
Nvidia Hopper: So schnell ist die neue Architektur für Supercomputer

Hopper ist Nvidias neue Architektur für Supercomputer-GPUs. Vorgestellt wurde sie mit vielen technischen Details Ende März. Das umfangreiche Whitepaper zu Nvidias Hopper-GPU GH100 lieferte im Nachgang weitere Details zur Architektur und erlaubte einen Vergleich mit AMDs mehr oder weniger direktem Gegenspieler Instinct MI250X.
ServeTheHome hat Bilder der Hopper-Grafikkarte H100 SXM5 veröffentlicht, der für Server gedachten Varianten der GH100-GPU. Bis dato lag lediglich das von Nvidia bereitgestellte Rendering der Oberseite vor.

Bei der auf PCI Express 5.0 basierenden Schnittstelle auf der Unterseite wollte sich Nvidia offensichtlich noch nicht in die Karten schauen lassen: Sie war mit Klebeband verdeckt. Auch die bis zu 700 Watt werden über diese Schnittstellen zugeführt.

71 Seiten Whitepaper zu Nvidia Hopper
Bereits Ende März hatte Nvidia die neue Hopper-Architektur auf der Hausmesse Graphics Technology Conference (GTC) für den Einsatz in Servern und Rechenzentren enthüllt. Zur Erinnerung: Die auf Hopper basierende GPU ist die „GH100“, die in den ersten Produkten als „H100“ aber nicht vollständig aktiviert zum Einsatz kommt.
Wie gewohnt erzielt Nvidia im üblichen Zweijahresrhythmus eine deutliche Steigerung der Rechenleistung, wobei dazu viele Neuerungen bei Fertigung, Architektur und Peripherie beitragen. Einige dieser Aspekte wurden bereits im Artikel zur Veröffentlichung des (G)H100 beschrieben, darunter die Eckdaten des erneut monolitischen Chips, die Bestückung mit HBM3 und das neue PCIe-5.0-Interface.
| Nvidia GH100 | Nvidia GA100 | Nvidia GV100 | |
|---|---|---|---|
| Architektur | Hopper | Ampere | Volta |
| Chip-Design | monolithisch | ||
| Fertigung | TSMC N4 | TSMC N7 | TSMC 12FFN |
| Transistoren | 80,0 Milliarden | 54,2 Milliarden | 21,1 Milliarden |
| Die Size | 814 mm² | 826 mm² | 815 mm² |
| SMs | 144 | 128 | 84 |
| FP64 CUDA Cores | 9.216 | 4.096 | 2.688 |
| FP32 CUDA Cores | 18.432 | 8.192 | 5.376 |
| Tensor Cores | 576 | 512 | 672 |
| GPU-Takt | nicht final | 1.410 MHz | 1.450 MHz |
| Speicher | 80 GB HBM3 | 48 GB HBM2/80 GB HBM2e | 32 GB HBM2 |
| Speichertakt | nicht final | 1.250 MHz | 880 MHz |
| Speicherinterface | 6.144 Bit | 6.144 Bit | 4.096 Bit |
| Bandbreite | 3,0+ TB/s | 1,9 TB/s/2,4 TB/s | 900 GB/s |
| TDP | 700 Watt | 400 Watt | 300 Watt |
| Interconnect | NVLink 900 GB/s PCIe 5.0 128 GB/s |
NVLink 600 GB/s PCIe 4.0 64 GB/s |
NVLink 300 GB/s PCIe 3.0 32 GB/s |
In diesem Artikel soll nun die neue Architektur mithilfe des Whitepapers (PDF) analysiert werden. Es ist mit 71 Seiten sehr umfangreich und strotzt nur so vor Superlativen und bunten Bildern. Während man bei AMD auf wenigen Seiten die technischen Daten vorgelegt bekommt und sich Anwendungsmöglichkeiten und Implementierung selbst überlegen muss, bietet Nvidia das genaue Gegenteil. Es fällt mitunter schwer, unter den ganzen vorgeschlagenen Anwendungsfällen die harten Fakten herauszuarbeiten. Aber genau das war das Ziel.
GH100: Eine GPU, zwei erste Produkte
Noch einmal zur Erinnerung: Auf Basis von Hopper gibt es vorerst eine GPU namens GH100, darauf basierend hat Nvidia zwei Produkte vorgestellt: H100 SXM5 als Server-Modul und H100 PCIe als klassische Steckkarte.
