GPU-Chiplets bei AMD: Das steckt im Patentantrag zur besseren Shader-Auslastung

AMD hat einen Patentantrag zur Aufteilung der Rendering-Last auf mehrere GPU-Chiplets veröffentlicht, der interessante Einblicke gewährt. Um die Auslastung der Shader in Games zu optimieren, wird eine Spielszene in einzelne Blöcke aufgeteilt und an die Chiplets verteilt. Dabei kommt Two-Level-Binning zum Einsatz.
Eine ganze Welle an neuen Patentanträgen
Mit einer wahren Welle an veröffentlichten Patentanträgen hat AMD in der letzten Woche potentiell eine Menge neuer Erkenntnisse zu kommenden Technologien bei GPUs und CPUs zugänglich gemacht. Alleine am 30. Juni wurden 54 Patentanträge veröffentlicht. Welche Patente am Ende genehmigt und welche sich überhaupt in Produkten wiederfinden werden, bleibt abzuwarten. Doch unabhängig davon liefern die Anträge interessante Einblicke in von AMD verfolgte technologische Ansätze.
Besonders interessant ist der Patentantrag US20220207827 zum zweistufigen Binning von Bilddaten, um Renderlasten einer GPU besser auf mehrere Chiplets verteilen zu können. Eingereicht hatte AMD den Antrag bereits Ende Dezember 2021.
Die klassische Aufteilung der Last auf Shader
Traditionell funktioniert die Rasterisierung von Bilddaten auf einer GPU verhältnismäßig einfach: Jede Shader-Einheit (ALU) der GPU kann die gleiche Aufgabe übernehmen, nämlich einzelnen Pixeln eine Farbe zuzuweisen. Dafür wird das Textur-Polygon, das sich an der Stelle des entsprechenden Pixels in der Spielszene befindet, auf den Pixel abgebildet. Da die Rechenaufgabe prinzipiell immer die gleiche ist und sich nur durch unterschiedliche Texturen an unterschiedlichen Stellen der Szene unterscheidet, nennt man die Arbeitsmethode „Single Instruction – Multiple Data“ (SIMD).
In modernen Spielen ist dieser „Shading“ genannte Rechenschritt längst nicht mehr die einzige Aufgabe einer GPU. Vielmehr kommen mittlerweile standardmäßig jede Menge Post-Processing-Effekte nach dem eigentlichen Shading hinzu, die zum Beispiel Umgebungsverdeckung, Kantenglättung und Schatten hinzufügen. Raytracing hingegen findet nicht im Anschluss, sondern parallel zum Shading statt und stellt eine gänzlich andere Rechenweise dar. Mehr dazu gibt es im Bericht So werden Strahlen von GPUs beschleunigt.
Diese Rechenlast skaliert bei Spielen auf GPUs vorbildlich auf bis zu mehreren tausend Recheneinheiten – anders als bei CPUs, wo Programme extra für mehr Kerne geschrieben werden müssen. Möglich ist das durch den Scheduler, der die Arbeit innerhalb der Grafikkarte in kleinere Aufgaben aufteilt, die von den Compute-Units (CU) verarbeitet werden. Diese Aufteilung wird Binning genannt. Dafür wird das zu rendernde Bild in einzelne Blöcke mit einer bestimmten Anzahl Pixel aufgeteilt, jeder Block von einer Untereinheit der GPU berechnet und im Anschluss synchronisiert und zusammengefügt. Dabei werden einem Block so lange zu berechnende Pixel hinzugefügt, bis die Untereinheit der Grafikkarte voll ausgelastet ist. In diesem Prozess werden die Rechenleistung der Shader, die Speicherbandbreite und die Cachegrößen berücksichtigt.

Neue Herausforderungen bei Multi-Chiplet-GPUs
Wie AMD im Patenttext herausstellt, benötigen die Aufteilung und das anschließende Zusammenfügen eine sehr gute Datenverbindung zwischen den einzelnen Elementen einer GPU. Das ist eine Hürde für die Chiplet-Strategie, da Datenverbindungen außerhalb eines Dies langsamer sind und höhere Latenzen haben.
