Neoverse V2: Arm-Plattform soll Genoa und Sapphire Rapids schlagen
Arm hat mit der Neoverse V2 eine neue Plattform für Server als Nachfolger der Neoverse V1 angekündigt. Konkurrierende x86-Designs von AMD und Intel will der IP-Entwickler damit bei Leistung pro Thread und Leistung pro Sockel hinter sich lassen. Erster Abnehmer von Neoverse V2 ist Nvidia mit der Grace-CPU und bis zu 144 Kernen.
Die Server-Sparte von Arm hat mit der V-, N- und E-Serie drei Standbeine für maximale Leistung, effiziente Leistung und effizienten Durchsatz, wie das Unternehmen selbst beschreibt. Während die N-Serie mit der N2-Plattform bereits in zweiter Generation vorlag, folgen jetzt die V2 und E2 in den anderen Klassen. Fokus der aktuellen Präsentation lag auf Neoverse V2 im HPC-Segment, wo Arm mit dem Vorgänger Neoverse V1 etwa beim AWS Graviton3 oder modifiziert beim Ampere Altra Abnehmer hat. Arm kommt allerdings auch beim Fujitsu A64FX oder Alibaba Yitian 710 zum Einsatz.
-
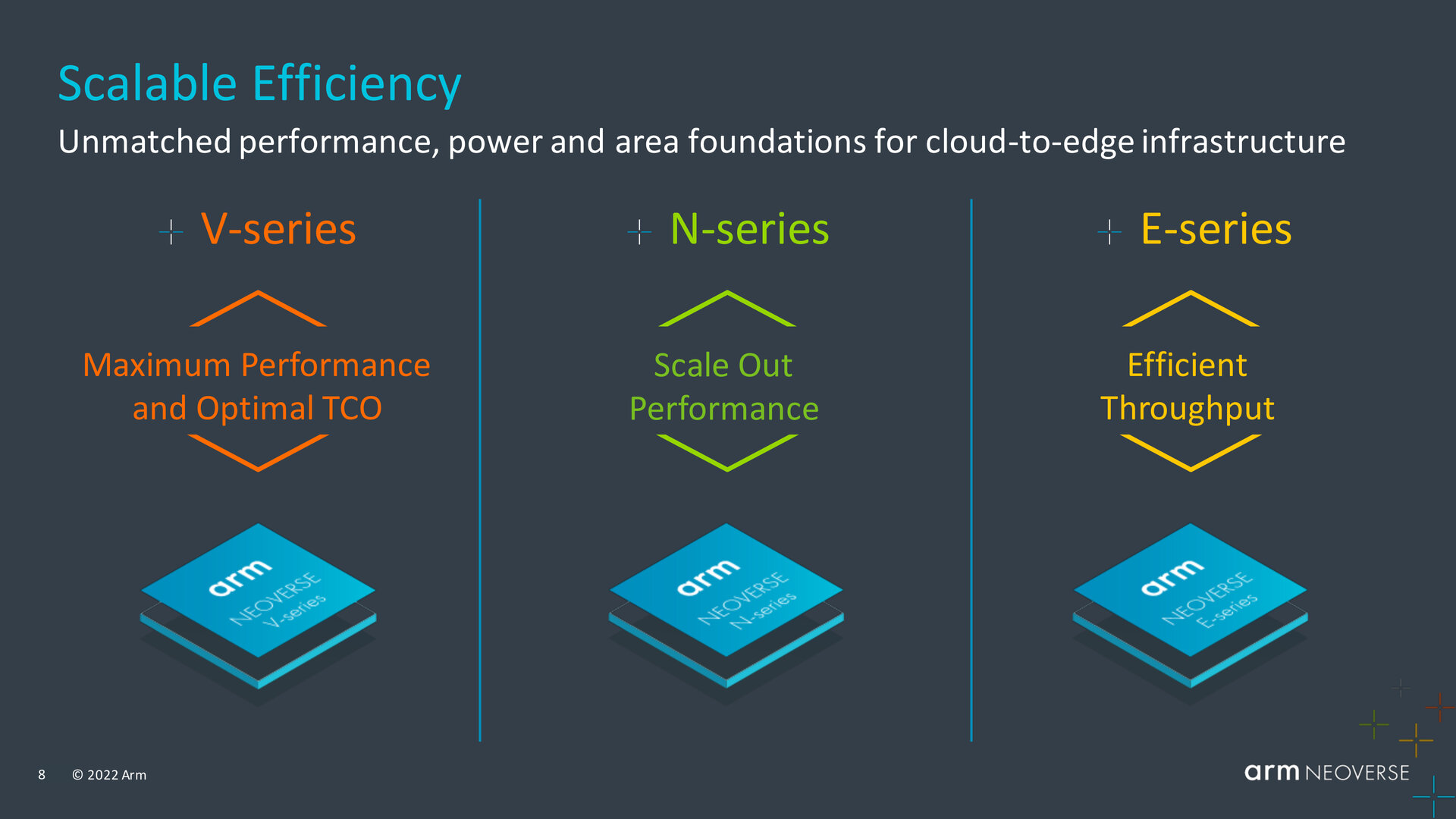 Die drei Server-Plattformen von Arm (Bild: Arm)
Die drei Server-Plattformen von Arm (Bild: Arm)

Genoa und Sapphire Rapids im Visier
Die Neoverse-V2-Plattform mit dem Codenamen „Demeter“ soll es kommendes Jahr mit AMD Genoa und Intel Sapphire Rapids aufnehmen und beide Kontrahenten schlagen. Anhand prognostizierter Werte für Genoa mit 96 Kernen/192 Threads und Sapphire Rapids mit 56 Kernen/112 Threads sieht Arm den Grace CPU Superchip von Nvidia bei der Integer-Leistung pro Thread und Sockel weit vor der Konkurrenz. Die Neoverse-V2-Plattform als solche bezeichnet Arm als marktführend bei der Leistung pro Thread für 2023. Mit der eigenen N-Serie will das Unternehmen die Führung bei der Leistung pro Watt behalten und mit beiden Plattformen eine höhere Effizienz als die Mitbewerber erzielen.

