Hot Chips 34: Intel spricht über die Leistung der HPC-GPU Ponte Vecchio

Pointe Vecchio ist extrem schnell, verkauft Intel zu Hot Chips 34. Das extrem verspätete Produkt nimmt es laut Intel problemlos mit Nvidias Ampere-Generation auf. Doch die präsentierten Zahlen sind wie immer mit Vorsicht zu genießen. Ob die theoretischen Spitzenwerte in der Praxis ankommen, bleibt fraglich. Und H100 rückt näher.
Ponte Vecchio schlägt Nvidia A100 von 2020
Ponte Vecchio, die auf einem Multi-Chip-Ansatz basierende HPC-GPU auf Basis der Xe-Architektur von Intel, nähert sich der Serienreife. Mit im Gepäck hat der Hersteller zum Fachsymposium Hot Chips 34 deshalb passende Benchmarks, die gute Werte offenbaren und das eigene Produkt gegenüber dem bisherigen Platzhirsch in dem Marktsegment, Nvidias A100-GPU, deutlich schneller darstellen.
Ponte Vecchio soll zusammen mit Sapphire Rapids direkt zum Start den Exascale-Supercomputer Aurora antreiben, der sich immer weiter verspätet, weil Intels Chips noch fehlen.
-
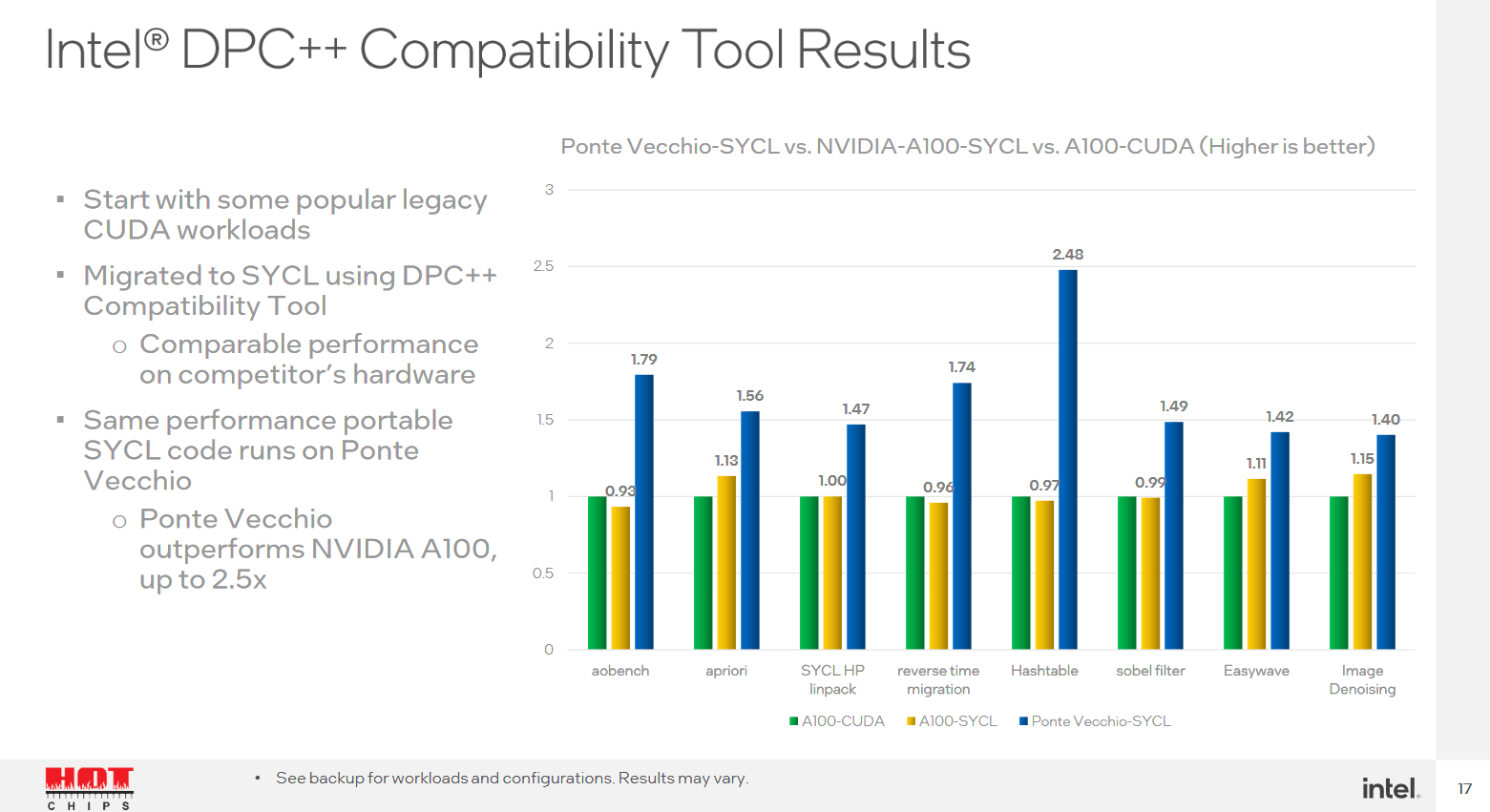 Intel-Benchmarks zu Ponte Vecchio gegen Nvidia A100 (Bild: Intel zu Hot Chips 34)
Intel-Benchmarks zu Ponte Vecchio gegen Nvidia A100 (Bild: Intel zu Hot Chips 34)
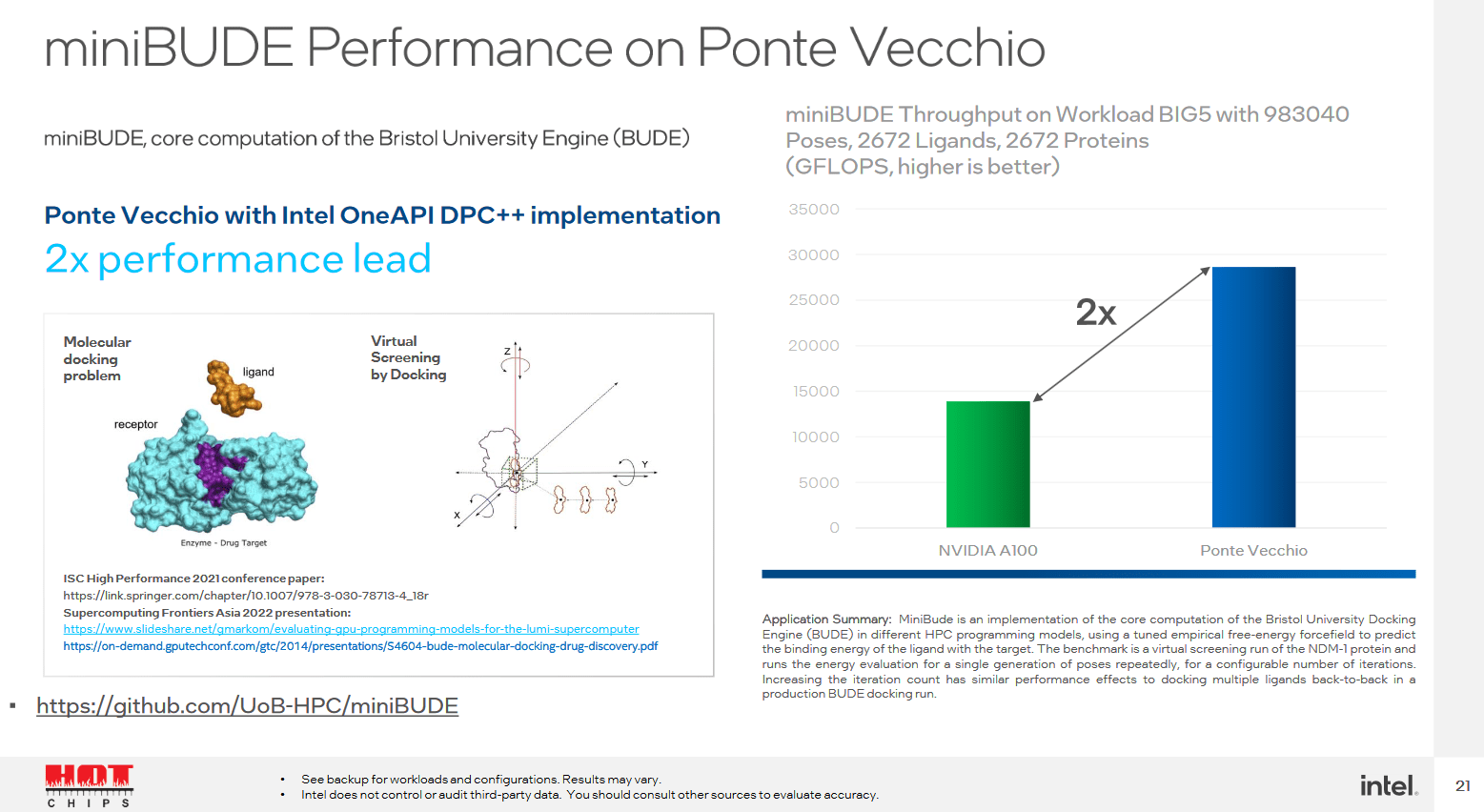

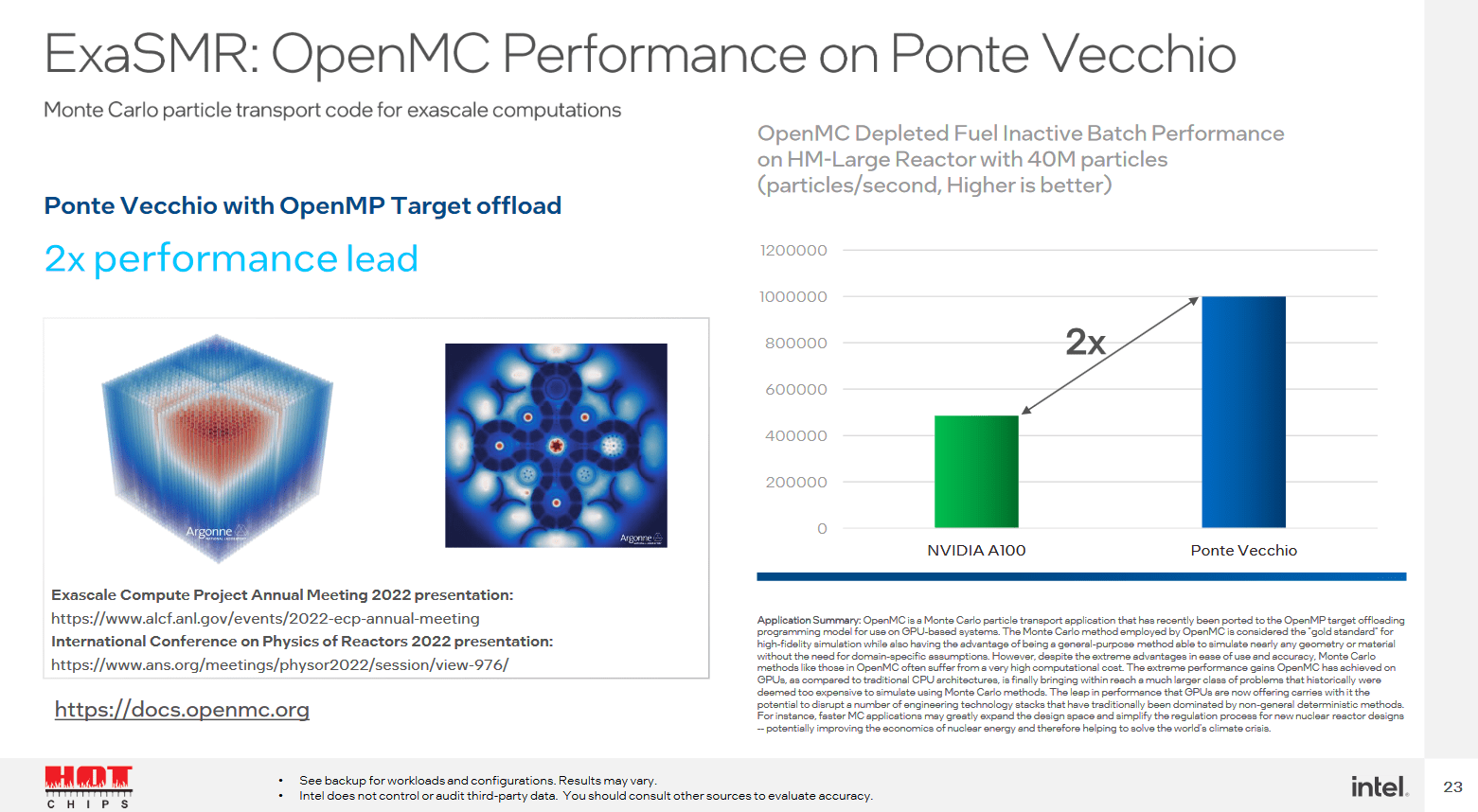
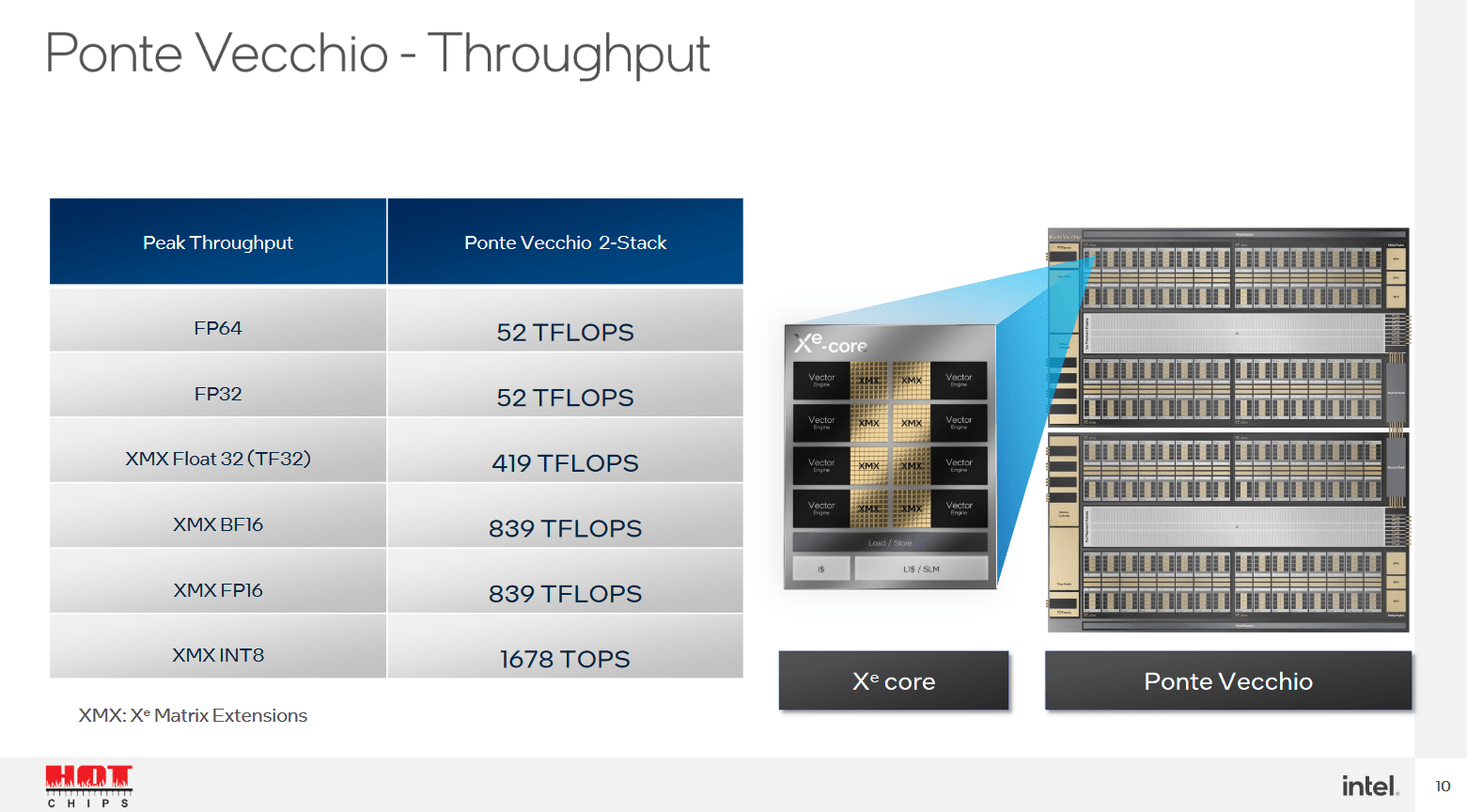
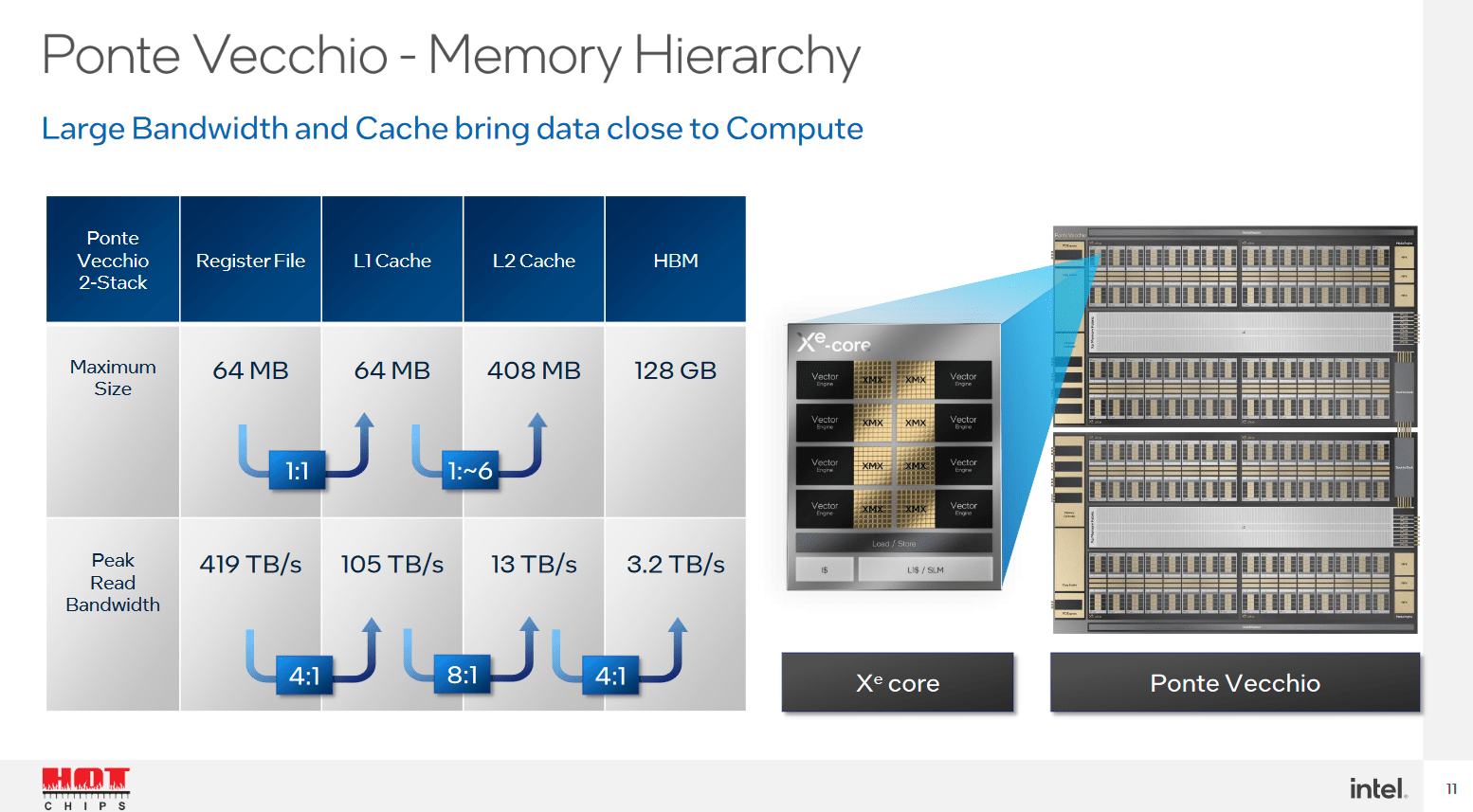
