Radeon RX 7900 XTX & XT im Test: AMD RDNA 3 gegen Nvidia GeForce RTX 4000 „Ada Lovelace“

Kurz vor Weihnachten betreten nun auch AMDs neue Grafikkarten auf Basis von RDNA 3 den Markt. ComputerBase hat das neue Flaggschiff-Modell Radeon RX 7900 XTX und die Radeon RX 7900 XT im Test, die sich unter anderem gegen Nvidias GeForce RTX 4080 stellen und dabei mit Preisen von 1.149 Euro bzw. 1.050 Euro punkten wollen.
AMD Radeon RX 7900 XTX und Radeon RX 7900 XT sind ab sofort offiziell ab 1.149 Euro respektive 1.049 Euro im Handel verfügbar. Angeboten werden die Refenzdesigns von AMD sowie verschiedene Customdesigns der Partner, die – anders als bei Nvidia – ebenfalls das Referenzdesign in eigener Kartonage und unter eigenen Garantie- und Service-Bedingungen verkaufen.
Erste Custom-Designs in der Redaktion
ComputerBase liegen zur Stunde bereits die Custom-Designs Asus Radeon RX 7900 XTX TUF Gaming OC, PowerColor Radeon RX 7900 XTX Hellhound und XFX Radeon RX 7900 XTX Merc 310 vor. Im Zulauf, aber noch nicht eingetroffen, ist die Sapphire Radeon RX 7900 XTX Nitro+.
-
 Radeon RX 7900 XTX: PowerColor Hellhound, XFX Merc 310, Asus TUF Gaming und Referenzdesign (v.l.n.r.)
Radeon RX 7900 XTX: PowerColor Hellhound, XFX Merc 310, Asus TUF Gaming und Referenzdesign (v.l.n.r.)

Ein Test wird in Kürze erscheinen. Je nachdem, wie weit es die Nitro+ dann bereits aus China nach Deutschland geschafft hat, mit oder noch ohne dieses Modell.






RX 7900 XTX und RX 7900 XT zum Weihnachtsfest
AMDs Next-Gen-Grafikkarten werden es wie angekündigt noch vor Weihnachten in die Händlerregale schaffen. Ab heute dürfen das neue Flaggschiff-Modell Radeon RX 7900 XTX und die kleinere Radeon RX 7900 XT getestet werden, ab dem 13. Dezember stehen dann sowohl das Referenzdesign als auch erste (womöglich nur wenige) Custom-Designs im Handel.
Und damit hat Nvidias Ada-Lovelace-Generation nun auch eine Konkurrenz. Wohl nicht die GeForce RTX 4090 (Test), die in vielerlei Hinsicht bei weitem unerreicht für AMDs neue Radeon-RX-7000-Serie bleiben wird. Die Navi-31-GPU duelliert sich stattdessen mit der GeForce RTX 4080 (Test), die AMD nach eigenen Angaben in der Spiele-Raster-Performance schlagen will.
AMD will mit einem geringeren Preis punkten
Abgesehen davon will AMD auch in Sachen Kosten punkten, denn diesbezüglich hat Nvidia mit den bisherigen GeForce-RTX-4000-Karten ein riesengroßes Scheunentor offen gelassen. Die GeForce RTX 4080 ist schließlich mit einem UVP von 1.399 Euro zweifellos sehr teuer. Auch die RDNA-3-Ableger werden kein Schnäppchen, sind aber günstiger. 1.149 Euro will AMD für die Radeon RX 7900 XTX mit 24 GB Speicher haben, die Radeon RX 7900 XT mit 20 GB wird ab 1.050 Euro starten. Die Preise gelten für Referenzmodelle, die meisten Custom-Designs werden entsprechend mehr kosten.
RX 7900 XTX & RX 7900 XT vs. RTX 4080 – Custom-Tests folgen sehr bald
Auf den folgenden Seiten wird ComputerBase nun das Gesamtpaket der Radeon RX 7900 XTX sowie Radeon RX 7900 XT testen und die wichtigsten Fragen klären. Zum Beispiel, ob sich Raytracing und damit die Schwachstelle von RDNA 2 gebessert hat. Und wie es um die Energieeffizienz der neuen Grafikkarten gestellt ist. Abseits vom normalen Testparcours wirft die Redaktion zudem einen Blick auf die neuesten Spiele wie zum Beispiel A Plague Tale: Requiem, The Callisto Protocol und Spider-Man: Miles Morales. Die Themen Overclocking und Undervolting werden ebenso eine Rolle spielen. Ob die Radeon RX 7900 XTX es schlussendlich schaffen wird, die Nvidia GeForce RTX 4080 zu schlagen, wird der Test zeigen.
Der Artikel wird dabei ausschließlich AMDs Referenzdesign behandeln, das es abseits von AMD selbst auch von den Boardpartnern geben wird. Tests von den richtigen Custom-Designs sind derzeit noch nicht erlaubt, werden aber in Kürze folgen – die ersten Testreihen sind bereits abgeschlossen.
