Arm-Kerne 2022: Cortex-X3, A715 und A510 sind schneller und sparsamer

Aufbauend auf der Armv9-Architektur stellt Arm heute die Komponenten der nächsten Generation von Systems on a Chip vor, wie sie in kommenden Smartphones, Tablets und PCs zum Einsatz kommen werden. Arm Cortex-X3, A715 und A510 Refresh liefern mehr Leistung, einen reduzierten Verbrauch und erlauben neue Konfigurationen.
TCS22 liefert 28 Prozent mehr Gaming-Leistung
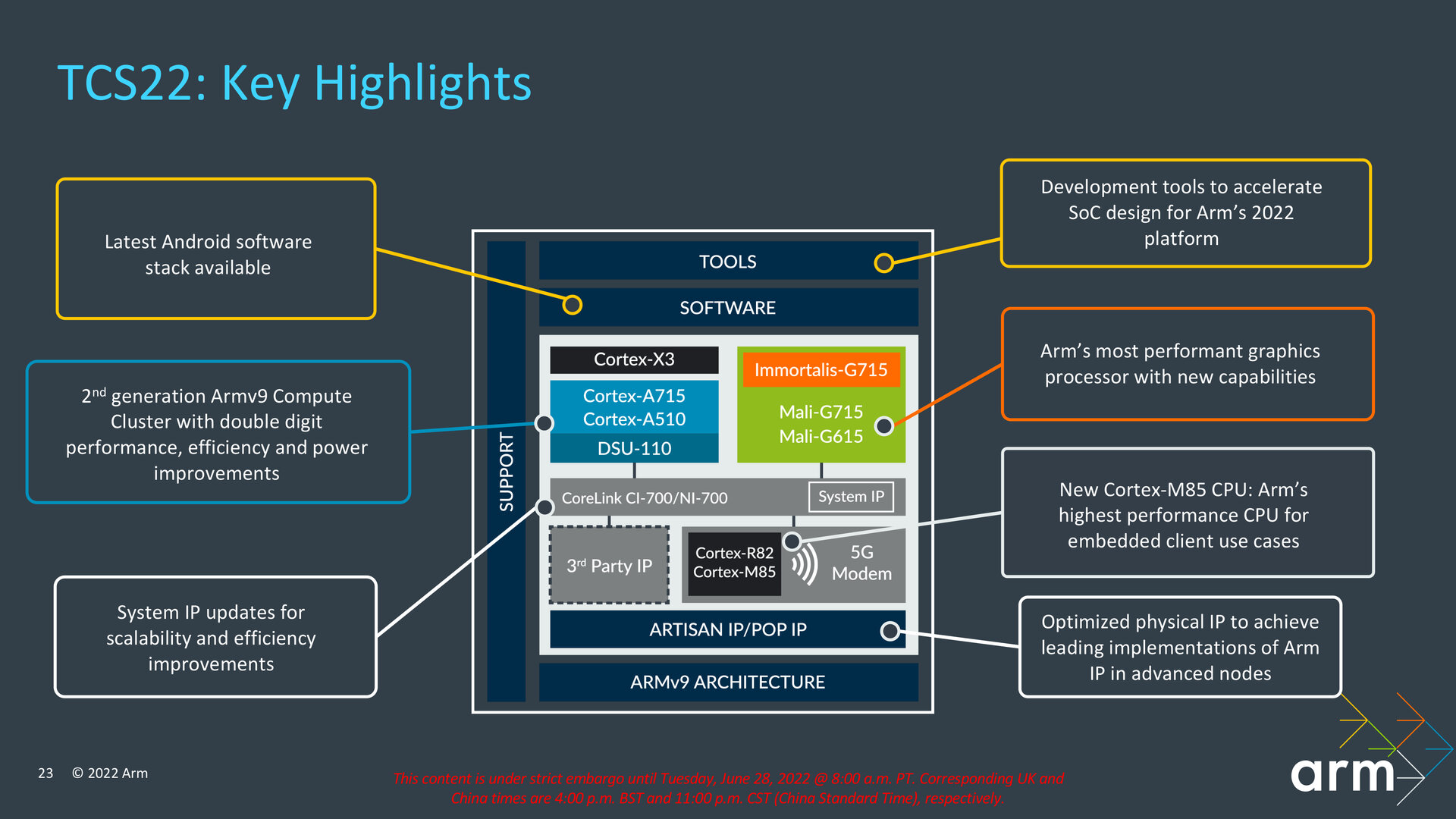
Cortex-X3, Cortex-A715 und Cortex-A510 Refresh sind die neuen CPU-Kerne des Jahrgangs 2022 von Arm und ein Bestandteil des Bereichs „Compute Performance“ der Total Compute Solutions 2022 (TCS22), die auch die Bereiche „Developer Access“ und „Security“ umfassen. So nennt Arm die ganzheitliche Lösung eigener IP dieses Jahrgangs. Entsprechende Produkte, also Prozessoren, dürften aber erst 2023 damit auf den Markt kommen. In einer typischen Konfiguration mit 1+3+4-Aufbau verspricht die TCS22 bezogen auf die Gaming-Leistung eine durchschnittliche Steigerung um 28 Prozent gegenüber der TCS21 mit Cortex-X2, Cortex-A710 und Cortex-A510.

In diese Betrachtung fließen allerdings nicht nur die neuen Cortex-Kerne ein, sondern insbesondere auch die neue Immortalis-G715-GPU und Optimierungen an der „DynamIQ Shared Unit“. Neben der Immortalis-G715 mit Hardware-Raytracing hat Arm heute als neue Grafikeinheiten zudem Mali-G715 und Mali-G615 vorgestellt. Alle drei neuen GPUs auf Basis der Valhall-Architektur deckt ComputerBase in einem separaten Artikel ab.