Ponte Vecchio wird über einen vergleichsweise riesigen L2-Cache von 408 MB verfügen und kann damit einige Anwendungen deutlich beschleunigen. Intel spricht im Vergleich zu künstlich auf 32 respektive 80 MB eingebremsten Ausbaustufen von bis zu 50 Prozent Leistungsvorteil. Dafür verzichtet Intel bei Ponte Vecchio auf einen L3-Cache, nach dem L2 kommen 128 GB HBM2e.
-
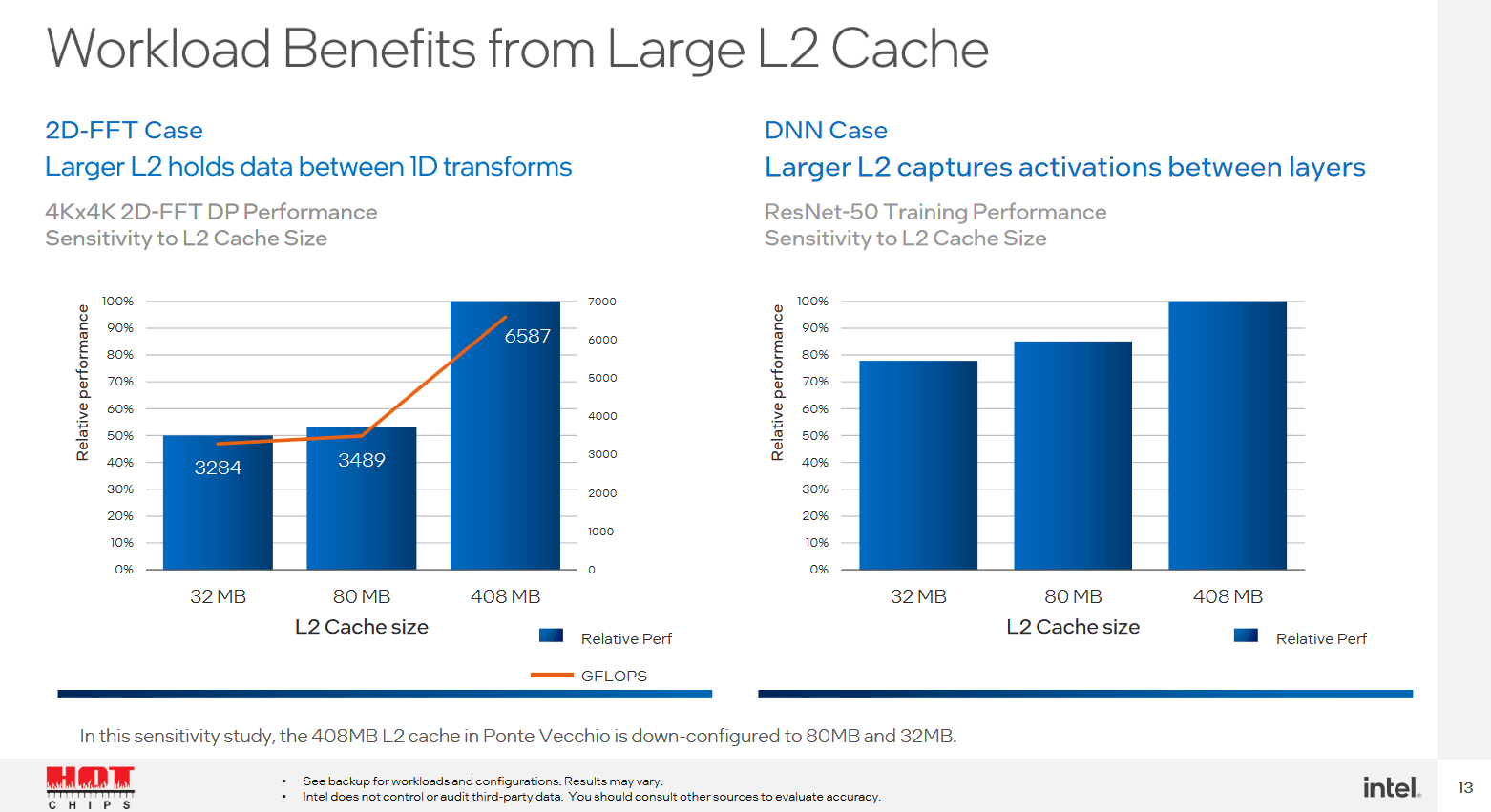 Viel L2-Cache hilft viel (Bild: Intel zu Hot Chips 34)
Viel L2-Cache hilft viel (Bild: Intel zu Hot Chips 34)