Ein paar Worte zur Technik rund um Navi 31 und RDNA 3
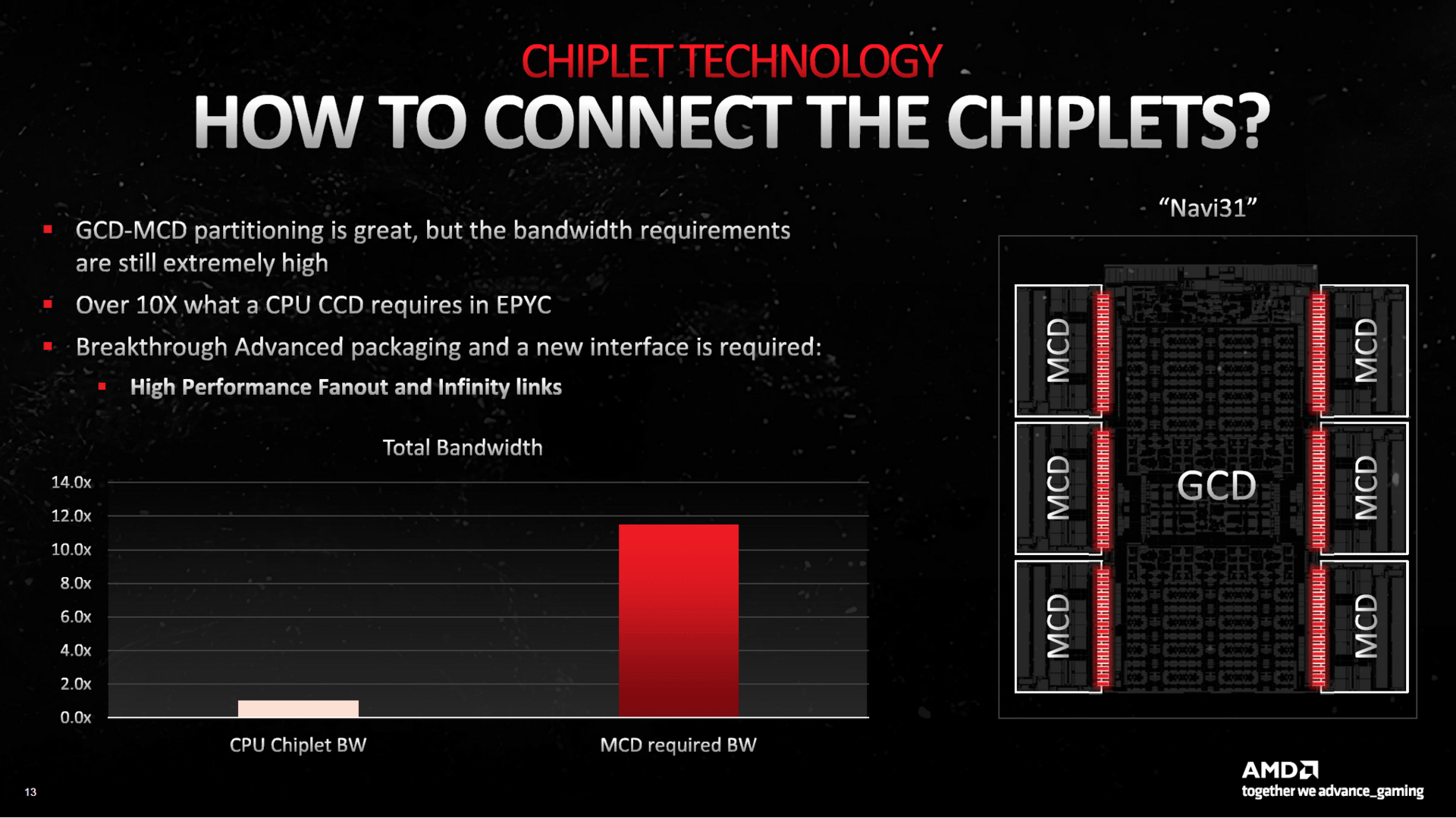
An dieser Stelle soll es aus Zeitgründen nicht großartig um die Technik von RDNA 3 gehen, stattdessen werden nur die interessantesten Neuerungen zusammengefasst. So handelt es sich bei Navi 31 um das erste Chiplet-Design bei GPUs, das einen 300 mm großen „Graphics Compute Die“ (GCD) im N5-Prozess bei TSMC mit sechs im N6-Verfahren gefertigten und insgesamt 220 mm² großen „Memory Cache Dies“ (MCD) auf einem Package vereint. Das soll laut AMD Vorteile bei den Kosten bringen, hat aber auch Nachteile bei der reinen Leistung.
GPU-Chiplets bringen Vor- und Nachteile
Doch wie sind die Chiplets überhaupt miteinander verbunden? Der bei den CPUs genutzte „Infinity Fabric“ ist für GPUs nicht geeignet, da der Bandbreitenbedarf bei Grafikkarten laut AMD mehr als 10 Mal so hoch pro MCD ist wie bei den CPUs pro CCD. Um dies zu ermöglichen, hat AMD eine neue Verbindung namens „Infinity Fanout Links“ entwickelt, die insgesamt eine maximale Bandbreite von 5,3 TB pro Sekunde liefert.
