Nvidia GeForce RTX 4000: Weitere Details zu Architektur, DLSS 3 und Founders Editions

Nvidia hat die GeForce RTX 4090 sowie die GeForce RTX 4080 angekündigt und damit die ersten drei Spieler-Grafikkarten auf Basis der neuen Architektur Ada Lovelace. Auf einem virtuellen Editors Day gab der Hersteller nun weitere Details zu Technik, DLSS 3 und Founders-Edition-Modellen bekannt.
Der eigentliche Aufbau bleibt unverändert
Nvidia hat einen etwas detaillierteren Überblick über die Gesamt-Architektur gegeben und veröffentlichte zum Beispiel ein Blockdiagramm der großen AD102-GPU. Darin zu sehen ist, dass sich beim generellen Aufbau gegenüber Ampere nicht viel geändert hat, primär gibt es einfach deutlich mehr Einheiten. Während Nvidia zum Beispiel bei Ampere den Streaming-Multiprocessor (SM) umgebaut hat, sodass jeder SM entweder 128 Floating-Point- oder 64 FP- und 64 Integer-Berechnungen pro Takt durchführen kann, hat sich bei Ada diesbezüglich nichts getan. Auch von einem großen L2-Cache, von dem die Gerüchteküche immer sprach, erwähnte Nvidia nichts. Allerdings ist bis jetzt noch gar nicht vom Cache geredet worden. Falls es diesbezüglich Veränderungen gegeben hat, sieht Nvidia sie aber wohl nicht als bedeutend genug an, darauf explizit einzugehen.
-
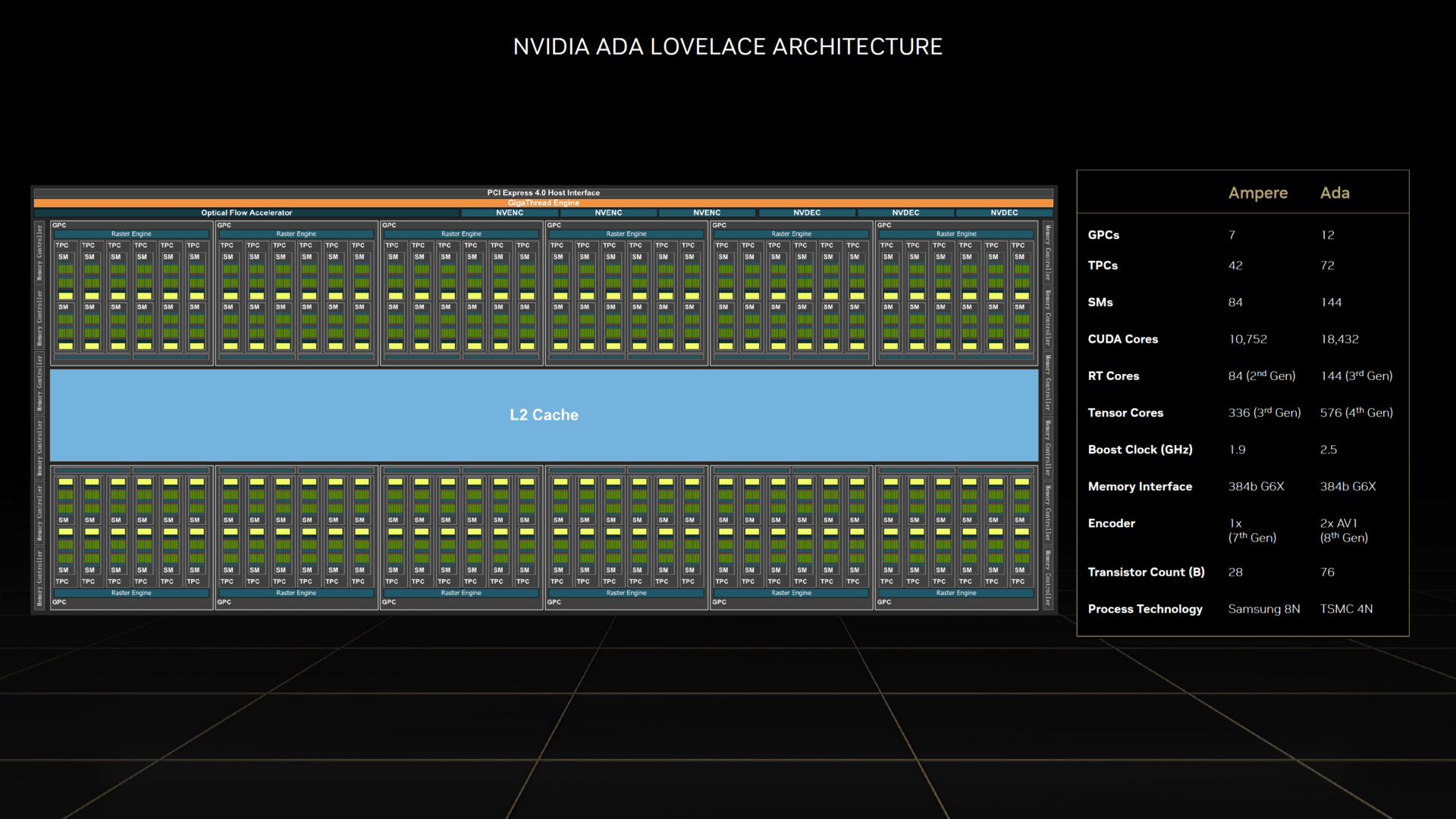 Nvidia AD102 – Blockdiagramm (Bild: Nvidia)
Nvidia AD102 – Blockdiagramm (Bild: Nvidia)




Sortierte Programme sollen deutlich mehr Leistung bei Ada bringen
Die wichtigste Änderung bei den FP32-Einheiten bei Ada Lovelace ist laut Jonah Alben, SVP GPU-Engineering bei Nvidia, das neue Feature „Shader Execution Reordering“ (SER). Das macht sich zu Nutze, dass alle modernen GPUs am effektivsten dann funktionieren, wenn auf den ALUs hintereinander dieselben Programme ausgeführt werden. Bei Rasterizer-Grafik ist das laut Alben von Natur aus oft der Fall, bei Raytracing soll dies aber anders sein. Dort werden Strahlen geschossen und je nachdem, auf welches Polygon der Strahl trifft, müssen nacheinander unterschiedliche Programme ausgeführt werden. Das lässt schnell eine „Bubble“ in der Rendering-Pipeline entstehen, sodass manche ALUs dann warten müssen, bis eine neue Rechenaufgabe angenommen werden kann.
SER soll bei Raytracing die ankommenden Rays scannen, die auszuführenden Programme aus diesen analysieren und dann so sortieren, dass möglichst immer dieselben Programme gleichzeitig ausgeführt werden, auch wenn sie eigentlich aus unterschiedlichen Rays stammen. Das soll die Auslastung der ALUs gegenüber dem Vorgänger Ampere erhöhen.
Alben nennt eine Performanceverbesserung bei Raytracing-Programmen durch SER von 44 Prozent in Cyberpunk 2077 mit dem noch nicht verfügbaren Overdrive-RT-Preset, 29 Prozent in Portal RTX und 20 Prozent in Racer RTX. Bei den Angaben handelt es sich um tatsächliche Leistungsverbesserungen in Form von FPS – intern können die Shader noch einmal deutlich mehr beschleunigt werden. Bei Rasterizer-Programmen spricht Nvidia von bis zu 25 Prozent mehr Leistung.
