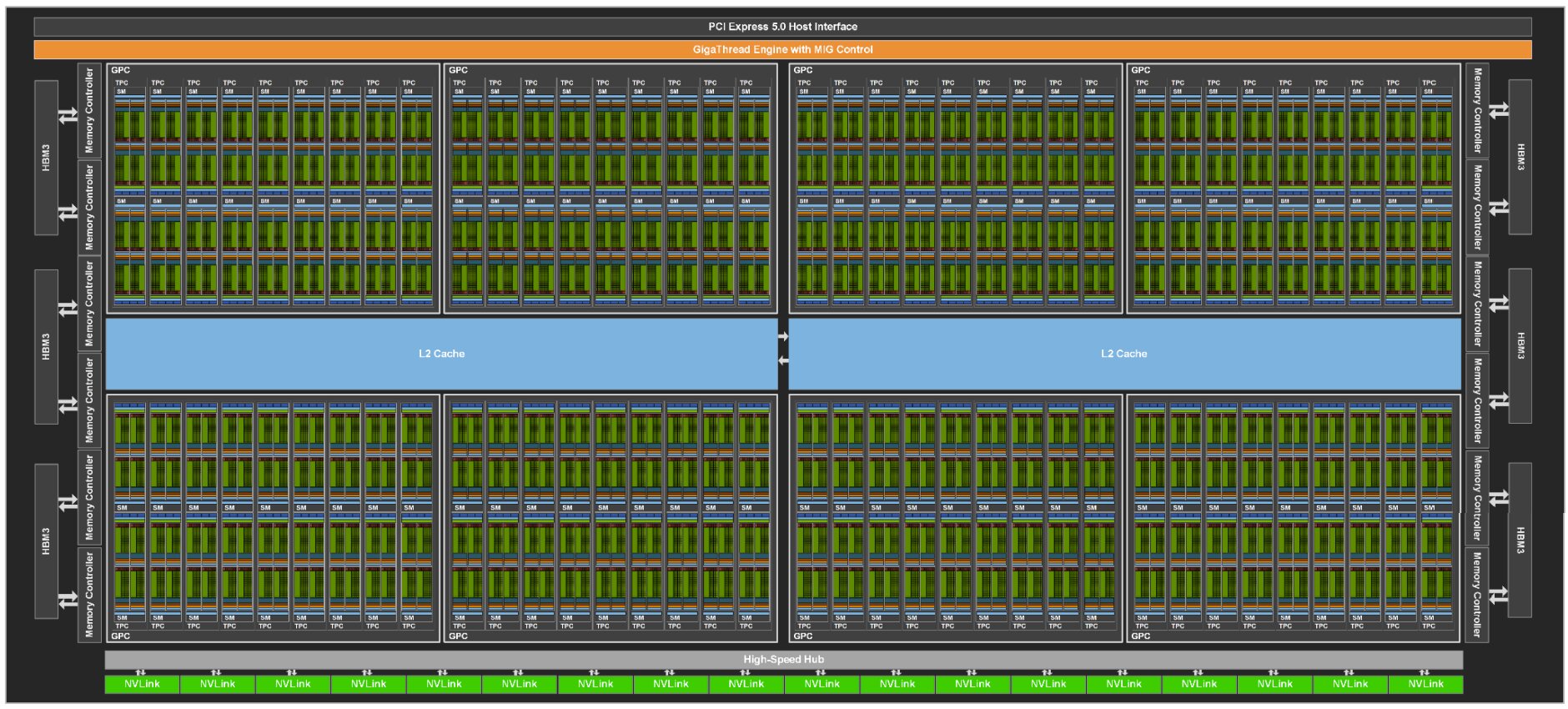
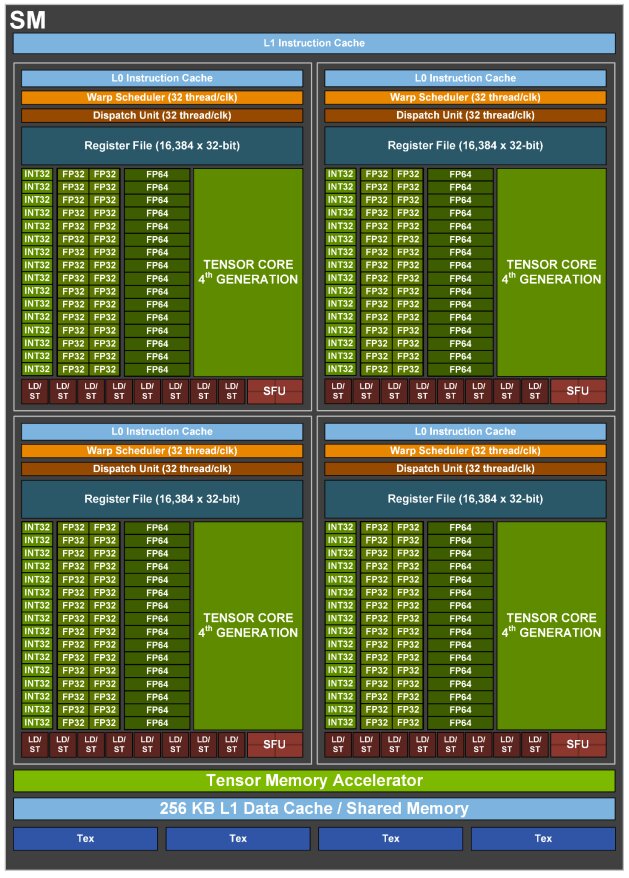
Der Chip setzt sich aus 8 GPU Processing Clusters (GPCs) zusammen, die jeweils 9 Texture Processing Clusters (TPCs) mit jeweils 2 Streaming Multiprocessors (SMs) umfassen. Ein SM von Hopper bietet 128 Cuda-Kerne (FP32) – bei GA100 waren es 64. In Summe kommt der GH100 damit auf 18.432 FP32-Cuda-Kerne, 125 Prozent mehr als GA100. Nur zwei der TPCs sind in der Lage Grafik auszugeben, der Rest ist einzig und allein auf Compute-Tasks ausgelegt.
