Hot Chips 34: Nvidia nennt mehr Details zum Grace (Hopper) Superchip

Zum Auftakt der Konferenz Hot Chips 34 hat Nvidia noch vor den eigenen Vorträgen weitere Details zu den „Superchips“ Grace und Grace Hopper veröffentlicht. Neben Details zur Bandbreite des Interconnects NVLink-C2C, der die Chips verbindet, hat Nvidia dabei auch die Wahl von LPDDR5X als Arbeitsspeicher begründet.
Neuer NVLinks-C2C für die Kommunikation
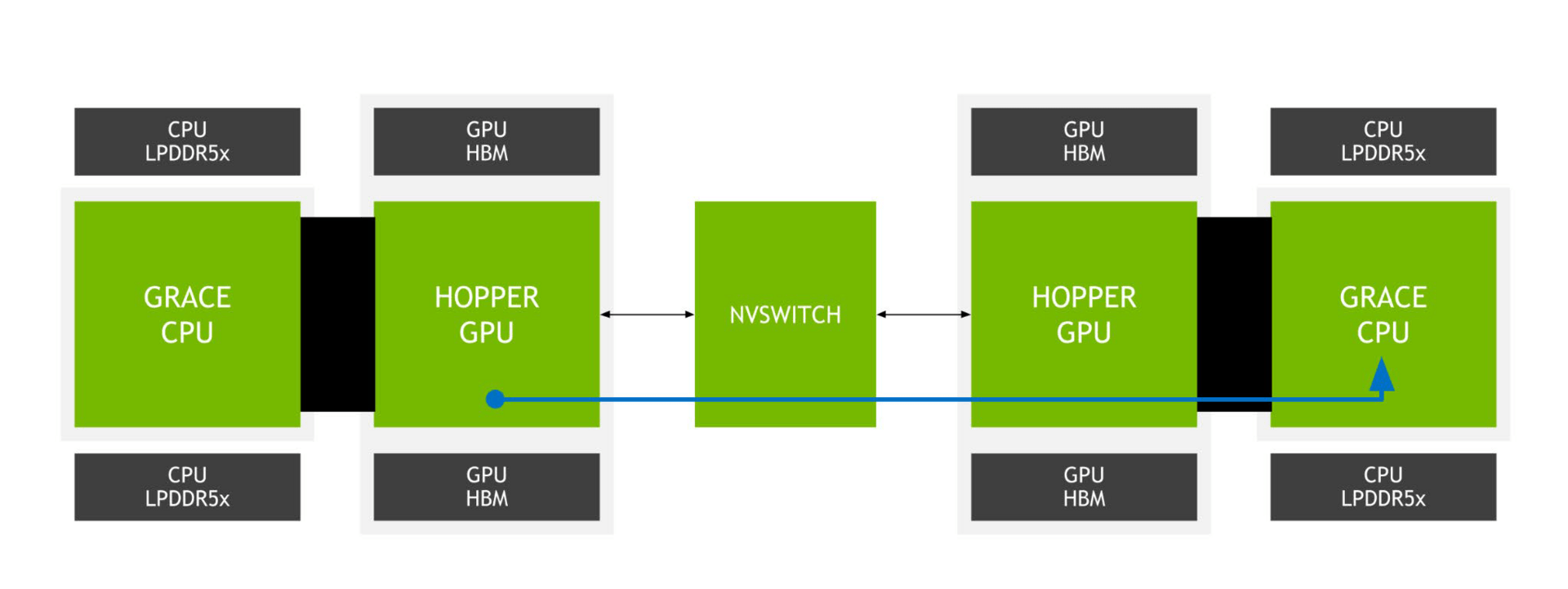
Besonderen Wert legt Nvidia auf den NVLink-C2C (Chip to Chip). Er verbindet beim Grace Superchip zwei ARM-CPUs des Typs Grace und beim Grace Hopper Superchip eine CPU und eine Hopper-GPU miteinander. Besonders stolz ist Nvidia dabei auf die Übertragungsraten bei extrem niedriger Latenz und niedrigem Energiebedarf, der Hersteller spricht von der siebenfachen Bandbreite gegenüber PCIe 5.0 mit 16 Lanes und der fünffachen Energieeffizienz.

Mit dem klassischen NVLink-Interface der Superchips lassen sich die Superchips über den neuen NVSwitch auch zum Superchip-Cluster skalieren.