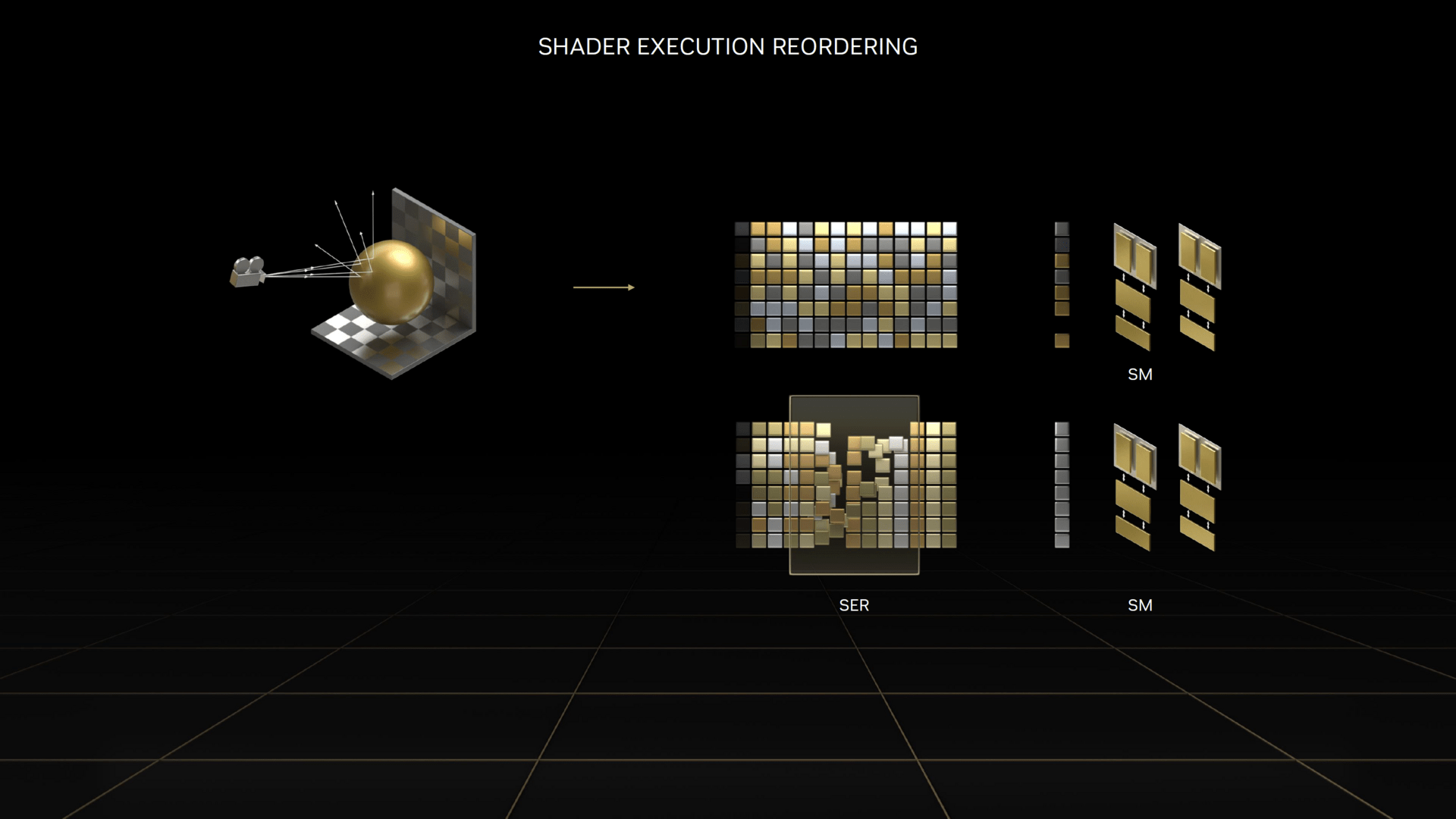
Die höchste Effizienz gibt es nur mit manueller Optimierung
Damit „Shader Execution Reordering“ optimal funktionieren kann, ist ein manueller Eingriff des Entwicklers notwendig. SER ist zwar automatisch auf GeForce RTX 4000 aktiv, kann vom Entwickler aber beeinflusst werden. Nvidia argumentiert dies damit, dass der Entwickler eben am besten weiß, wann welcher Workload anliegt und wie die einzelnen Programme idealerweise sortiert werden sollen. SER kann über eine spezielle API angesprochen werden.
Komprimierte BVH-Struktur für weniger CPU-Last
Auch wenn SER die größte Änderung an den ALUs ist, gibt es natürlich noch weitere Verbesserungen. So sind die Raytracing-Einheiten der dritten Generation nun dazu in der Lage, mit Hilfe so genannter „Displaced Micro-Meshes“ die Komplexität einer erstellten BVH-Struktur deutlich zu vereinfachen, um so unter anderem die CPU-Belastung deutlich zu reduzieren. Die bisherigen RT-Einheiten mussten die BVH-Struktur zum Beispiel mit jedem vorhandenen Polygon in dem ausgewählten Bereich füllen, was bei Ada Lovelace nicht mehr nötig ist. Dort reichen nun oft ein paar Basis-Polygone und der neue RT-Core weiß, wie sie zu evaluieren sind, und kann daraus dieselben Informationen fassen wie die alten RT-Kerne mit sämtlichen Micro-Polygonen. Je nach Komplexität der Szene kann die BVH-Struktur durch „Displaced Micro-Meshes“ 7,6- bis 15-mal schneller erstellt werden, was die CPU deutlich entlasten soll.
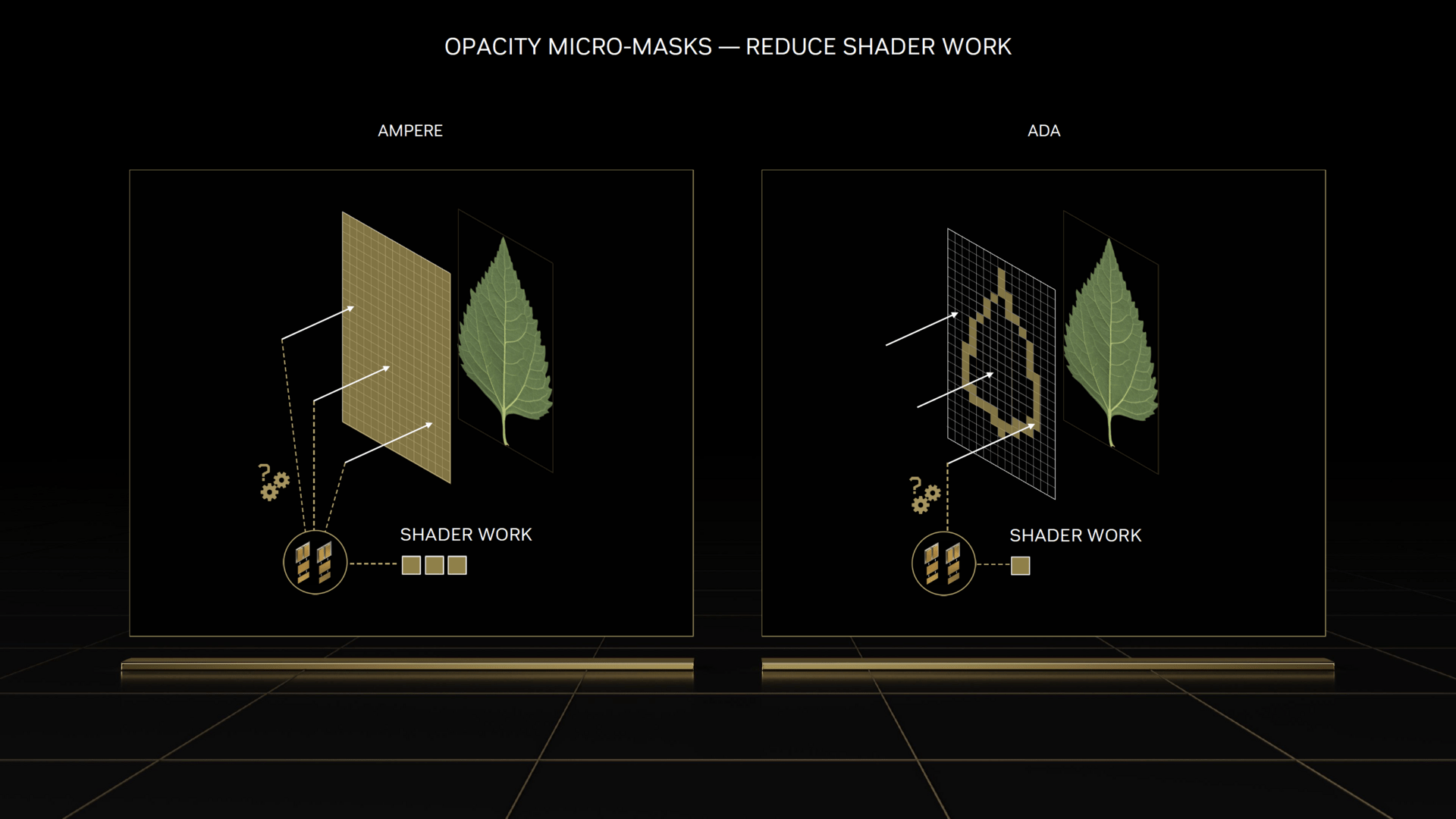
Damit dies funktioniert, muss ein Tool das Feature aber unterstützen – unter anderem Adobe und Simplygon werden damit arbeiten. „Displaced Micro-Meshes“ sind damit nicht in Spielen zu erwarten – zumindest deutet Nvidias Beschreibung darauf hin. Allgemein hilfreich ist jedoch, dass die RT-Kerne der dritten Generation im Vergleich zu den Pendants des Vorgängers den doppelten Datendurchsatz haben. Dasselbe gilt für die so genannten „Opacity Micro Maps“, die kurz gesagt dafür sorgen, dass die RT-Einheiten von transparenten Effekten verdeckte Objekte besser erkennen können, sodass dahinter liegende Polygone nicht berechnet werden müssen. Das ist etwas, das bei reiner Rasterizer-Grafik bereits lange funktioniert, bis zur dritten Generation der RT-Einheiten galt dies aber nicht bei Raytracing.
