
In-Memory Processing: SK Hynix demonstriert seinen GDDR6-AiM-Beschleuniger

Rechenaufgaben direkt in den Speicher verlegen, um die Wege der Daten zu verkürzen und deren Verarbeitung zu beschleunigen. Diese Idee steckt hinter dem Konzept Processing-In-Memory (kurz PIM). SK Hynix hat jetzt einen Prototyp seines AiM-Beschleunigers mit GDDR6-Speicher vorgeführt.
Bereits seit vielen Jahren wird die Idee von Processing-In-Memory oder auch In-Memory Processing verfolgt. Nicht nur bei Speicherherstellern wie Samsung und SK Hynix wird daran geforscht, auch bei AMD stand etwa eine mögliche Umsetzung in einer APU der Zukunft bereits vor neun Jahren auf dem Zettel.
SK Hynix demonstriert GDDR6-AI-Beschleuniger
Allmählich kommen die Konzepte aber einem Marktstart immer näher. SK Hynix hat jetzt den Prototyp seiner Beschleunigerkarte AiMX vorgeführt. Diese nutzt spezielle „GDDR6-AiM Chips“. Dahinter verbirgt sich der von Grafikkarten bekannte GDDR6-Speicher, der aber zusätzlich mit integrierten Recheneinheiten (Processing Units, PU) versehen ist. Jeder der 16 Speicherbänke pro Chip ist eine PU zugeordnet, die mit 1 GHz arbeitet. Fotos zeigen die Karte, bei der die kleinen grauen Chipgehäuse den GDDR6-AiM-Speicher beherbergen. Bei den beiden großen Packages in der Mitte handelt es sich um FPGAs der Familie Xilinx Virtex.


Ein solcher GDDR6-AiM-Chip soll bestimmte Gleitkommaberechnungen (Bfloat16) mit einer Spitzenleistung von 512 GFLOPS ermöglichen. Das BF16-Format wird in Systemen für maschinelles Lernen eingesetzt und bisher vor allem von spezialisierten Prozessoren wie TPUs oder FPGAs verarbeitet. Dafür geeignete Tensor-Recheneinheiten kommen bei Grafikchips der neueren Generationen zum Einsatz. Das maschinelle Lernen ist ein wesentlicher Bestandteil von Künstlicher Intelligenz (Artifical Intelligence, AI).


Dass bestimmte, für KI-Anwendungen relevante Berechnungen mit solchen PIM-Lösungen durch kürzere Datenwege weitaus schneller ausgeführt werden können, hat SK Hynix im Rahmen des AI Hardware & Edge AI Summit 2023 demonstriert. Auf einem Server-System mit der AiMX-Karte wurde ein Open Pre-trained Transformer Language Model der Firma Meta eingesetzt. In ausgewählten Tests erreichte AiMX eine zehnmal schnellere Datenverarbeitung im Vergleich zu einem System mit einem klassischen GPU-Beschleuniger. Parallel soll nur ein Fünftel der Energie benötigt worden sein. Mit welcher GPU hier konkret verglichen wurde, verraten die Informationen allerdings nicht.
Noch ist alles in der Schwebe
Welche der Ansätze sich im Markt durchsetzen werden, bleibt abzuwarten. Noch wird viel experimentiert. Bei Samsung stand jüngst PIM bei High Bandwidth Memory und LPDDR im Fokus. Ein weiterer Ansatz geht in Richtung Processing-near-Memory (PNM), wobei die neuen CXL-Speichererweiterungen eine Rolle spielen.