AMD gibt aber ehrlich zu, dass das Chiplet-Verfahren bei GPUs zwar Kostenvorteile bringt, jedoch zugleich Leistungsnachteile. Bei gleichem Takt hat Navi 21 im Vergleich zu Navi 31 eine zwischen 5 bis 10 Prozent schlechtere Latenz beim DRAM-Zugriff. Darüber hinaus steigt die Latenz zum „Infinity Fabric“ um einen vergleichbaren Wert an. AMD will dies durch höhere Taktraten ausgleichen beziehungsweise gar in einen Vorteil umwandeln, was aber nichts daran ändert, dass ein monolithischer Navi 31 bei gleichen Taktraten immer noch schneller wäre. Das ist der Nachteil, den GPU-Chiplets zurzeit mit sich bringen.
-
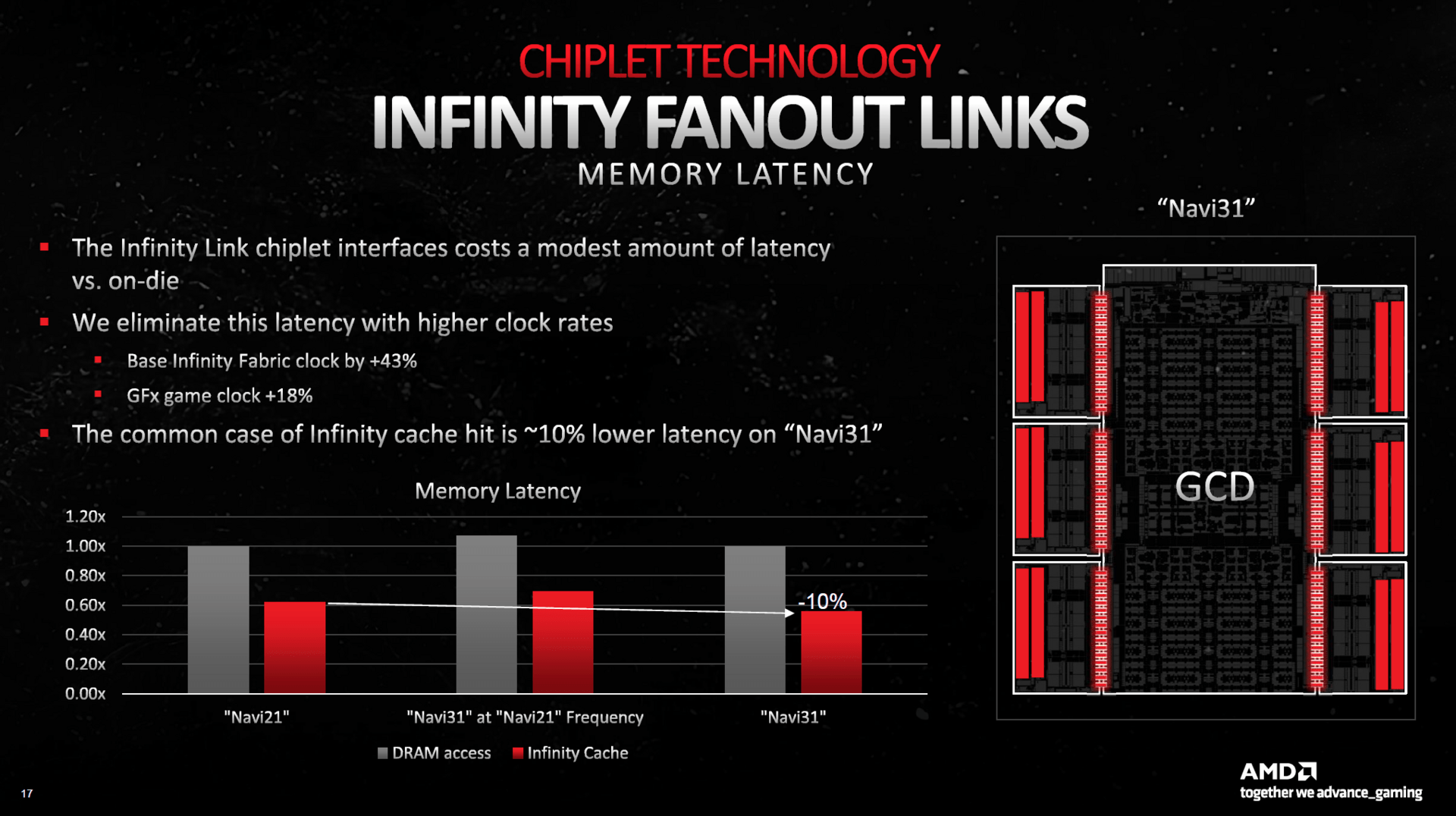 Chiplets auf Navi 31 (Bild: AMD)
Chiplets auf Navi 31 (Bild: AMD)
Dual-Issue und mehr für mehr Leistung pro CU
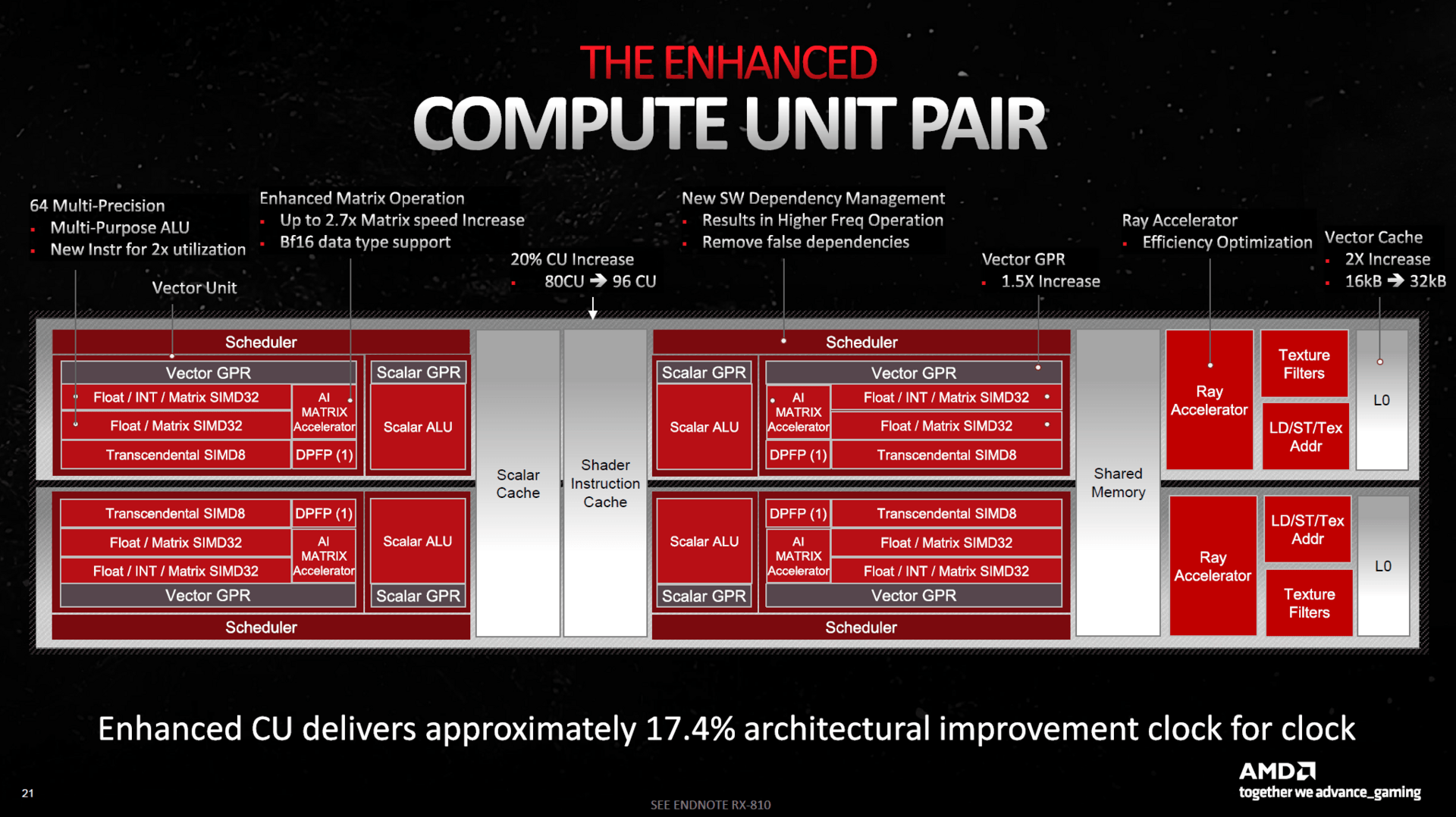
Der GCD besteht bei Navi 31 im Vollausbau aus insgesamt 96 Compute-Units, was nur eine geringe Steigerung gegenüber dem Vorgänger Navi 21 ist. Um ein größeres Leistungsplus als 20 Prozent zu erhalten, hat AMD die FP32-Einheiten nun als „Dual-Issue“ ausgelegt. Sie können