Evolution der letztjährigen Armv9-Premiere
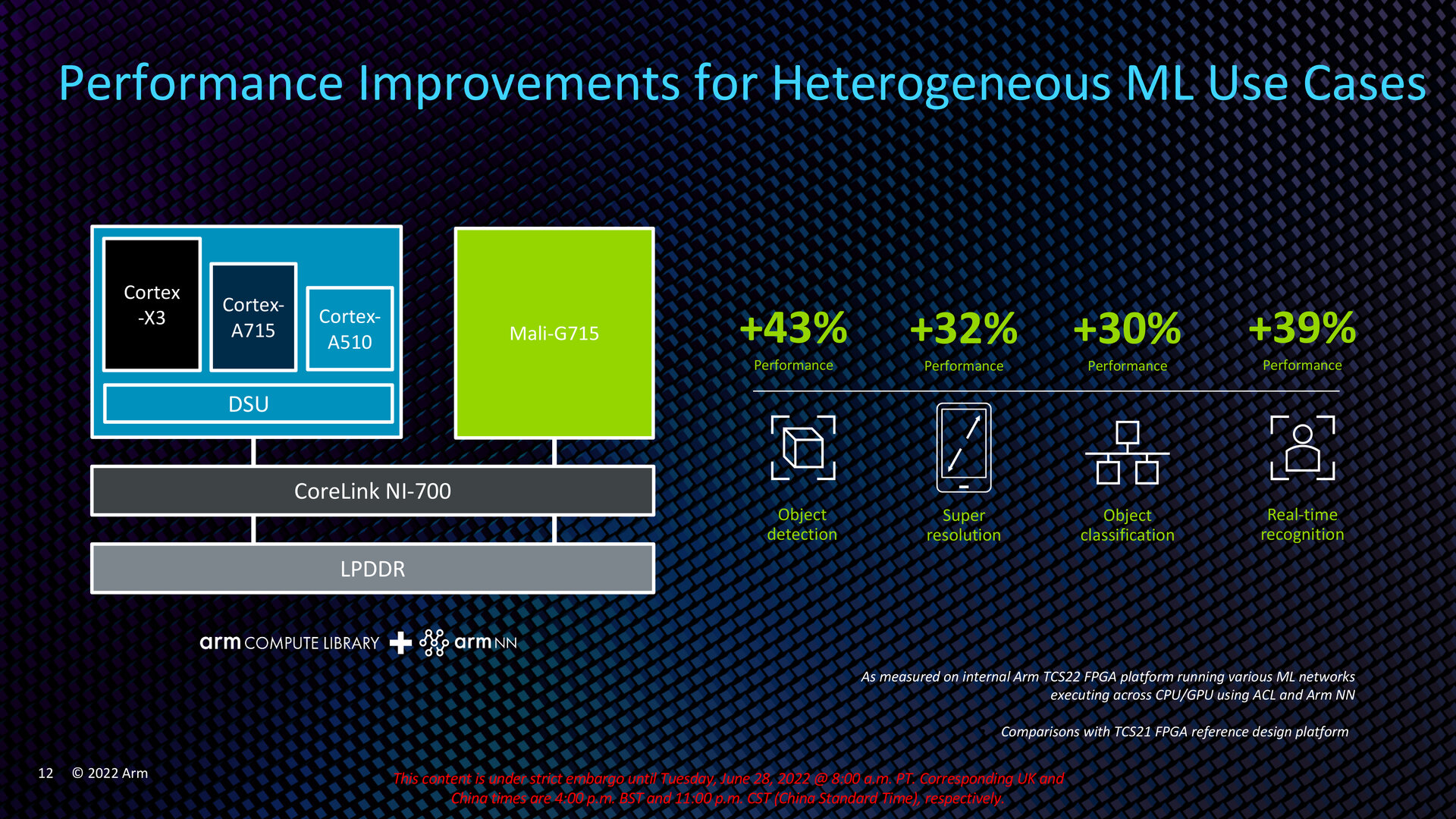
Mit der TCS21 erfolgte vor rund einem Jahr die Armv9-Premiere mit den zugehörigen Vorstellungen von Cortex-X2, Cortex-A710 und Cortex-A510 sowie DSU-110 und Mali-G710. Die TCS22 baut darauf auf und bleibt damit ISA-kompatibel. Neben der gesteigerten Gaming-Leistung von durchschnittlich 28 Prozent soll die TCS22 in diesem Szenario den DRAM-Traffic um bis zu 23 Prozent und den Energieverbrauch um bis zu 16 Prozent im Vergleich mit einer für High-End-Smartphones typischen Konfiguration reduzieren. Über die neue IP, den Support für Komponenten wie den Cortex-M85 und Software-Optimierungen legt die TCS22 auch im Bereich Machine-Learning deutlich zu. Prozentuale Veränderungen einzelner Komponenten der TCS22 gegenüber dem Vorjahr hat Arm ebenfalls vorgelegt, auf die im weiteren Verlauf des Artikels eingegangen wird.
-
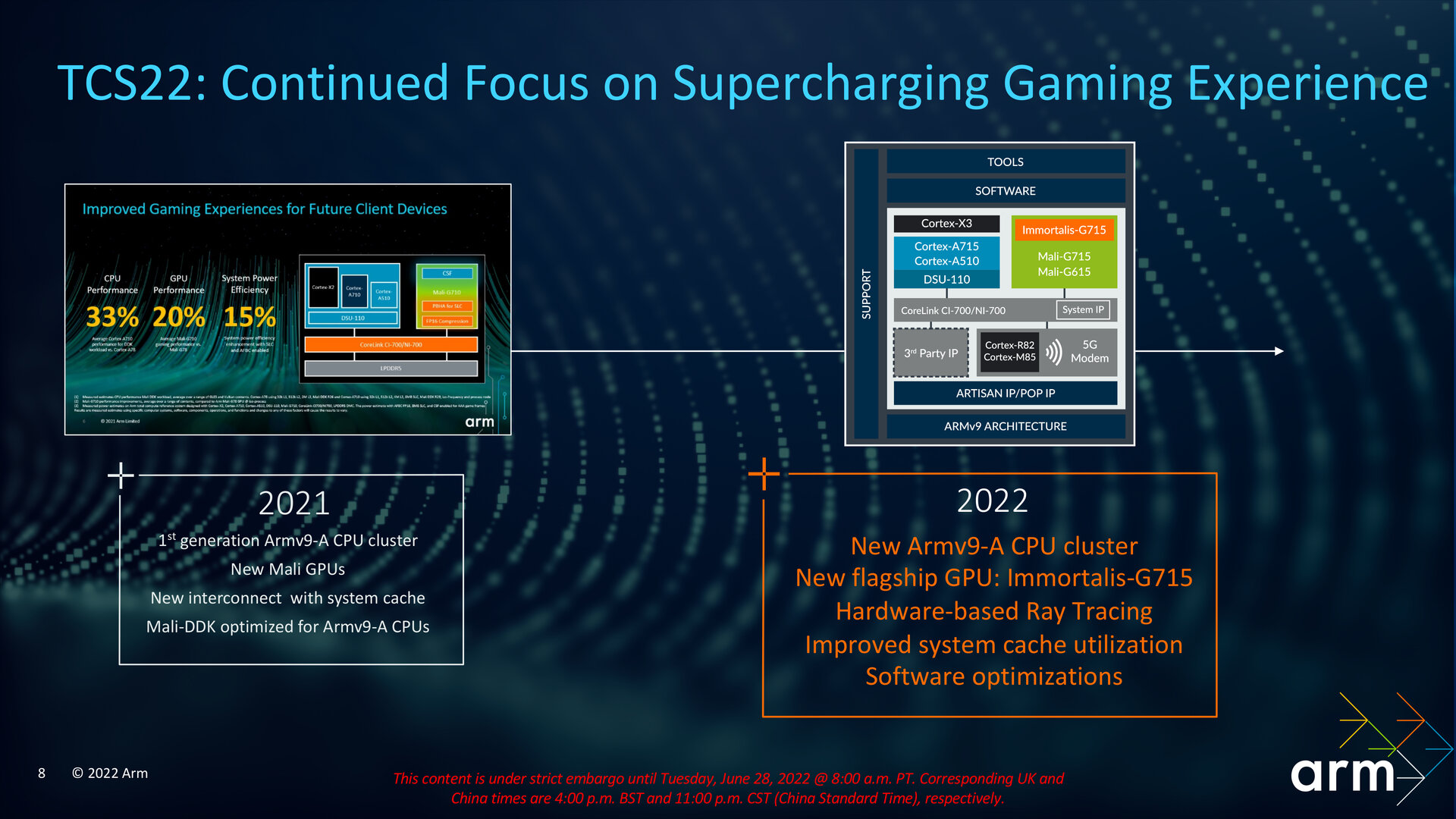 Überblick der Veränderungen der TCS22 (Bild: Arm)
Überblick der Veränderungen der TCS22 (Bild: Arm)

DSU ist bereit für schnelle Arm-Notebooks
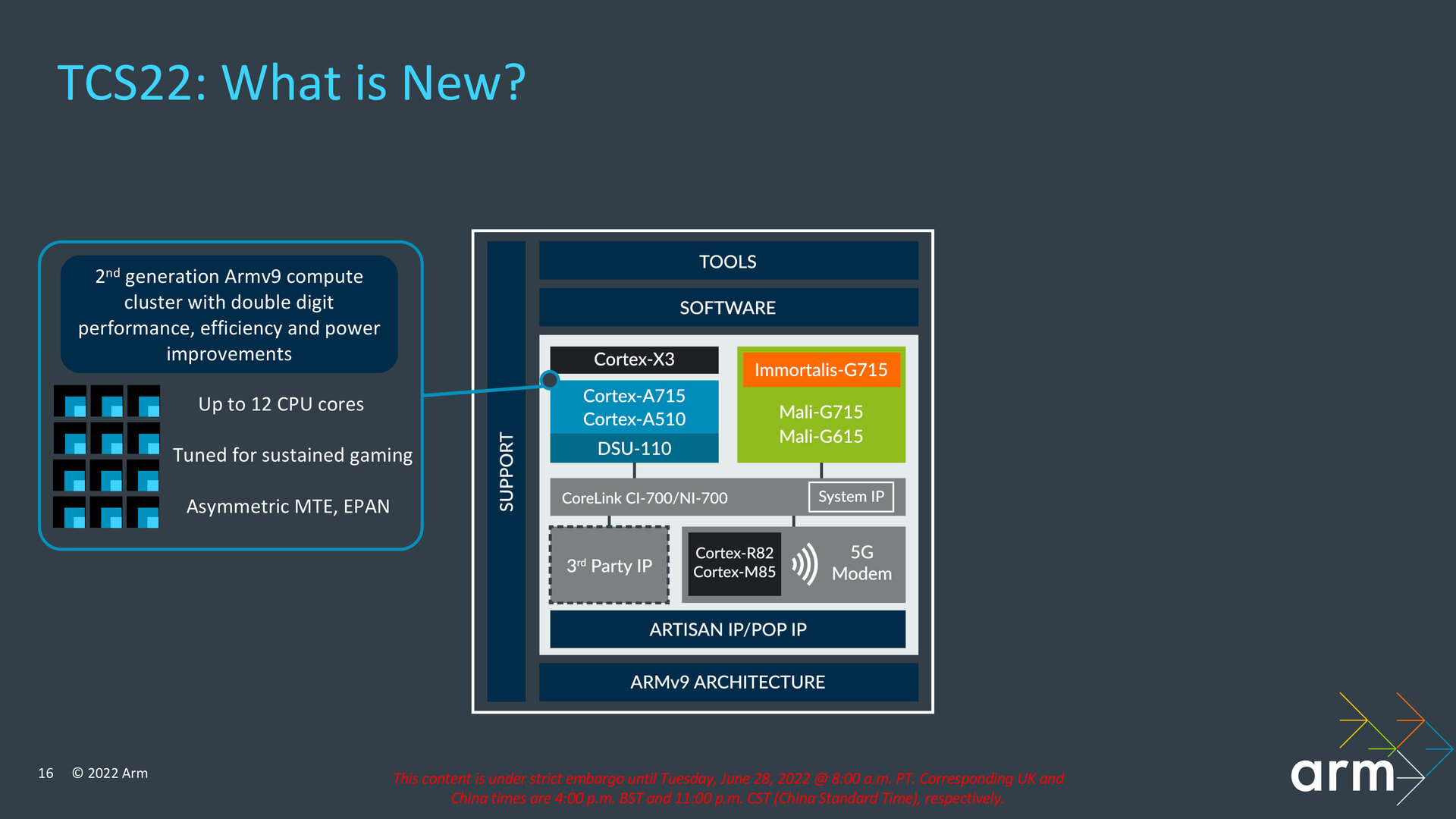