-
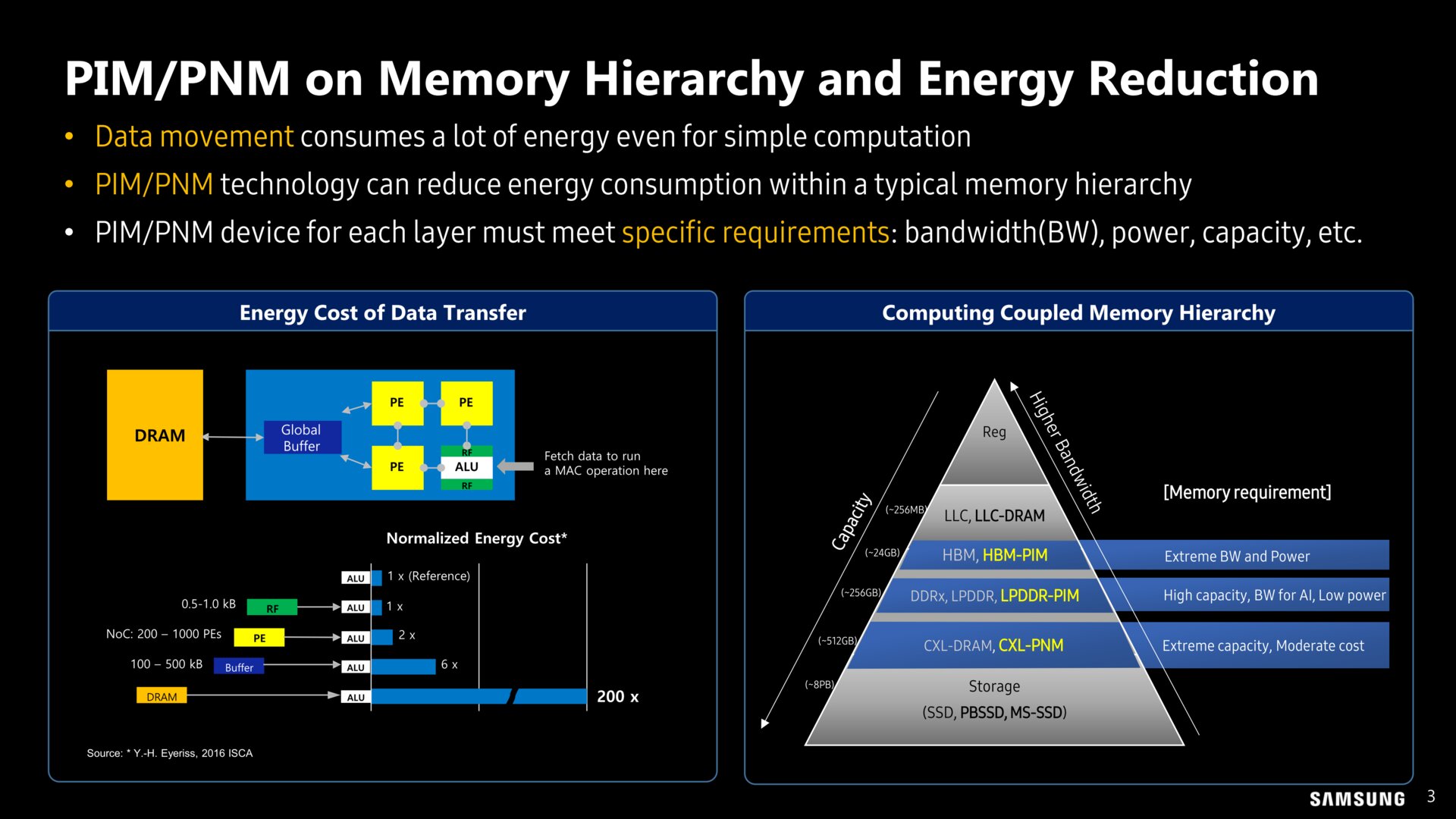 In der Speicherpyramide wird mit PIM und PNM gerechnet (Bild: Samsung)
In der Speicherpyramide wird mit PIM und PNM gerechnet (Bild: Samsung)
