
Nvidia DGX GH200: 256 Grace Hopper Superchips liefern 1 ExaFLOPS FP8 für KI

Nvidias Grace Hopper Superchip mit Arm-CPU und Hopper-GPU geht in die vollständige Produktion und ist damit bereit für die Auslieferung an erste Abnehmer. Passend dazu lässt sich mit dem DGX GH200 ein KI-Supercomputer bauen, der 256 Grace Hopper Superchips für 1 ExaFLOPS FP8-Rechenleistung speziell für KI miteinander kombiniert.
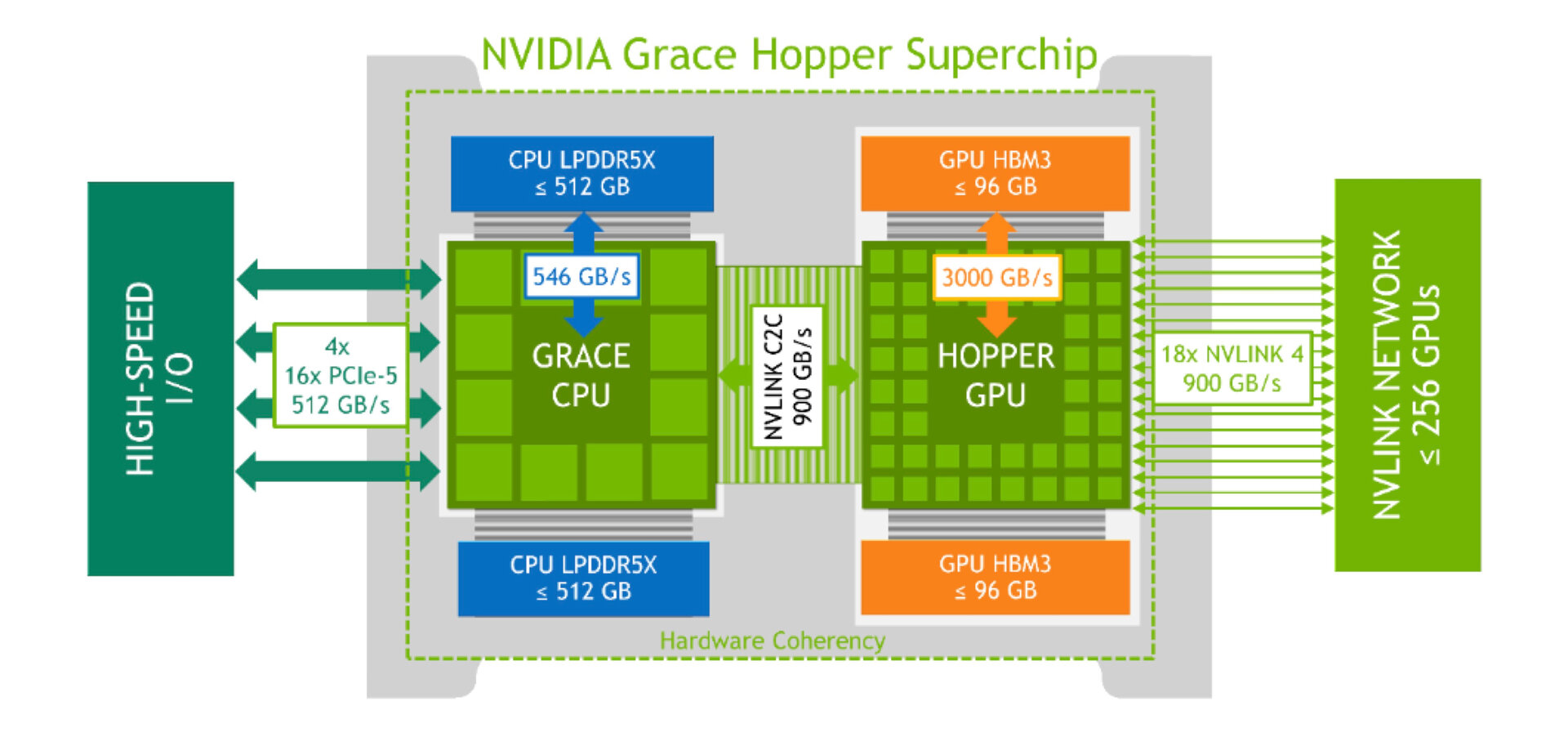
Mit der Ankündigung des Meilensteins durch Nvidia-CEO Jensen Huang im Rahmen der Computex hat der Grace Hopper Superchip erstmals eine offizielle Modellnummer: GH200. Hinter der Superchip-Architektur verbirgt sich im Falle des Grace Hopper Superchips eine Kombination aus Arm-CPU und Hopper-GPU, die über einen Chip-2-Chip-Interconnect mit 900 GB/s Bandbreite miteinander verbunden sind, sodass eine siebenmal so hohe Bandbreite im Vergleich selbst zum neuesten PCIe Gen5 mit 16 Lanes erreicht wird. Bei diesem Standard liegt das Maximum bei 128 GB/s.