Neu im Bereich der möglichen Konfigurationen ist der Support von bis zu zwölf Kernen innerhalb des Clusters der „DynamIQ Shared Unit-110“ (DSU-110), die Arm letztes Jahr eingeführt hatte. Diese Veränderung erlaubt neue High-End-Konfigurationen, wie sie für kommende Arm-PCs notwendig sind. Exemplarisch nannte Arm im Rahmen des Client Tech Days einen Aufbau mit acht Cortex-X3 und vier Cortex-A715, aber ohne Cortex-A510 Refresh. Ebenso ließe sich damit ein SoC mit zwölf ausschließlich sparsamen kleinen Kernen realisieren. Arm will mit der TCS22 nicht nur, aber insbesondere auch Spieler ansprechen und hat die neuen Kerne deshalb für eine konstant hohe Leistung in diesem Bereich ausgelegt, ohne dass Throttling das Spielvergnügen mindern soll.
Die Mikroarchitektur der DSU-110 hat sich nicht wesentlich verändert, Arm spricht von einem notwendigen „Tuning“, um das Design für die zusätzlichen Kerne vorzubereiten. Updates gab es auch für Bereiche, die von der Anzahl der Kerne abhängig sind, etwa die Memory Mapped Registers pro Kern, sowie Prüfverfahren für die physische Umsetzung mit neuem Floorplan.
In der Theorie können Partner mit der aktualisierten DSU-110 fortan auch bis zu zwölf Kerne der letztjährigen IP verbauen. Sollen allerdings die neuesten ISA-Features wie Asymmetric MTE und EPAN (im folgenden Absatz erklärt) zum Einsatz kommen, muss die neueste IP zum Einsatz kommen.
-