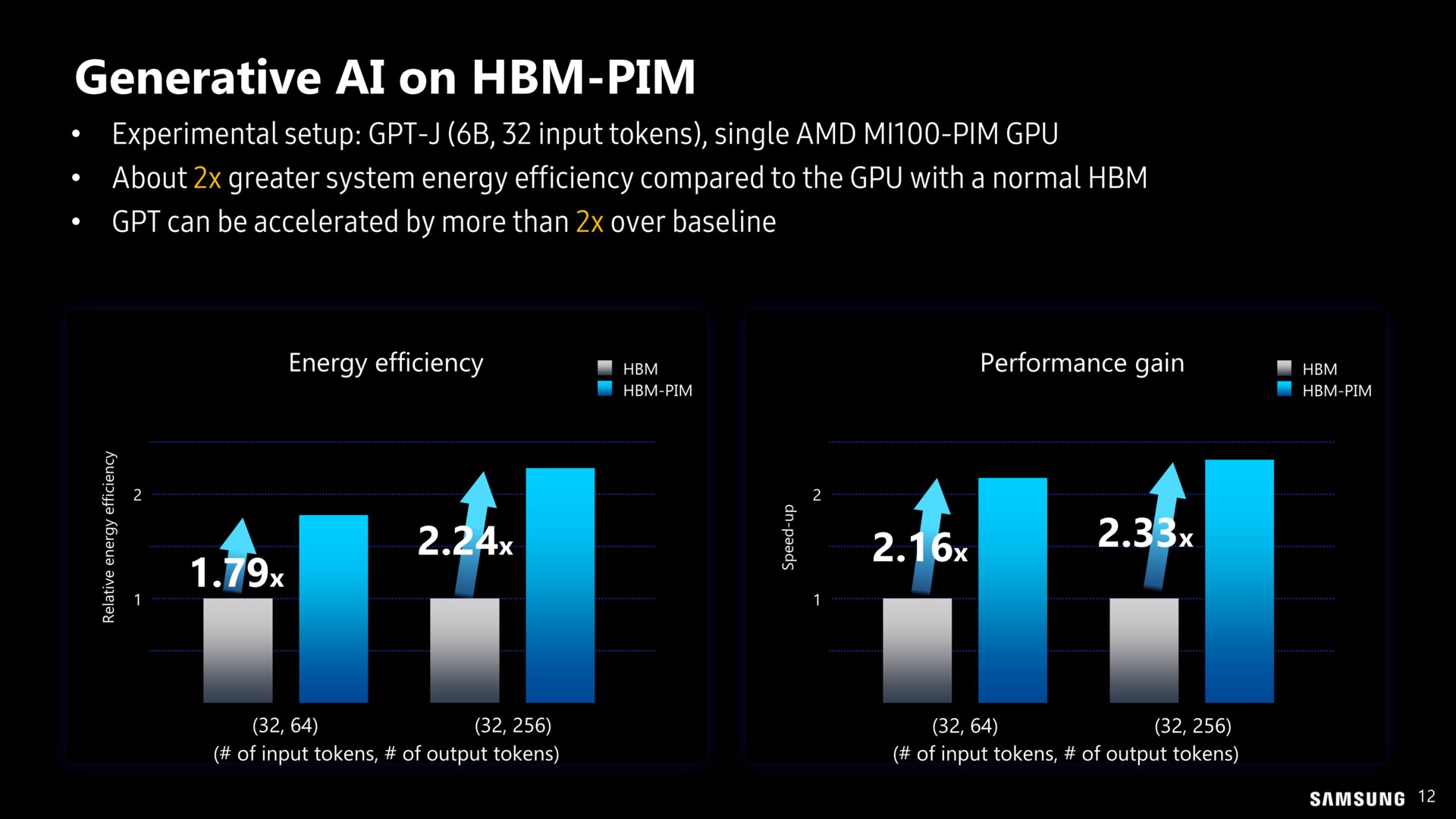

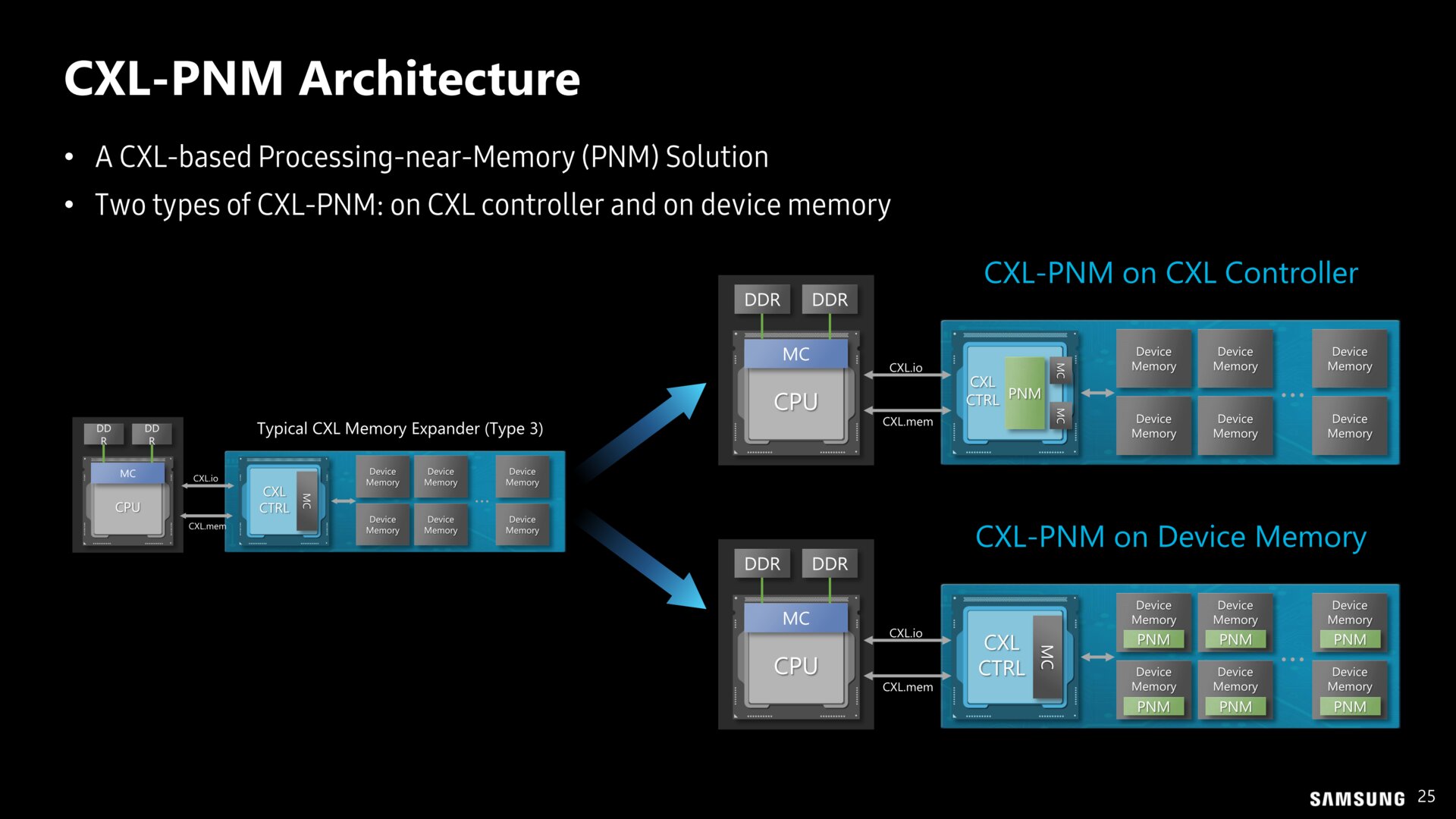
Das Wirrwarr der Abkürzungen passt zu den verschiedenen Lösungen, die im Grunde alle das gleiche Ziel verfolgen, nämlich die Datenwege zu beschleunigen und Flaschenhälse zu umgehen. Die kommenden Jahre werden zeigen, welche Konzepte sich im boomenden KI-Markt durchsetzen.