-
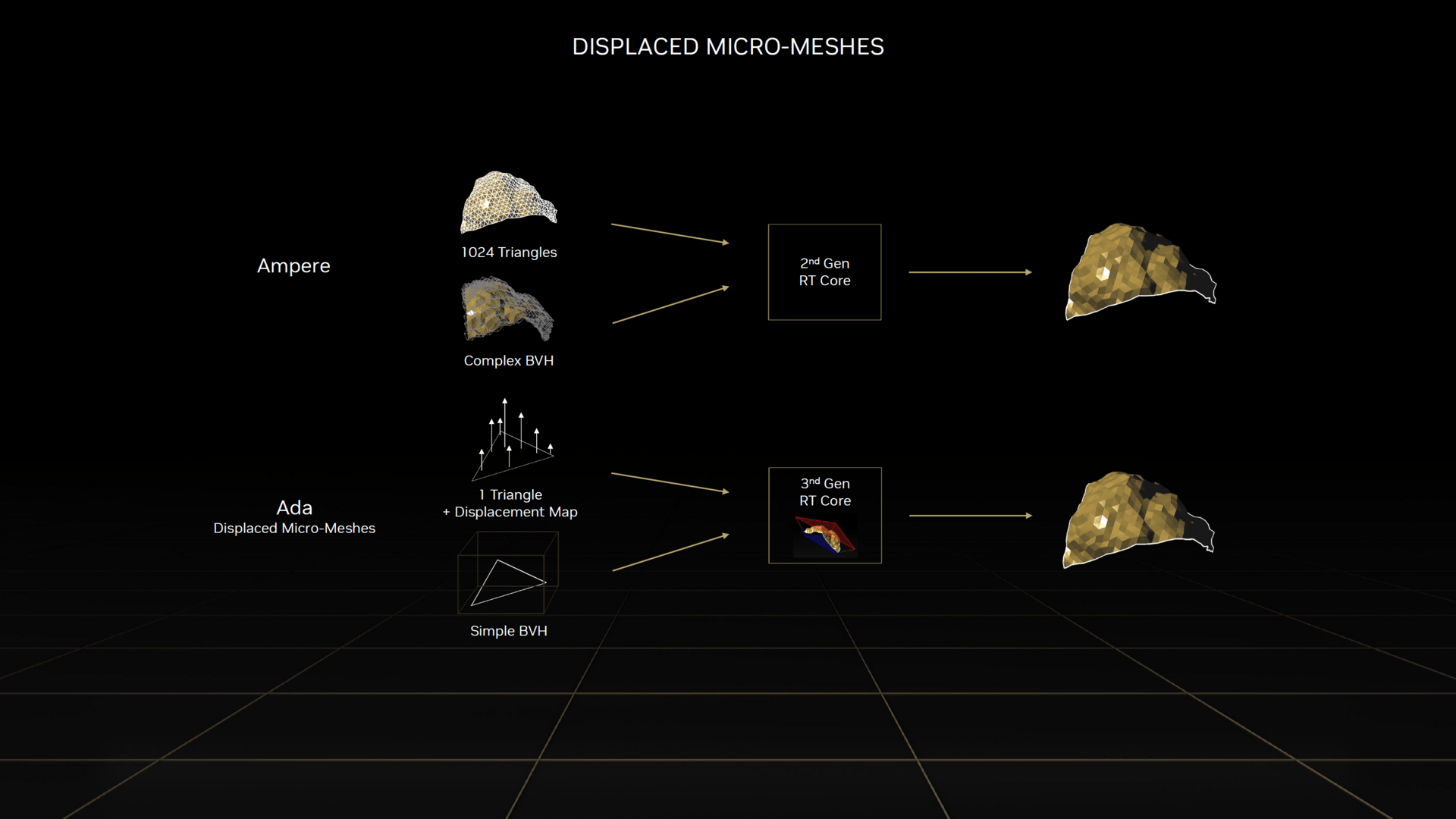 Neue RT-Features von Ada (Bild: Nvidia)
Neue RT-Features von Ada (Bild: Nvidia)

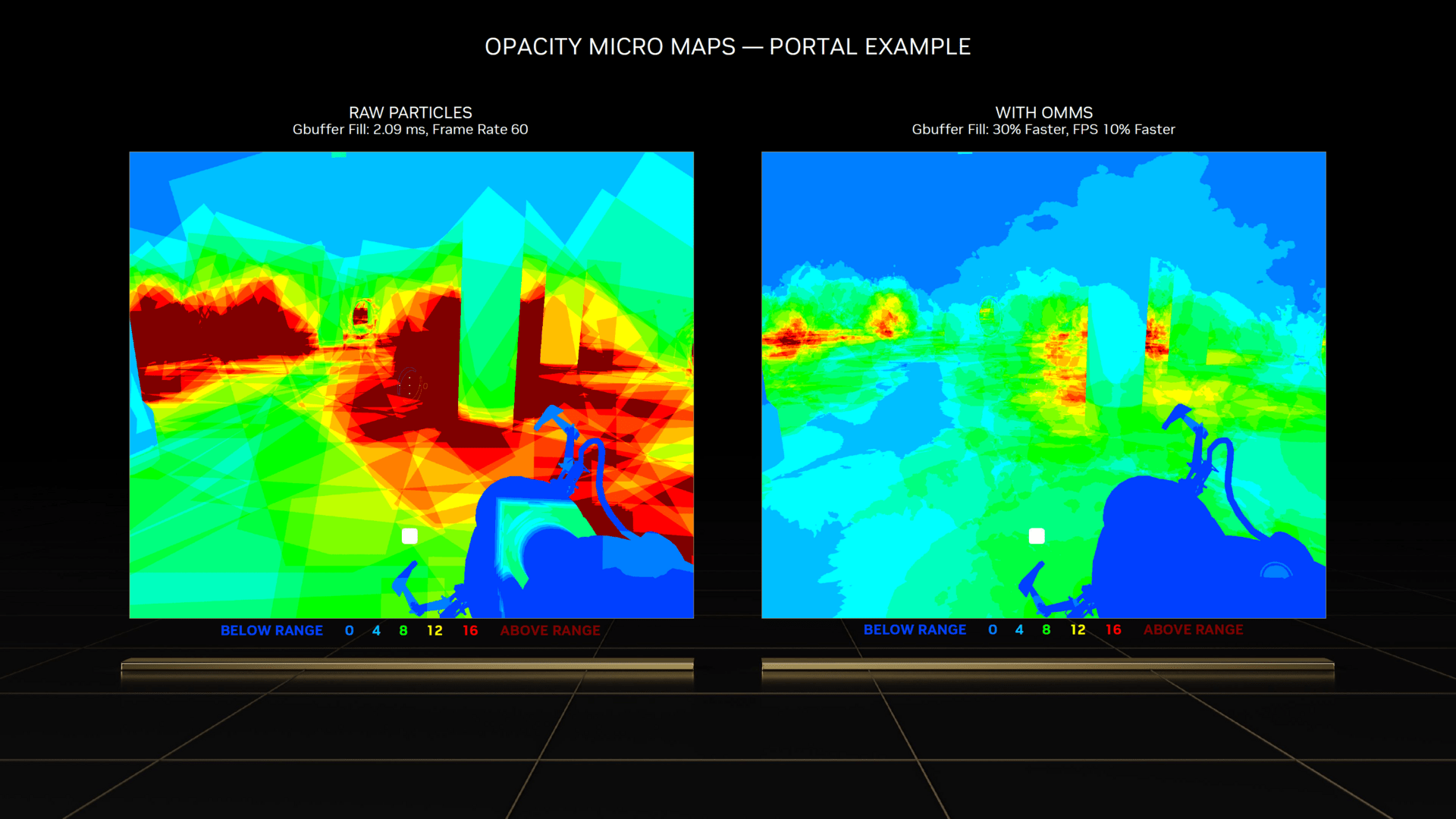
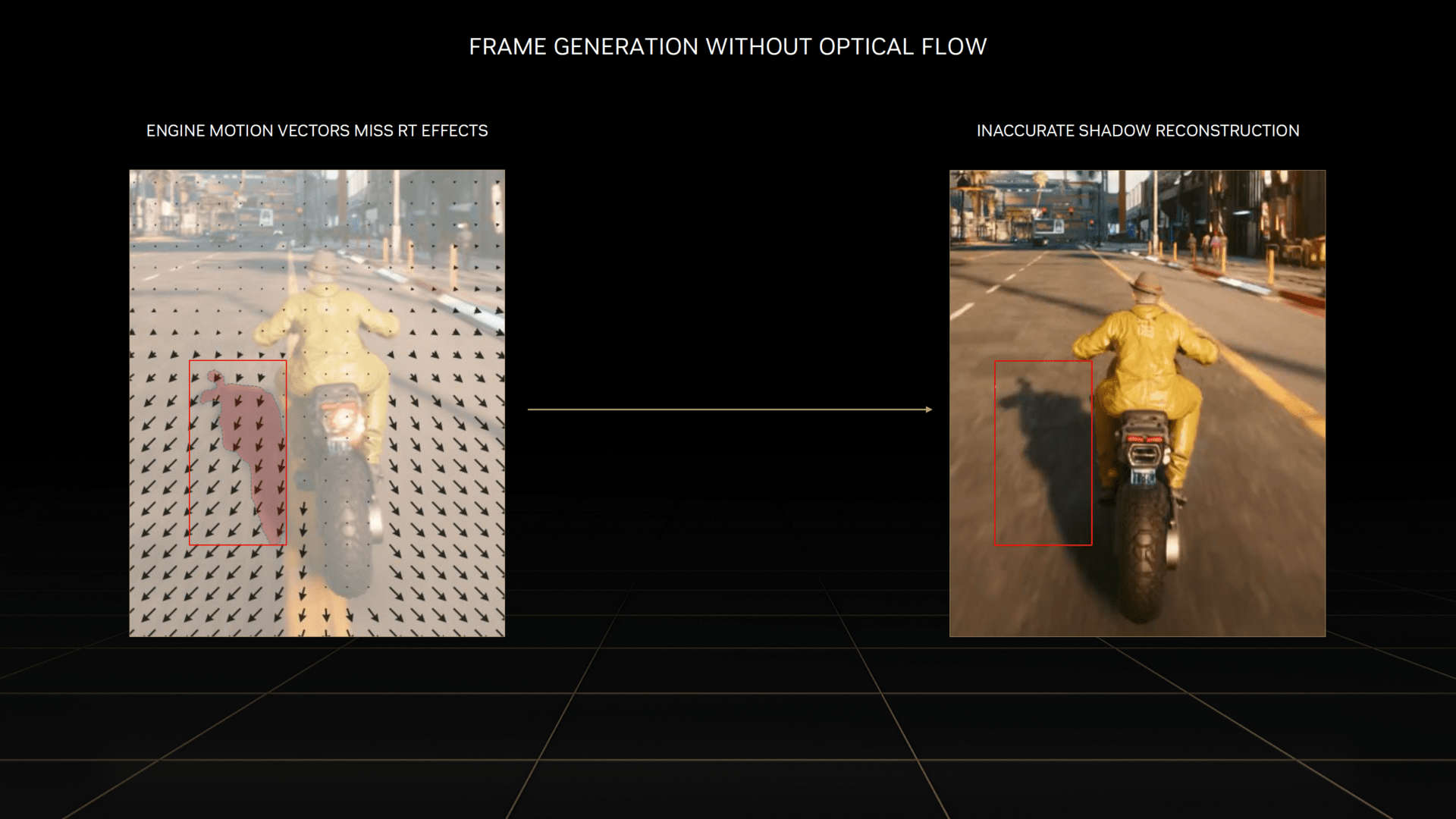
DLSS 3 mit neuen Einheiten und eine Frage zur Latenz
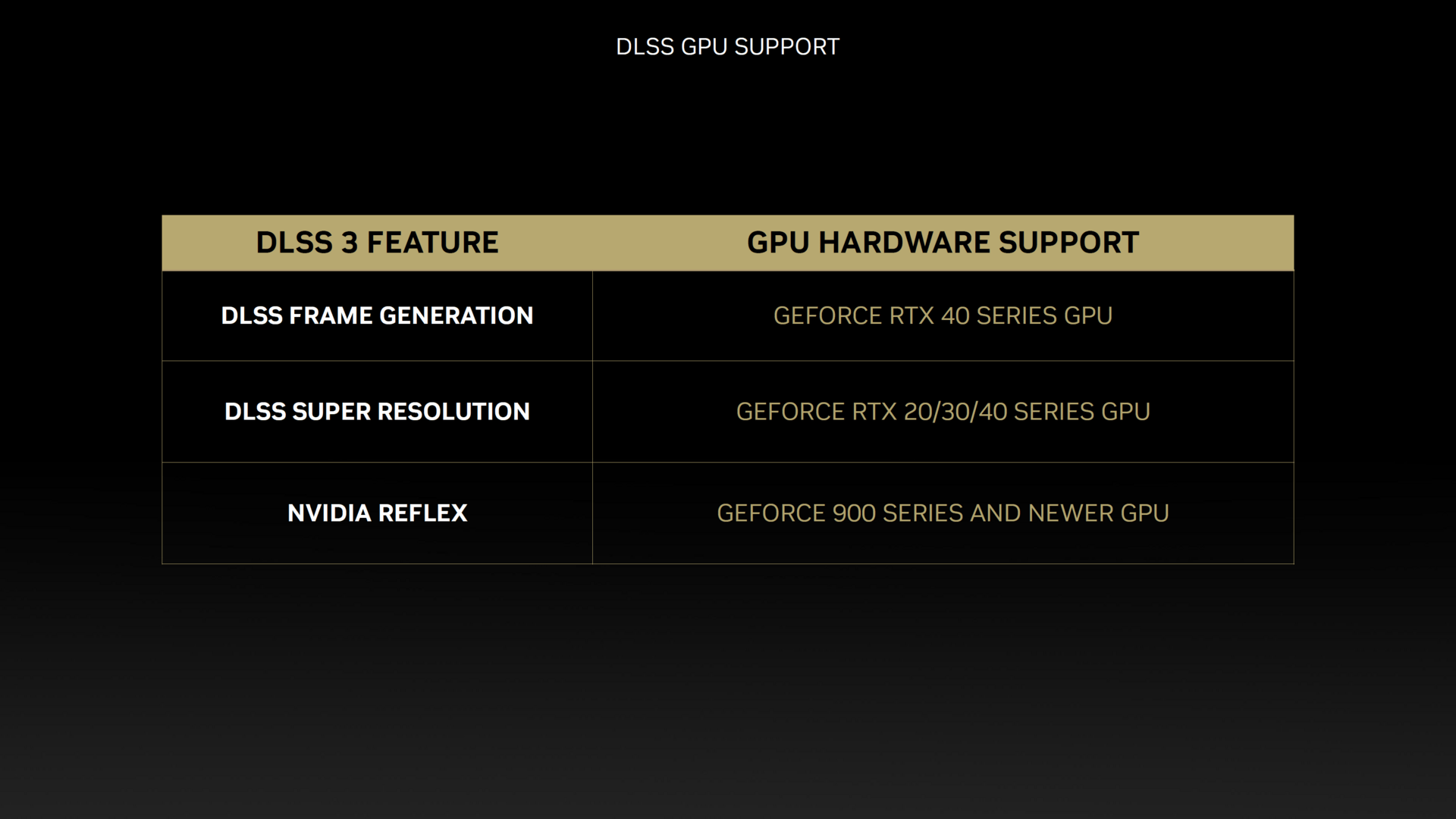
Neuigkeiten gibt es auch zu DLSS 3. Während DLSS 2, was Nvidia nun DLSS Super Resolution nennt, auf allen GeForce-RTX-Grafikkarten lauffähig ist, beschränkt sich DLSS 3 ausschließlich auf die GeForce-RTX-4000-Produkte. Den für das Feature wichtigen „Optical Flow Accelerator“ gibt es zwar auch schon bei älteren GeForce-RTX-Beschleunigern, für Ada Lovelace wurde dieser aber überarbeitet und ist nun um den Faktor 2 bis 2,5 schneller. Darüber hinaus wurde der Algorithmus verbessert, der die Genauigkeit verbessert – was für die korrekte Generierung der zusätzlichen Frames von DLSS 3 notwendig sein soll.