H100 SXM5 mit 132 Streaming Multiprocessor
Beim H100 SXM5 für das SXM5-Modul bleiben alle 8 GPCs aktiv, aber es werden über den Chip verteilt 12 von 144 oder 8 Prozent Streaming Multiprocessors deaktiviert. Analog fällt die Anzahl der Cuda- und Tensor-Kerne. Der H100 SXM5 ist also näher dran am GH100 als es der A100 am GA100 war. Wie bei Ampere nutzt Nvidia darüber hinaus nur fünf Sechstel der Speichercontroller, denn mit nur fünf von sechs aktiven HBM3-Stacks bleiben zwei der zwölf 512-Bit-Controller inaktiv. Über 5.120 Bit ergeben sich mit HBM3e trotzdem über 3 TB/s Speicherbandbreite. Das Modul wird mit bis zu 700 Watt TDP beworben.

H100 PCIe mit 114 Streaming Multiprocessor
Für den H100 PCIe für PCI-Express-5.0-Steckkarten nutzt Nvidia ein deutlich beschnittenere Ausbaustufe, die mit 14.592 Cuda-Cores und 456 Tensor-Cores ganze 20 Prozent weniger Ausführungseinheiten als GH100 bietet. Nvidia behält es sich dabei vor sowohl einen ganzen GPC als auch lediglich einzelne TPCs oder SMs abzuschalten – je nachdem, wo die Defekte im Chip liegen. Auch der H100 PCIe nutzt nur zehn 512-Bit-Speichercontroller, verfügt darüber hinaus aber über eine weitere Anpassung gegenüber der maximalen Fähigkeit des GH100: H100 PCIe setzt auf HBM2e statt HBM3, was die maximale Bandbreite am selben Bus von „über 3 TB/s“ auf „über 2 TB/s“ senkt – in diesem Punkt gleicht H100 PCIe der HBM2e-Ausbaustufe des A100 mit 80 GB Speicher. Die TDP der PCIe-Steckkarte beträgt 350 Watt.

Die von Nvidia gemachten und nachfolgend übernommenen Leistungsdaten beziehen sich immer auf H100 SXM5 mit 700 Watt TDP für Server.
Fertigung und technische Daten
Beim Blick auf die unten angegebene Tabelle fällt direkt auf, dass Nvidia deutlich von dem neuen Fertigungsverfahren in 4 nm Strukturgröße profitiert. Die Transistordichte ist gut 50 Prozent höher als beim A100 und damit ca. 2,5 Mal höher als bei AMDs aktueller Beschleunigerkarte der Instinct-Reihe: der MI200. Von letzterer ist die Chipgröße Hersteller-seitig nie kommuniziert worden, weshalb die der sehr ähnlich aufgebauten MI100 genommen wurde.
Nvidia nennt den Herstellungsprozess etwas ungewöhnlich „4N“, während bei anderen Strukturgrößen wie 7 nm das „N“, wie von TSMC bekannt, vorangestellt wird. Laut Nvidia handelt es sich dabei um einen in Zusammenarbeit mit TSMC optimierten Prozess. Von TSMC gibt es dazu keine offiziellen Informationen. Für den Standardprozess „N4“ gibt TSMC jedoch an, dass gegenüber N5 Leistung, Energieverbrauch und Transistordichte optimiert wurden. Der Sprung um mehr als eine Node von N7 auf 4N ist interessant, weil Nvidia damit aggressiv die modernste Fertigung nutzt. Ob AMD mit den nächsten Instinct-Karten gleichzieht oder erst einmal bei N5 verbleibt, ist noch offen.
