Deutsches Exascale-System Jupiter: 23.752 GH200 ergeben Europas schnellsten Supercomputer

Nvidia und das deutsche Forschungszentrum Jülich haben die Eckdaten von Jupiter bekannt gegeben: 23.752 GH200 machen den Supercomputer zum schnellsten in Europa. Viel Leistung gibt es nicht nur für Künstliche Intelligenz (AI), die ExaFLOPs-Marke fällt auch für HPC-Anwendungen. Und das alles bei nur 18,2 Megawatt.
Sehr schnell und effizient
Höher, schneller und weiter ohne den Blick auf die Stromrechnung (und die Anschaffungskosten) geht ziemlich leicht. Doch soll der Stromverbrauch nicht vollends aus dem Ruder laufen, grenzt das automatisch die Wahl der Hardware ein.
Der schnellste Supercomputer in Deutschland, der zugleich die neue Nummer 1 in Europa ist, lässt sich mit einem Fokus auf Effizienz aber auch politisch besser verkaufen, schließlich ist (Industrie-)Strom und sein Preis hierzulande ein Dauerthema. Und da die öffentliche Hand das Projekt Jupiter massiv unterstützt, muss dies auch so sein: 250 Millionen Euro werden von der europäischen Supercomputing-Initiative EuroHPC JU und 250 Millionen Euro zu gleichen Teilen vom Bundesministerium für Bildung und Forschung (BMBF) und dem Ministerium für Kultur und Wissenschaft des Landes Nordrhein-Westfalen (MKW NRW) getragen.
18,2 Megawatt Leistungsaufnahme bei 1,0 ExaFLOPS HPC-Leistung liegen in der Liga, in der das aktuelle Nummer-1-System Frontier mit Hardware von AMD agiert. Frontier bot laut Top500 aus dem Mai 2023 bis dato 1,2 ExaFLOPS an Leistung bei knapp über 20 Megawatt. Zuletzt wurde Frontier allerdings weiter optimiert, für einen perfekten Vergleich mit Jupiter gilt es die neuen Daten noch abzuwarten. Einmal mehr deutlich machen Frontier und Jupiter so oder so: Ohne GPU geht im Supercomputer nichts mehr.

GH200 in seiner Sternstunde
Der GH200 alias Grace Hopper Superchip wird zu Zehntausenden in dem Supercomputer JUPITER, die Abkürzung steht für „Joint Undertaking Pioneer for Innovative and Transformative Exascale Research“, verbaut, genauer gesagt in 23.752-facher Ausführung. die GPUs finden im sogenannten Booster-Modul ihren Platz.

Dafür hat Nvidia ein neues Quad-Pack für den möglichst platzsparenden und effizienten Einsatz von vier GH200 gebaut, welches Eviden (Teil der Atos-Gruppe) dann in den Atos BullSequana XH3000 verbauen wird. Ein Quad-Pack markiert ein Node, zwei Nodes werden in einem Blade verbaut – so ist es zuletzt bei diesen Lösungen die Regel gewesen. Natürlich wird das Blade flüssigkeitsgekühlt, anders geht es bei diesen eng gepackten, sehr viel elektrische Leistung konsumierenden Produkten heutzutage gar nicht mehr.
The overall system will require the space of about 4 tennis courts and will use over 260km of high-performance cabling