Nvidia hat sich auch zur Latenz mit DLSS 3 geäußert, denn das neue Upsampling ist nach eigenen Aussagen sehr rechenintensiv und die Erstellung zusätzlicher, nicht klassisch berechneter Frames kostet Latenz. Hinzu kommt, dass auch keine neuen Steuerungseingaben dafür benutzt werden können. Das ist zugleich der Grund, warum DLSS 3 automatisch Reflex integriert hat, damit die Latenz nicht spürbar abfällt.
Die Latenz wird eigentlich schlechter – Reflex behebt dies aber
So hat Nvidia eine Szene aus Cyberpunk 2077 mit einer GeForce RTX 4090 gezeigt, die mit DLSS 2 eine Framerate von 62 FPS mit einer Latenz von 58 ms aufweist. Mit DLSS 3 steigt die Framerate auf 101 FPS – entsprechend werden die zusätzlichen Bilder nicht klassisch berechnet, sondern von dem neuronalen Netzwerk per „Optical Multi Frame Generation“ erstellt. Die Latenz fällt zugleich auf einen Wert von 55 ms.
Daraus lassen sich mehrere Schlüsse ziehen. So nutzt DLSS 3 schlussendlich Reflex, um auf eine ähnliche Latenz wie DLSS 2 bei schlechterer Framerate zu gelangen. Durch das Feature wird die Latenz aber eben