Grace CPU Superchip kommt 2023
Grace hatte Nvidia zur GTC im April 2021 als erste eigene Arm-CPU vorgestellt, sich damals aber noch mit Details zurückgehalten. Ein Jahr später wurde dann allerdings zur GTC 2022 offiziell bekannt, dass mit dem Grace Hopper Superchip und dem Grace CPU Superchip zunächst zwei Lösungen für das erste Halbjahr 2023 geplant sind. Letztere Ausführung ohne Hopper-GPU kommt mit zwei CPUs auf 144 Kerne, unterstützt LPDDR5X, soll eine Speicherbandbreite von 1 TB/s für beide CPUs erreichen und gegenüber der etablierten x86-Konkurrenz die doppelte Leistung pro Watt bieten.
Neoverse V2 wechselt zu Armv9
Für Neoverse V2 wechselt das Unternehmen von der Armv8.4-Architektur zu Armv9 und alle damit einhergehenden Neuerungen. Im Vergleich zu Neoverse V1 kann der L2-Cache mit 2 MB bis zu doppelt so groß ausfallen, eine Konfiguration 1 MB wird aber weiterhin angeboten. Die SVE2-Befehlssatzerweiterung stellt Arm von zwei 256-Bit-Pipelines auf auf vier mit 128 Bit um, sodass sich kumulativ zwar nichts am SVE2-Support ändert, aber nur noch kleinere Vektoren und mit 128 Bit das Minimum von SVE2 parallel verarbeitet werden können. Wie Anandtech anmerkt, ist die gezeigte Unterstützung von BF16 und INT8 MATMUL eigentlich nicht neu, Arm nennt dort allerdings Verbesserungen an der Mikroarchitektur. Bis alle Details zu Neoverse V2 bekanntgegeben werden, dürfte Arm noch auf den Marktstart erster Lösungen im kommenden Jahr warten.