Das Cluster-Modul wird ausgestattet mit dem neuen, in Europa entwickelten und hergestellten Rhea-Prozessor von SiPearl, einer CPU mit hoher Speicherbandbreite für komplexe Arbeitslasten. Die Cluster- und Booster-Module werden dynamisch als ein einheitlicher Supercomputer unter Verwendung des modularen ParaStation-Modulo-Betriebssystems von ParTec betrieben.
Installation ab Anfang 2024
Die Installation von Jupiter startet Anfang 2024. Mit dem Bau werden die wissenschaftlichen Nutzerinnen und Nutzer die Möglichkeit erhalten, das System im Rahmen des Early Access Program vorzubereiten und zu testen. Dies ermöglicht eine enge Zusammenarbeit aller Beteiligten, um die bestmögliche Version des Systems für die wissenschaftliche Gemeinschaft herzustellen und zu konfigurieren, erklärten die Partner per Pressemitteilung.
Im Nachgang der Ankündigung hat das Forschungszentrum Jülich weitere technische Details zum Supercomputer veröffentlicht. Wie bereits bekannt wird das komplette System in Modulen aufgebaut. Herzstück sind zum einen das Cluster-Modul mit den Prozessoren sowie das Booster-Module mit den Nvidia-Chips. Ohne die Storage-Module und das passende Interconnect geht aber auch nichts. Die in der nachfolgenden Darstellung in Blau eingefärbten Module sind gesetzt, die drei anderen optional für eine spätere Erweiterung geplant.
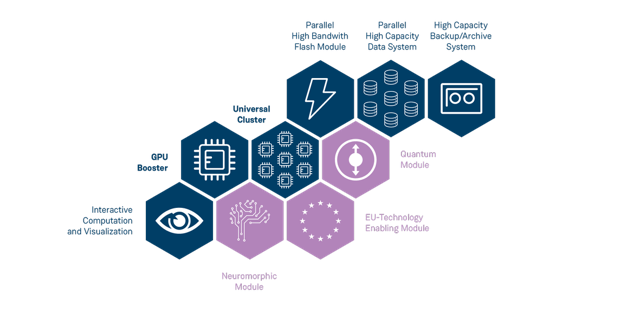
Das Booster-Modul ist das mit Abstand größte, rund 6.000 Nodes werden hier mit dem Grace Hopper Superchip bestückt (Nvidia nannte eine Zahl von 23.752 Stück). Es ist auch das leistungsfähigste und soll die 1 ExaFLOP/s (FP64, HPL) garantieren, mit geringerer Genauigkeit wie FP8 liegt der Wert noch viel höher. Diese über 20.000 GPUs stecken als „Quad-Pack“ in einem warmwassergekühlten BullSequana XH3000.

Ebenfalls in Nodes dieser Serie, rund 1.300 an der Zahl, stecken die Rhea1-CPUs. Die CPUs auf Basis der Arm-Architektur nutzen HBM2e als sehr schnellen, naheliegenden Speicher, zusätzlich sind 512 GByte DDR5 pro Node, optional auch die doppelte Menge von 1 TByte verbaut. Umfangreiche technische Details zur CPU sind noch Mangelware, vor zwei Jahren gab es erste Informationen: 64 Kerne nach Arm-V1-Architektur, HBM2e, PCIe 5.0 und mehr. Damals war aber auch noch Intel als GPU-Lieferant geplant für ein europäisches Exascale-System, nun ist bekanntlich aber erstmal Nvidia am Zug. Wie es final also um die CPUs bestellt ist, werden die kommenden Monate offenbaren.
Beim Interconnect kommen bewährte Mellanox-Technologien wie InfiniBand und DragonFly+ zum Einsatz – das Unternehmen gehört seit einigen Jahren ebenfalls zu Nvidia. Der Umfang des Interconnects ist gewaltig um keine Flaschenhälse zu produzieren und Leistung auf der Strecke zu lassen.
At the core of the system, the InfiniBand NDR network connects 25 DragonFly+ groups in the Booster module, as well as 2 extra groups in total for the Cluster module, storage, and administrative infrastructure. The network is fully connected, with more than 11000 400 Gb/s global links connecting all groups with each other.
Inside each group connectivity is maximized, with a full fat-tree topology. In it, leaf and spine switches use dense 400 Gb/s links; leaf switches rely on split ports to connect to 4 HCAs per node on the Booster module (1 HCA per node on the Cluster module), each with 200 Gb/s.
In total, the network comprises almost 51000 links and 102000 logical ports, with 25400 end points and 867 high radix switches, and has still spare ports for future expansions, for example for further computing modules.
Forschungszentrum Jülich
Der Kern des Massenspeicher-Moduls basiert auf 40 IBM Elastic Storage Server 3500. Es fasst 29 PetaByte Flash-Speicher, 21 PB davon werden zur Verfügung stehen. 3TB/s werden beim Lesen und 2 TB/s beim Schreiben anvisiert. Ergänzt wird dies durch ein 300 PB großes, aber nicht so performantes Storage Module und ein 700 PB fassendes Archiv.
Am Ende muss das gesamte System auch noch verwaltet werden. Dafür kommt natürlich eine Spezialanfertigung zum Einsatz, eine Mischung aus Software von Atos, ParTec und dem Forschungszentrum und seiner langen Erfahrung in dem Bereich. Über mehr als 20 Login-Nodes wird dann via SSH Zugang zum System respektive den jeweiligen Modulen gewährt, eine Inegration in bestehende Umgebungen erfolgt ebenfalls.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.