| H100 | A100 | MI250X | |
|---|---|---|---|
| Transistoren (Mrd.) | 80 | 54,2 | 2 × 29 |
| Chipgröße (mm²) | 814 | 826 | unbekannt, ca. 2 x 750* |
| Fertigung (nm) | 4 | 7 | 6 |
| Transistordichte (Mio. Tr/mm²) | 98,3 | 65,6 | ca. 38,7* |
| Anzahl Shader | 16.896 | 6.912 | 2 × 7.040 |
| Anzahl Matrix-Einheiten | 528 | 432 | 2 × 440 |
| GPU-Takt (MHz) | ca. 1.880** | 1.410 | 1.700 |
| * Schätzung auf Basis des MI100-Dies | |||
| ** Finaler Takt wurde noch nicht kommuniziert | |||
Was die Rechenleistung angeht, so hat Nvidia durch eine Verdopplung der FP32-Shader pro SM (Shader-Multiprocessor) die Leistung deutlich erhöht und liefert jetzt mehr Shader als AMD mit der MI200. Um die von Nvidia versprochene Verdreifachung der Shader-Leistung gegenüber Ampere durchzusetzen, ist zusätzlich noch ein Takt von mindestens 1.880 MHz notwendig. Von Nvidia gibt es aber noch keine offizielle Angabe zum finalen Takt. Sollte sich der rechnerisch ermittelte Takt bewahrheiten, wäre AMD auch dort geschlagen. Insgesamt kann Nvidia AMD bei der nominellen FP32-Leistung damit unter Druck setzen.
Leistung in traditionellen Vektorberechnungen
Bei anderen Zahlenformaten der traditionellen Berechnungsmethode per Vektoren sieht das stellenweise noch anders aus. AMD hat insbesondere die Leistung in FP64 letztes Jahr massiv erweitert, hier erreicht Nvidia trotz deutlicher Verbesserungen gegenüber der letzten Generation nicht AMDs Leistung mit zwei GPU-Chips. Wie von Nvidia beworben, steigt die Vektorleistung in allen Formaten außer FP16, welches zuvor schon deutlich ausgebaut war, um den Faktor 3.
| Datenformat | H100 | A100 | MI200 |
|---|---|---|---|
| Standard-ALUs | |||
| Vektor FP64 (TFLOPS) | 30 | 9,7 | 47,9 |
| Vektor FP32 (TFLOPS) | 60 | 19,5 | 47,9 |
| Vektor FP32 RPM (TFLOPS) | N/A | N/A | 95,7 |
| Vektor FP16 (TFLOPS) | 120 | 78 | 191 |
| Matrix-Einheiten | |||
| Matrix FP64 (TFLOPS) | 60 | 19,5 | 95,7 |
| Matrix FP32 (TFLOPS) | N/A | N/A | 95,7 |
| Matrix TF32 (TFLOPS) | 500 | 156 | N/A |
| Matrix FP16 (TFLOPS) | 1.000 | 312 | 383 |
| Matrix BF16 (TFLOPS) | 1.000 | 312 | 383 |
| Matrix INT8 (TOPS) | 2.000 | 624 | 383 |
| Matrix FP8 (TFLOPS) | 2.000 | 312 | 383 |
Bei den Matrix-Operationen ist das Bild komplett gedreht. Hier schreitet Nvidia, durch den Zugewinn um den Faktor 3, nochmal deutlich davon. Lag AMD zuvor nur in INT8 deutlich zurück und bei den anderen Formaten entweder auf Augenhöhe oder nicht zu weit entfernt, trennen die beiden Hersteller wieder Faktoren bis über 5 x. Neu ist dabei das Format FP8, das zuvor wie FP16 berechnet wurde. Jetzt wird es jedoch, wie INT8 auch, doppelt so schnell berechnet wie die größeren Zahlengeschwister. In den passenden Anwendungen hat Nvidia so ein Alleinstellungsmerkmal.