| Nvidia GH100 | Nvidia GA100 | Nvidia GV100 | |
|---|---|---|---|
| Architektur | Hopper | Ampere | Volta |
| Fertigung | TSMC N4 | TSMC N7 | TSMC 12FFN |
| Transistoren | 80,0 Milliarden | 54,2 Milliarden | 21,1 Milliarden |
| Die Size | 814 mm² | 826 mm² | 815 mm² |
| SMs | 144 | 128 | 84 |
| FP64 CUDA Cores | 9.216 | 4.096 | 2.688 |
| FP32 CUDA Cores | 18.432 | 8.192 | 5.376 |
| Tensor Cores | 576 | 512 | 672 |
| GPU-Takt | nicht final | 1.410 MHz | 1.450 MHz |
| Speicher | 80 GB HBM3 | 48 GB HBM2/80 GB HBM2e | 32 GB HBM2 |
| Speichertakt | nicht final | 1.250 MHz | 880 MHz |
| Speicherinterface | 6.144 Bit | 6.144 Bit | 4.096 Bit |
| Bandbreite | 3,0+ TB/s | 1,9 TB/s/2,4 TB/s | 900 GB/s |
| TDP | 700 Watt | 400 Watt | 300 Watt |
| Interconnect | NVLink 900 GB/s PCIe 5.0 128 GB/s |
NVLink 600 GB/s PCIe 4.0 64 GB/s |
NVLink 300 GB/s PCIe 3.0 32 GB/s |
Nvidia nutzt auch GH100 nicht voll aus
Wie den GA100 nutzt Nvidia auch den GH100 (vorerst) nicht im Vollausbau. Vom GA100 auf den kommerziell genutzten A100 hatte Nvidia rund 18 Prozent der Ausführungseinheiten deaktiviert. Beim GH100 hängt der Verschnitt vom Produkt ab, auf dem er landet.
H100 SXM5 mit 132 Streaming Multiprocessors
Beim H100 SXM5 für das SXM5-Modul bleiben alle 8 GPCs aktiv, aber es werden über den Chip verteilt 12 von 144 oder 8 Prozent Streaming Multiprocessors deaktiviert. Anlog fällt die Anzahl der Cuda- und Tensor-Kerne. Der H100 SXM5 ist also näher dran am GH100 als es der A100 am GA100 war.
Wie bei Ampere nutzt Nvidia darüber hinaus nur fünf Sechstel der Speichercontroller, denn mit nur fünf von sechs aktiven HBM3-Stacks bleiben zwei der zwölf 512-Bit-Controller inaktiv. Über 5.120 Bit ergeben sich mit HBM3e trotzdem über 3 TB/s Speicherbandbreite. Das Modul wird mit bis zu 700 Watt TDP beworben.
H100 PCIe mit 114 Streaming Multiprocessor
Für den H100 PCIe für PCI-Express-5.0-Steckkarten nutzt Nvidia ein deutlich beschnittenere Ausbaustufe, die mit 14.592 Cuda-Cores und 456 Tensor-Cores ganze 20 Prozent weniger Ausführungseinheiten als GH100 bietet. Nvidia behält es sich dabei vor sowohl einen ganzen GPC als auch lediglich einzelne TPCs oder SMs abzuschalten – je nachdem, wo die Defekte im Chip liegen.
Auch der H100 PCIe nutzt nur zehn 512-Bit-Speichercontroller, verfügt darüber hinaus aber über eine weitere Anpassung gegenüber der maximalen Fähigkeit des GH100: H100 PCIe setzt auf HBM2e statt HBM3, was die maximale Bandbreite am selben Bus von „über 3 TB/s“ auf „über 2 TB/s“ senkt – in diesem Punkt gleicht H100 PCIe der HBM2e-Ausbaustufe des A100 mit 80 GB Speicher. Die TDP der PCIe-Steckkarte beträgt 350 Watt.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.