also zwei Rechenaufgaben zur selben Zeit durchführen. Theoretisch wird damit die Rechenleistung verdoppelt, wobei AMD nicht umsonst auf die Nennung von 12.288 FP32-ALUs (96 CUs × 64 FP32-ALUs × 2) verzichtet und stattdessen von 6.144 FP32-ALUs spricht.
Das ist mit Sicherheit ehrlicher, denn AMD ist einen möglichst ressourcenschonenden Weg gegangen, um Transistoren zu sparen. Der Treiber-Compiler kann schließlich nur bestimmte Befehle zusammenlegen, die dann schneller berechnet werden können. Ist dies dagegen nicht möglich, werden quasi nur 6.144 FP32-ALUs genutzt. Nun ist es die Aufgabe des Treiber-Compilers, möglichst viele Befehle Dual-Issue-tauglich zu machen – und deswegen spricht AMD auch davon, dass in Zukunft mehr Programme doppelt so schnell ausgeführt werden als aktuell. Damit hat das Treiberteam aber auch mehr Arbeit mit RDNA 3 als noch mit RDNA 2. Nvidia ist bereits bei Ampere mit doppelt ausgeführten FP32-Einheiten einen sehr ähnlichen Weg gegangen, der nochmal etwas weitergeht als der von AMD – allerdings vermutlich auch mehr Transistoren kostet.