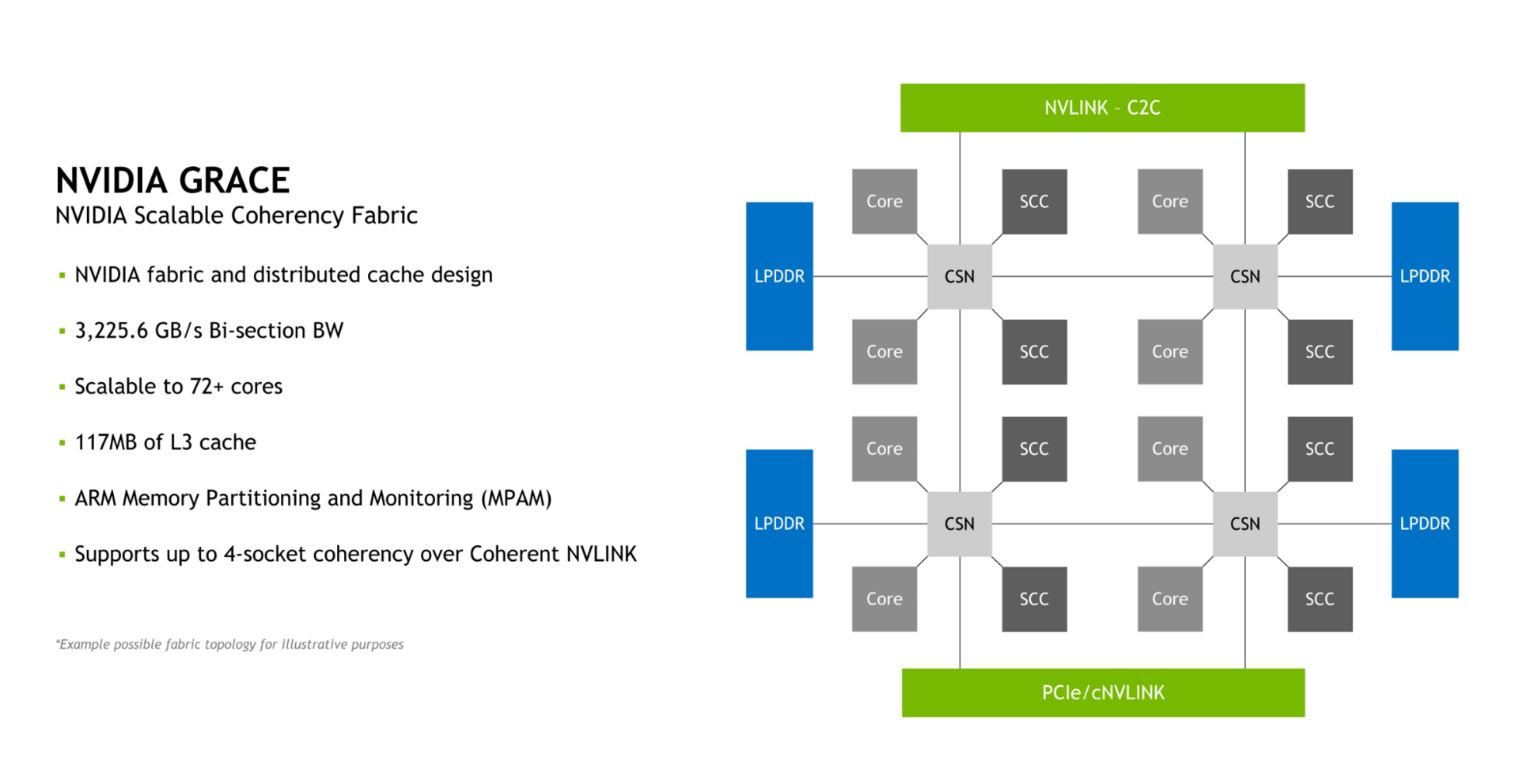
Zur Vorstellung des Grace Superchip im März dieses Jahres hatte Nvidia bereits von einer „industrieweit führenden Effizienz“ bei einer maximalen Leistungsaufnahme inklusive Arbeitsspeicher von „nur 500 Watt“ gesprochen. Zur Hot Chips 34 unterstreicht der Hersteller diesen Punkt erneut und betont das Design gezielt nicht mit der Brechstange ausgelegt zu haben.
LPDDR5X als effizienteste Wahl
Dabei geholfen haben soll unter anderem die Verwendung von LPDDR5X, dessen Vorzüge Nvidia genauer darlegt. Eine hohe Bandbreite gepaart mit mittelgroßem Speicherausbau bei jedoch relativ geringen Kosten und sehr geringem Energiebedarf gaben den Ausschlag für LPDDR5X.

Ein einzelner Grace-Chip soll so in der Lage sein, bis zu 536 GB/s Speicherbandbreite zu liefern, 98 Prozent des theoretischen Höchstwerts von 546 GB/s für LPDDR5X. Zwei Grace-Chips kombiniert schaffen dann über 1 TByte/s Speicherbandbreite. Wird eine Hopper-GPU an eine Grace-CPU angeschlossen, fällt die Bandbreite leicht auf 506 GB/s ab, was jedoch noch immer 92 Prozent des theoretischen Höchstwerts für eine einzelne Grace-CPU darstellt.
Die Besonderheit der Mischung von Grace mit Hopper ist unter anderem Unified Memory und Extended GPU Memory. Dadurch kann die Hopper-GPU selbst auf entfernten LPDDR5X der Grace-CPU zugreifen und für sich beanspruchen, was den nutzbaren Speicher der GPU fernab seines eigenen HBM deutlich erweitert.