auch nicht schlechter, was man bei zusätzlich erstellten und nicht berechneten Bildern zunächst vermuten könnte – denn es gibt gerade keine neuen Steuerung-Inputs. Ohne Reflex würde die Latenz aber gegenüber DLSS 2 trotz höherer Framerate entsprechend schlechter ausfallen. Damit wird sich eine Leistungssteigerung durch DLSS 3 auch bei prozentual gleicher Verbesserung jedoch automatisch anders anfühlen als mit DLSS 2 (oder ohne Upsampling). Wie dies zu bewerten ist und ob dies überhaupt eine Rolle spielt, wird sich erst in einem Test klären lassen.
-
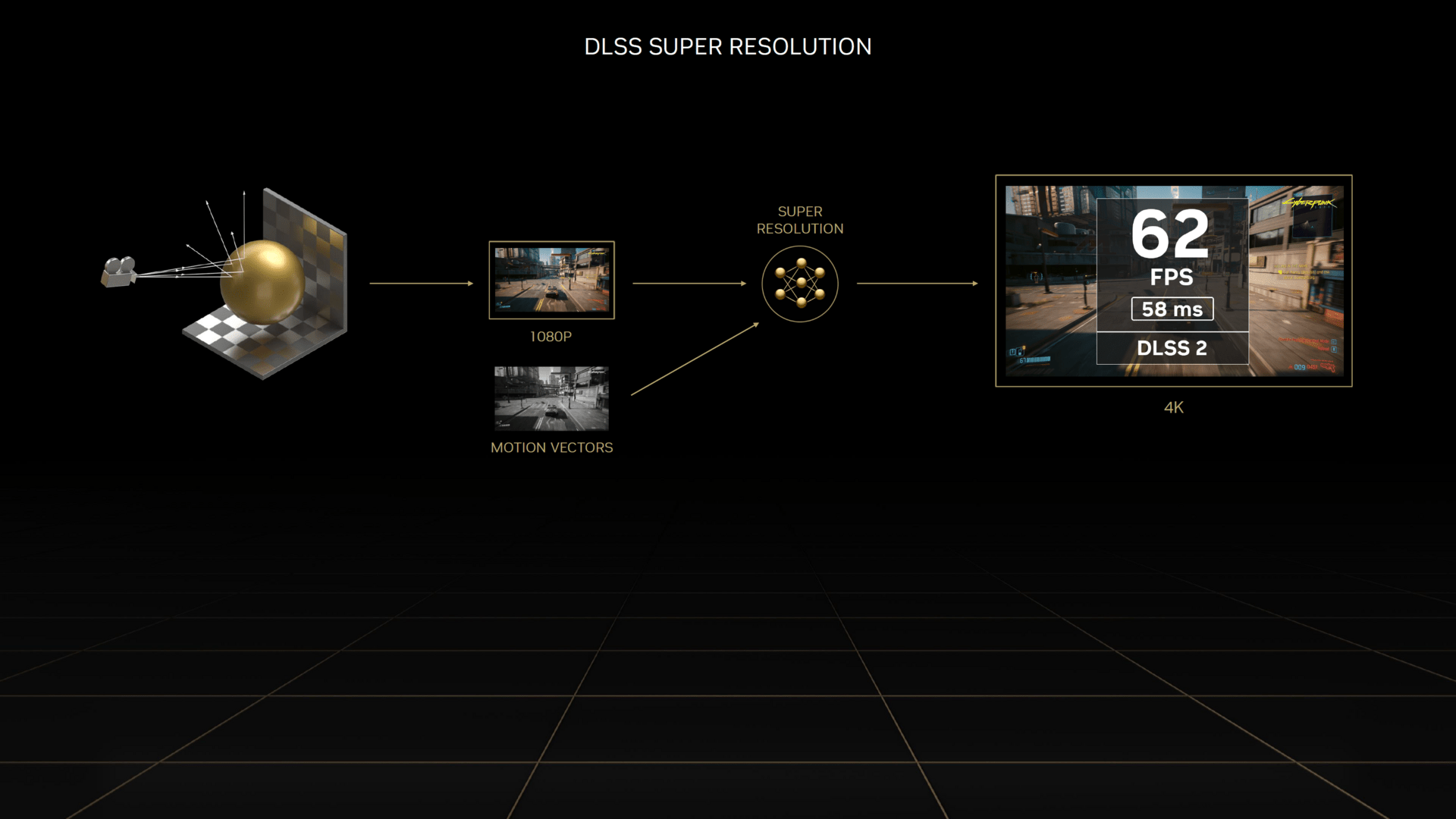 Nvidia DLSS 3 (Bild: Nvidia)
Nvidia DLSS 3 (Bild: Nvidia)
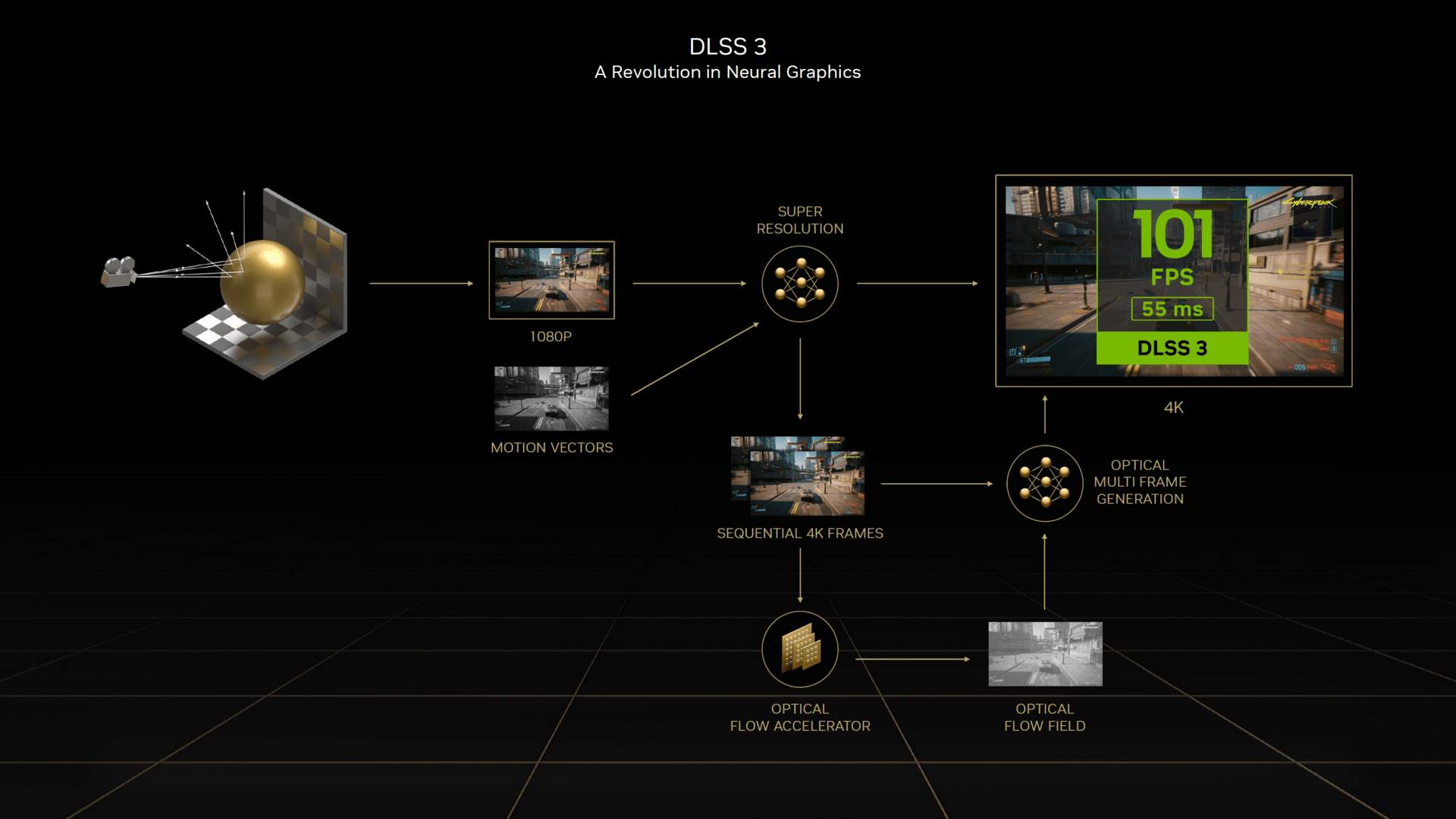


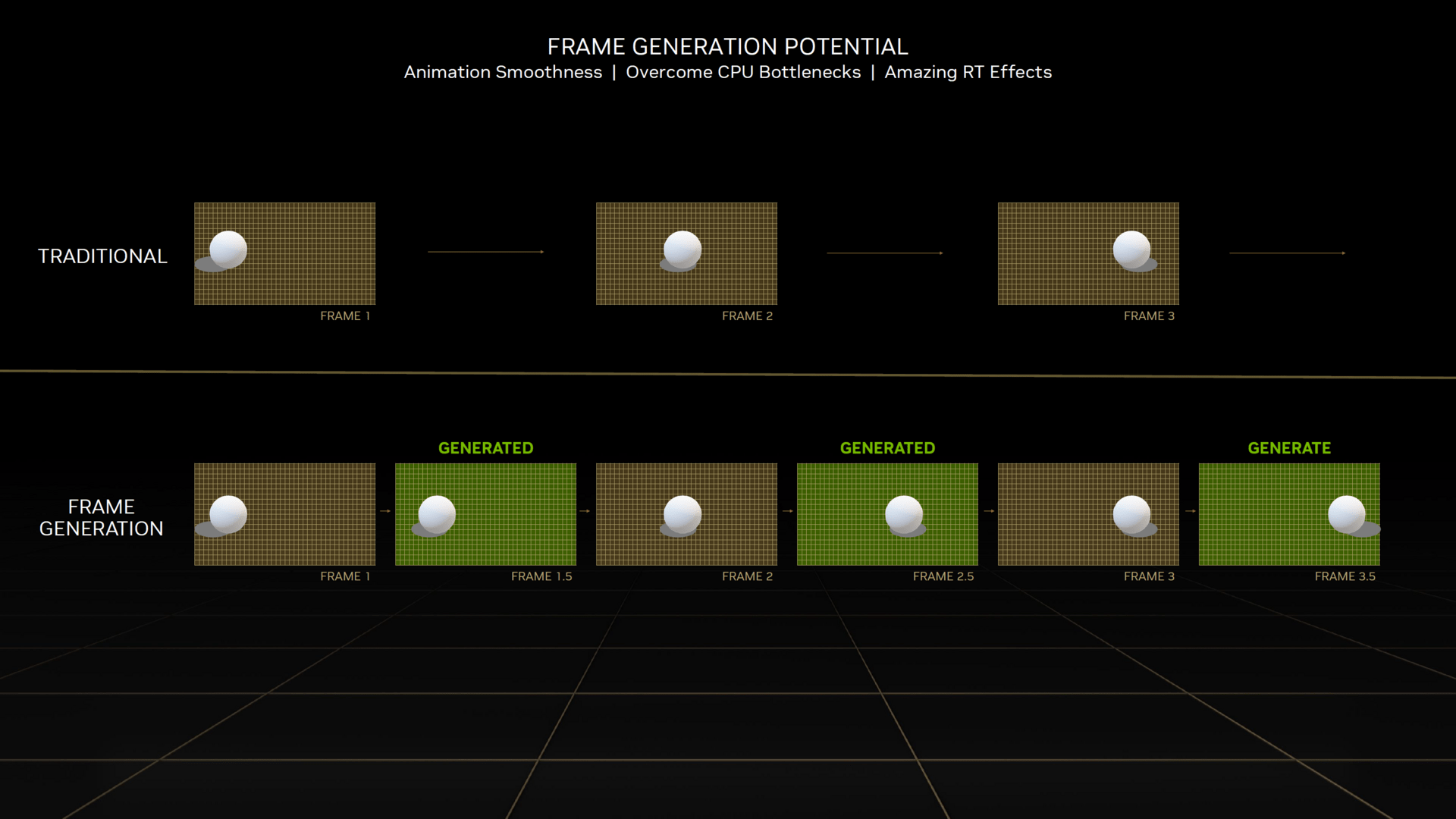
DLSS 3 wird einen Ein-/Ausschalter werden
Zwei weitere Dinge sind noch erwähnenswert. DLSS 3 wird dieselben Leistungs-Modi wie DLSS 2 bieten, allerdings hat dies nur einen Einfluss auf die Renderauflösung und damit den klassischen „DLSS-2-Teil“. DLSS 3 lässt sich dann über einen zusätzlichen Schalter namens „Frame Generation“ wahlweise aktivieren.