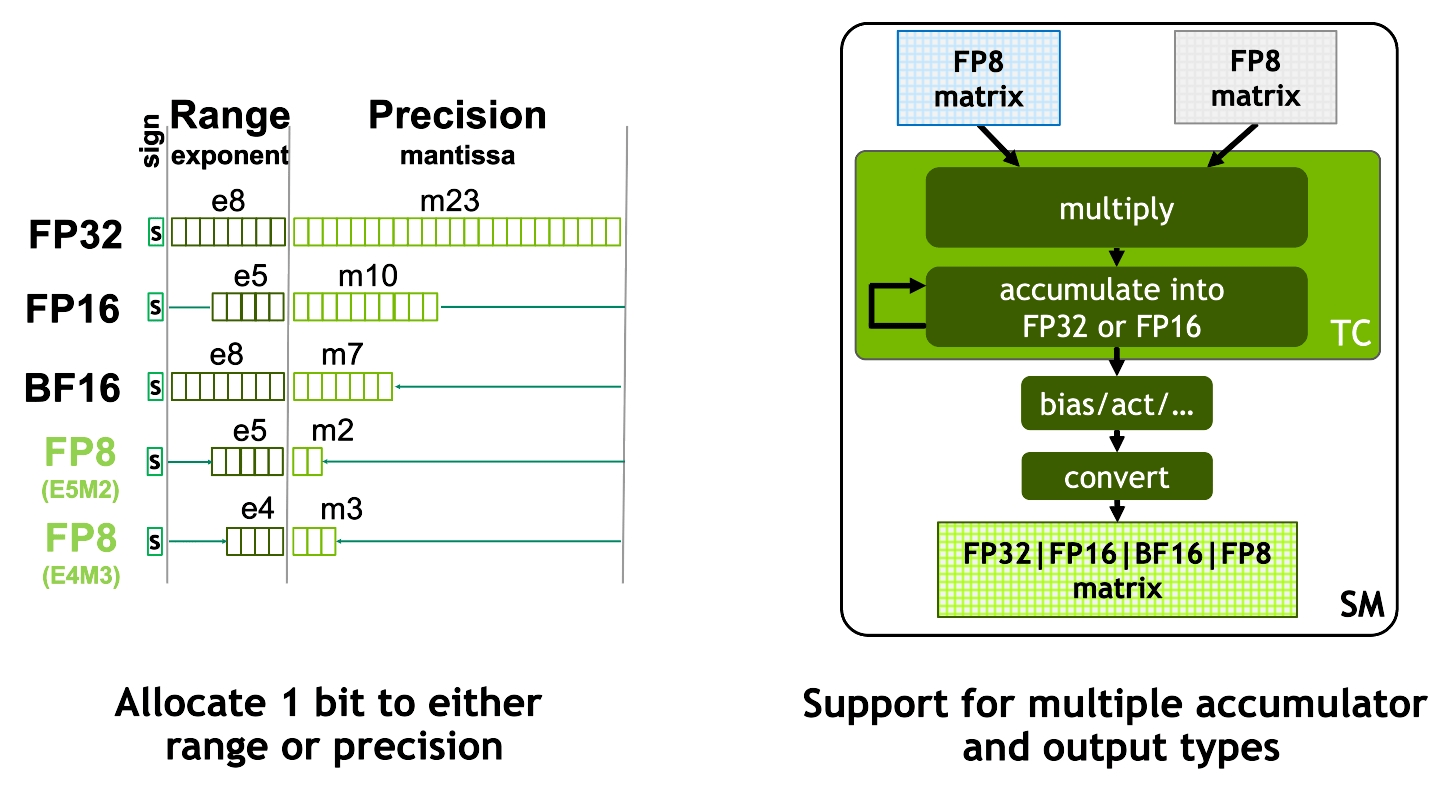
FP8 als neu unterstütztes Zahlenformat
FP8 ist dabei so neu, dass nicht nur eine standardisierte IEEE-Implementierung genutzt wird, sondern der Anwender zwischen zwei Zahlenformaten wählen kann. Bei Gleitkommazahlen werden die verfügbaren Stellen (hier 8) immer in ein Bit für das Vorzeichen sowie einige Stellen für die Mantisse und für den Exponenten aufgeteilt. Die wählbaren Konfigurationen bei FP8 sind:
- E4M3, also mit 4 Bits für den Exponenten und 3 für die Mantisse und
- E5M2, also mit 5 Bits für den Exponenten und 2 für die Mantisse.
E5M2 bietet dabei einen größeren Zahlenraum, während E4M3 eine höhere Genauigkeit liefert. Auch das Zahlenformat für das Ergebnis der Matrix-Operation kann vom Anwender zwischen vier Varianten gewählt werden.
Verbesserungen für KI
Rohleistung ist gut, Auslastung ist besser. Um zu gewährleisten, dass die hohe Rechenleistung der H100 auch beim Anwender ankommt, hat Nvidia mehrere Neuerungen implementiert. Eine bekannte Beschleunigung für die Matrix-Operationen ist das Sparsity-Feature, das Matrizen mit vielen Nullstellen doppelt so schnell berechnen lässt.
