AMD MI300A & MI300X: Die neue Instinct-Serie ist ein Meilenstein in vielen Bereichen

Mit der neuen Produktreihe Instinct MI300A/MI300X geht AMD den Platzhirsch Nvidia an und will dank Modularität mitunter sogar mehr bieten. Die Einzelteile aber auch das Gesamtkonstrukt sind dabei mitunter ein Novum in vielen Bereichen und technisch überaus interessant, denn sie bedienen sich an vielen Errungenschaften.
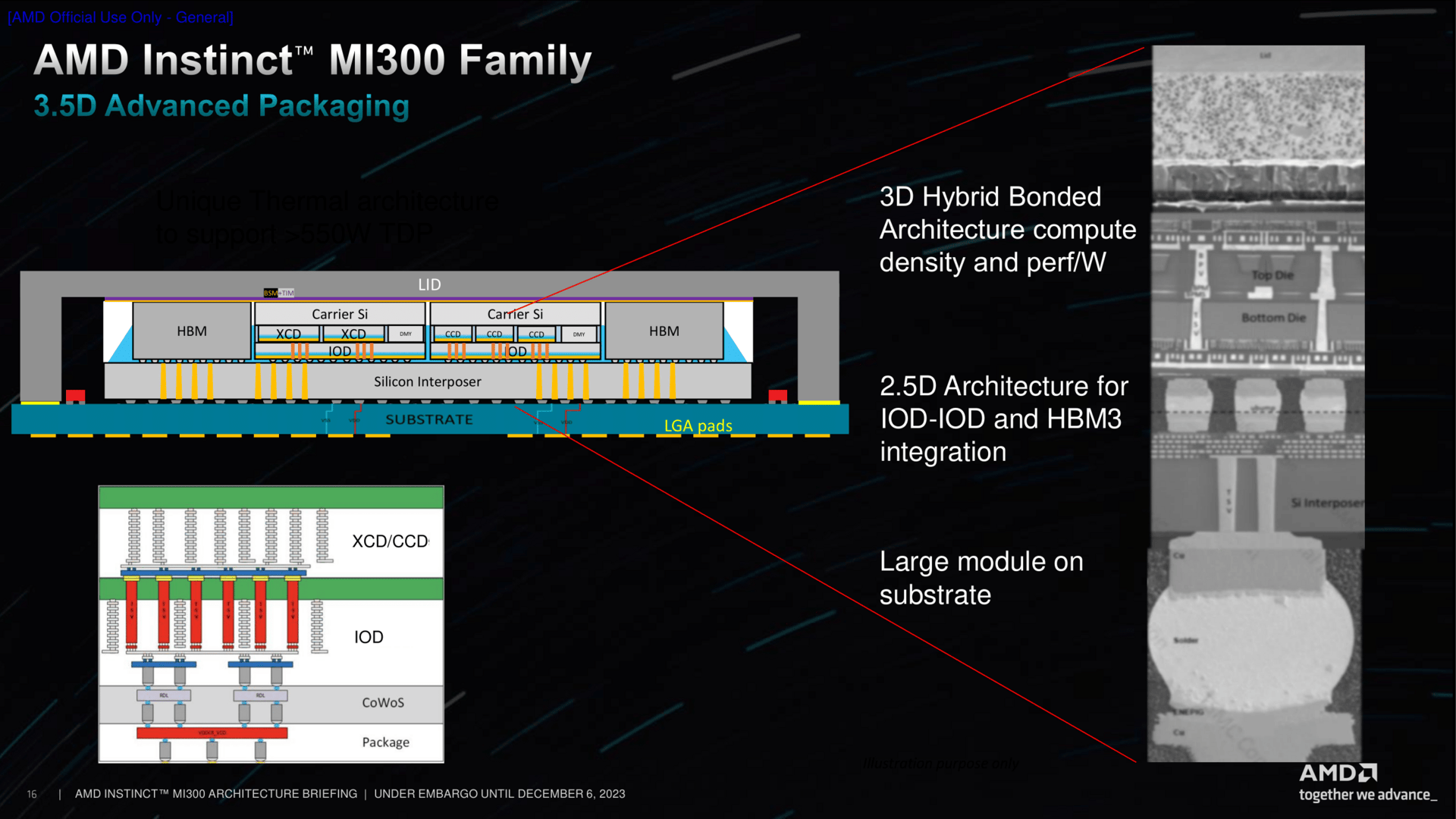
MI300 ist ein Beschleuniger für das HPC-Umfeld und insbesondere auch für das aktuell boomende Geschäft mit dem Thema Künstliche Intelligenz (AI). Dafür kommen nicht nur Anpassungen bei bereits bekannten Architekturen zum Einsatz; das Ganze wird auch in einem sogenannten 3,5D-Package verpackt. Dieser Chiplet-Ansatz soll unter anderem dabei helfen, die Leistung/Watt-Gleichung und damit die Energieeffizienz optimal zu gestalten. Dafür nutzt AMD das bekannte 2,5D-Chip-Design, wie es bereits seit Jahren in Form von Grafikchips mit direkt daneben liegendem HBM zugegen ist, setzt aber mit dem zusätzlichen 3D-Stacking nicht nur sprichwörtlich noch einen oben drauf, sodass das fertige Produkt nun auf 3,5D-Stacking setzt.
Der grundlegende Aufbau von MI300
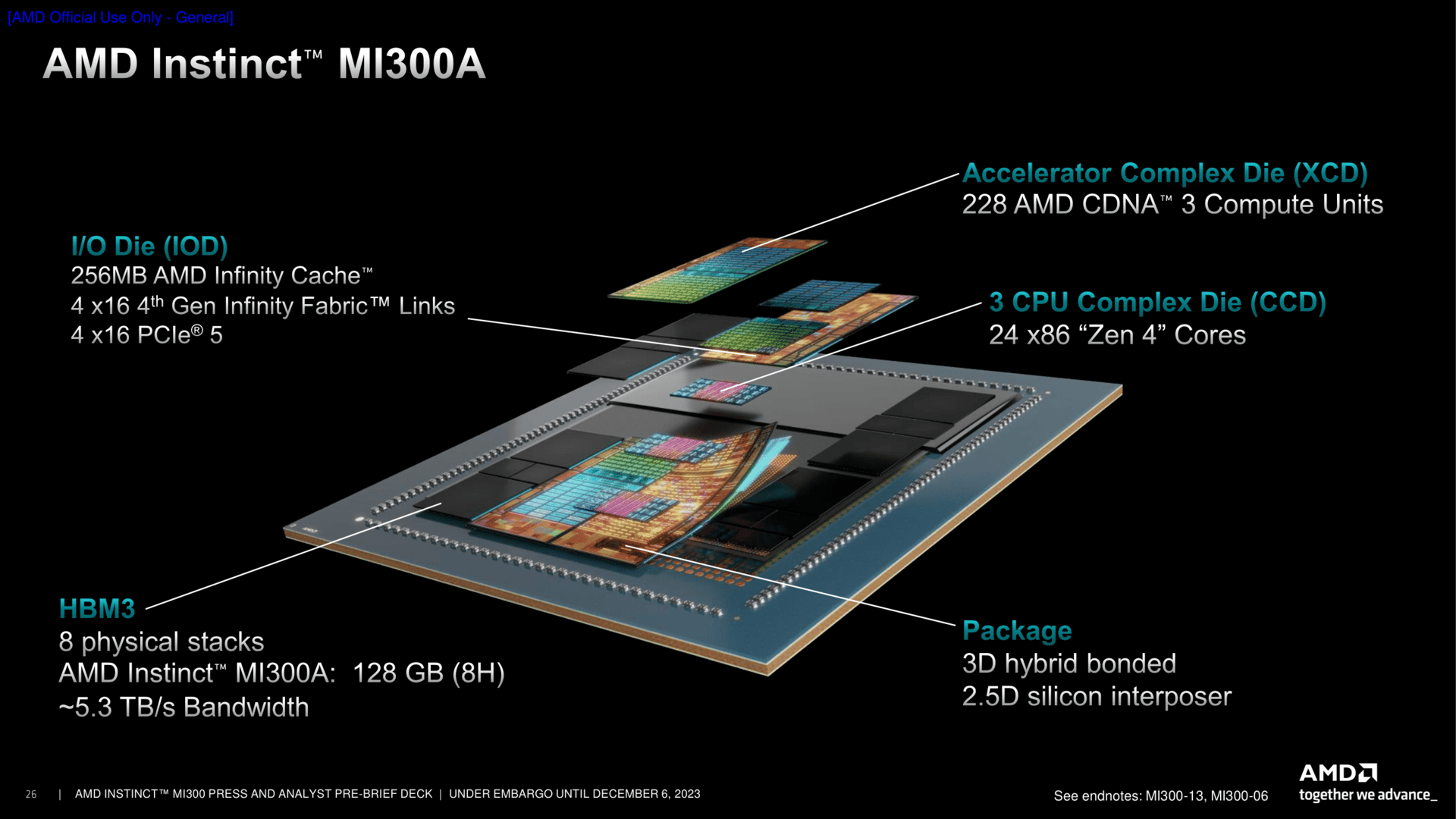
Die Basisplatte, wenn man es so sagen möchte, ist der IO-Die. Vier davon liegen nebeneinander, was zusätzliche Möglichkeiten bietet, aber auch Herausforderungen nach sich zieht. So gibt es kombiniert 128 HBM-Kanäle, 256 MByte Infinity Cache und auch PCIe-Lanes satt. Ein zusätzlicher Infinity Fabric AP (Advanced Packaging) Interconnect Controller wurde nun aber nötig, um die IODs untereinander kommunizieren zu lassen.

Für MI300 musste AMD den GPU-Teil umbauen. Heraus kommt ein Accelerator Complex Die (XCD). Sechs davon, jeweils zwei pro Chip, sind in der APU-Standardausführung zugegen. Der GPU-Teil bietet 38 CUs, aus Yield-Gründen geht AMD hier nicht ans Maximum. Die Basis ist die CDNA3-Architektur, die gegenüber dem Vorgänger einige Optimierungen bietet, insbesondere für den AI-Bereich wie Low Precision Ops FP16 und FP8. Vergrößerte Puffer, verdoppelte L1-Caches und mehr runden das Paket für deutlich mehr Leistung vs. MI200/MI250 ab. Viel weiter in die Details der CDNA-3-Architektur steigt AMD heute aber nicht ein.