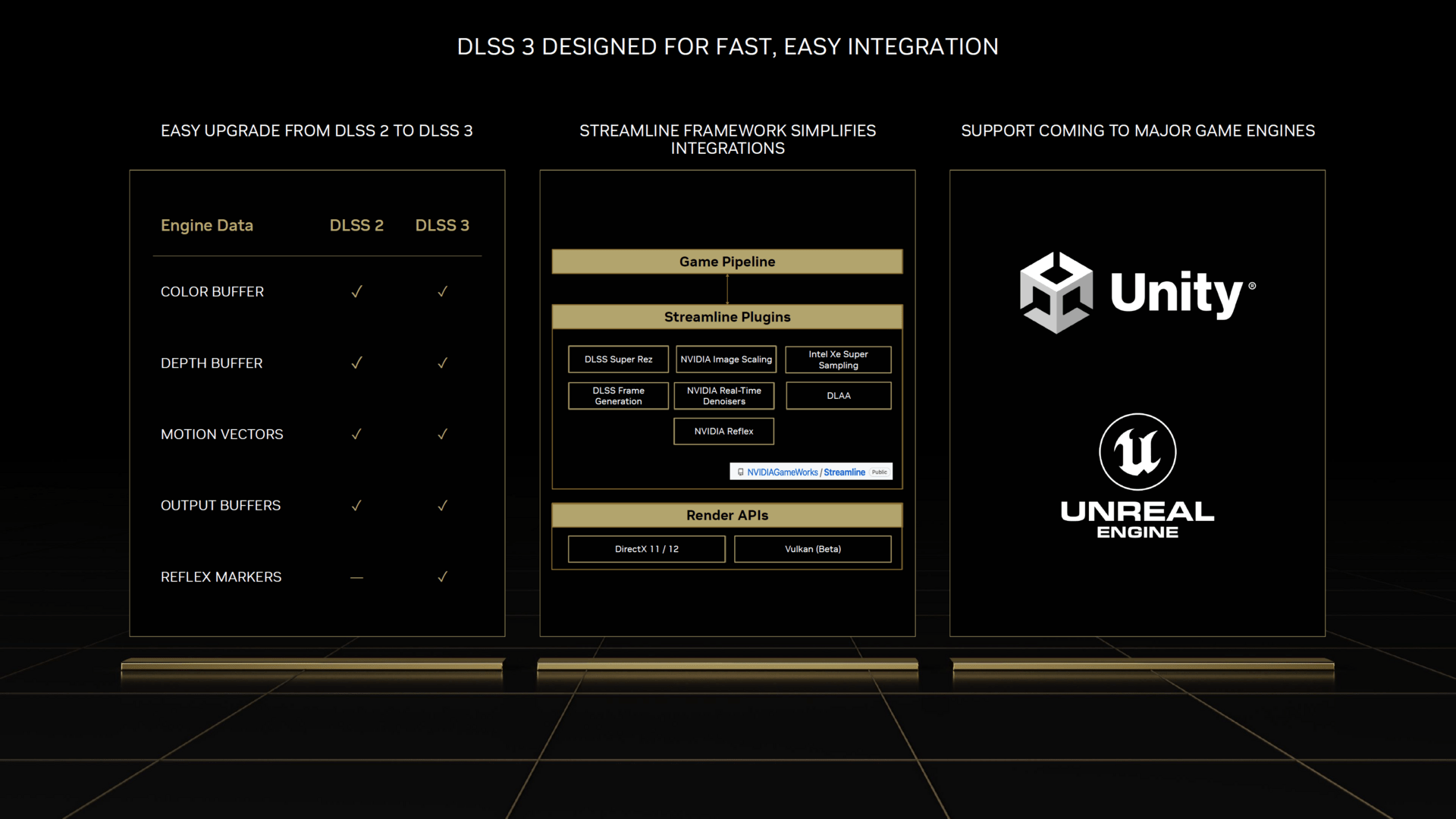
Laut Nvidia ist DLSS 3 einfach zu integrieren, wenn das Spiel bereits DLSS 2 unterstützt. In dem Fall sei kaum Mehrarbeit nötig, wobei natürlich die so genannten „Markers“ für Reflex eingebaut werden müssen. Wer die Unreal Engine 4, Unreal Engine 5 oder Unity-Engine nutzt, kann die DLSS-Integration der Engine nutzen, alternativ steht mit Streamline auch ein Open-Source-Framework zur Verfügung.
Leistungsmäßig soll DLSS 3 die Performance je nach Anforderung an die GPU verdoppeln bis gleich verfünffachen können. Bei aktuellen Rasterizer-Titeln soll die zweifache Framerate möglich sein, aktuelle RT-Titel sollen 2,5- bis 4-mal mehr FPS ermöglichen. Bei zukünftigen RT-Workloads soll DLSS 3 dann einen noch größeren Schub bringen, der zwischen dem Faktor 4 und 5,5 liegen soll.
-
 Nvidia DLSS 3 (Bild: Nvidia)
Nvidia DLSS 3 (Bild: Nvidia)


Neue Kühlung und bessere Stromversorgung für die Founders Edition
Nvidia hat auch mehr Details zur Founders Edition der GeForce RTX 4090 FE und GeForce RTX 4080 16 GB preisgegeben. Obwohl der Kühler optisch sehr ähnlich zu den FE-Modellen der GeForce-RTX-3000-Serie ausfällt, will Nvidia den Kühlkörper neu entwickelt haben. So soll es eine neue Vapor-Chamber und ein verändertes Heatpipe-Design geben. Dasselbe gilt für die Kühllamellen, die angepasst worden sind. Darüber hinaus wird ein größerer Lüfter verbaut, sodass der Luftfluss gegenüber dem RTX-3090-Kühler um 20 Prozent stärker ausfallen soll.
Mit dem neuen Kühler sollen die Temperaturen des GDDR6X-Speichers um 10 °C gefallen sein. Dies liegt an einem effizienteren Micron-Speicher an sich, aber auch daran, dass nun 16-Gbit-Speichermodule mit einer Kapazität von 2 GB genutzt werden, sodass alle Speichermodule auf die Vorderseite der Grafikkarte wandern. Darüber hinaus wurde der Luftfluss des Kühlers für den Speicher optimiert. Die GeForce RTX 4080 16 GB FE und die GeForce RTX 4090 nutzen den identischen Kühler – dies war bei der Ampere-Generation noch anders.
Neuer Stromstecker und deutlich schnellere Reaktionszeiten
Das PCB der GeForce RTX 4090 Founders Edition ist wieder äußerst klein gehalten, um dem Kühlkörper einen maximalen Platz zu geben. Die Stromversorgung wird über den neuen 16-Pin-PCIe-5.0-Anschluss (12VHPWR) sichergestellt, der Founders Edition wird aber auch ein 3×8-Pin-Adapter beiliegen. Wer Nvidias Flaggschiff übertakten möchte, kann das Powerlimit auf bis zu 600 Watt erhöhen – zumindest nach Spezifikation würde dies aber nur noch über den 16-Pin-Anschluss funktionieren.
Neu ist auch die Stromversorgung. Bei der GeForce RTX 4090 Founders Edition setzt Nvidia auf 20 Spannungswandlerkreise für die GPU und 3 weitere für den 24 GB großen GDDR6X-Speicher. Neu ist obendrein die Regulierung des Stromes, wenn die GPU auf Lastwechsel stößt. So soll Ada Lovelace nicht nur zehn Mal so schnell auf Änderungen bei den Stromanforderungen reagieren können, darüber hinaus soll dies auch deutlich gleichmäßiger geschehen. Während Ampere bei wechselnden Lastphasen immer mal wieder große Spikes hat und so für einen sehr kurzen Augenblick auch mal deutlich mehr Energie als im Schnitt aufnehmen kann, soll dies bei der GeForce RTX 4000 viel seltener der Fall sein. Trotz 100 Watt höherer durchschnittlicher Leistungsaufnahme bei der GeForce RTX 4090 im Vergleich zur GeForce RTX 3090 soll die bei einem Lastwechsel kurzzeitig anliegende maximale Leistungsaufnahme der neuen Grafikkarte geringer sein als beim Vorgänger.
Dual-Videoencoder bis hinauf zu 8K AV1
Interessantes gibt es noch über die Videoeinheiten bei Ada Lovelace zu berichten. So kann die neue Generation den AV1-Codec encodieren und darüber hinaus gibt es nicht nur einen Encoder auf der GPU, sondern gleich deren zwei. Unabhängig vom Codec können die zwei Einheiten dazu genutzt werden, um die Transcodierungs-Zeiten massiv zu reduzieren. Damit dies möglich ist, splitten die Encoder das Video in zwei Hälften auf, die obere Hälfte wird an den einen und die untere an den anderen Encoder geschickt. Diese verrichten dann ihre Arbeit und schicken die Bilder an den Treiber weiter, der sie dann wieder zusammensetzt.