Um zusätzlich mehr Leistung aus den Rechenwerken zu holen, hat AMD die Compute-Units darüber hinaus weiter verbessert, obschon der eigentliche Aufbau gleich geblieben ist. So wurden die Cache-Größen deutlich angezogen, der L2-Cache ist mit 6 MB nun 50 Prozent größer, der L1-Cache mit insgesamt 3 MB 300 Prozent größer und der L0-Cache mit ebenso 3 MB um 240 Prozent gewachsen. Des Weiteren wurden die Vector-Register vergrößert und beschleunigt, sodass AMD bei gleichem Takt bei RDNA 3 von durchschnittlich 17,4 Prozent mehr Performance pro CU als bei RDNA 2 spricht.
-
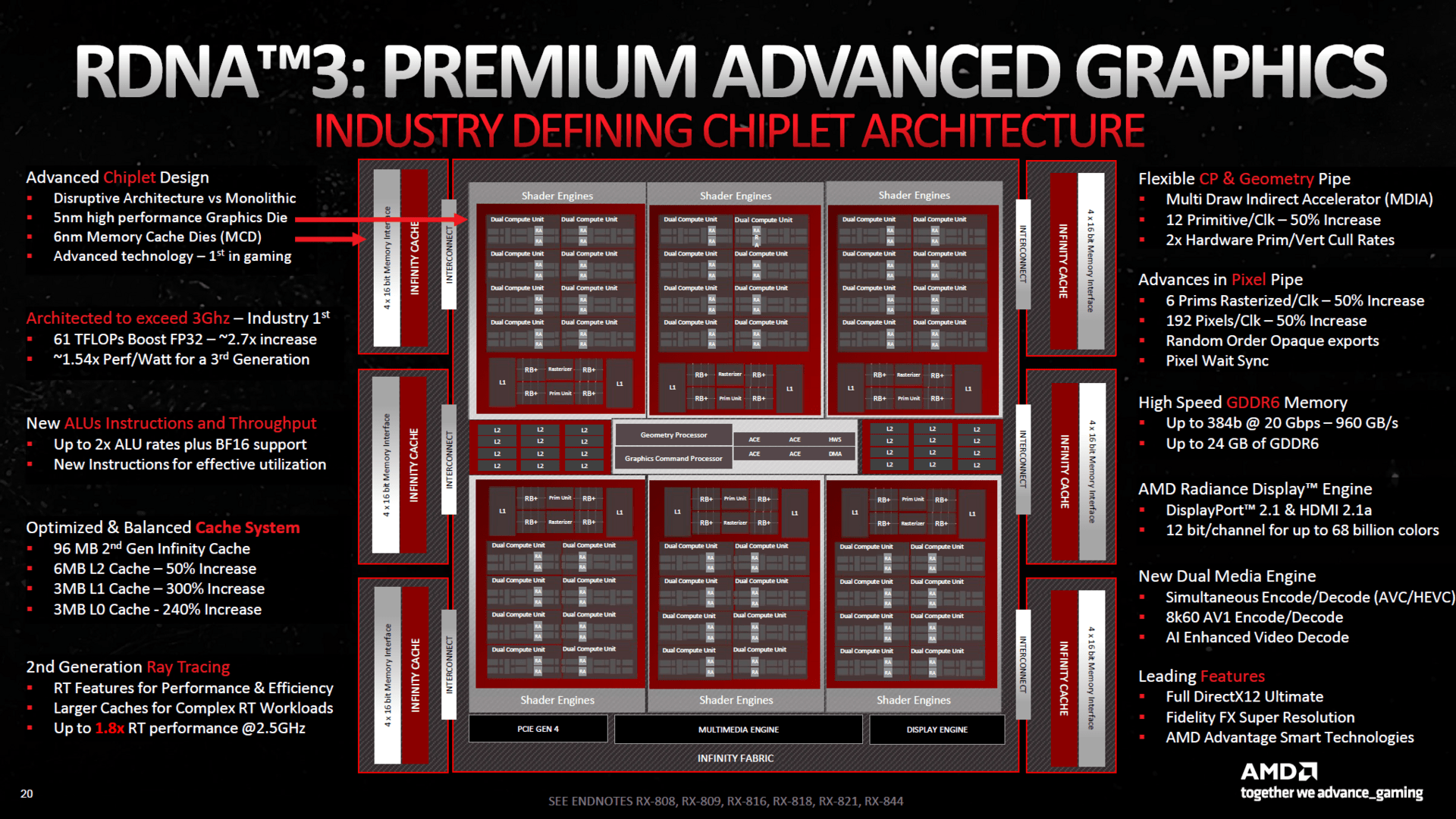 Die Architektur von Navi 31 (Bild: AMD)
Die Architektur von Navi 31 (Bild: AMD)
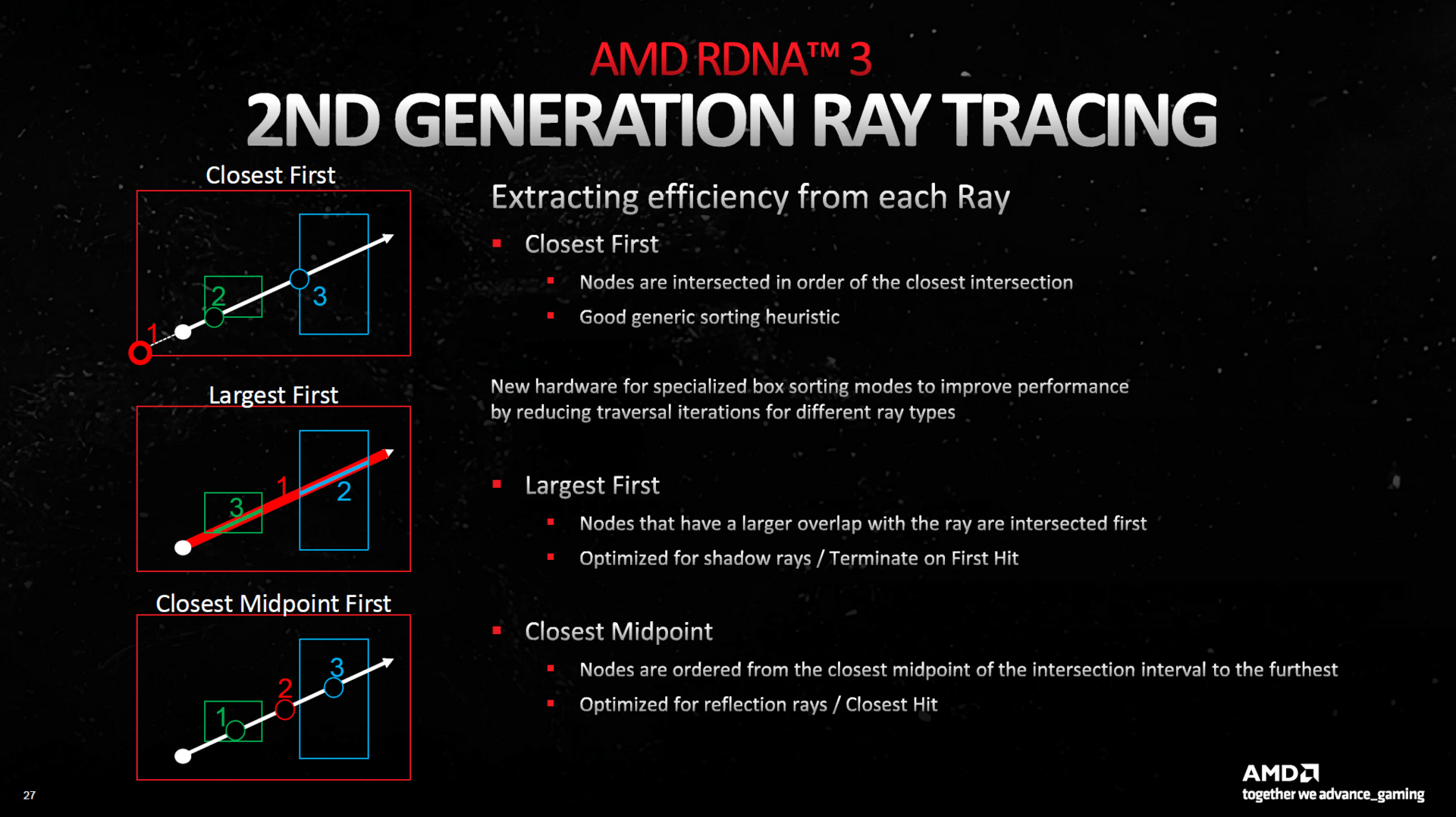
Raytracing macht einen großen Sprung, aber …
Darüber hinaus führt RDNA 3 die zweite Generation an Raytracing-Einheiten ein, die immer noch genauso aufgebaut ist wie bei RDNA 2 und damit auch in den Textureinheiten beheimatet ist – aber es soll deutlich schneller werden. So sollen die RT-Einheiten von RDNA 3 längst nicht mehr jeden RT-Strahl verfolgen müssen, sondern können nicht weiter benötigte auch abbrechen und vor allem in komplexen Szenarien soll die „Strahlenverfolgung“ nun deutlich schneller funktionieren. Generell soll jeder einzelne Strahl schneller ins Ziel geführt werden können als bei RDNA 2. Was RDNA 3 jedoch anders als Nvidia-GPUs immer noch nicht kann, ist eine beschleunigte Erstellung der BVH-Struktur – das machen nach wie vor die FP32-Einheiten – und anders als bei Lovelace können auch keine Shader für optimiertes Raytracing neu sortiert werden.