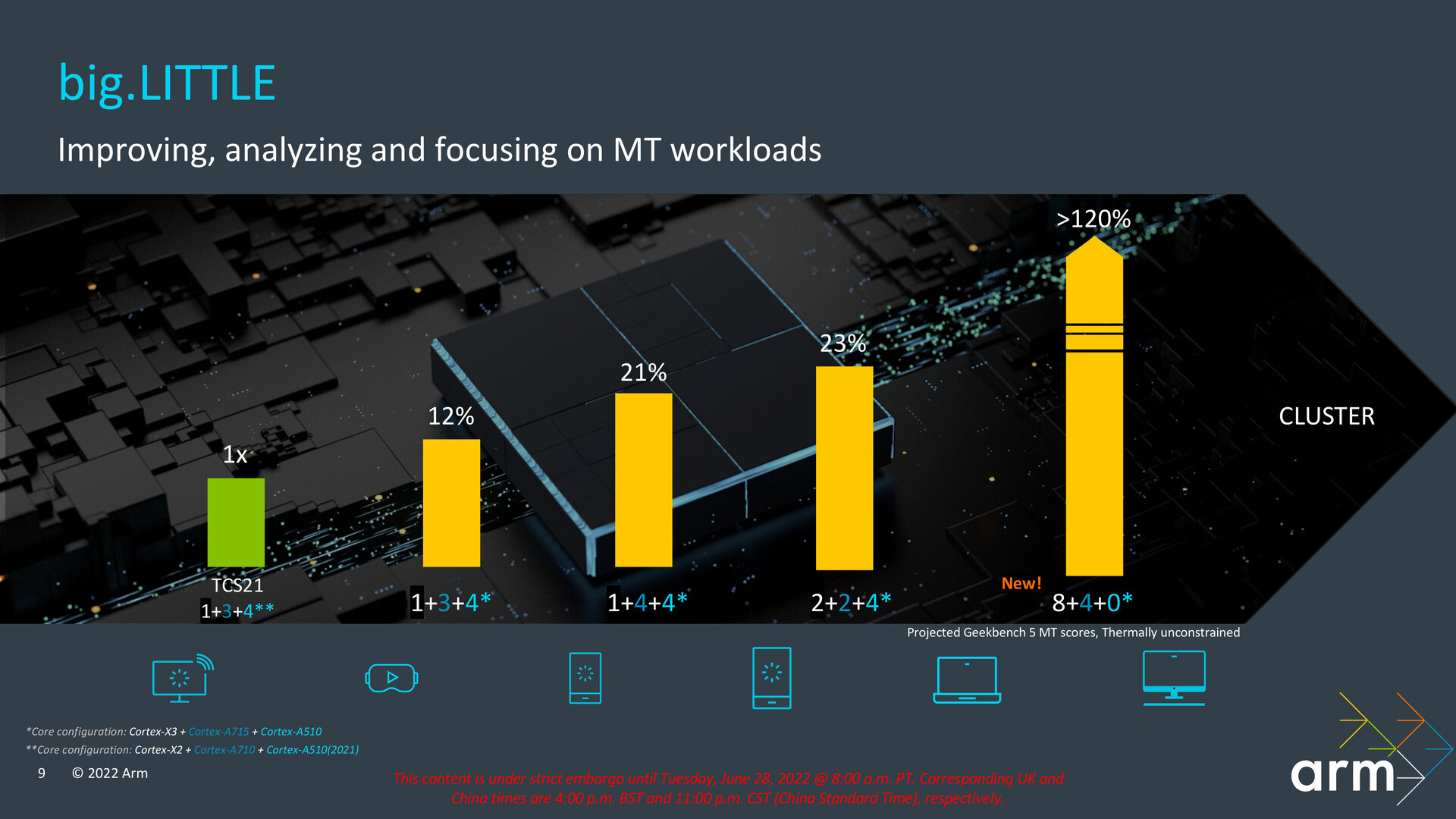 Arm-Notebooks und PCs erwartet eine neue 8+4+0-Konfiguration (Bild: Arm)
Arm-Notebooks und PCs erwartet eine neue 8+4+0-Konfiguration (Bild: Arm)

Arm erweitert Sicherheitsfeatures
Im Bereich Sicherheit bringt das neue Compute-Cluster Unterstützung für Asymmetric MTE als Erweiterung der letztes Jahr mit Armv9 eingeführten „Memory Tagging Extension“ (MTE) mit. Speicherbereiche und zugehörige Zeiger werden dabei mit dem gleichen Tag versehen und von der CPU dahingehend auf eine Übereinstimmung überprüft. Liegt dabei eine Diskrepanz vor, kommt es zu einer Verarbeitungsunterbrechung seitens der CPU. Bei Asymmetric MTE kann die CPU diesen Fehler während eines Ladebefehls triggern und asynchron dazu einen Speicherbereich während eines Speicherbefehls aktualisieren.
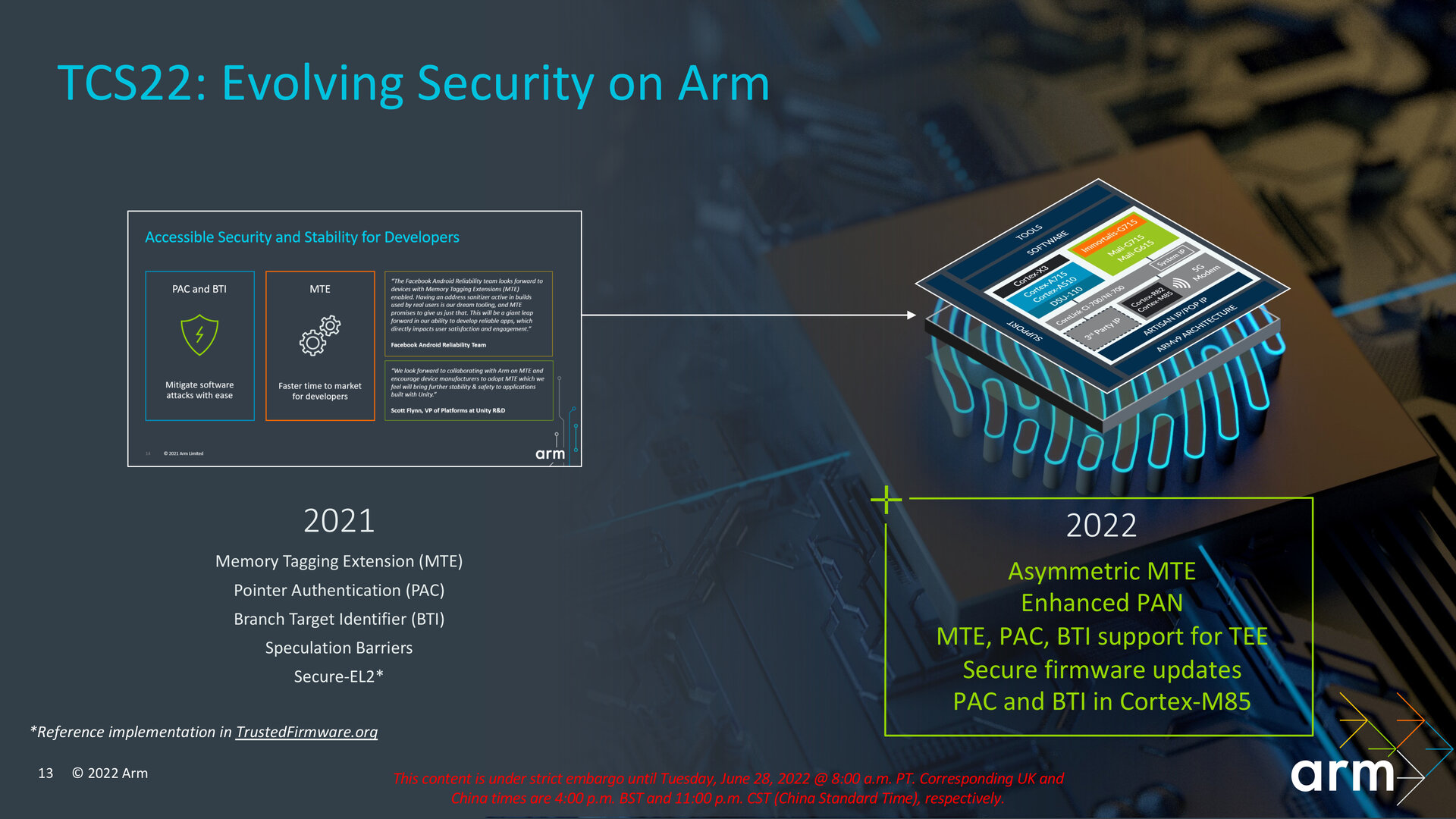
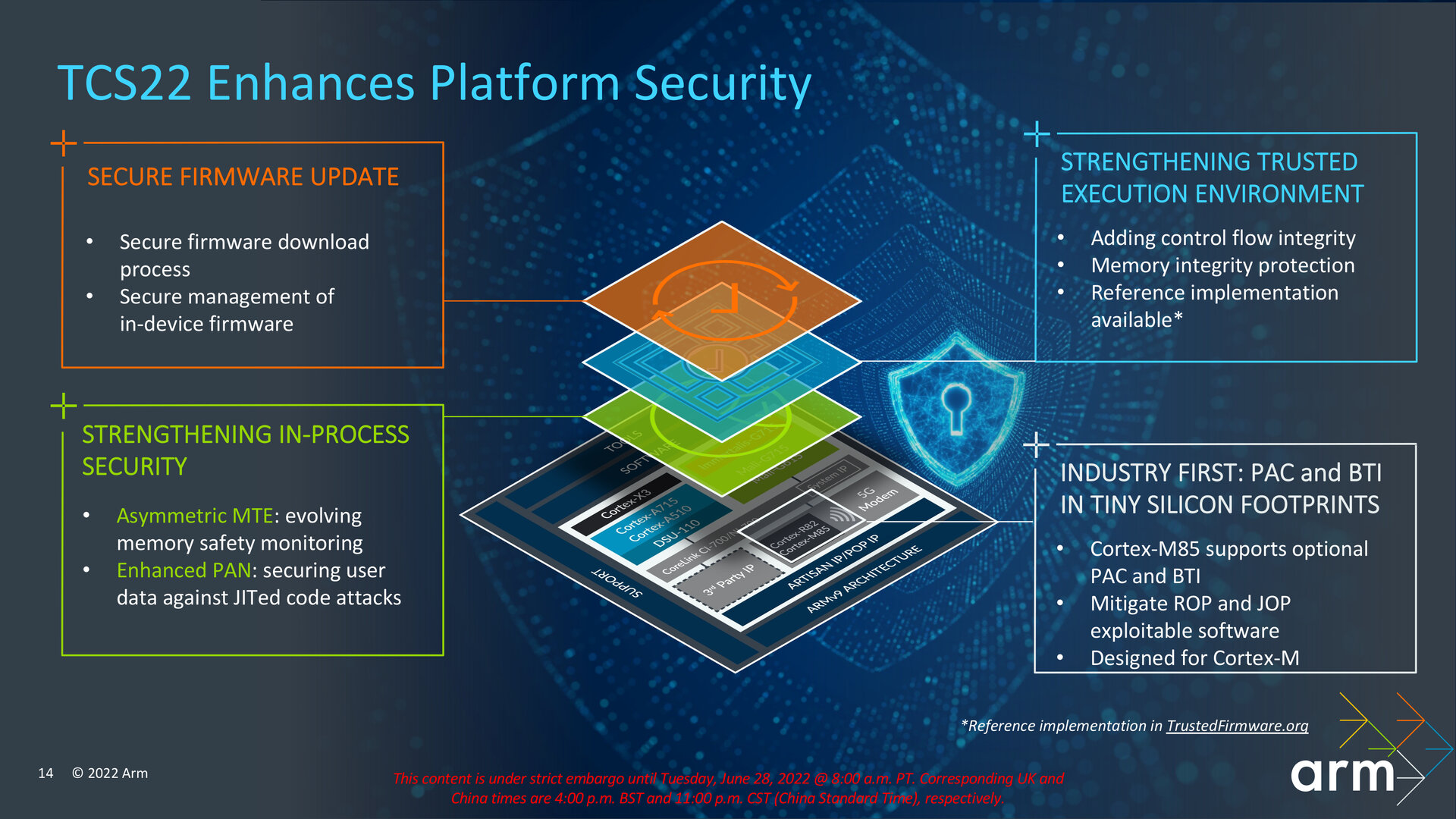
Arm legt mit EPAN („Enhanced PAN“) auch beim vorherigen PAN („Privileged Access Never“) nach, das Zugriffe etwa auf Kernel-Ebene auf weniger privilegierte Speicherbereiche des User-Modes unterbinden soll. Die Sicherheitsfunktion soll verhindern, dass ein User-Mode-Angriff etwa über einen überlisteten Kernel stattfinden kann. Ein Bug in den Arm-Spezifikationen verhinderte allerdings nicht den Zugriff auf User-Mode-Speicherseiten, die als „execute-only“ markiert waren. „Enhanced PAN“ soll genau diesen Umstand korrigieren.