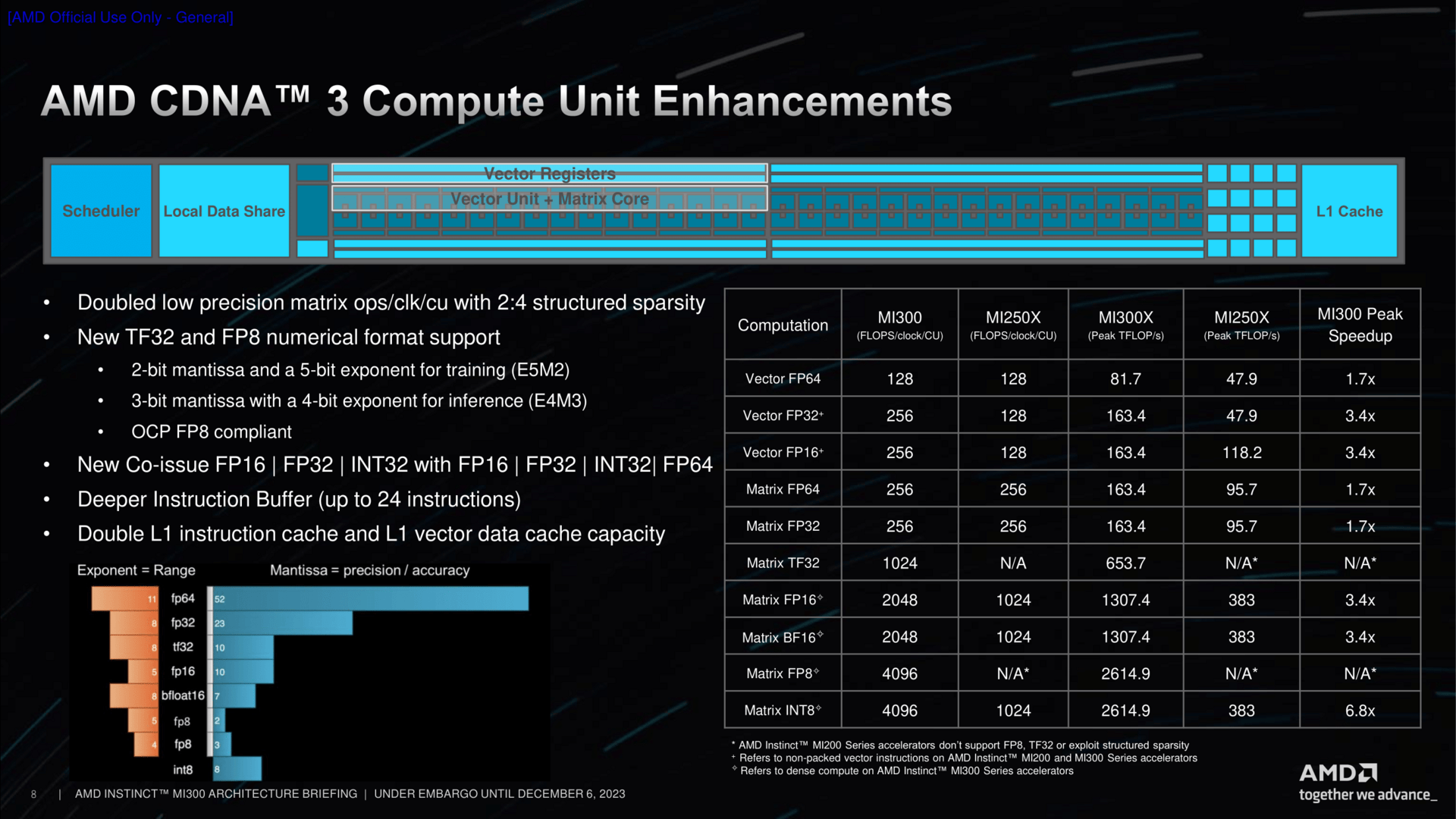
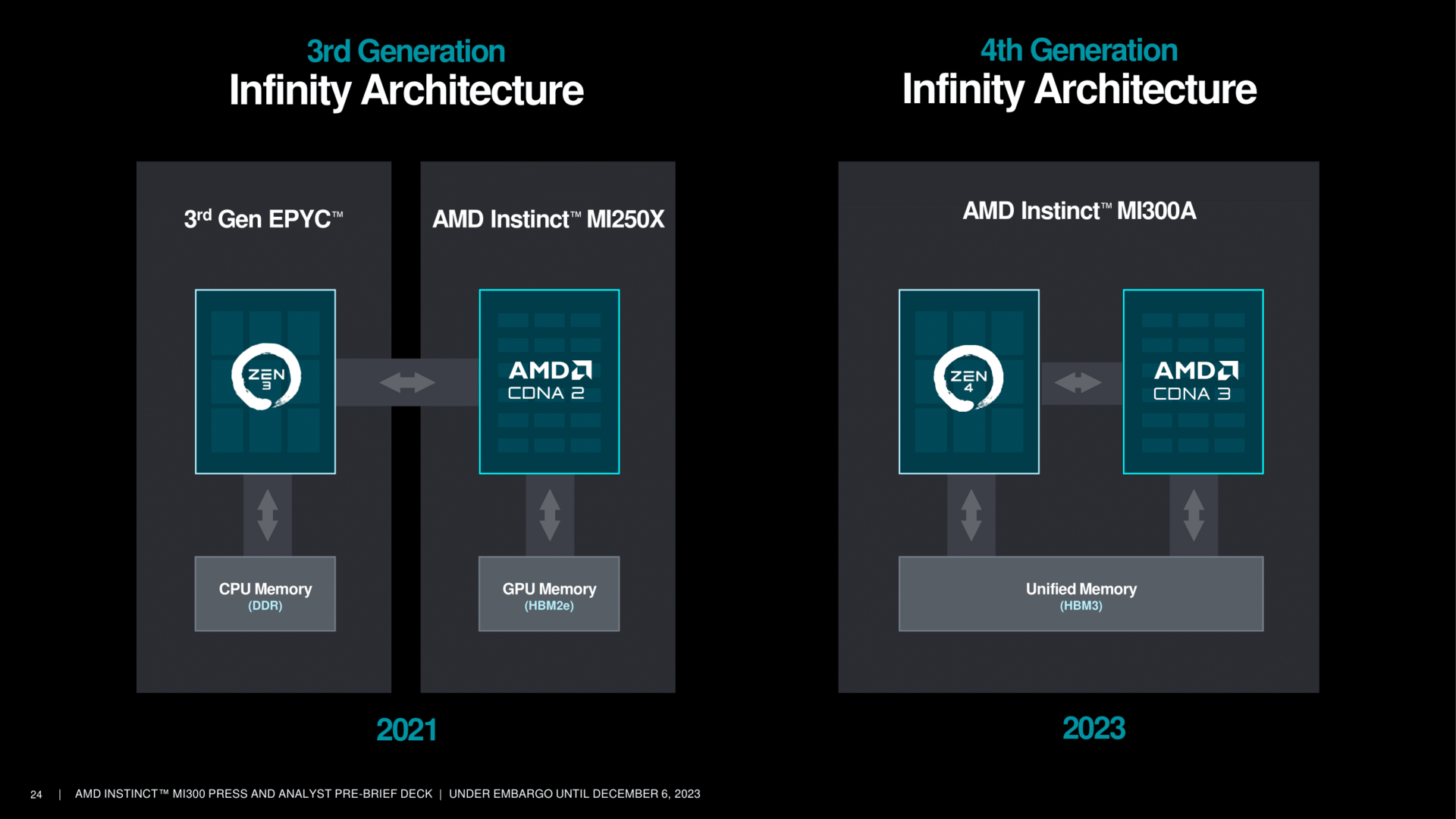
Der Zen-4-CCD ist ein ziemlicher bekannter, er ist auch der gleiche wie in den aktuellen Epyc-Prozessoren. Doch statt über GMI mit den anderen CCDs zu kommunizieren, nutzt er nun ein direktes Interface über Hybrid Bonding zum darunter liegenden IO-Die. Diese Schnittstellen sind auf dem CCD bereits seit dem Start vertreten, im Schaubild als BPV unter anderem zwischen den GMI-Links dargestellt. Dadurch bekommt der CCD auch Zugriff auf die nächste Cache-Stufe, den Infinity Cache, um Daten nicht nur schnell zwischen den CCDs sondern auch zu den XCDs zu transferieren. Ein zusätzlicher Prefetcher soll dabei helfen, die Latenzen vom CCD in Richtung des HBMs zu minimieren.

Das Speichersystem ist ein grundlegend Neues. Dem Infinity Fabric auf dem Chip, dargestellt in den bunten Linien, kommt dabei eine gewichtige Aufgabe zu. Seine Bandbreite liegt auf exakt gleichem Niveau wie die der XCDs. Zwei XCDs sind je mit einem IO-Die verbunden, der wiederum spricht zwei HBM-Chips an. Daraus ergeben sich die aufsummierten Speicherkanäle und die Speichermenge für MI300X, bei MI300A entsprechend in der kleineren Stack-Variante etwas weniger.