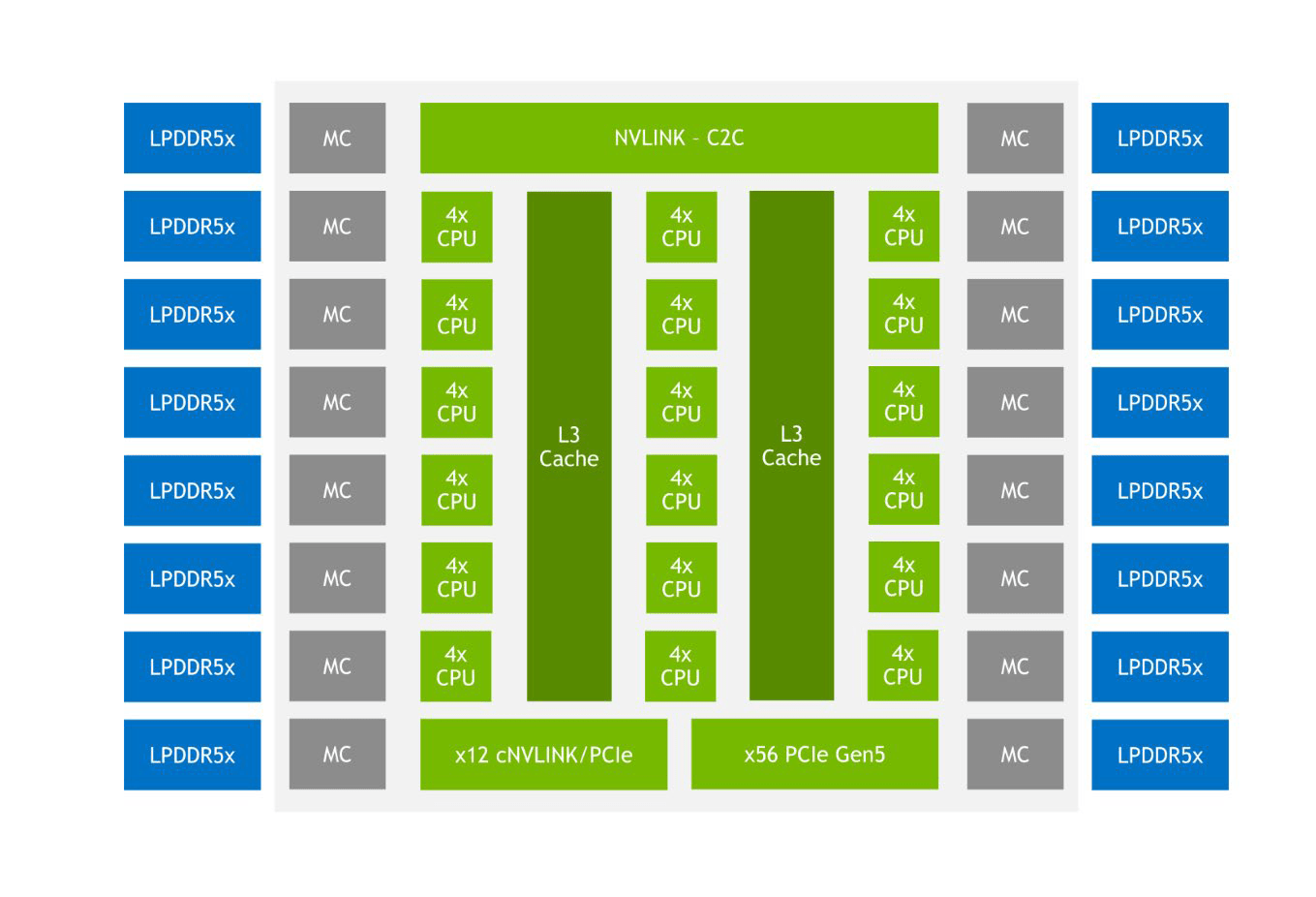
Nvidia spricht zwar am liebsten über die eigenen Entwicklungen, Grace wird aber auch klassische Schnittstellen bieten, um in modernen Rechenzentren volle Kompatibilität zu gewährleisten. Bis zu 68 PCIe-Lanes stehen dafür unter anderem zur Verfügung. Vier PCIe-5.0-Links mit 16 Lanes sind das wichtigste Element, jeder davon lässt sich zu zwei PCIe-5.0-Schnittstellen mit acht Lanes splitten.
Die Vorabinformationen dürften im Rahmen der dann vollständigen Präsentationen noch ergänzt werden – so bei Bedarf auch diese Meldung. Insgesamt gibt Nvidia zu Hot Chips 34 vier Vorträge:
- NVIDIA’s Hopper GPU: Scaling Performance
- NVLink-Network Switch - NVIDIA’s Switch Chip for High Communication-Bandwidth SuperPODs
- NVIDIA’s Orin System-on-Chip
- NVIDIA’s Grace CPU
ComputerBase hat die Informationen zu diesem Inhalt von Nvidia vorab unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt. Eine Einflussnahme des Herstellers auf die Meldung fand nicht statt, eine Verpflichtung zur Veröffentlichung bestand nicht.
- Meteor Lake: TSMC baut mehr Chips als Intel für Next-Gen-CPU
- Hot Chips 34: Intel spricht über die Leistung der HPC-GPU Ponte Vecchio
- Hot Chips 34: Nvidia nennt mehr Details zum Grace (Hopper) Superchip