Ein weiteres Feature, das jetzt dazugekommen ist, sind die Instruktionen für dynamische Programmierung. Bei Problemstellungen, wo immer wieder auf vorherige Erkenntnisse zurückgegriffen wird (wie den sogenannten Optimierungsproblemen), können mit diesen Instruktionen vorherige Ergebnisse behalten werden, so dass Neuberechnungen entfallen. Dabei ist es von der Anwendung abhängig, wie viele Berechnungen so eingespart werden können, weswegen die von Nvidia beworbene Beschleunigung um den Faktor 7 nur als absoluter Best Case zu verstehen ist. In den entsprechenden Anwendungsgebieten wie Routenoptimierung wird die H100 allerdings deutliche Vorteile bieten.
-
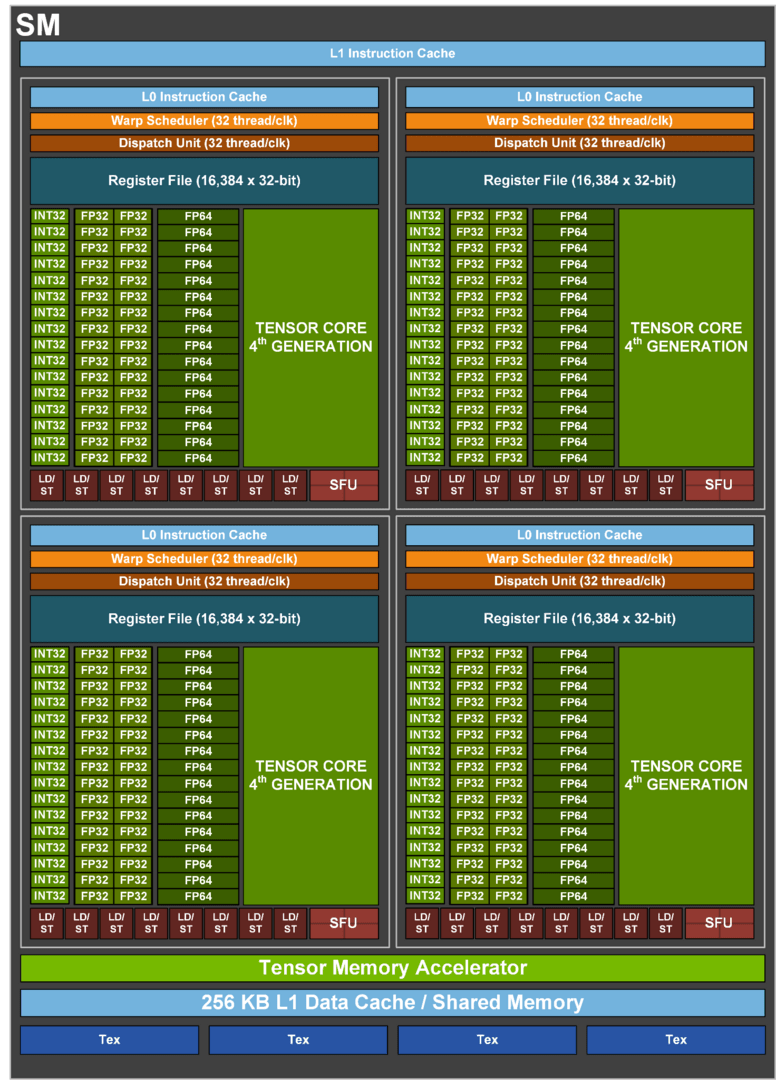 Der Streaming Multiprocessor von Hopper (Bild: Nvidia)
Der Streaming Multiprocessor von Hopper (Bild: Nvidia)
Die Granularität, mit der Aufgaben auf Shader verteilt werden können, wurde erweitert. Wo bisher ein SM mit 128 Shadern die Grundeinheit der Aufgabenverteilung war, können jetzt mehrere SMs zu einem Cluster zusammengefasst werden, um dies als zusammenhängende Einheit zu kennzeichnen, in der alle Rechenwerke an derselben Aufgabe arbeiten. Innerhalb eines solchen Clusters können SMs auf die Daten im Cache der anderen SMs zugreifen, was deutlich schneller vonstattengehen soll, als die Daten neu zu laden. Interessanterweise ähnelt der Ansatz einem von AMD 2020 veröffentlichten Patent auf Basis von Simulationsdaten. AMD hat diese Technologie, die seinerzeit ohne Cluster beschrieben wurde, bisher nicht realisiert. Nvidia verspricht mit angepasstem Code in den richtigen Anwendungen eine Verdopplung der Leistung.