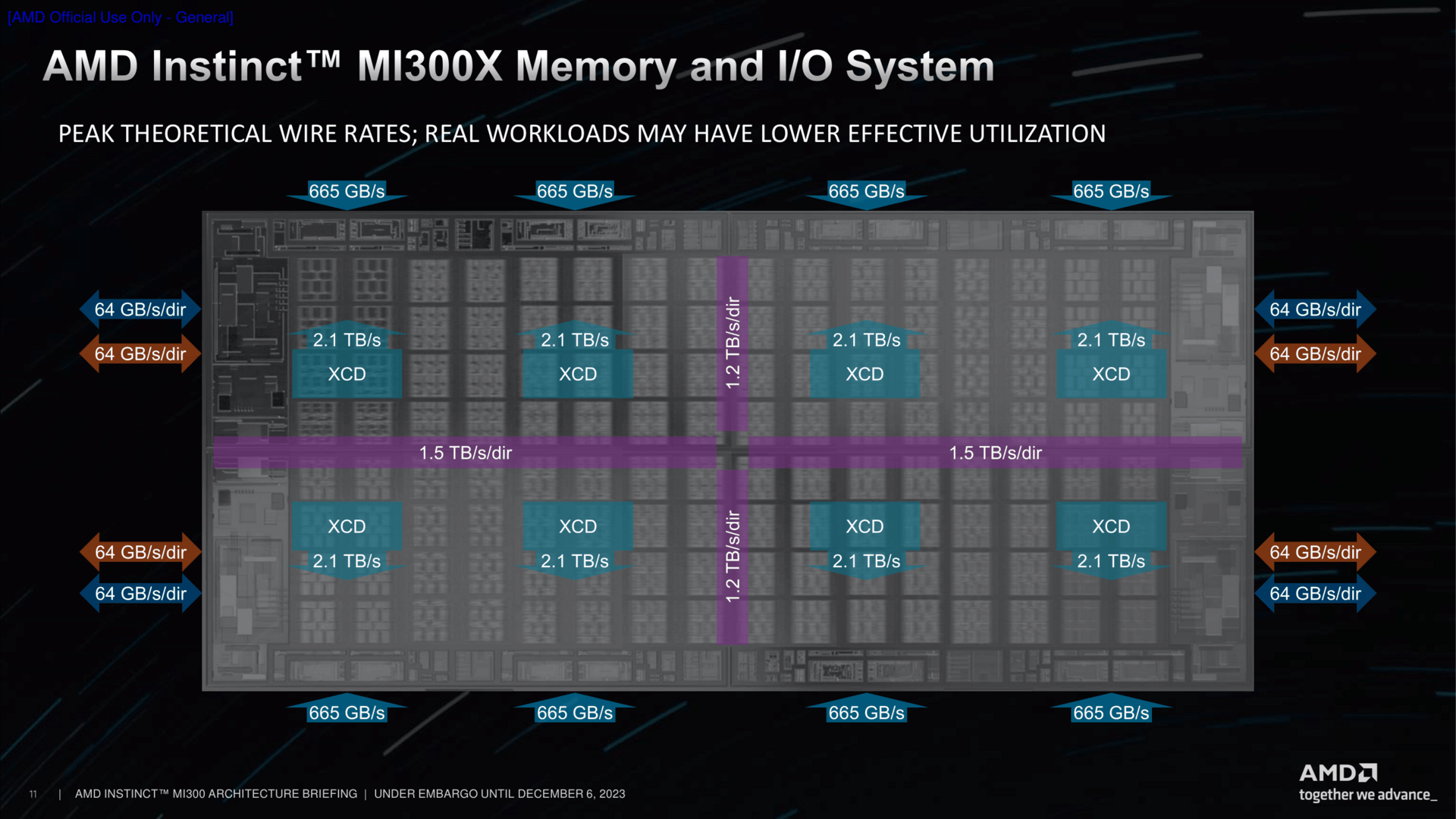
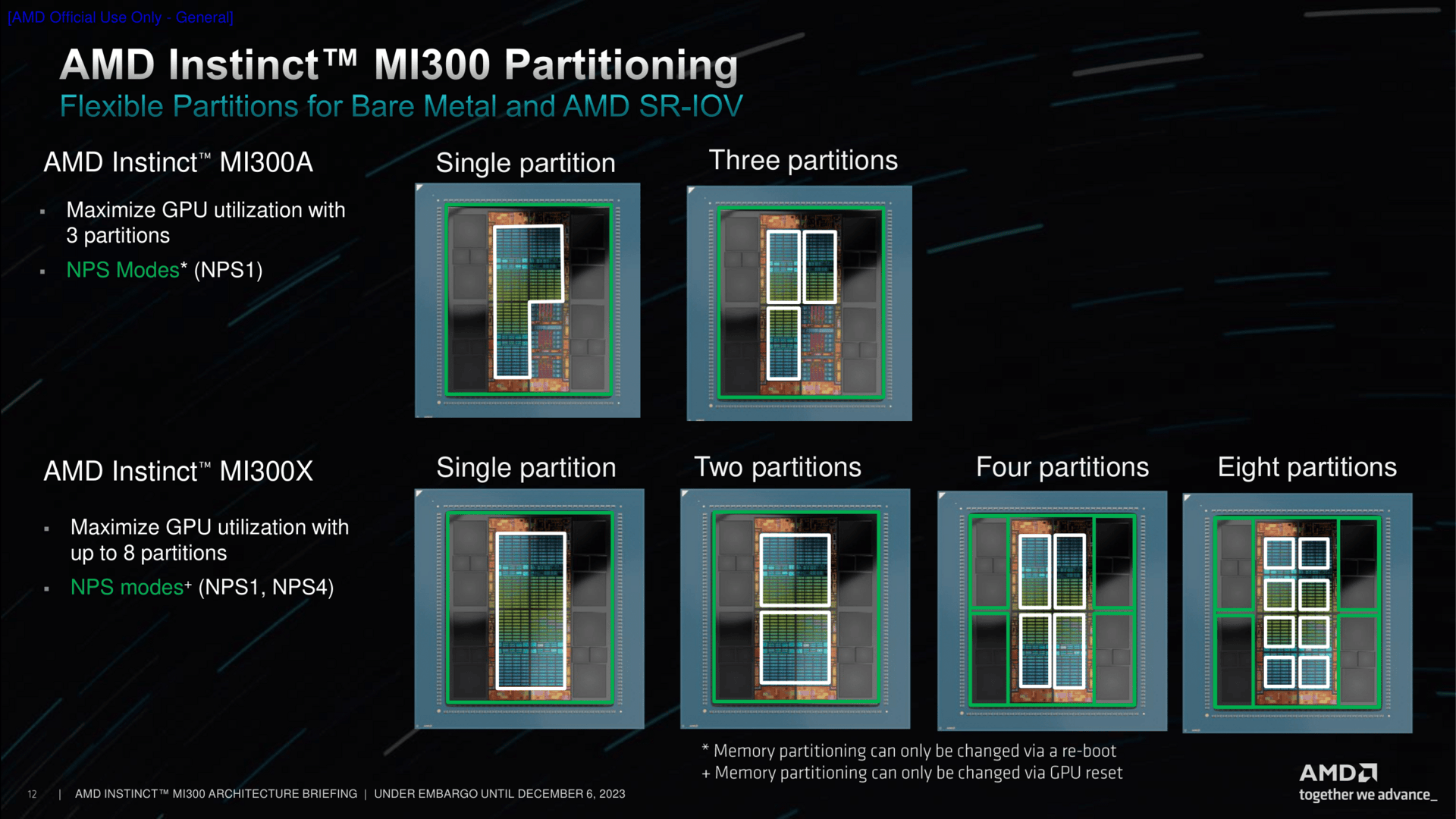
Im Einsatz kann ein MI300 dann je nach Zweck unterschiedlich konfiguriert werden. Bei der APU-Variante ist dies ziemlich einfach: Entweder arbeiten alle CUs zusammen oder jeweils zwei XCDs werden getrennt angesprochen.
Genau dort setzt MI300X dann an. Hier gibt es alle Varianten von einer riesigen GPU, wo quasi alle XCDs zusammengeschaltet sind, bis hin zur einzelnen Partitionierung pro XCD.
3D-Stacking in höchster Form
Packaging ist einmal mehr ein großes Thema bei AMD. Mit dem 3D-V-Cache-Stacking auf einen bestehenden CCD hat sich AMD vor einigen Jahren das erste Mal einen Namen gemacht. Das Konzept wurde in zweiter Generation nach Milan + Ryzen 5000 bei Genoa + Ryzen 7000 wiederholt, war dort aber faktisch nur eine etwas optimierte Variante. Die gesammelte Erfahrung von der Produktion bis hin zum Channel fließt nun in die MI300-Serie ein. Denn MI300 funktioniert ohne das Stacking schließlich nicht.
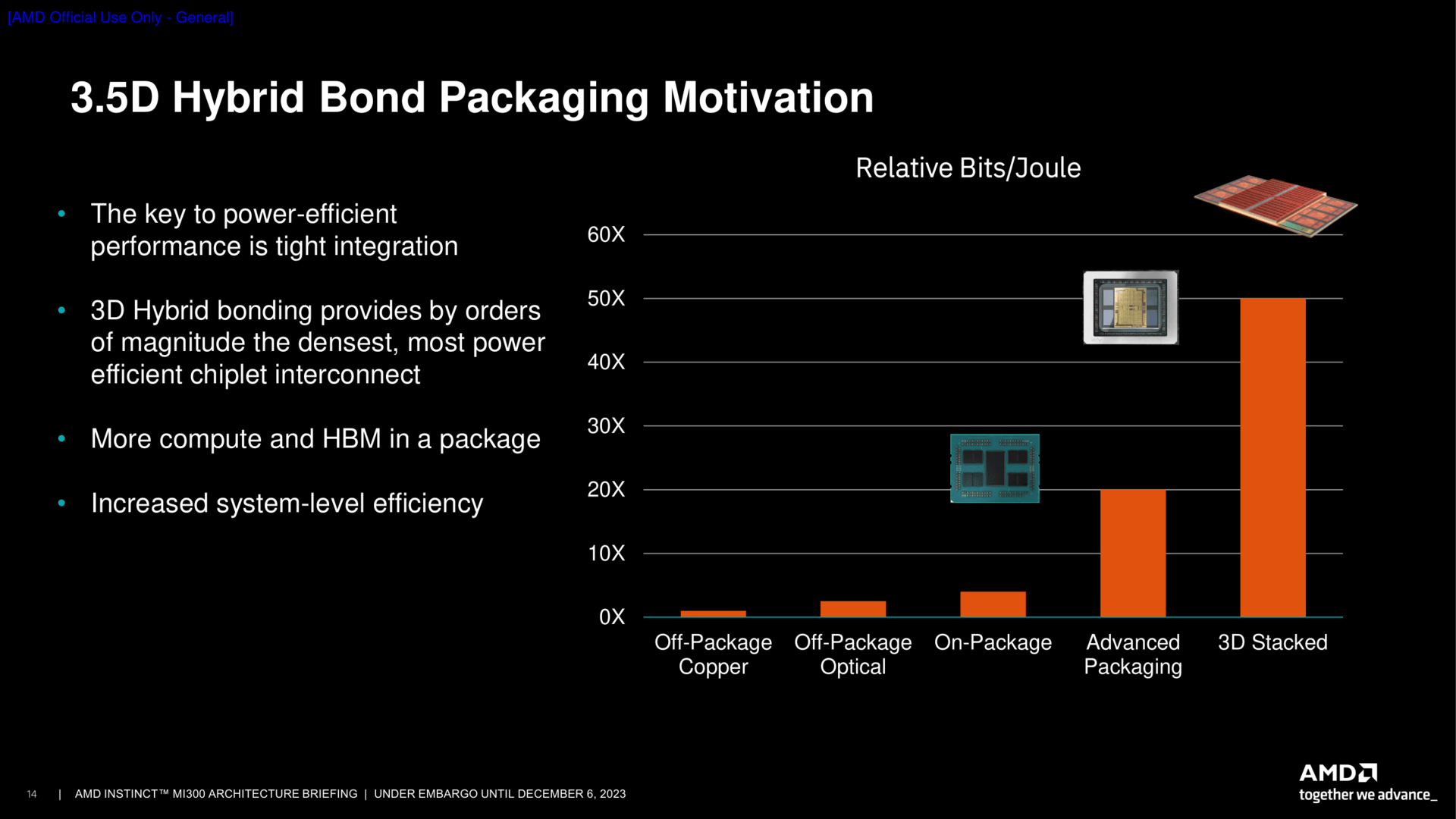
Die Basis für das Stacking ist TSMCs SoIC-Technologie, eben genau so wie beim 3D-Cache, aber auch CoWoS (Chip-on-Wafer-on-Substrate) wie bei klassischen GPU-Lösungen. Bei SoIC schultern TSVs die Arbeit, denn es werden zwei Chips mittels Durchkontaktierung verbunden. Anders als beim 3D-Cache sitzt der wichtigere Chip nun aber nicht mehr unten und der Zusatz oben drauf, sondern umgekehrt. Das hilft unter anderem in einem Punkt: Wärmeabgabe. Denn das, was die wesentliche Arbeit macht, sitzt nun näher am Kühler, der dann aufgesetzt wird.
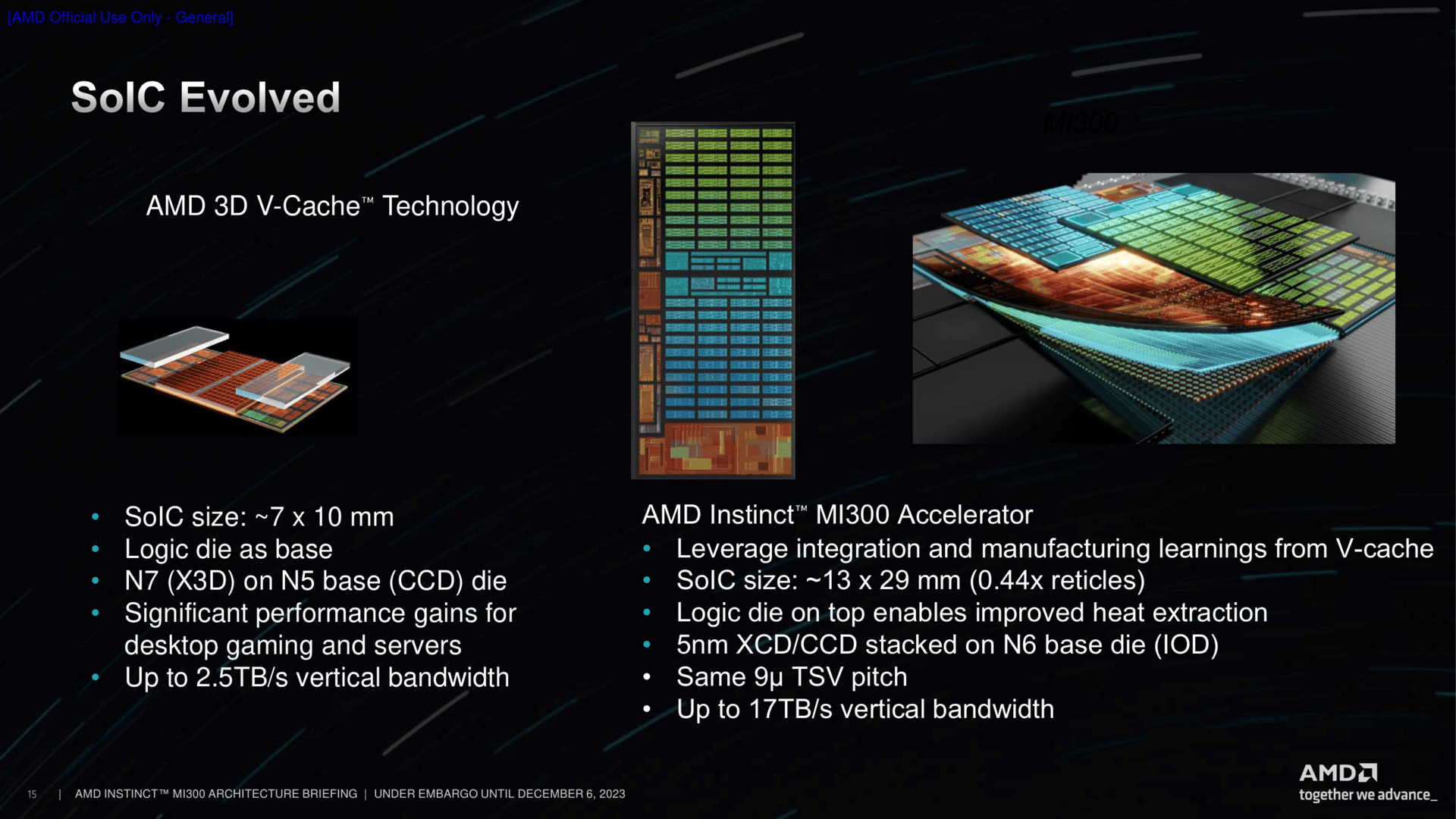
Der Logik-Chip obendrauf ist in seinen Ausmaßen mit dem bisher bekannten 3D-Cache nicht mehr vergleichbar. Aus 70 Quadratmillimetern in Form eines kleinen Rechtecks ist nun ein 5,4 Mal so großer Chip von 13 mm × 29 mm Fläche geworden. Dieser basiert auf TSMCs N5-Technologie, der darunter liegende IO-Die ist in N6 gefertigt – also exakt so, wie bisher beispielsweise bei Genoa auch. Die Bandbreite zwischen den beiden Chips liegt nun bei bis zu 17 TByte/s, sieben Mal mehr als bei den bisherigen 3D-Cache-Adaptionen.
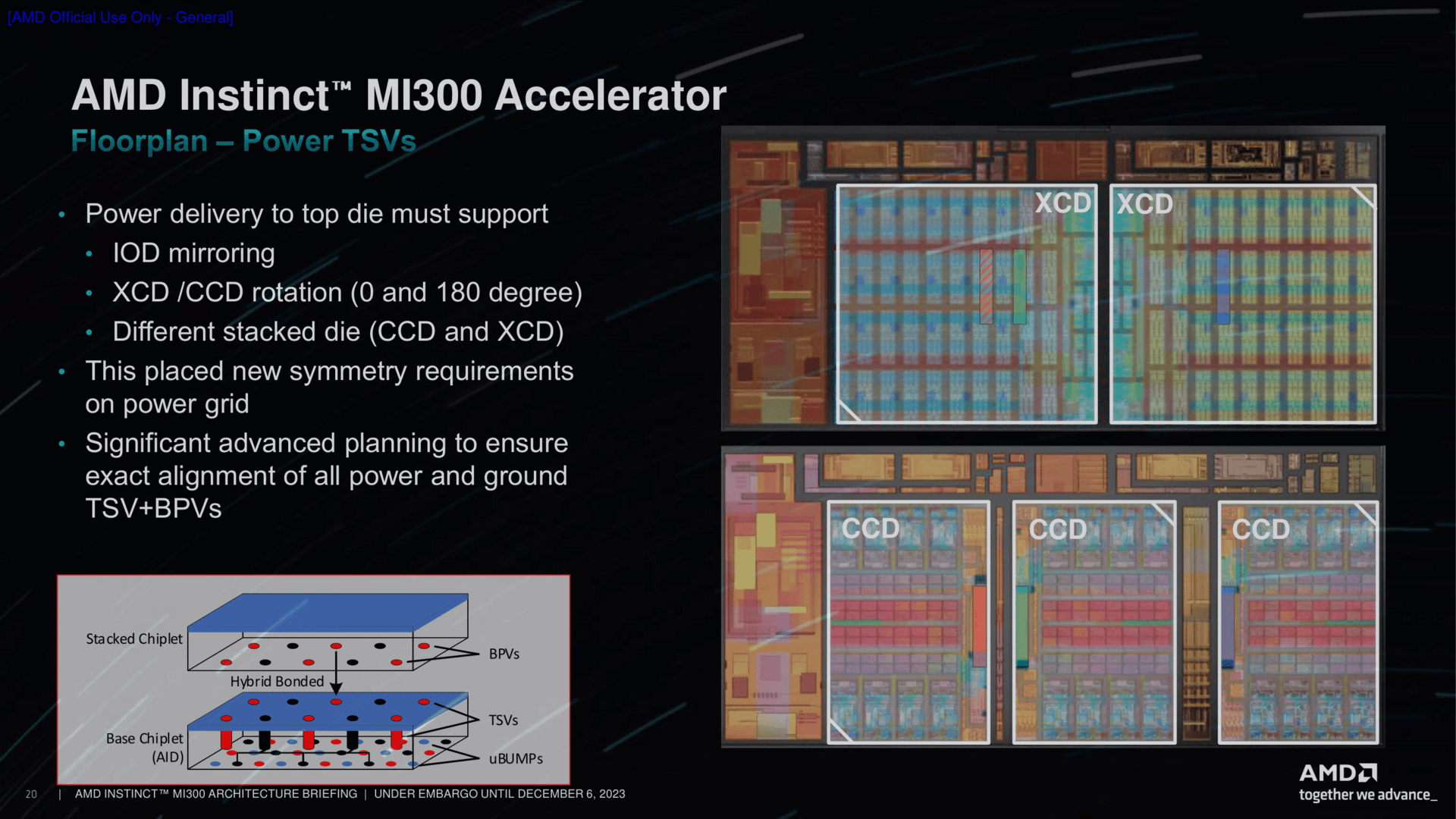
Dabei ist das Lego-Prinzip, wie auch AMD es hier und da gerne nennt, eben spielerisch fast am einfachsten zu erklären. Die CCDs besitzen beispielsweise mehrere Stellen, die als Bond Pad Via (BPV) zum darunter liegenden IOD fungieren. Da ein CCD und auch XCD aber nur gedreht (rotated) und nicht gespiegelt werden kann, muss die Bodenplatte alias IOD entsprechend an den Stellen vorbereitet sein. Der IOD ist dabei jedoch soweit flexibel und kann auch gespiegelt (mirrored) sein, sodass am Ende durch diese Option die passenden Stacks – egal ob CCD oder XCD – obendrauf gesetzt werden können.