-
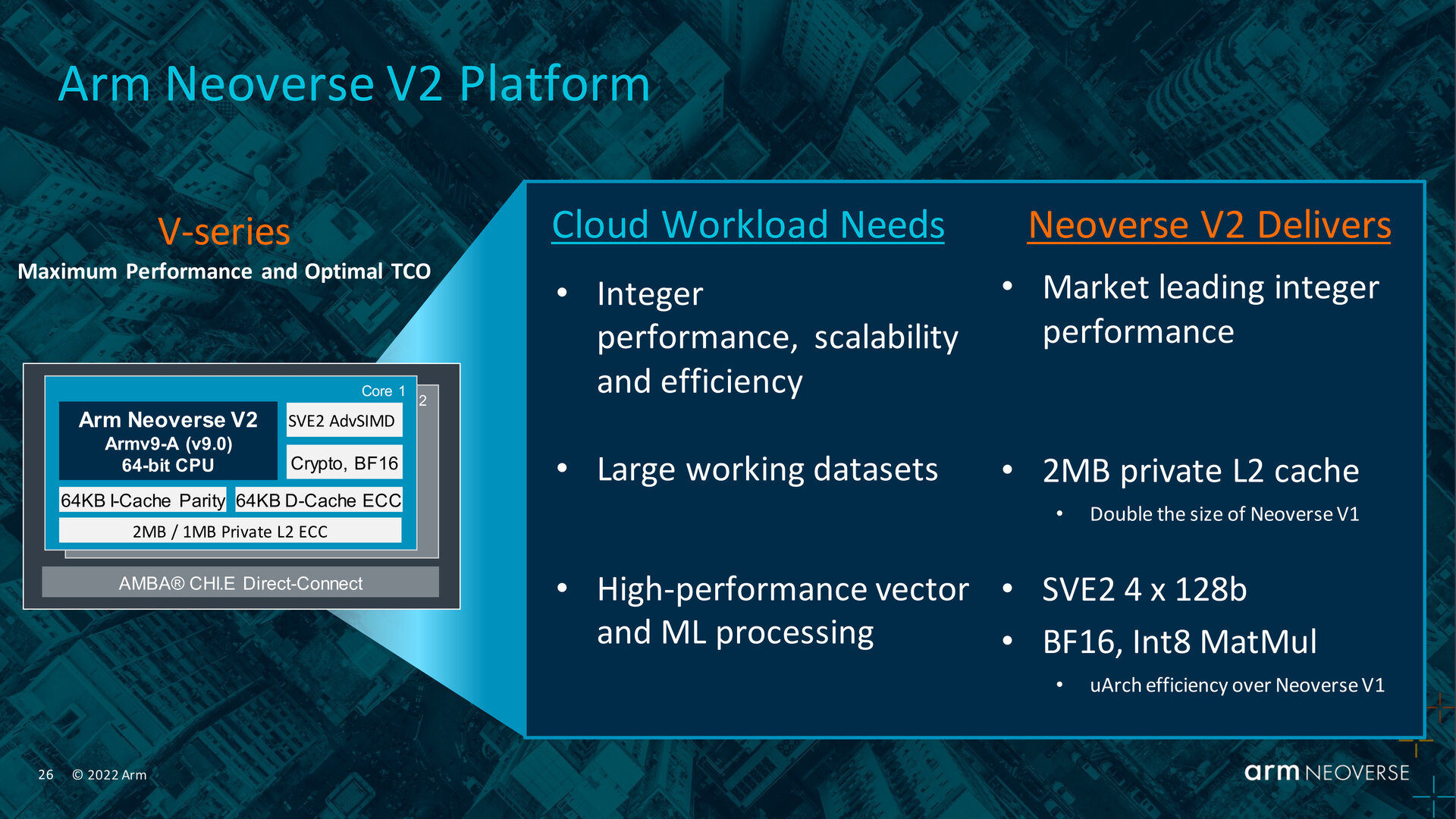 Neoverse V2 im Überblick (Bild: Arm)
Neoverse V2 im Überblick (Bild: Arm)

Als Fabric wird der mit Neoverse V1 eingeführte CMN-700 (Coherent Mesh Network) fortgeführt und kann mit bis zu 512 MB SLC kombiniert werden. Über das Mesh wird mit einer Bandbreite von bis zu 4 TB/s kommuniziert. Speicherinterfaces liegen für DDR5 und LPDDR5 vor, wobei dies auch LPDDR5X umfassen müsste, wie es Nvidia bei Grace nutzt. Mehrere Chiplets lassen sich mit dem eigenen Arm AMBA CHI (Coherent Hub Interface) verbinden, Unterstützung gibt es aber auch für UCIe. Mittels CXL 2.0 auf Basis von PCI Gen5 können Beschleuniger und weitere I/O-Geräte eingebunden werden.