Tensor-Cores der vierten Generation
Die Tensor-Cores dienen zur Multiplikation zweier Matrizen, zu deren Ergebnis eine dritte Matrix addiert wird. Diese Multiply-Add genannte Berechnung ist sehr spezifisch, weswegen man bei Tensor-Cores von einer Fixed-Function-Unit spricht. Die Tensor-Cores beherrschen diese eine Rechenaufgabe und sonst nichts. Für Anwendungen, die diese Rechenart ausnutzen, zum Beispiel für das Inferencing zum Training von neuronalen Netzen, ist die Beschleunigung der Rechenaufgabe essentiell, um zeitnah Ergebnisse zu erhalten.
Die KI-Leistung ist für Nvidia das Steckenpferd der Server-GPUs. Damit die Leistung beim Multiply-Add weiter ansteigt, hat das Unternehmen die vierte Generation seiner Tensor-Cores implementiert. Sie verdoppelt die Leistung pro Core pro Clock für alle unterstützten Zahlenformate. Für das neue FP8, das zuvor wie FP16 verarbeitet wurde, steht sogar ein Faktor von 4 auf dem Papier. Die gesamte KI-Leistung der GPU steigt durch die erhöhte Anzahl und den erhöhten Takt der Einheiten zusätzlich um 50 %. Die folgende Tabelle vergleicht die IPC der neuen Tensor-Cores mit denen von Ampere und AMDs CDNA 2.
| Nvidia Hopper/Ampere | AMD CDNA 2 | ||
|---|---|---|---|
| Datenformat | 4. Gen Tensor-Core | 3. Gen Tensor-Core | 2. Gen Matrix-Core |
| Matrix FP64 (FLOPS) | 64 | 32 | 64 |
| Matrix FP32 (FLOPS) | N/A | N/A | 64 |
| Matrix TF32 (FLOPS) | 512 | 256 | N/A |
| Matrix FP16 (FLOPS) | 1.024 | 512 | 256 |
| Matrix BF16 (FLOPS) | 1.024 | 512 | 256 |
| Matrix INT8 (OPS) | 2.048 | 1.024 | 256 |
| Matrix FP8 (FLOPS) | 2.048 | 512 | 256 |
| Rechenleistung pro Core pro Clock. | |||
Im Gebiet von KI ist AMD zurzeit hoffnungslos abgeschlagen. Eine mögliche Aussicht auf schnelle Besserung wäre ein KI-Chip aus dem Repertoire der kürzlich erworbenen Xilinx-IP. Ob solch ein Chip Teil der für 2023 angekündigten Produkte sein wird, ist noch nicht offiziell bekannt.
Tensor Memory Accelerator
Zum Übertragen der Matrizen für die Multiply-Add-Funktion der Tensor-Cores ist schneller Speicher ausschlaggebend. Bisher wurden die Matrizen vor der Rechnung Element für Element aus dem VRAM in den L1-Cache eines SMs übertragen. Diese Übertragung erfolgte durch eine Schleife, deren Berechnung den gesamten SM für die Zeit der Übertragung in Beschlag nahm. Um diese Rechenleistung künftig nicht mehr brachliegen zu lassen, hat Nvidia eine Beschleunigungseinheit namens „Tensor Memory Accelerator“ (TMA) implementiert. Diese Einheit ist nur für die Übertragung von Daten aus dem VRAM zuständig und entlastet dadurch den SM. Dieser kann somit in der Zeit, in der die Daten übertragen werden, andere Aufgaben übernehmen. Der TMA übersetzt dabei Befehle, die bestimmte Matrizen zur Übertragung auswählen, eigenständig in die gewünschten Speicheradressen. Das vereinfacht auch die Programmierarbeit.