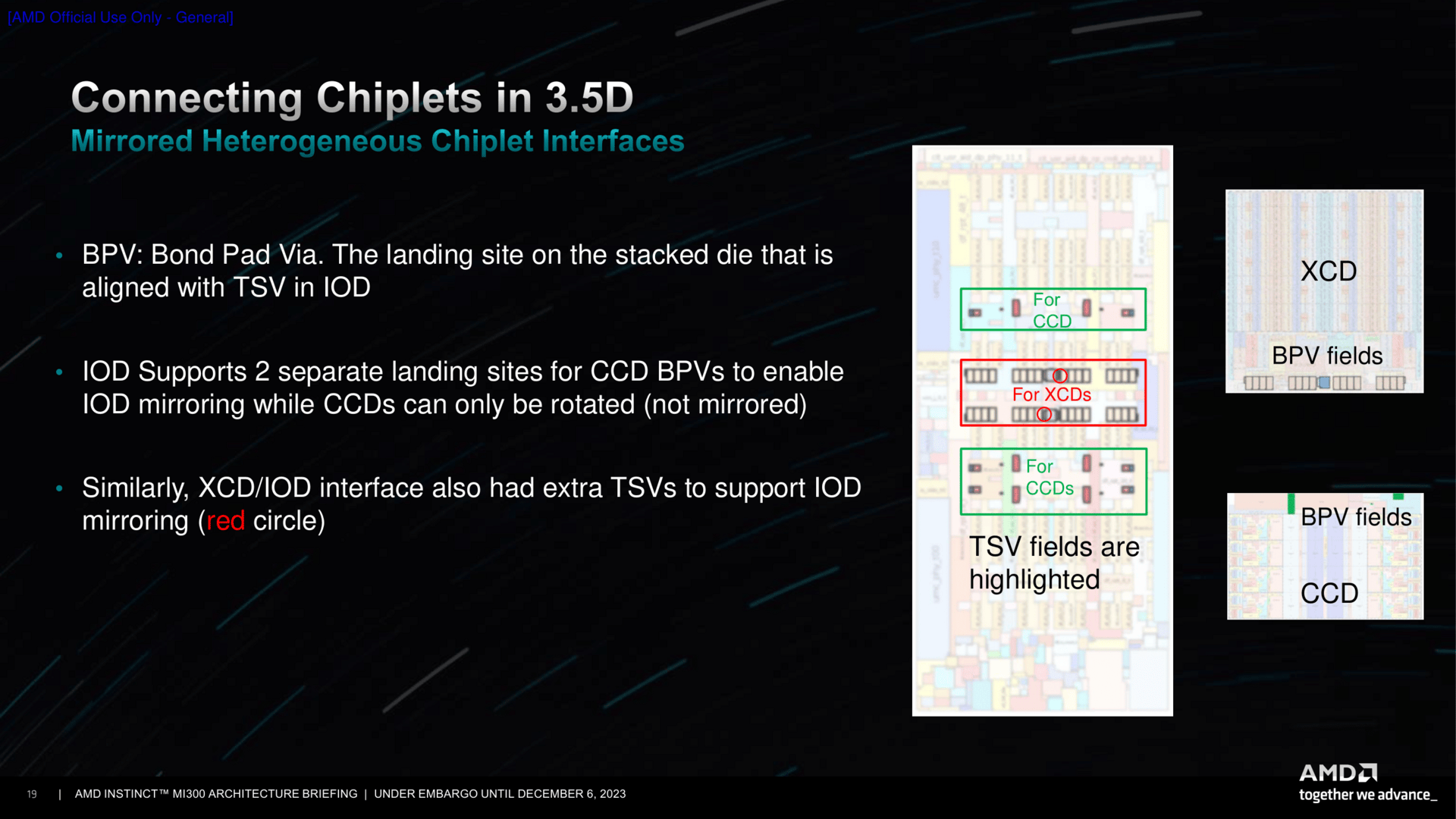
Dieses Dreh- und Spiegel-Prinzip ist keine Neuheit, wird in der Chiplet-Ära jetzt aber auf die Spitze getrieben. Intel kommt um derartige Maßnahmen natürlich auch nicht herum, dort sind Tiles auch gerne einmal gedreht und mitunter auch gespiegelt. Denn nur so lassen sich bestimmte Dinge wie Interface und Zugang zum Speicher optimieren, vor allem aber die Kommunikation der Chips untereinander verbessern.
Zwei Varianten jetzt, in Zukunft vielleicht eine dritte?
Der Fokus zum Start liegt auf MI300X und MI300A. Der eine als klassischer Beschleuniger, der andere wiederum als große APU, bei dem die Beschleunigerlösung ihren benötigten Prozessor gleich mitbringt.
MI300X als beste AI-Beschleunigerlösung
MI300X ist der klassische GPU-Beschleuniger. Viele CUs, eine Menge schneller Speicher und eine TDP von 750 Watt sollen hohe Leistung bieten.