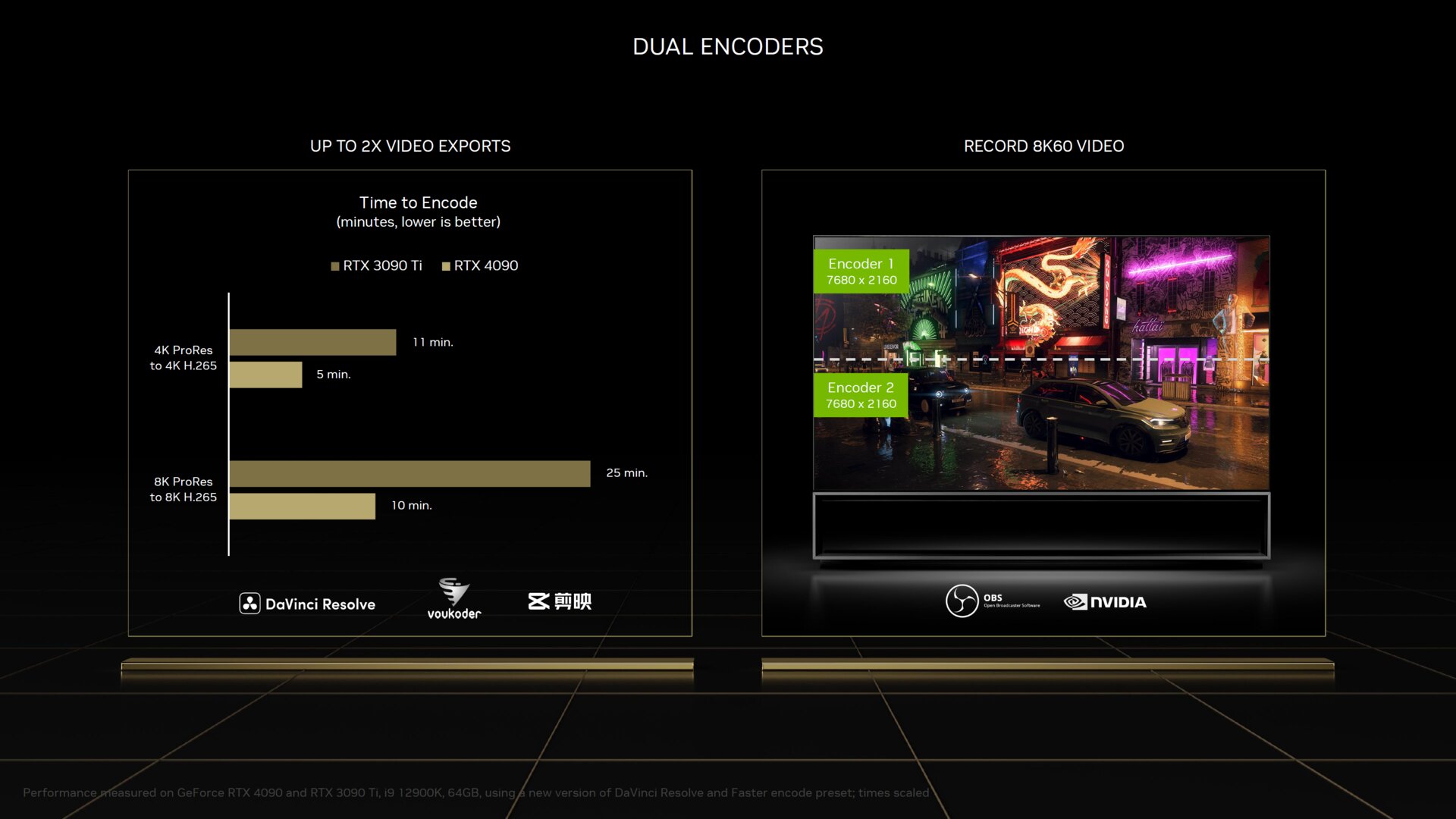
Gegenüber der GeForce RTX 3090 Ti soll die GeForce RTX 4090 Videos damit deutlich schneller encodieren können. Anstatt 11 Minuten beim Erstellen eines H.265-Videos in Ultra-HD-Auflösung soll die neue Grafikkarte nur 5 Minuten benötigen und damit mehr als doppelt so schnell arbeiten. Das Erstellen eines 8K-Videos im H.265-Codec soll gar in 10 statt 25 Minuten erledigt sein. Ob das Aufsplitten der Videos einfach so funktioniert oder ob dafür eine Softwareanpassung nötig sein wird, ist unklar.
Mit den zwei Encoder-Einheiten wird die 8K-Auflösung inklusive 60 FPS damit auch in GeForce Experience Einzug halten. In dem Fall wird das Video bei der Aufnahme ebenfalls in zwei Hälften gesplittet – ein Encoder nimmt die obere Hälfte, der andere Encoder die untere Hälfte auf.
Auch wenn Nvidia somit bereits kurz nach der Vorstellung viele Details zu den neuen RTX 4000 verraten hat, einige offene Fragen bleiben noch, die es in den kommenden Wochen zu beantworten gilt.
Die offiziellen, technischen Spezifikationen (Update)
Nvidia hat mittlerweile weitere Details zur Ada-Lovelace-Architektur bekannt gegeben. Darunter sind auch neue technische Spezifikationen, die unter anderem sowohl die Chip- sowie Cache-Größen zu den 3 GPUs AD102, AD103 sowie AD104 betreffen, die auf der GeForce RTX 4090, GeForce RTX 4080 16 GB sowie GeForce RTX 4080 12 GB eingesetzt werden. Die Informationen hat ComputerBase in folgende Tabelle eingefügt.
| RTX 4090 | RTX 4080 16 GB | RTX 4080 12 GB | RTX 3090 Ti | |
|---|---|---|---|---|
| Architektur | Ada | Ampere | ||
| GPU | AD102 | AD103 | AD104 | GA102 |
| Fertigung | TSMC N4 | Samsung 8 nm | ||
| Transistoren | 76,3 Mrd. | 45,9 Mrd. | 35,8 Mrd. | 28 Mrd. |
| Chipgröße | 609 mm² | 379 mm² | 295 mm² | 628 mm² |
| SM | 128 | 76 | 60 | 84 |
| FP32-ALUs | 16.384 | 9.728 | 7.680 | 10.752 |
| RT-Kerne | 128, 3rd Gen | 76, 3rd Gen | 60, 3rd Gen | 84, 2nd Gen |
| Tensor-Kerne | 512, 4th Gen | 304, 4th Gen | 240, 4th Gen | 336, 3rd Gen |
| Base-Takt | 2.230 MHz | 2.210 MHz | 2.310 MHz | 1.560 MHz |
| Boost-Takt | 2.520 MHz | 2.510 MHz | 2.610 MHz | 1.860 MHz |
| FP32-Rechenleistung | 82,6 TFLOPS | 48,8 TFLOPS | 40,1 TFLOPS | 40,0 TFLOPS |
| FP16-Rechenleistung | 82,6 TFLOPS | 48,8 TFLOPS | 40,1 TFLOPS | 40,0 TFLOPS |
| FP16 über Tensor | 330 TFLOPS | 195 TFLOPS | 164 TFLOPS | 156 TFLOPS |
| Textureinheiten | 512 | 304 | 240 | 336 |
| ROPs | 176 | 112 | 80 | 112 |
| L1 Cache | 16.384 KB | 9.728 KB | 7.680 KB | 10.752 KB |
| L2 Cache | 73.728 KB | 65.536 KB | 49.152 KB | 6.144 KB |
| Speicher | 24 GB GDDR6X | 16 GB GDDR6X | 12 GB GDDR6X | 24 GB GDDR6X |
| Speicherdurchsatz | 21 Gbps | 22,4 Gbps | 21 Gbps | |
| Speicherinterface | 384 Bit | 256 Bit | 192 Bit | 384 Bit |
| Speicherbandbreite | 1.008 GB/s | 717 GB/s | 504 GB/s | 1.008 GB/s |
| Slot-Anbindung | PCIe 4.0 | |||
| Video-Engine | 2 × NVENC (8th Gen) 1 × NVDEC (5th Gen) |
1 × NVENC (7th Gen) 1 × NVDEC (5th Gen) |
||
| TDP | 450 Watt | 320 Watt | 285 Watt | 450 Watt |
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.