Immortalis-GPU beherrscht Hardware-Raytracing
Arm führt mit der TCS22 neue Grafikeinheiten für das Flaggschiff- und Premiumsegment ein. Neues Flaggschiff ist die Immortalis-G715, die sich mit bis zu 16 GPU-Kernen integrieren lässt. Die zwei großen Neuerungen der Immortalis-G715 sind Hardware-Raytracing über eine neue RTU („Ray Tracing Unit“) im Shader-Core und die Unterstützung für „Variable Rate Shading“ (VRS). Neben der Immortalis-G715 ist die Mali-G715 eine Stufe tiefer ebenfalls neu und bietet bis auf die RTU dieselben Veränderungen wie VRS und Optimierungen an der Execution-Engine. Dasselbe gilt für die Mali-G615, die mit weniger Shader-Cores konfiguriert werden kann und optional weniger L2-Caches aufweist.
-
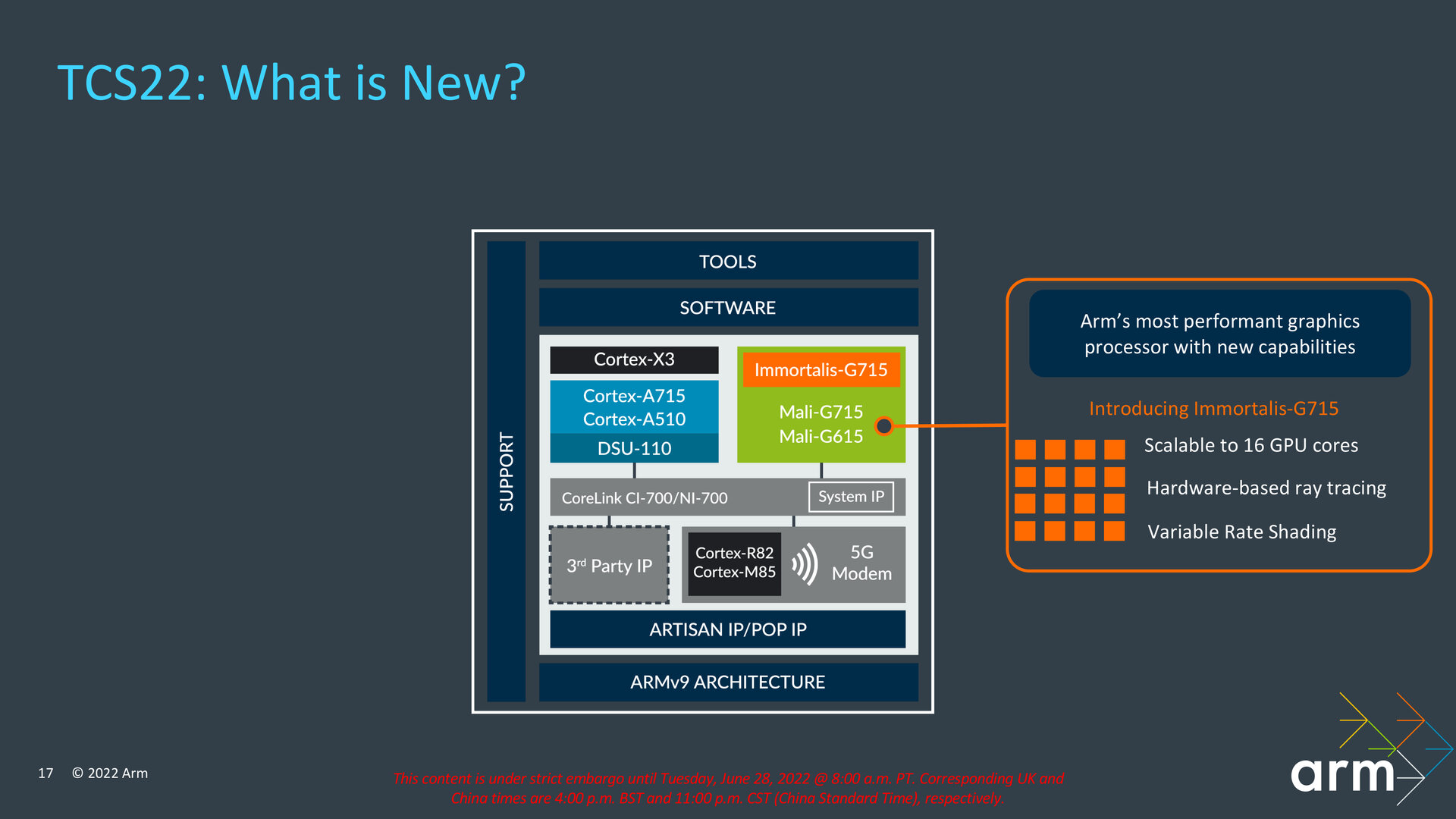 Drei neue GPUs, davon eine mit Hardware-Raytracing (Bild: Arm)
Drei neue GPUs, davon eine mit Hardware-Raytracing (Bild: Arm)
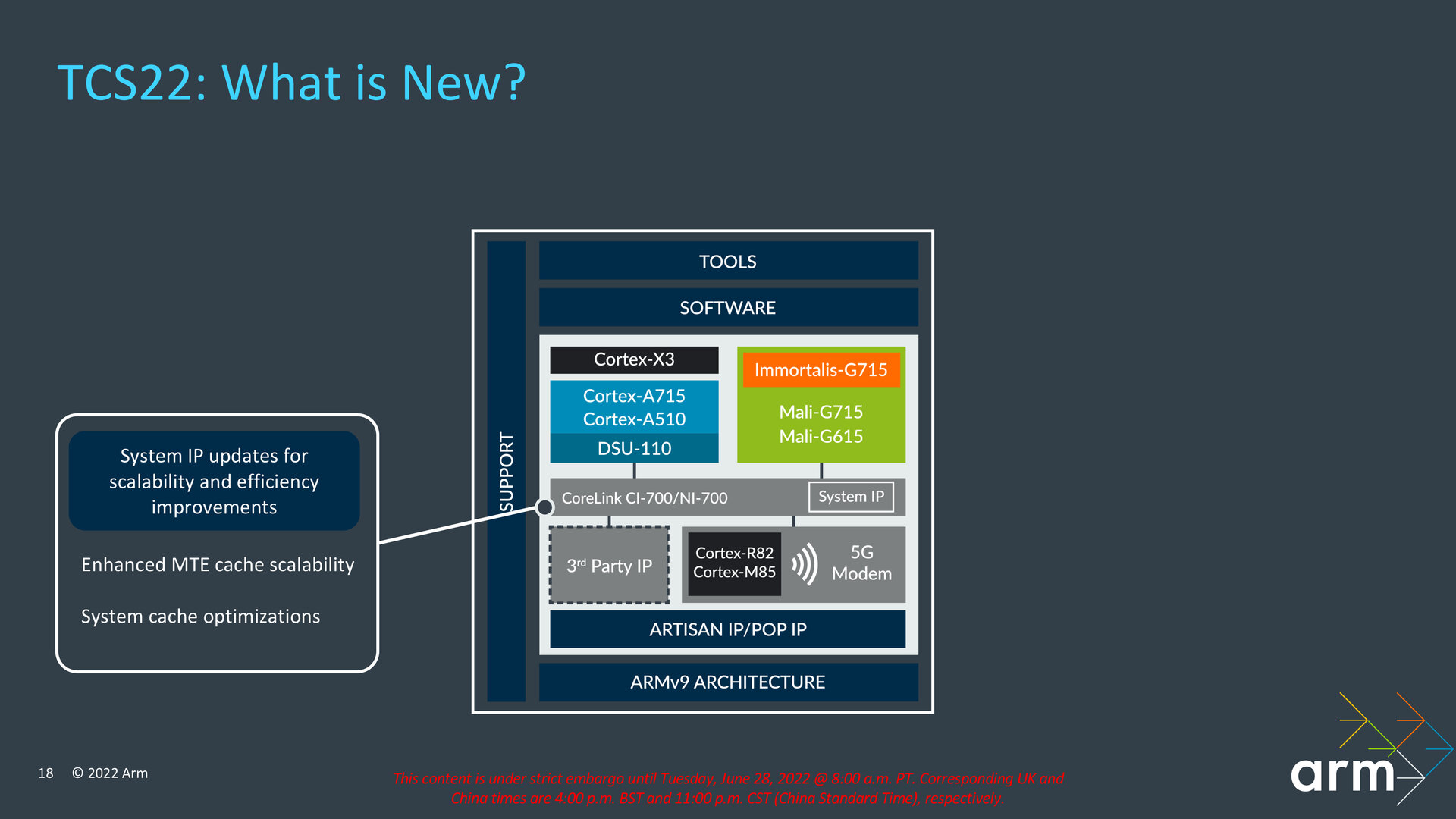
CoreLink CI-700 und NI-700 bleiben fast gleich