AMD spricht bei RDNA 3 von einer bis zu 80 Prozent besseren RT-Performance bei hoher RT-Last. Hierbei gibt es aber eine Besonderheit zu bedenken. So gibt es bei RDNA 3 wie auch beim Vorgänger pro Compute-Unit eine RT-Einheit. Da die Anzahl der Compute-Units jedoch eben nur um 20 Prozent steigt und die neuen Dual-Issue-ALUs keine Hilfe beim Raytracing sind, wenn die speziellen Einheiten limitieren, macht die RT-Leistung zumindest in der Theorie trotz bis zu 80 Prozent mehr Leistung pro RT-Einheit keinen überproportionalen Sprung. Dazu hätte es mehr RT-Einheiten pro CU gebraucht. So steigen die Rasterizer- und die RT-Leistung vergleichbar an.
-
 Raytracing bei RDNA 3 (Bild: AMD)
Raytracing bei RDNA 3 (Bild: AMD)

RDNA 3 mit separaten KI-Einheiten – so halbwegs
Eine Premiere bei RDNA 3 sind separate KI-Beschleuniger, die auf Navi 31 ein physischer Bestandteil der GPU sind. 192 gibt es davon auf Navi 31, pro Compute-Unit sind also deren 2 vorhanden. Sie unterscheiden sich jedoch grundsätzlich von Nvidias Tensor-Kernen und sind nicht ansatzweise so schnell. Hinzu kommt, dass sie selbst offenbar gar keine Matrizen berechnen können, sondern stattdessen einfach deutlich schneller als zuvor Vorbereitungen für die Matrizenberechnungen treffen können, die dann aber wiederum von den normalen FP32-ALUs berechnet werden. Entsprechend soll die Matrix-Leistung auf Navi 31 auch „nur“ um den Faktor 2,7 auf RDNA 3 ansteigen. Nvidia nennt bei den eigenen GPUs deutlich höhere Zugewinne.
AMD hat das Speicherinterface auf Navi 31 von 256 auf 384 Bit erweitert. Es ist nicht Teil des GCD-Chips, sondern setzt sich aus den sechs MCD-Chiplets zusammen. Pro Chiplet gibt es vier 16 Bit breite Speicherkanäle, was auf der Radeon RX 7900 XTX mit allen sechs Chiplets 384 Bit ergibt und auf der Radeon RX 7900 XT mit fünf Chiplets (plus einem Dummy-Chiplet für eine bessere Stabilität des Kühlers) 320 Bit. Entsprechend steigt auch der Speicherausbau auf 24 respektive 20 GB des Typs GDDR6 an.
Infinity-Cache zweiter Generation wird deutlich schneller
Außerdem befindet sich die zweite Generation des Infinity-Caches auf den MCDs, pro MCD sind 16 MB Cache verbaut, 96 MB also auf dem Flaggschiff und 80 MB auf der kleineren Variante. AMD will den Infinity-Cache gegenüber der Urversion optimiert haben, sodass er weniger oft Daten hin und her schicken muss, um Energie zu sparen und so auch die verkleinerte Kapazität gegenüber den 128 MB von RDNA 2 zu kompensieren. Darüber hinaus hat AMD die Performance des Infinity-Caches verdoppelt, der bei RDNA 3 eine Bandbreite von 2,5 TB/s beisteuert, während der von RDNA 2 „nur“ 1,2 TB/s geliefert hat.
| RX 7900 XTX | RX 7900 XT | RX 6900 XT | RTX 4080 | |
|---|---|---|---|---|
| Architektur | RDNA 3 | RDNA 2 | Ada Lovelace | |
| GPU | Navi 31 | Navi 21 | AD103 | |
| Design | Chiplet 1 × GCD + 6 × MCD |
Chiplet 1 × GCD + 5 × MCD |
Monolithisch | |
| Fertigung | TSMC N5 (GCD) TSMC N6 (MCD) |
TSMC N7P | TSMC N4 | |
| Transistoren | 57,7 Mrd | 26,8 Mrd. | 45,9 Mrd. | |
| Chipgröße | 300 mm (GCD) 37 mm (1 × MCD) |
519 mm² | 379 mm² | |
| CU/SM | 96 | 84 | 80 | 76 |
| FP32-ALUs | 6.144/12.288 | 5.376/10.752 | 5.120 | 9.728 |
| RT-Kerne | 96, 2nd Gen | 84, 2nd Gen | 80, 1st Gen | 76, 3rd Gen |
| KI-Kerne | 192, 1st Gen | 168, 1st Gen | Nein | 304, 4th Gen Tensor |
| Game/Base-Takt | 2.300 MHz | 2.000 MHz | 2.015 MHz | 2.210 MHz |
| Boost-Takt | 2.500 MHz | 2.400 MHz | 2.250 MHz | 2.510 MHz |
| FP32-Rechenleistung | 61,4 TFLOPS | 51,6 TFLOPS | 23,0 TFLOPS | 48,8 TFLOPS |
| FP16-Rechenleistung | 122.9 TFLOPS | 103,2 TFLOPS | 46,1 TFLOPS | 48,8 TFLOPS |
| Textureinheiten | 384 | 336 | 320 | 304 |
| ROPs | 192 | 128 | 112 | |
| L2-Cache | 6.144 KB | 4.096 KB | 65.536 KB | |