Ein MI300X wird in der Regel nie allein unterwegs sein, sondern in einem Verbund von acht Stück beispielsweise auf einer OCP UBB Platform. Aber auch PCIe-Lösungen könnten später folgen – ähnlich also wie Nvidia bei der Hopper-Generation. Aktuell bleibt hier aber erst einmal die MI210 als PCIe-Karte weiterhin gesetzt. Zu mehr Details in dieser Richtung ließ sich AMD nicht bewegen.
-
 AMD-CEO Lisa Su mit Instinct MI300X in achtfacher Ausführung
AMD-CEO Lisa Su mit Instinct MI300X in achtfacher Ausführung


MI300A als APU für ein breites Spektrum
Mit der Variante MI300A entdeckt AMD seine Liebe zur APU völlig neu. Ausgelegt auf einen Spielraum von 550 bis 760 Watt werden diese Lösungen drei Zen-4-CCDs mit jeweils acht Kernen mit sechs XCDs verbinden. Die CPU-Kerne takten dabei mit 3,7 GHz erklärte AMD. Die GPU taktet im besten Fall mit 2.100 MHz, die HBM-Chips arbeiten mit 5,2 GT/s.

Durch die neue Generation Infinity Fabric werden Speicherzugriffe minimiert, was zur erhöhten Effizienz beiträgt. Die Mischung von CPU, GPU und HBM in einem Chip soll am Ende je nach Test extrem gut funktionieren, im besten Fall erklärt AMD hier eine vierfache Leistung eines MI300A gegenüber Nvidias H100.