Während bei CPUs der Gang zu Chiplets verhältnismäßig einfach war, weil eine einmal auf mehrere Kerne aufgeteilte CPU-Aufgabe auch auf Chiplets gut funktioniert, ist das bei GPUs nicht der Fall. Das bedeutet, dass der Scheduler einer GPU heute auf dem Stand ist, auf dem CPU-Software vor der Einführung der ersten Dual-Core-CPUs war. Eine feste Trennung auf mehrere Chiplets war bisher nicht sinnvoll möglich.

AMDs Ansatz: Two-Level-Binning
AMD will dieses Problem lösen, indem die Rasterisierungs-Pipeline abgeändert wird, um Aufgaben auf mehrere GPU-Chiplets aufzuteilen. Dazu wird das Binning erweitert und verbessert. AMD spricht von „Two-Level-Binning“ oder „Hybrid-Binning“.
Anstatt eine Spieleszene direkt pixelweise in Blöcke aufzuteilen, wird die Aufteilung zweistufig vorgenommen. Erst wird die Geometrie verarbeitet, das heißt, dass die 3D-Szene in ein zweidimensionales Bild umgewandelt wird. Dieser als Vertex-Shading bezeichnete Schritt geschieht normalerweise vollständig, bevor die Rasterisierung begonnen wird. Im Fall von GPU-Chiplets wird das Vertex-Shading nur minimal auf dem ersten GPU-Chiplet vorbereitet und im Anschluss die Spielszene in ein grobes Binning geschickt. Dadurch entstehen grobe Blöcke (Coarse-Bins), die jeweils von einem GPU-Chiplet abgearbeitet werden. Innerhalb dieser groben Blöcke wird das Vertex-Shading vollendet, sodass im Anschluss die herkömmlichen Aufgaben wie Rasterisierung und Post-Processing erfolgen können.
Das Chiplet, das die Aufteilung übernimmt, ist dabei immer das gleiche und wird „Primary Chiplet“ genannt. Es ist direkt mit dem Rest des PCs, vornehmlich der CPU, verbunden. Die anderen Chiplets stehen hintenan und erledigen Aufgaben nur, wenn sie ihnen zugewiesen wurden. Dafür arbeiten sie asynchron und können auch dann weiterarbeiten, wenn das „Primary Chiplet“ mit der Analyse der Szene für den nächsten Frame beschäftigt ist („Visibility Phase“). Überhaupt scheint es eine enorme Herausforderung zu sein, die Auslastung der Recheneinheiten zu maximieren. Ist das „Primary Chiplet“ mit dem Coarse-Binning der Spielszene beschäftigt, „warten“ die anderen Einheiten auf Daten. Ist ein Chiplet mit seinem Block früher fertig als der Rest, wird wieder gewartet. Das wäre ineffizient.
Um die Auslastung der Chiplets zu optimieren, liefert AMD im Patent neben einer statischen Aufteilung der Arbeit (Chiplet 1 arbeitet immer an Block 1, Chiplet 2 an Block 2 etc.) auch eine dynamische Aufteilung. Dabei wird die Arbeitslast eines jeden Blocks zu Anfang abgeschätzt, um im Anschluss die Blöcke so zu verteilen, dass alle Chiplets gleichzeitig fertig werden. Die zwei Prinzipien werden in den Abbildungen dargestellt, die im Patent „Fig. 4“ und „Fig. 5“ heißen.