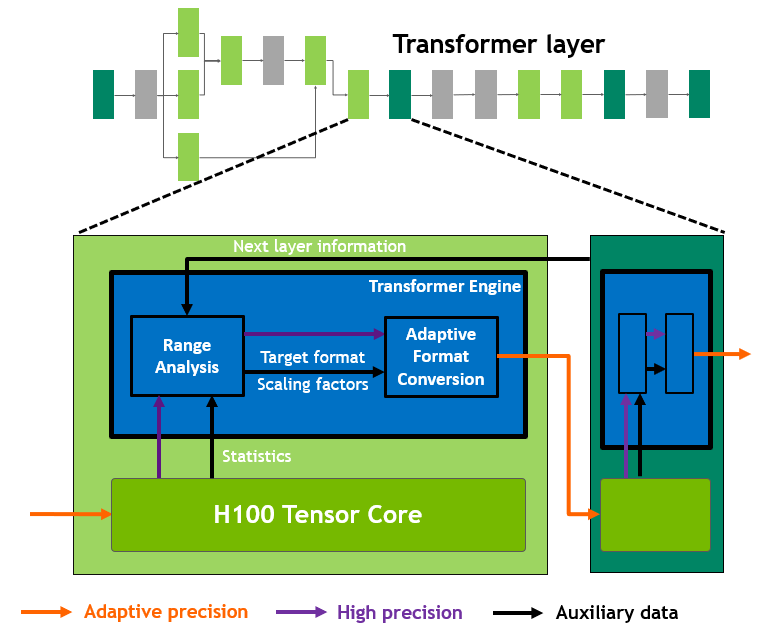
Transformer Engine
Ganz neu ist die Transformer-Engine, die die Arbeit der Tensor-Cores bei einem bestimmten, 2017 vorgestellten Algorithmus beschleunigt, der Transformer genannt wird. Transformer sind der zurzeit beste Algorithmus zur Analyse menschlicher Sprache. Genau genommen geht es um das Training einer künstlichen Intelligenz, die im Anschluss in der Lage ist, menschliche Sprache zu verstehen. Nvidia beschleunigt die Berechnung von Transformern, indem die Genauigkeit zwischen FP16 und FP8 bei jedem Rechenschritt angepasst wird. Dazu entscheidet die Transformer-Engine anhand des letzten Ergebnisses, welche Genauigkeit für den nächsten Rechenschritt erforderlich ist. Die eingehenden Matrizen werden anschließend entweder im Format FP16 belassen oder in FP8 konvertiert. Dabei werden sowohl die geringere Genauigkeit als auch der verringerte Zahlenraum von FP8 berücksichtigt. Im Anschluss wird das Ergebnis, je nach Anforderung, in das richtige Zielformat konvertiert.
Hardware-Video-Dekoder
In Server-GPUs werden die integrierten Video-Dekoder nicht zur Erstellung einer Bildausgabe verwendet, sondern zur Verarbeitung von Videomaterial zum Training von Deep-Learning-Modellen: Um die AI mit Informationen in Bild- oder Videoformat zu füttern, müssen die Videos decodiert werden.
Damit die vielen Recheneinheiten des H100 mit ausreichend Material gefüttert werden können, hat Nvidia die Anzahl gleichzeitiger Streams, die vom Video-Dekoder bearbeitet werden, verdoppelt. Unterstützt werden die Formate H.265, H.264 und VP9, wobei H.265 mit 340 gleichzeitigen Full-HD-Streams am meisten Daten gleichzeitig verarbeiten kann. Für das Training mit Bilddaten beherrscht der Dekoder auch JPEG und dekomprimiert bis zu 6.350 Full-HD-Bilder pro Sekunde.
Fazit
Das Whitepaper zu Hopper liefert weitere Interessante Einblicke in die Hopper-Architektur respektive das, was Nvidia gegenüber Ampere geändert hat. Zusammen mit den zur Vorstellung bereits bekannten Informationen wird dabei deutlich, wie stark Nvidia den Fokus abermals auf die Leistung im Bereich AI gelegt hat: AMDs „Gegenspieler“ Instinct MI200 ist in diesem Segment quasi keiner, dafür liegt die CDNA-2-Architektur bei klassischen Vektor-Berechnungen vorne.
Eine Überraschung bleibt, dass Hopper wirklich noch einmal ein klassischer monolithischer Die geworden ist, während AMD bei CDNA 2 bereits auf ein Multi-Chip-Modul setzt und das auch bei den Gaming-Grafikkarten auf Basis von RDNA 3 am oberen Leistungsende tun wird.
Doch Nvidia liefert mit dem monolitischen Ansatz auf erneut knapp über 800 mm² nicht nur sehr viel Leistung, auch bis zu 700 Watt TDP und davon ein Großteil für das Package sind für die SXM5-Variante für Server-Umfelder offensichtlich kein Problem.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.