MI300C als optionale CPU-HBM-Kombination
Im Pre-Briefing kam selbstredend auch die Frage nach einer reinen Lösung nur mit CCDs auf. Das ist freilich direkt machbar, denn so wie sich bei MI300A ein XCD gegen das CCD-Paket tauschen lässt, wäre dies auch bei den anderen drei Feldern möglich. Doch bestätigen wollte das AMD explizit so heute noch nicht als Produkt.
Die Leistung ist laut ersten Tests sehr gut
Einige Benchmarks hat der Hersteller auch mitgebracht. Wie üblich sind diese mit Vorsicht zu genießen, schließlich sind diese sorgfältig ausgewählt und zeigen in der Regel die Stärken des Produkts. Der Lieblingsgegner ist Nvidias Hopper H100, in der ersten Form mit dem geringsten Speicherausbau. Dies darf schon als kleines Indiz gewertet werden, dass neuere Versionen mit mehr Speicher und vor allem dann H200 im nächsten Jahr vermutlich etwas besser dastehen dürften.
-
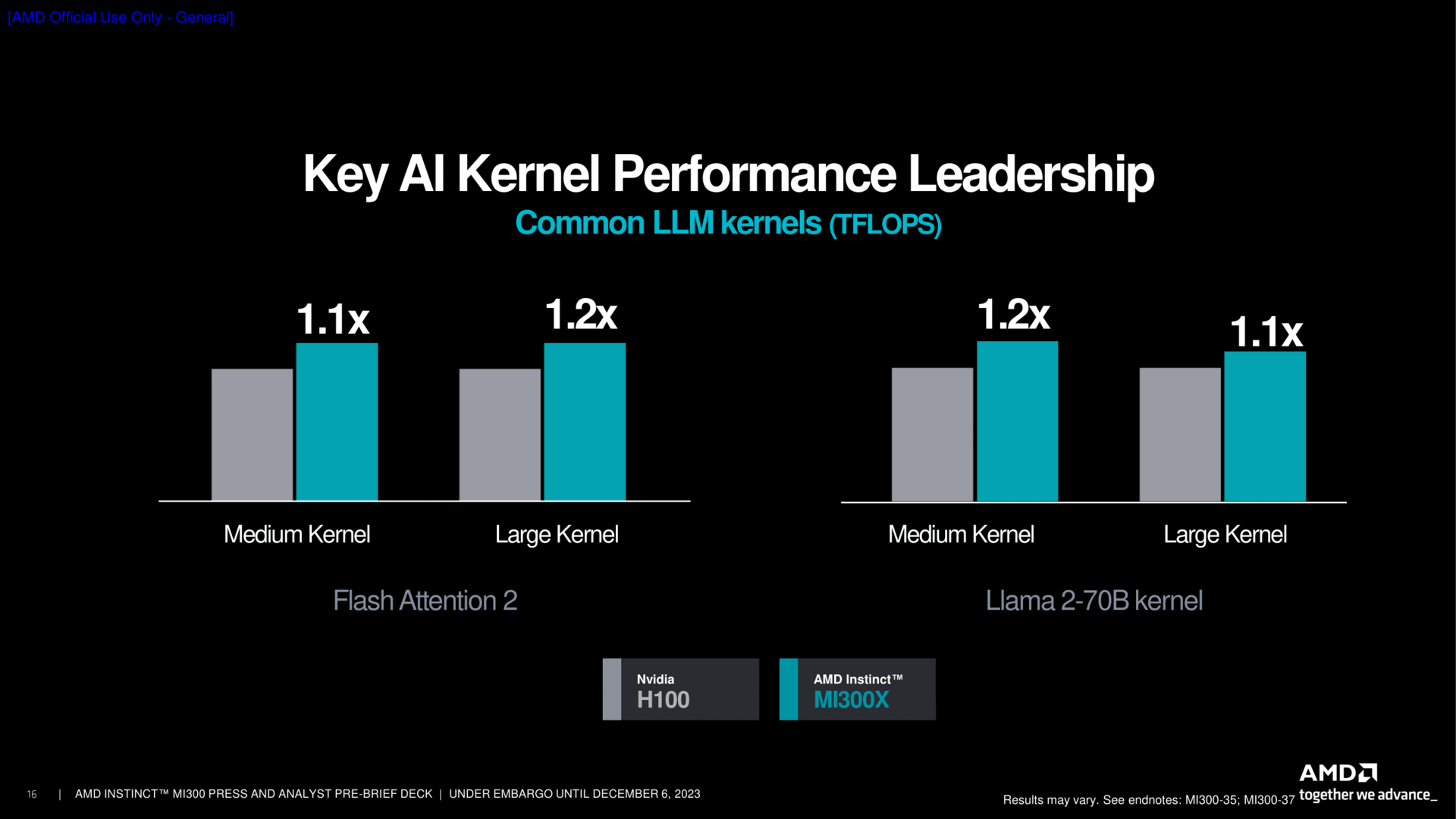 AMD Instinct MI300 Press Pre-Brief Deck (Bild: AMD)
AMD Instinct MI300 Press Pre-Brief Deck (Bild: AMD)
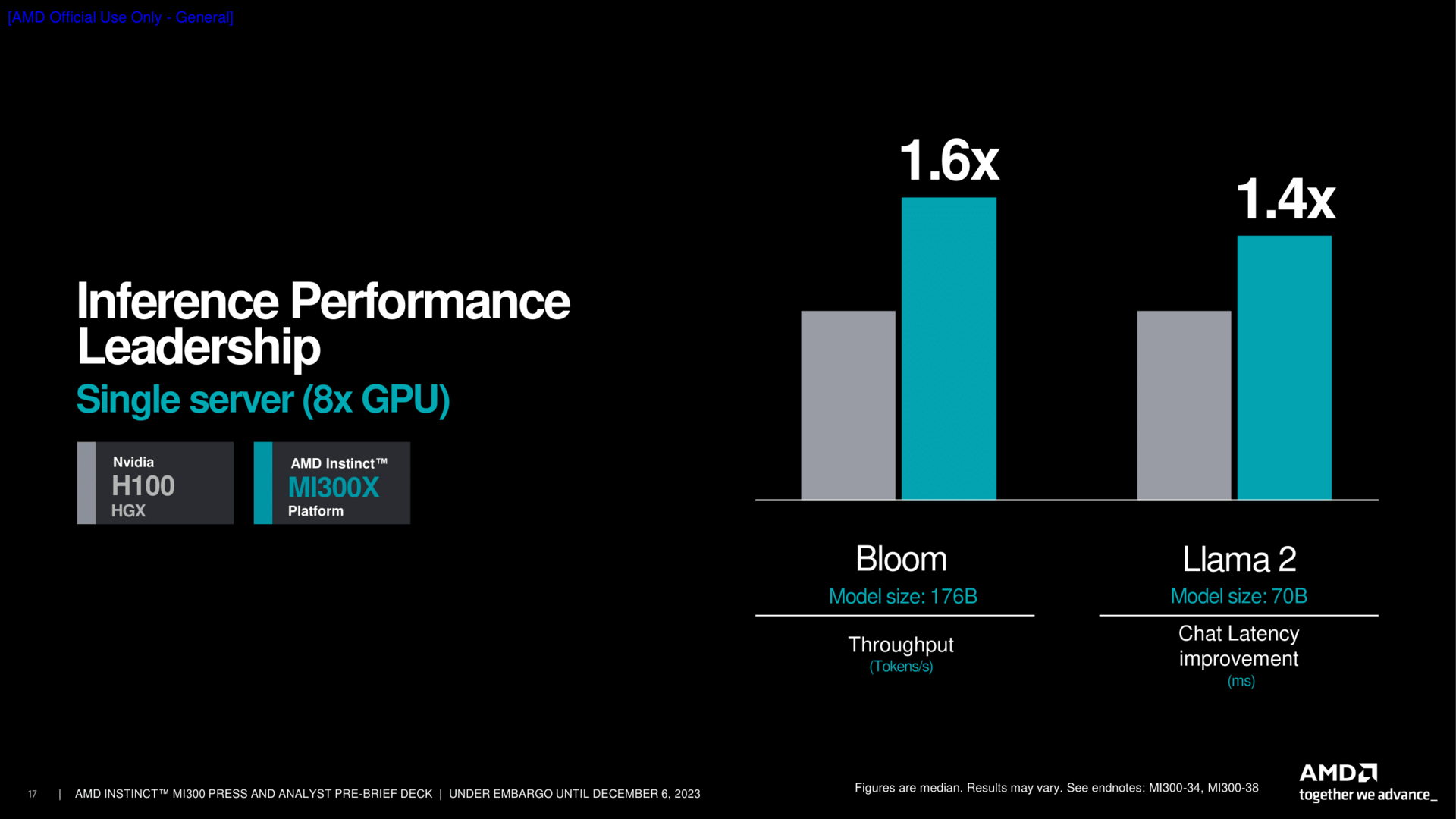
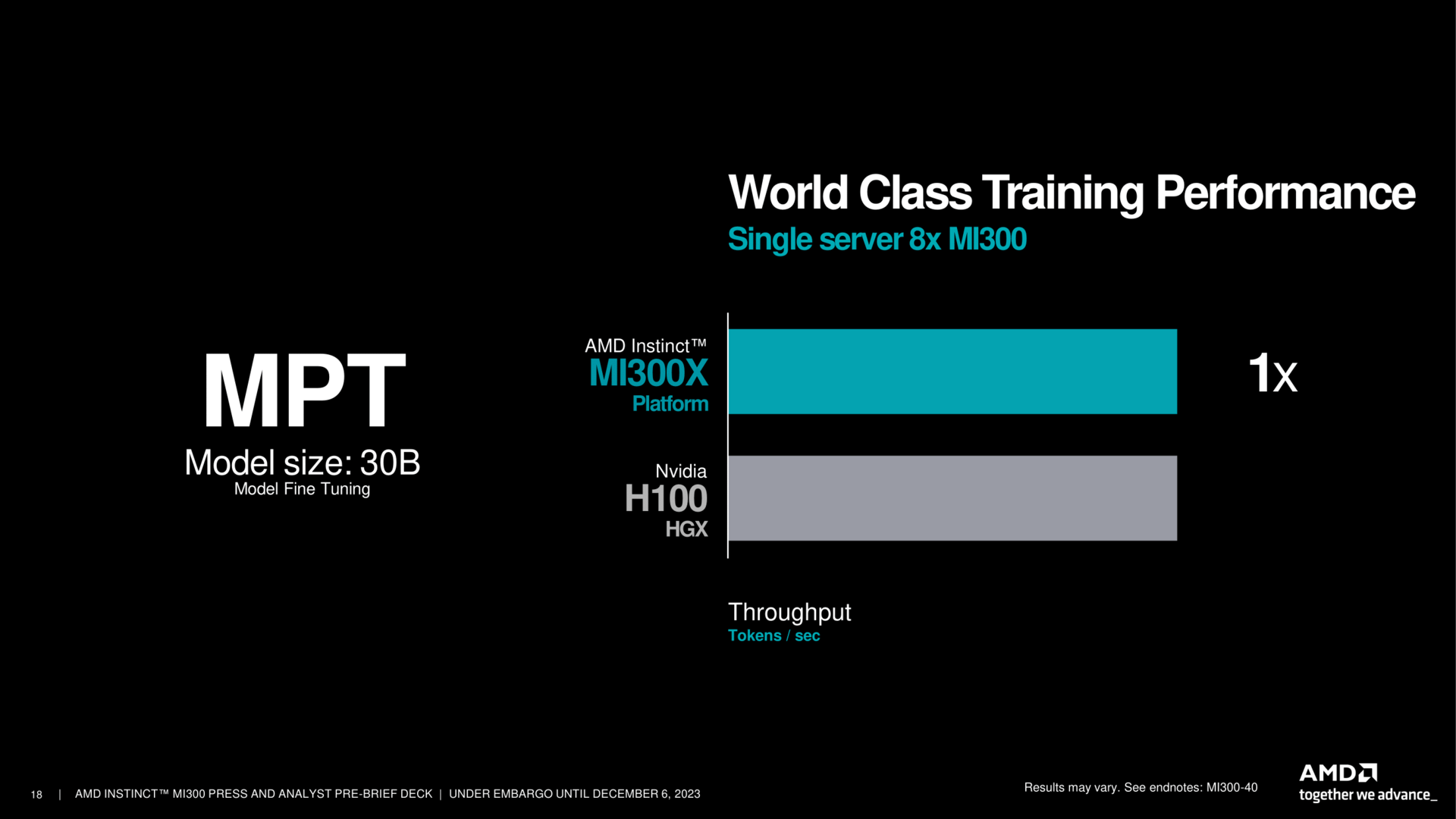