Ponte Vecchio wird auch auf Hopper GH100 treffen
Nicht von Intel zur Hot Chips erwähnt wurde: Bis Ponte Vecchio dann einmal auf dem Markt ist, wird auch Nvidias Hopper-Generation in Form der GH100-GPU langsam verfügbar sein. Hier sind die Vorzeichen wieder deutlich andere, denn der Nachfolger von Nvidia Ampere im Profi-Bereich wird ebenfalls deutlich schneller zu Werke gehen.
Auch Nvidia hat für Hopper am L2-Cache geschraubt, setzt darüber hinaus auf neuesten HBM3 und will auch sonst in den meisten Bereichen stets um den Faktor 2 gegenüber Ampere zulegen. Auf dem Papier sieht es bei hoher Genauigkeit (FP64) nach einem Vorteil für Intel aus, bei niedrigerer Genauigkeit und insbesondere bei AI- und Cryptographie-Lasten dürfte aber Nvidia vorne liegen. Mit CUDA hat der Konkurrent darüber hinaus bereits ein starkes Standbein im Markt, da muss Intel mit oneAPI erst noch beweisen, wie gut das funktioniert.
Theorie und Praxis dürften abweichen
Am Ende sind die präsentierten Zahlen aber letztlich nur vom Hersteller präsentierte, mit hoher Wahrscheinlichkeit klug ausgewählte Zahlen, wie Dan Ernst, Principal Architect für Future Azure Cloud Systems und viele Jahre beim Supercomputer-Anbieter Cray angestellt, in mehreren Postings über Twitter erklärte. Es müsse extrem darauf geachtet werden, was die Hersteller verkaufen. Oft ist es der theoretische absolute Spitzenwert, der in echten Systemen letztlich nie erreicht wird.