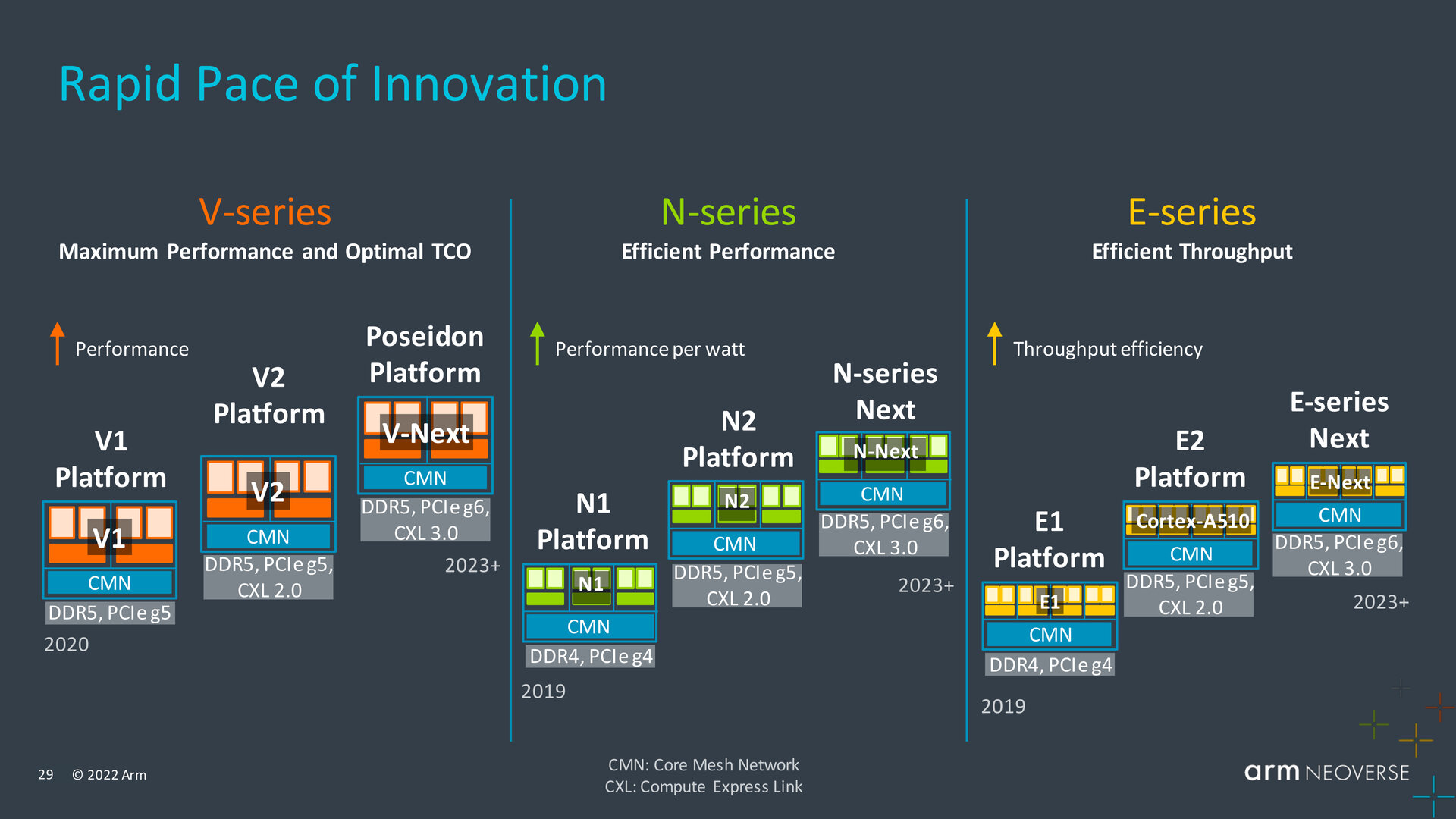
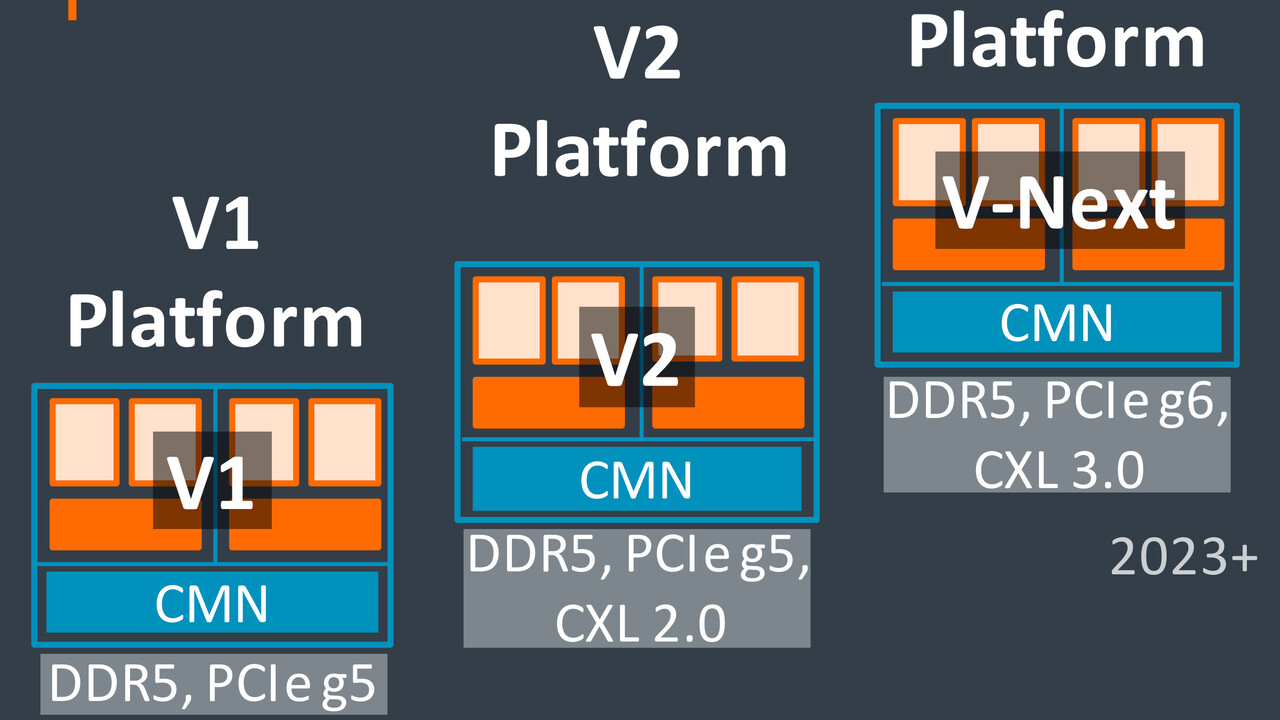
Roadmap für Neoverse V3, N3 und E3
Über das kommende Jahr hinaus soll einer von Arm präsentierten Roadmap zufolge „Poseidon“ alias V-Next als Server-Plattform mit Unterstützung für PCIe Gen6 und CXL 3.0 folgen. Für die N-Serie ist nach 2023 ebenfalls eine Entwicklung in diese Richtung geplant. Selbiges gilt für die E-Serie, der Arm parallel zur Neoverse V2 jetzt die E2 folgen lässt, deren Cores auf dem Cortex-A510 für besonders effiziente Lösungen basieren.