Die APU-Variante überrascht in einem Test, und hier hat sich AMD sogar Grace Hopper GH200 als Gegenspieler gesucht. Der Superchip von Nvidia feiert aktuell riesige Erfolge, da er ein sehr gutes Verhältnis aus Leistung zum Verbrauch bietet. Und exakt in dieser Position will AMD mit MI300A GH200 noch um den Faktor 2 übertreffen – das kam dann doch unerwartet.
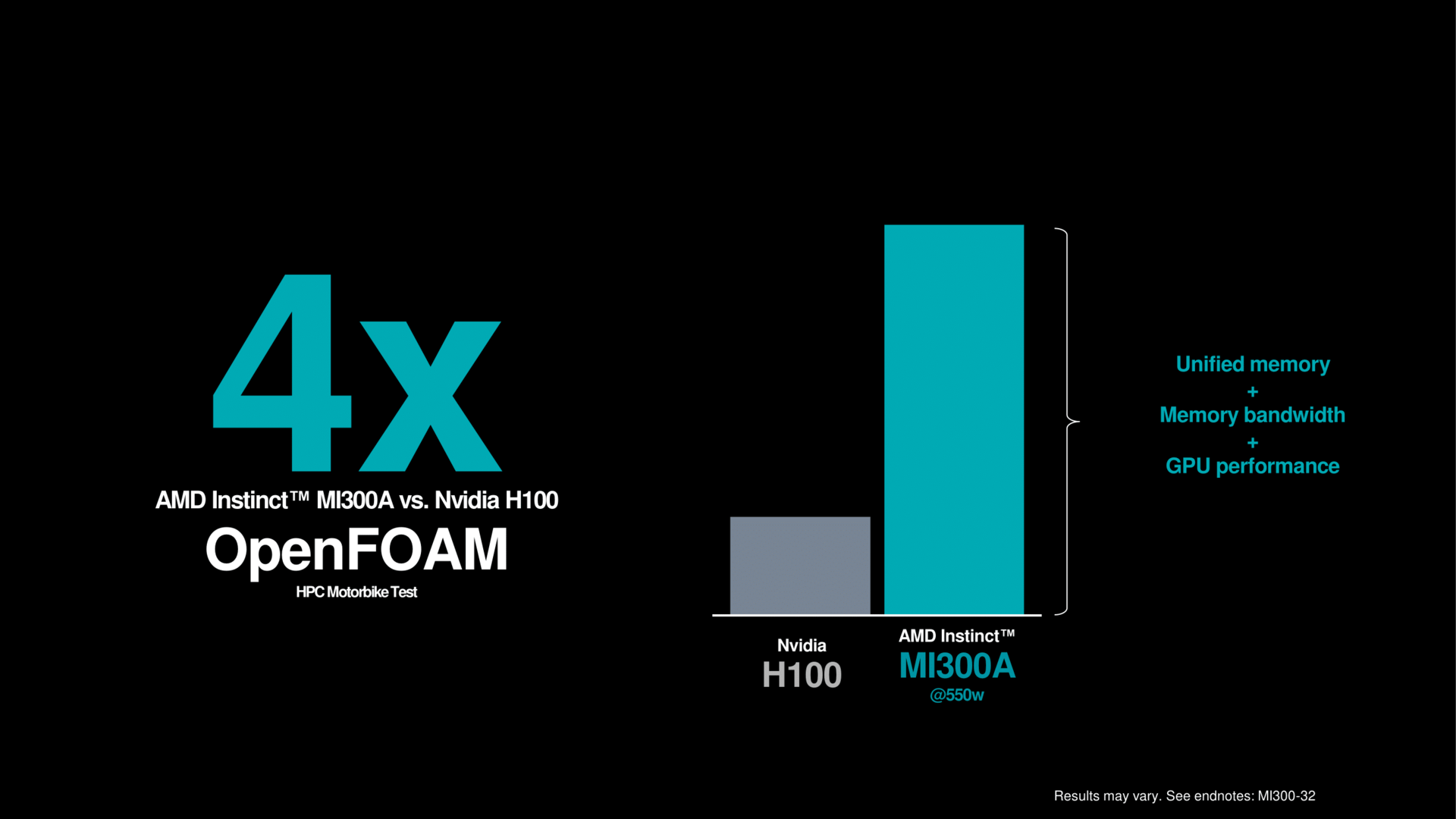
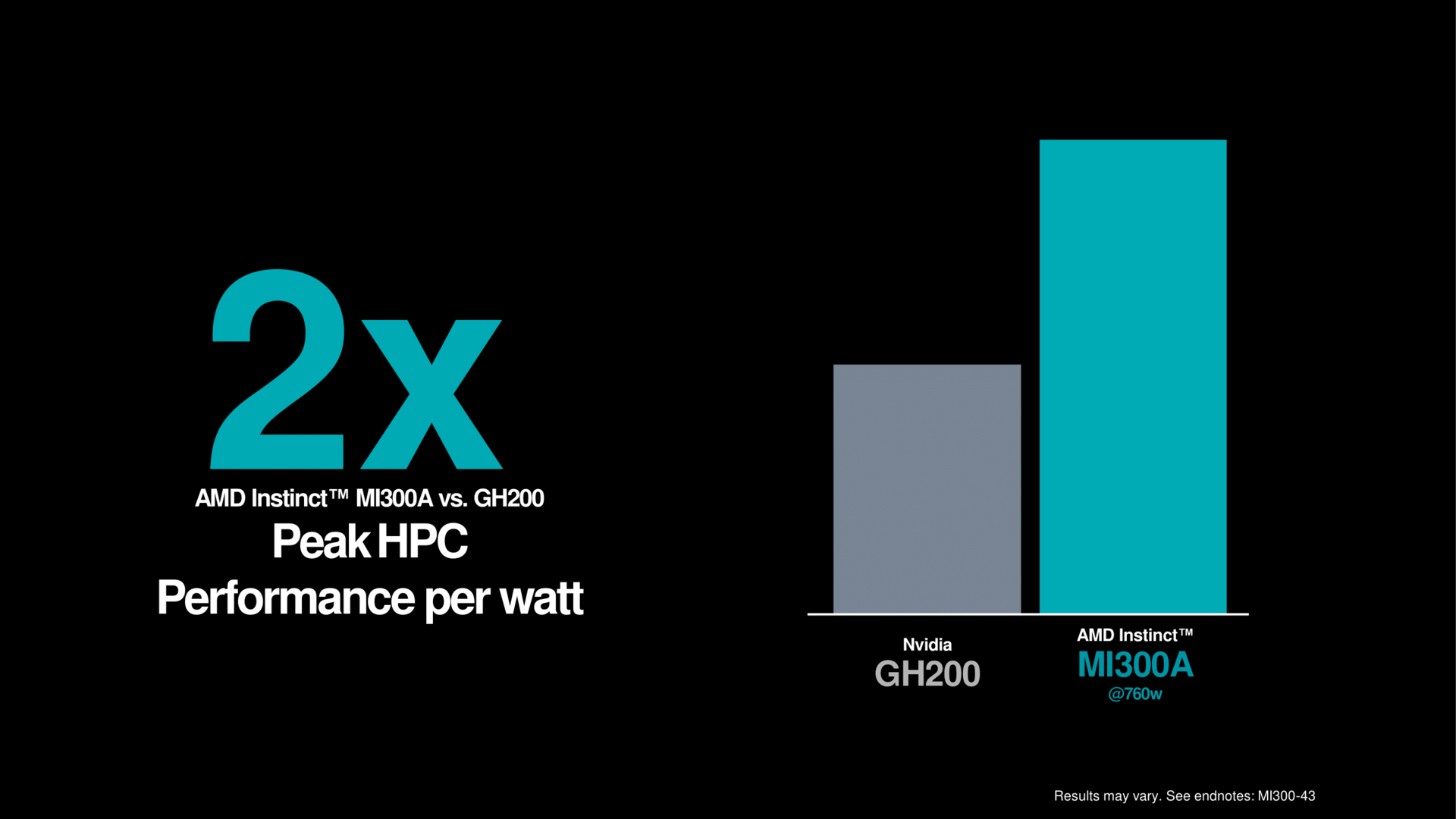
MI300A als riesige APU ist mit diesem überraschend guten Wert damit auch ein Aushängeschild für die ganze x86-Architektur kombiniert mit einer modernen GPU. Denn von einem Arm-Effizienzvorteil ist hier plötzlich nichts mehr zu sehen, alles geht schlichtweg auch mit einer ganz normalen Zen-4-CPU. Natürlich ist es am Ende aber das Komplettpaket, welches dieses Ergebnis aufstellt. Es verdeutlicht aber, in x86 plus Anhang steckt noch viel Potenzial.

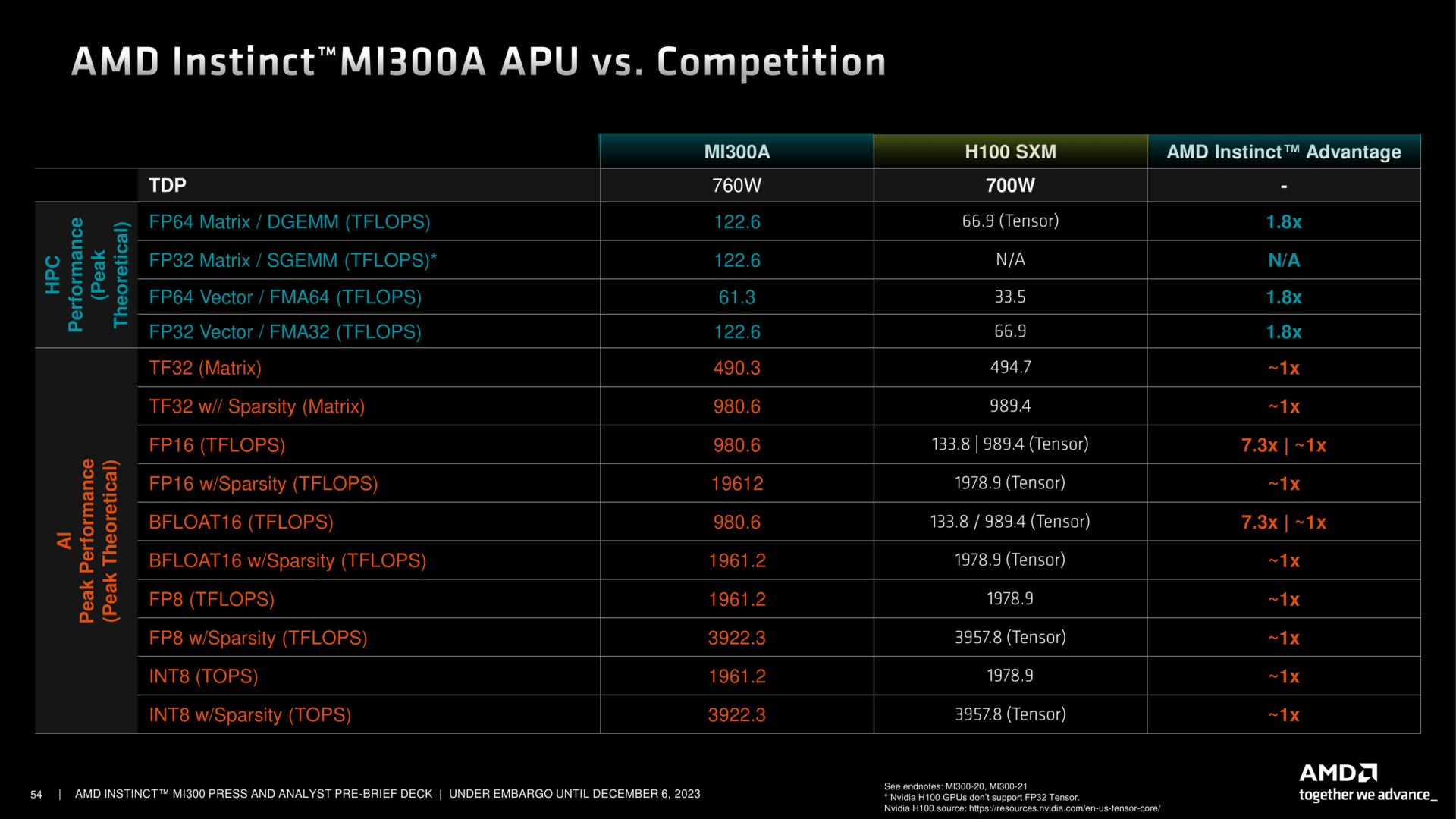
Große Schritte nach vorne macht AMD auch bei der Software. ROCm 6 führt die MI300-Serie in das Feld ein, stetige Aktualisierungen von ZenDNN und Vitis AI runden das Paket ab.
-
 ROCm 6 ist die Basis für MI300X
ROCm 6 ist die Basis für MI300X