-
 Statische Arbeitsaufteilung auf GPU-Chiplets. Durch unterschiedliche Komplexitäten der Aufgaben (410-420) sind die Chiplets unterschiedlich schnell fertig. (Bild: AMD)
Statische Arbeitsaufteilung auf GPU-Chiplets. Durch unterschiedliche Komplexitäten der Aufgaben (410-420) sind die Chiplets unterschiedlich schnell fertig. (Bild: AMD)
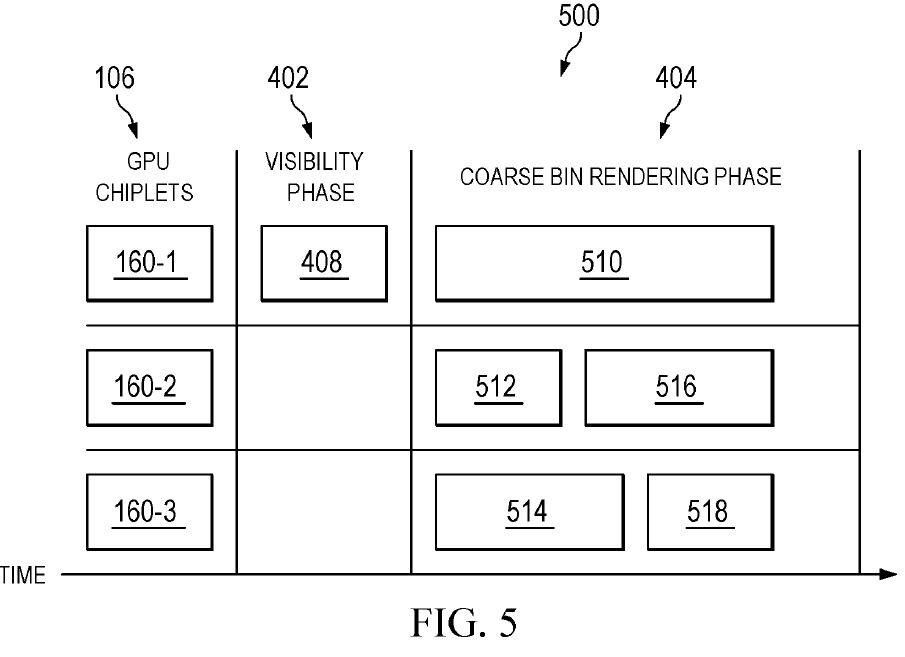
AMDs Ansatz berücksichtigt dabei auch „einfache“ Rechenlasten, bei denen zum Beispiel alte Spiele die GPU so wenig fordern, dass es unwirtschaftlich wäre, die Aufteilung auf mehrere Chiplets vorzunehmen. Dann wird die Rasterisierung komplett vom ersten Chiplet übernommen und abgearbeitet. Es entsteht kein Overhead und die übrigen Chiplets können in einen energiesparenden Zustand geschickt werden.
AMD schützt mit seinem Patent auch eine Lösung per Treiber, indem ein Verfahren via „non-transitory computer readable medium“ beschrieben wird. Der Treiber soll Instruktionen bereitstellen, die die Arbeitsaufteilung auf die GPU-Chiplets wie beschrieben ermöglichen.
Wann kommt Radeon mit GPU-Chiplets?
Wann der von AMD beschriebene Ansatz zur optimierten Auslastung der Shader auf Multi-Chiplet-GPUs in Spielen in der Praxis relevant wird, darüber herrscht aktuell noch keine Klarheit. AMD hat inzwischen zwar bestätigt, dass RDNA 3 als Basis von Radeon RX 7000 Ende des Jahres auf einen Chiplet-Ansatz setzen wird, nicht aber, dass es mehrere GPU-Chiplets geben wird. Zuletzt hieß es, es werden zwar mehrere Speicher-Controller mit Infinity-Cache-Chiplets, aber nur ein GPU-Chiplet zum Einsatz kommen. Ob diese Gerüchte am Ende zutreffen, bleibt abzuwarten.
Bereits heute auf zwei GCDs (Graphics-Compute-Dies) setzt CDNA 2 für die HPC-Grafikkarten der Instinct-MI200-Serie, CDNA 3 wird darauf aufbauen. Verbunden werden die Chiplets über den „AMD Infinity Interconnect“.


- Radeon RX 7000 & MI300: RDNA 3 kommt mit Chiplets, aber erst CDNA 3 stapelt sie
- AMD Radeon RX 7000: Navi 3X und RDNA 3 sind hybrid in 5 und 6 nm geplant
Die Redaktion dankt Community-Mitglied @ETI1120 für den Hinweis zu diesem Artikel.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.