Den Grace Hopper Superchip hatte Nvidia erstmals zur GTC im Frühjahr 2021 vorgestellt und für 2023 in Aussicht gestellt, was sich jetzt als korrekte Vorhersage erwiesen hat. Sogenannte Superchips hat Nvidia zwei im Portfolio: den Grace Hopper Superchip sowie den Grace Superchip, bei dem der Chip-2-Chip-Interconnect für eine zweite Arm-CPU genutzt wird. Auch daran lassen sich aber wiederum externe GPUs anflanschen.
DGX GH200 nutzt 256 Grace Hopper Superchips
Erste Systeme mit GH200 sollen im weiteren Verlauf dieses Jahres verfügbar werden, erklärte Nvidia zur Messe in Taiwan. Eines davon hat selbstverständlich Nvidia selbst heute in das Portfolio aufgenommen: DGX GH200 ist ein praktisch fertiger KI-Supercomputer, der gleich 256 der Grace Hopper Superchips in einem System vereint. Nvidia bewirbt den Supercomputer mit einer Leistung von 1 ExaFLOPS, womit der Rechner sofort in der Oberliga der Top500 landen würde, wo nur das Frontier-System aus den USA zuletzt diese Marke durchbrochen hat.
Nvidias Berechnung für die angegebenen 1 ExaFLOPS liegt jedoch eine Leistung pro H100-GPU von 3.958 TeraFLOPS für „FP8 Tensor Core“ unter Einbeziehung der Sparsity-Beschleunigung zugrunde, was bei 256 GPUs genau 1,013 ExaFLOPS entspricht. Für einen Eintrag in der Top500 wird jedoch FP64 angesetzt, das bei lediglich 34 TFLOPS pro Grace Hopper Superchip liegt. Ein DGX GH200 käme demnach auf 8,704 PetaFLOPS, sodass man hochgerechnet 115 DGX GH200 oder 29.440 Grace Hopper Superchips für 1 ExaFLOPS bei FP64 benötigen würde. Unter Verwendung von „FP64 Tensor Core“ mit DMMA-Instruktionen ließen sich diese Angaben jedoch verdoppeln (Leistung) respektive halbieren (Nodes). Zum Vergleich: Der schnellste Supercomputer Frontier nutzt 9.472 AMD Epyc 7453 und 37.888 Radeon Instinct MI250X und erreicht 1,194 ExaFLOPS.
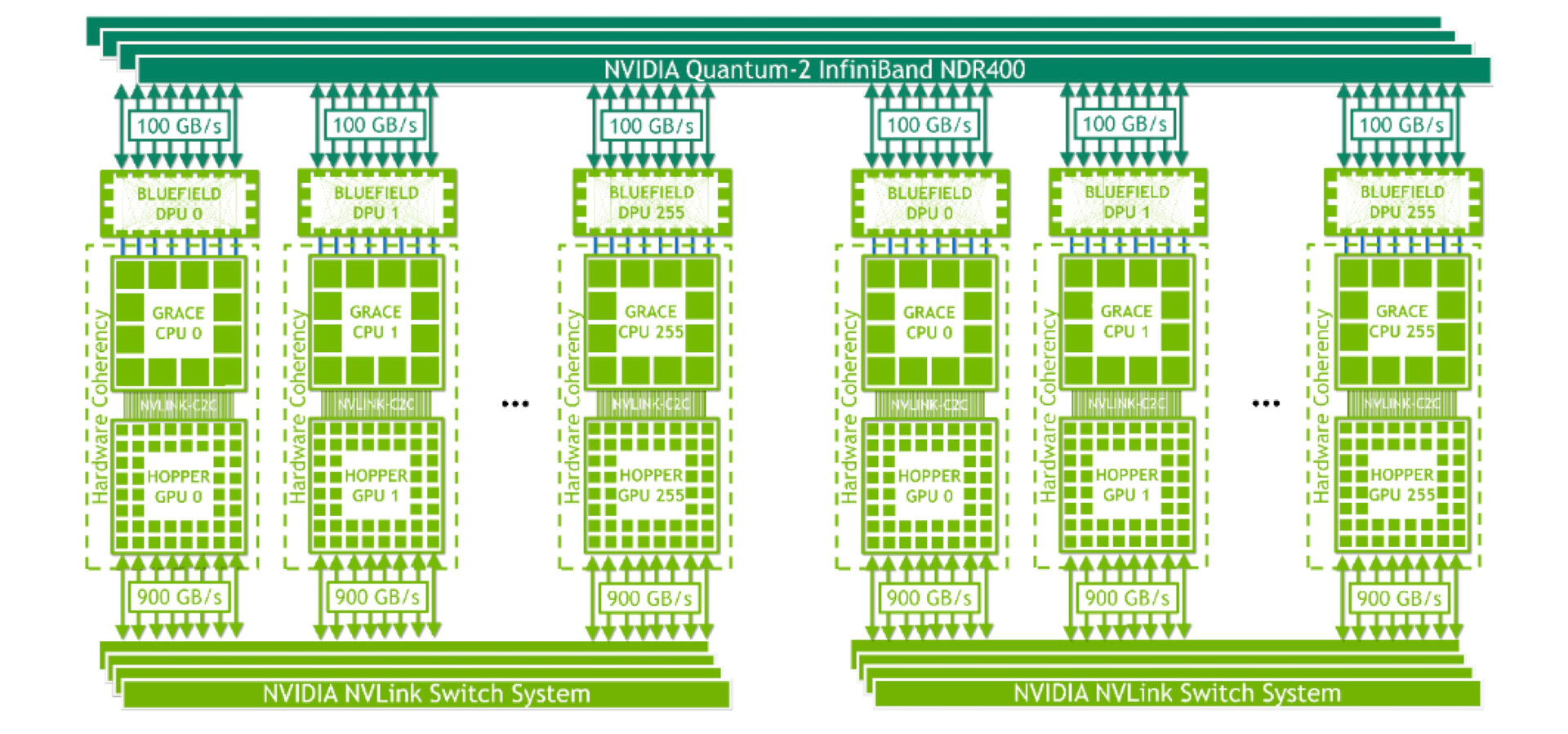
Nvidia Helios nutzt vier DGX GH200