| Speicher | 24 GB GDDR6 | 20 GB GDDR6 | 16 GB GDDR6 | 16 GB GDDR6X |
| Speicherdurchsatz | 20 Gbps | 16 Gbps | 22,4 Gbps | |
| Speicherinterface | 384 Bit | 320 Bit | 256 Bit | |
| Speicherbandbreite | 960 GB/s | 880 GB/s | 512 GB/s | 717 GB/s |
| Infinity-Cache | 96 MB, 2nd Gen | 80 MB, 2nd Gen | 128 MB, 1st Gen | Nein |
| IC-Bandbreite | 2,5 TB/s | 2,0 TB/s | 1,2 TB/s | Nein |
| Slot-Anbindung | PCIe 4.0 ×16 | |||
| TDP | 355 Watt | 315 Watt | 300 Watt | 320 Watt |
RDNA 3 hat zwei verschiedene Takt-Domänen
Interessantes gibt es noch bei den Taktraten. Nicht so beim Speicher, der arbeitet mit 20 Gbps, also mit 10.000 MHz. Bei der GPU selbst hat AMD den „Primär-Takt“ nun aber auf zwei verschiedene Takt-Domänen aufgeteilt, den Front-End-Takt und den Shader-Takt. So taktet auf der Radeon RX 7900 XTX das Front End mit 2,5 GHz und die eigentlichen Shader-Einheiten nur mit 2,3 GHz. Durch Letzteres soll die Leistungsaufnahme um bis zu 25 Prozent reduziert werden. Bei der Radeon RX 7900 XT beträgt der Takt 2,0 respektive 2,2 GHz.
Wird die Grafikkarte nun übertaktet, werden beide Domänen um das eingestellte Plus angehoben. Wer zum Beispiel den Takt bei der Radeon RX 7900 XTX um 100 MHz erhöht, erhält einen Front-End-Takt von 2,6 GHz und einen Shader-Takt von 2,4 GHz. An Tools (externe und im eigenen Treiber) gibt AMD dabei nur den Front-End-Takt weiter, der Shader-Takt lässt sich zumindest aktuell nicht auslesen. Wie gewohnt ist die Anzeige ein Durchschnittswert innerhalb eines gewissen Zeitrahmens.
Die RX 7900 XT darf ein wenig mehr Energie nutzen
Dann noch etwas zur Leistungsaufnahme. Die Radeon RX 7900 XTX weist eine „Typical Board Power“ von 355 Watt auf, die Radeon RX 7900 XT eine von 315 Watt. Wer bei Letzterem nun stutzt, hat gut aufgepasst, denn bei der Ankündigung wurde die Radeon RX 7900 XT noch mit 300 Watt genannt. AMD will zwischenzeitlich jedoch herausgefunden haben, dass nur durch die zusätzlichen 15 Watt die gewünschte Performance auf allen GPUs gewährleistet werden kann. Der Hersteller hat sich dann für diesen Weg entschieden, anstatt die Leistung minimal zu beschneiden. Auf sonstige Eigenschaften der Grafikkarte soll dies keine Auswirkungen haben.

Mit DisplayPort 2.1 und AV1-Codec
RDNA 3 bietet als erste Architektur überhaupt DisplayPort 2.1 in der Ausführung „UHBR13.5“ als Monitorausgang an. Das ist nicht die größte Ausbaustufe, erlaubt aber dennoch eine maximale Bandbreite von 54 Gbps und damit bei aktivierter DSC-Kompression zum Beispiel 4K-Auflösung bei 480 Hz, 8K bei 165 Hz oder WQHD bei 900 Hz. Darüber hinaus wird eine Farbwiedergabe mit 12 Bit pro Kanal unterstützt. Anfang 2023 sollen entsprechende DP-2.1-Monitore erscheinen. Mit derselben Bandbreite kann auch der verbaute USB-C-Anschluss umgehen. Darüber hinaus steht noch HDMI 2.1 zur Verfügung.
Des Weiteren hat RDNA 3 eine neue Media-Engine bekommen beziehungsweise gleich zwei davon, sodass zwei H.264- oder H.265-Streams gleichzeitig en- oder decodiert werden können. Obendrein kann RDNA 3 mit dem AV1-Codec umgehen, hier ist 8K60 beziehungsweise 4K240 die maximal mögliche Auflösung beziehungsweise Framerate. Genauere Details dazu zeigt folgende Tabelle.
| H.264 (AVC) | H.265 (HEVC) | AV1 | VP9 | |
|---|---|---|---|---|
| Encodieren | 4K330 4:2:0, 8 Bit |
4K210 8K48 4:2:0, 8/10 Bit |
4K240 8K60 4:2:0, 8/10/12 Bit |
4K210 8K48 4:2:0, 8/10 Bit |
| Decodieren | 4K180 4:2:0, 8 Bit |
4K180 8K48 4:2:0, 8/10 Bit |
4K240 8K60 4:2:0, 8/10 Bit |
– |
(*) Bei den mit Sternchen markierten Links handelt es sich um Affiliate-Links. Im Fall einer Bestellung über einen solchen Link wird ComputerBase am Verkaufserlös beteiligt, ohne dass der Preis für den Kunden steigt.