Für die Interconnects CoreLink CI-700 und NI-700, über die eigens entwickelte System-IPs und Third-Party-IPs anderer Hersteller angebunden werden, hat Arm Cache-Optimierungen vorgenommen, die zum Beispiel bei der Nutzung von (Asymmetric) MTE für eine bessere Skalierbarkeit sorgen sollen. An den CoreLink CI-700 können weiterhin zwischen einem und acht DSU-Cluster und acht Speicher-Controller angebunden werden – im Smartphone ist jeweils eine Komponente davon üblich. Ein CoreLink CI-700 wird mit sogenannten XP-Knotenpunkten konfiguriert, die in einem bis zu 4 × 3 Punkten großen Mesh vorliegen können, die jeweils maximal acht System-Level-Cache-Slices mit bis zu 4 MB aufweisen können. Der SLC wird von Arm auch als Speicher für die MTE-Tags genutzt.
Optimierungen für moderne Fertigungsprozesse
Die physische IP habe Arm dahingehend optimiert, dass sie besser in Kombination mit modernsten Fertigungsprozessen wie 5 nm und 4 nm genutzt werden könne, wie sie etwa Samsung und TSMC anbieten. Support liegt bei der TCS22 jetzt auch für eine Anbindung des Cortex-M85 vor, der für Embedded-Lösungen wie beispielsweise Smart Speaker geeignet ist, aber auch als Always-on-Prozessor agieren kann, um mit seinen DSP- und Machine-Learning-Funktionen Sprachbefehle etwa auf dem Smartphone zu verarbeiten. Wird der kleinere Cortex-M55 genutzt, sind darauf jetzt auch die Arm Custom Instructions lauffähig, die zu ihrer Einführung auf den Cortex-M33 beschränkt waren.