Das Zusammenspiel der 256 Grace Hopper Superchips im DGX GH200 erfolgt über den NVLink der 4. Generation, der im Supercomputer ebenso mit 900 GB/s von einer GPU zur nächsten arbeitet, die in dem System über den NVLink Switch wie eine riesige GPU behandelt werden. Aufgrund der 96 GB HBM3 pro GPU ergibt sich ein Unified Memory von satten 144 TB. Damit ist allerdings noch nicht Schluss, wie mit dem „Helios“ ein erster eigener Supercomputer von Nvidia selbst zeigt, der gleich 1.024 der Grace Hopper Superchips und somit vier DGX GH200 nutzt. Die DGX GH200 sind im Netzwerk per Quantum-2 InfiniBand verbunden, das immerhin noch auf 400 GB/s pro Sekunde und somit etwas weniger als die Hälfte der internen GPU-zu-GPU-Bandbreite kommt. Der Helios-Supercomputer soll laut Nvidia zum Ende dieses Jahres online gehen.
Zusagen von Google, Meta und Microsoft
Große Abnehmer für den DGX GH200 hat Nvidia mit Google, Meta und Microsoft bereits gewinnen können. Der Grace Hopper Superchip wurde speziell für das Training großer AI Models, für Generative AI, Recommender-Systeme und Data Analytics entwickelt und passt damit perfekt zu den Aufgabengebieten der genannten Unternehmen. Der DGX GH200 soll auch als Blaupause für Cloud-Service-Anbieter dienen, damit diese ihre Infrastruktur weiter anpassen können. Systeme von Drittanbietern wurden zwar noch nicht angekündigt, dürften aber später folgen und als HGX statt DGX laufen.
Hintergrund zum Grace Hopper Superchip
Der Grace Hopper Superchip (PDF) besteht aufseiten der CPU aus 72 Kernen des Typs Arm Neoverse V2 mit jeweils 64 KB I- und D-Cache als L1-Cache sowie jeweils 1 MB L2-Cache pro Kern. Der L3-Cache beläuft sich auf insgesamt 117 MB. An die CPU angebunden werden 480 GB LPDDR5X mit ECC-Support bei 546 GB/s, zudem stellt die CPU viermal PCIe Gen5 x16 für in Summe 512 GB/s zur Verfügung. Die H100-GPU wird jedoch mittels C2C-Interconnect mit 900 GB/s angeflanscht und verfügt selbst über 96 GB HBM3 mit über 3 TB/s Bandbreite. 96 GB HBM3 entsprechen der Hälfte der Doppel-GPU H100 NVL, aber somit dem derzeitigen Maximum von Nvidia pro Einzel-GPU. Der Grace Hopper Superchip lässt sich von 450 bis 1.000 Watt TDP konfigurieren und mit Luft oder Wasser kühlen.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.