-
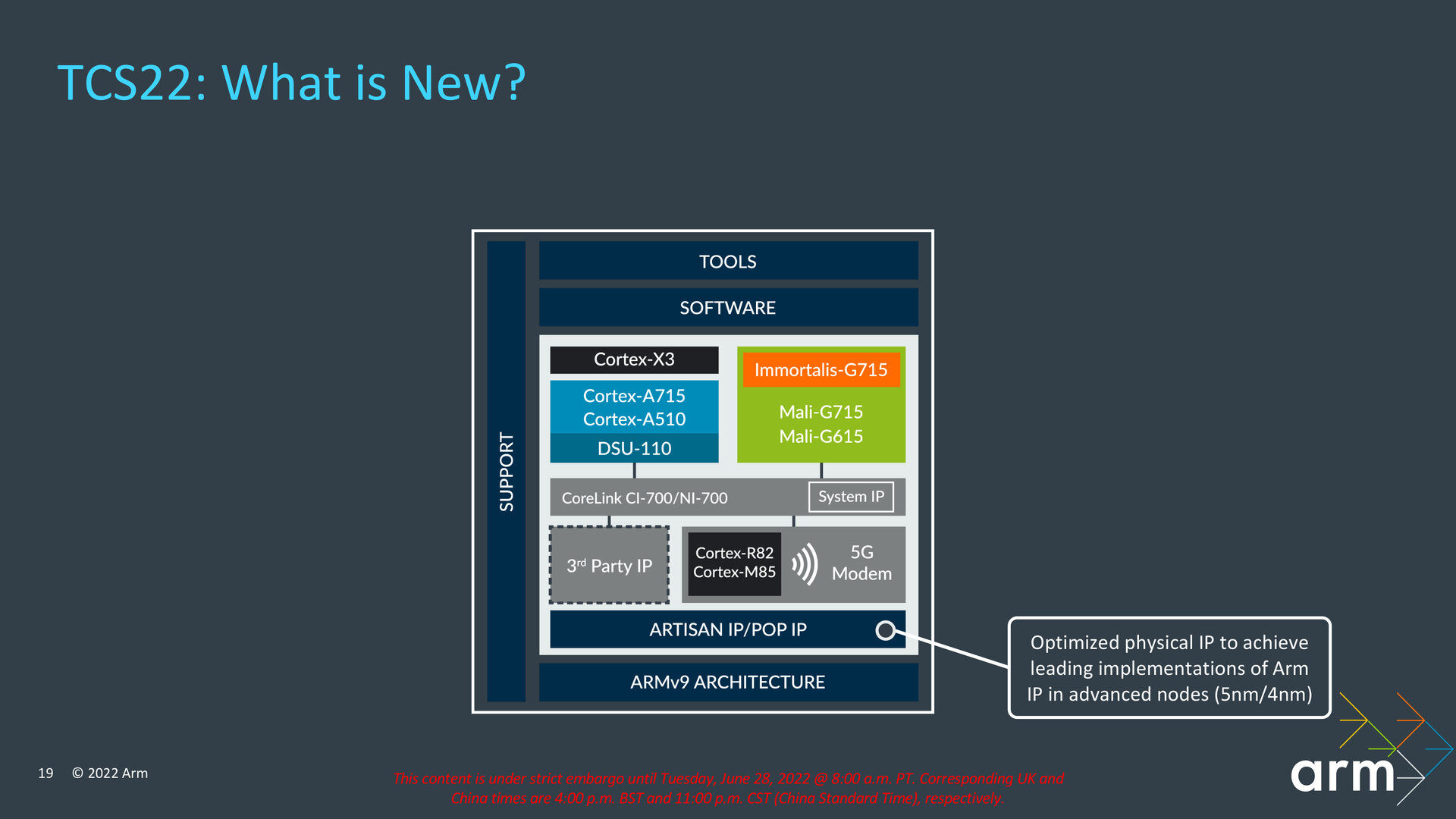 Optimierungen für moderne Fertigungsprozesse (Bild: Arm)
Optimierungen für moderne Fertigungsprozesse (Bild: Arm)
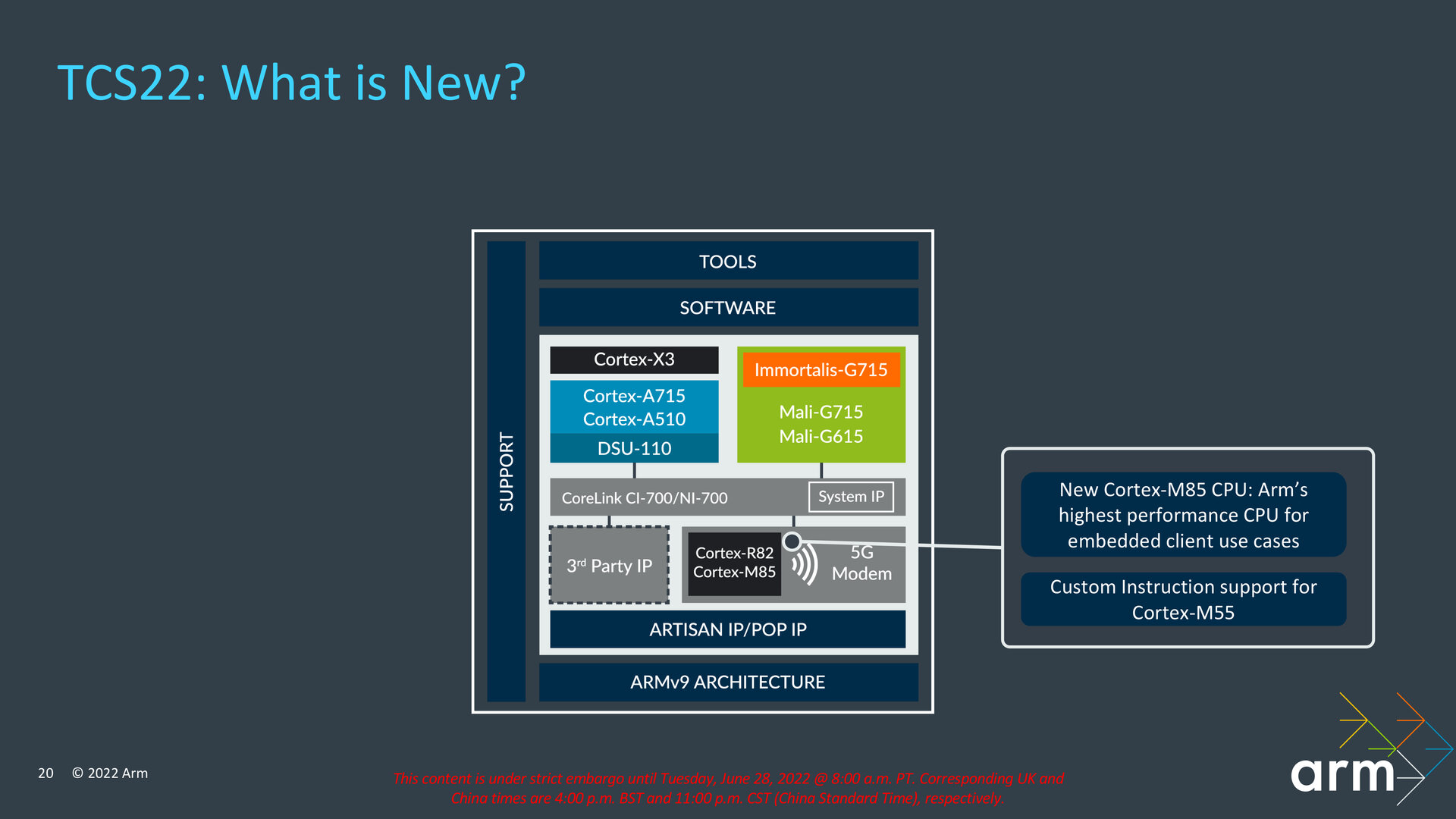
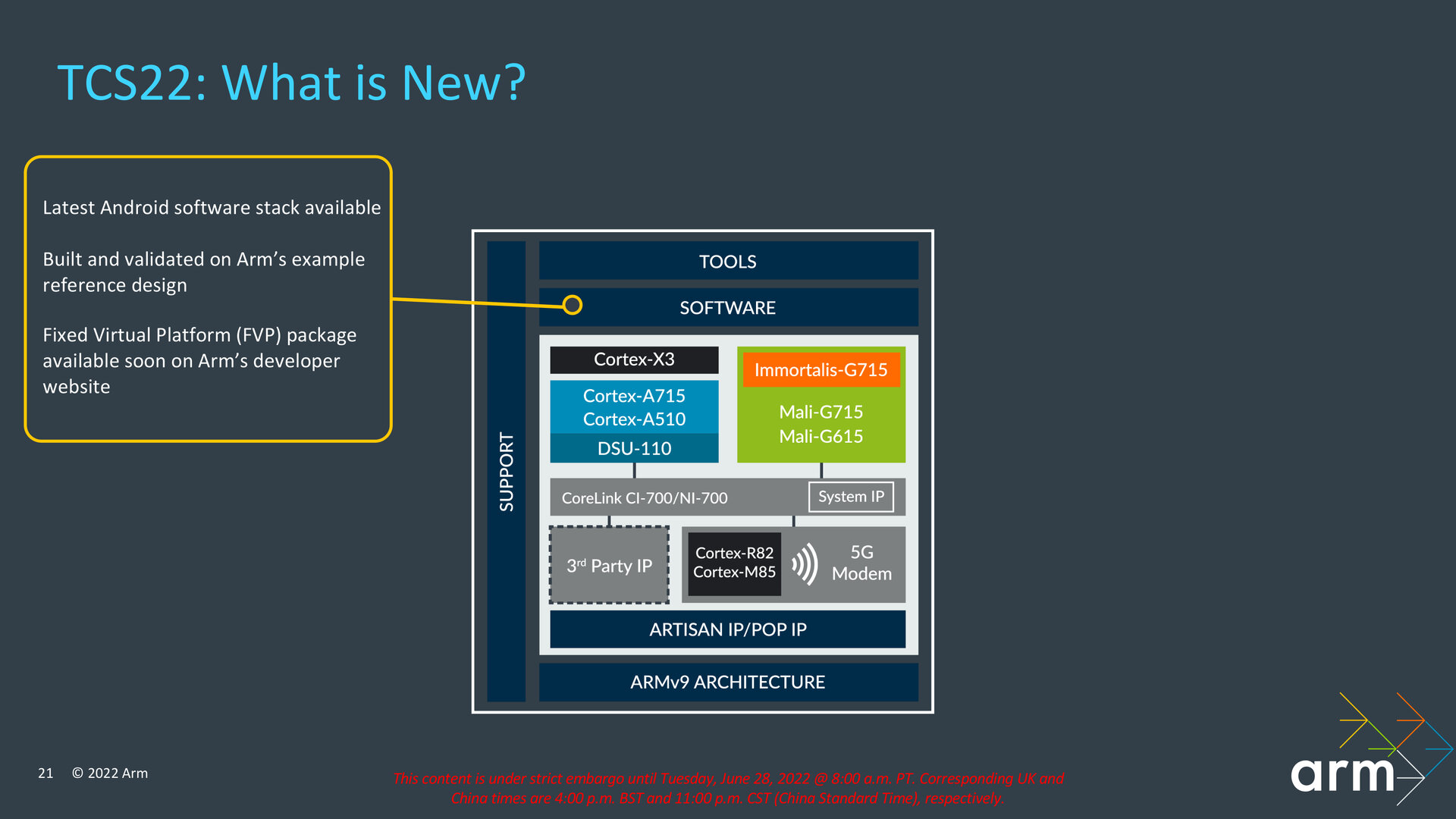
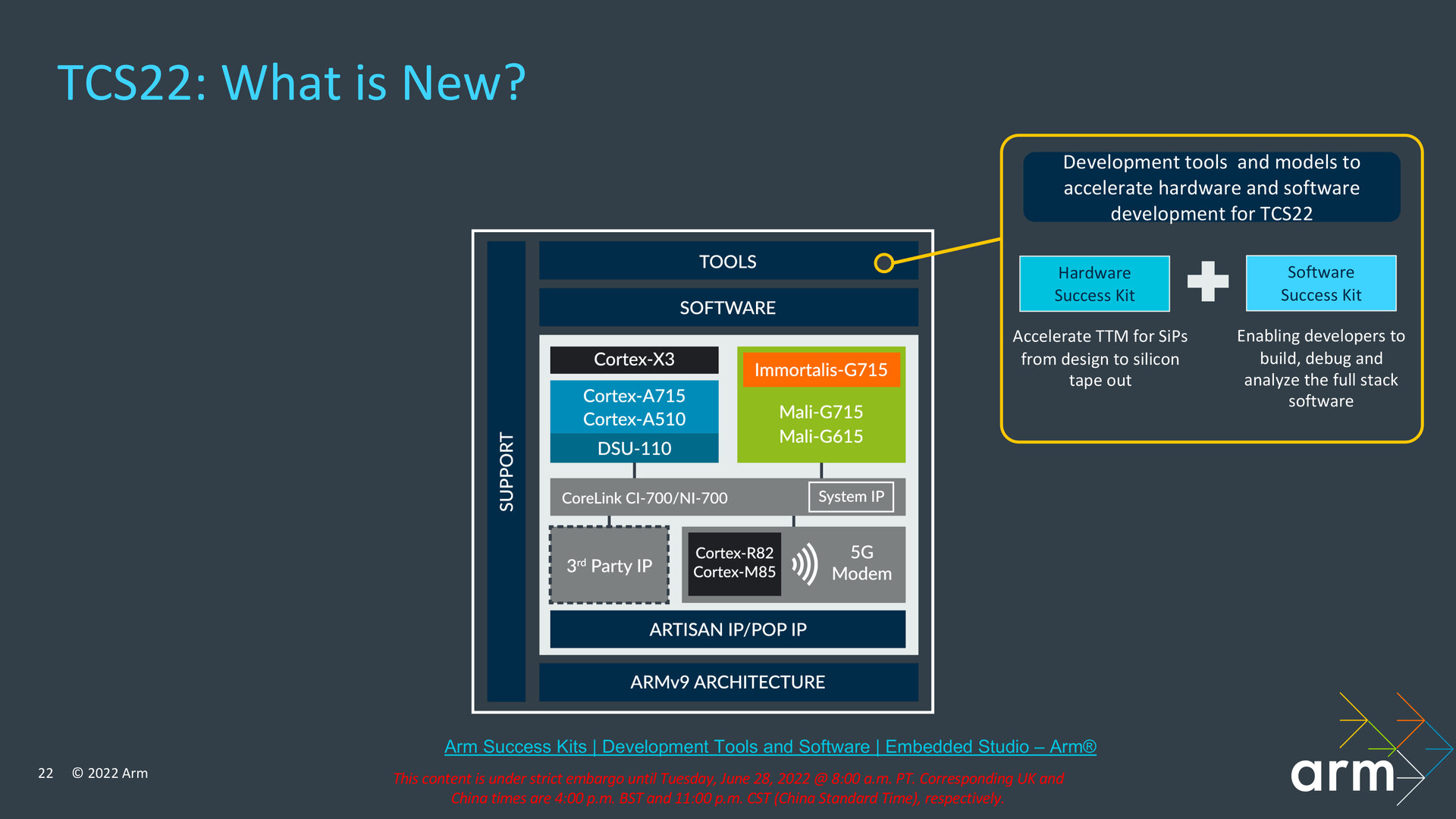
Neue Werkzeuge für Entwickler
Im Bereich der Software respektive bei den Werkzeugen für Entwickler bietet Arm mit der TCS22 Unterstützung für das neueste Android an, das in Version 13 zum Herbst erwartet wird, und will demnächst eine neue Fixed Virtual Platform (FVP) zur Verfügung stellen, mit der sich ein vollständiges Arm-System auf Basis der neuen Komponenten annähernd mit der Geschwindigkeit von echter Hardware simulieren lassen soll. Die FVP stellt Arm für die Betriebssysteme Windows und Linux zur Verfügung. Zu den Werkzeugen für Entwickler gehören auch das Hardware Success Kit und das Software Success Kit, die Arm in Kürze in neuer Generation angepasst für die TCS22 zur Verfügung stellen will.