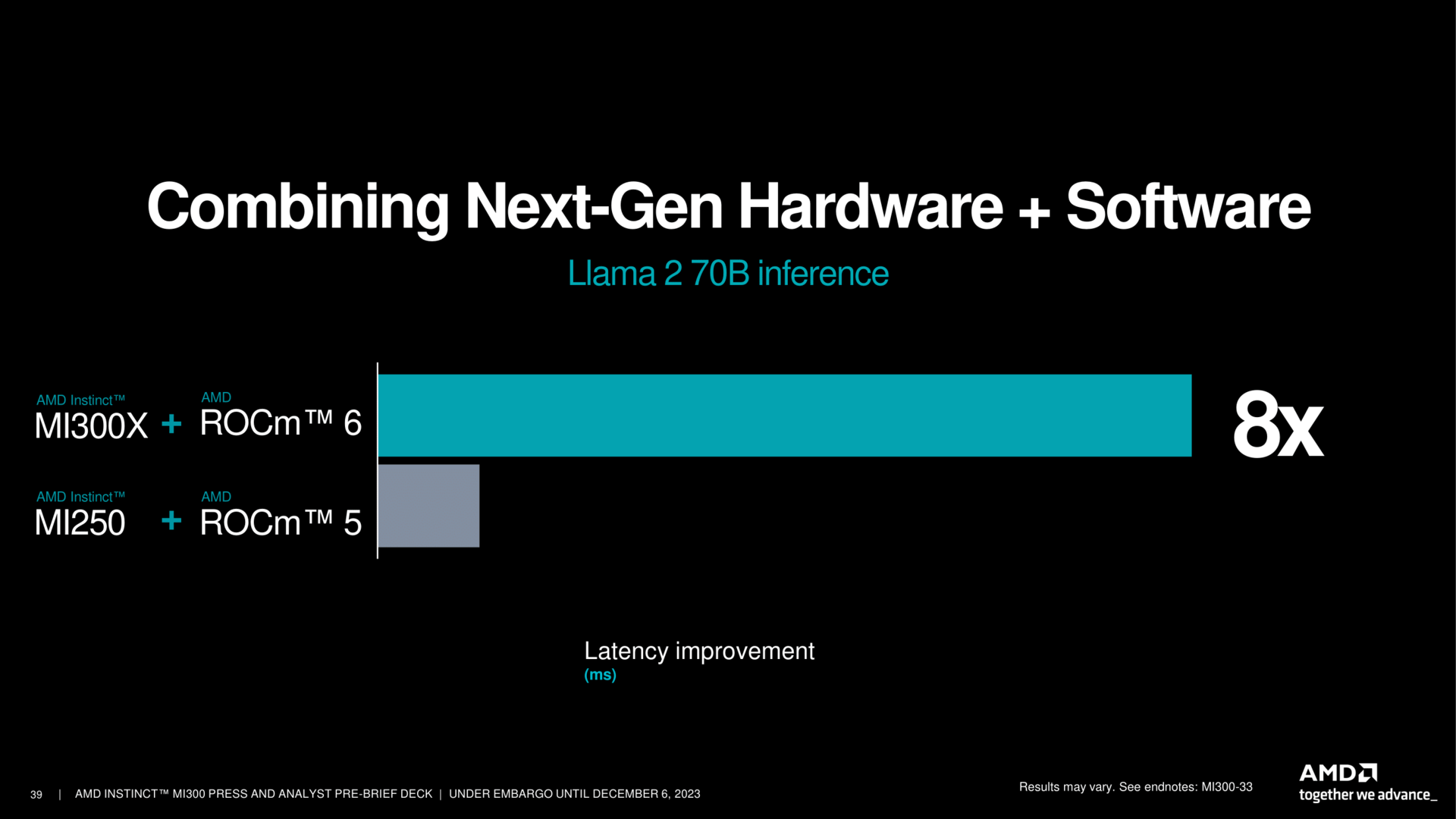
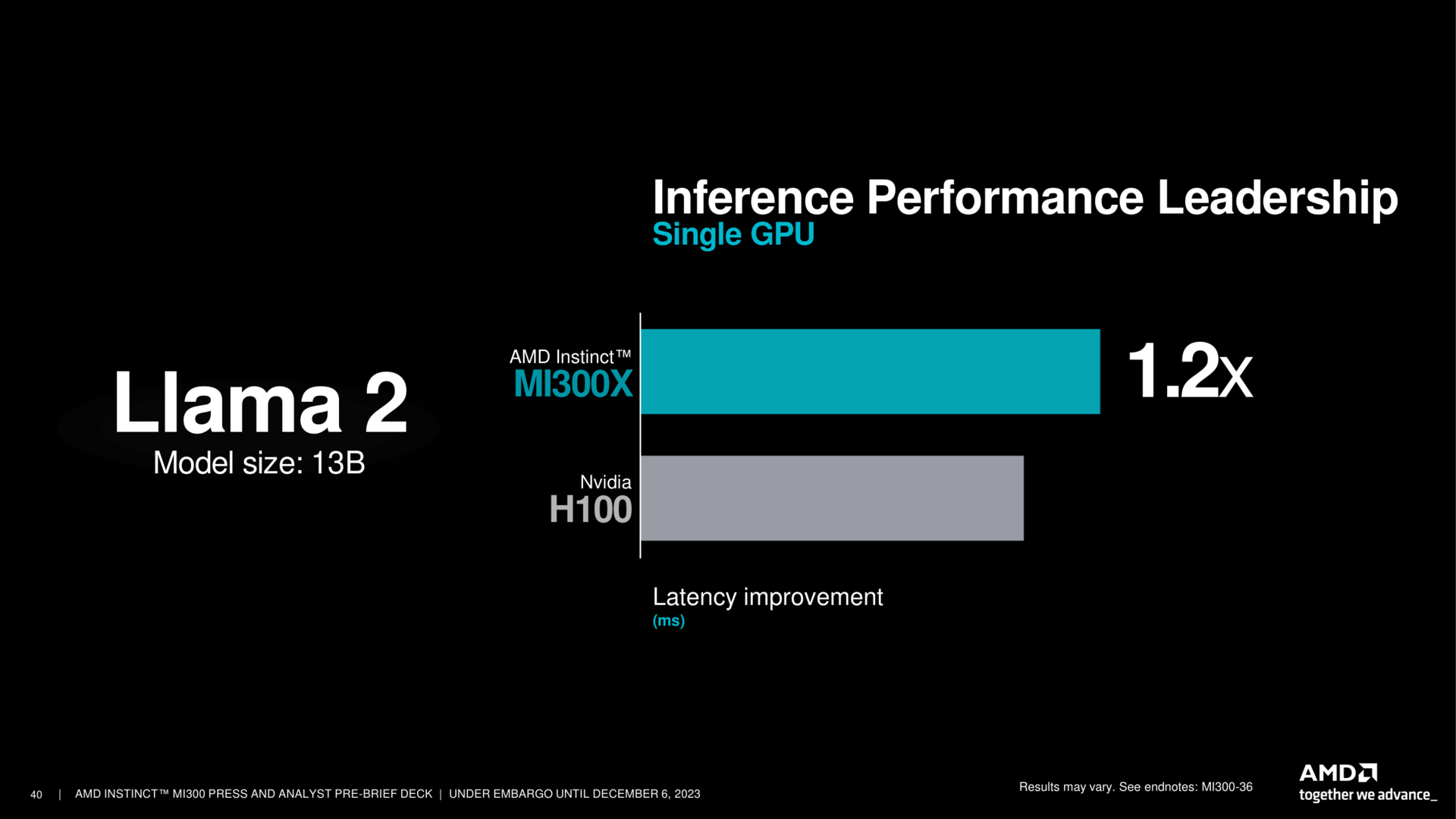


Nun muss die Umsetzung im Markt erfolgen
Das Gesamtpaket sieht heute auf den ersten Blick sehr gut aus. Am Ende bleibt trotzdem die Frage, ob das reicht. Der meisten Kundschaft, die aktuell ohnehin den Markt leer kauft, dürfte es mehr als genügen. Wären die Vorzeichen etwas anders, wäre es jedoch schwerer. Den Platzhirsch Nvidia im Markt mit zehn Prozent mehr Leistung zu übertreffen lässt keinen Großkunden hier schnell wechseln – das musste AMD schon im CPU-Servermarkt lernen.
An der Software-Front hat AMD aber viel Aufholarbeit geleistet; bisher hieß es in dem Bereich stets, an CUDA komme nichts vorbei. Es dürfte dementsprechend auch hier wieder eher ein Marathon denn ein Sprint sein. Immerhin heißt es nun aber bei der Hardware nicht mehr, dass es nur Nvidia gibt und dann lange nichts mehr – dafür hat MI300 heute gesorgt.
Die Verfügbarkeit der Lösungen soll zeitnah gegeben sein, Auslieferungen an Großkunden erfolgen bereits, bei Microsoft Azure kann das bereits ab heute getestet werden. Preise nannte AMD auch auf wiederholte Nachfrage mit einem Lächeln nicht.
-
 AMD-CEO Lisa Su mit MI300X (Bild: AMD)
AMD-CEO Lisa Su mit MI300X (Bild: AMD)

Im Demo-Showcase konnte ComputerBase einige der Systeme selbst in Augenschein nehmen und einige Impressionen im Bild festhalten.
-
 AMD Instinct MI300 im Demo-Showcase
AMD Instinct MI300 im Demo-Showcase

















ComputerBase wurde von AMD zum Event nach San Jose eingeladen. Flug, Transfers, Hotel sowie die Verpflegung vor Ort wurden von AMD gezahlt. Pre-Briefings sowie weitere Informationen im Rahmen des Events wurden zum Teil vorab der öffentlichen Präsentation unter NDA zur Verfügung gestellt. Eine Verpflichtung zur Veröffentlichung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Eine Woche nach AMDs Präsentation hat Nvidia den vom Konkurrenten gezeigten Benchmarks, die auch Werte für die eigene H100-GPUs enthielten, widersprochen. Per öffentlichkeitswirksamen Beitrag im Nvidia Developer Blog wirft das Unternehmen dem Wettbewerber vor, H100 nicht auf für die Plattform optimierter Software getestet zu haben.
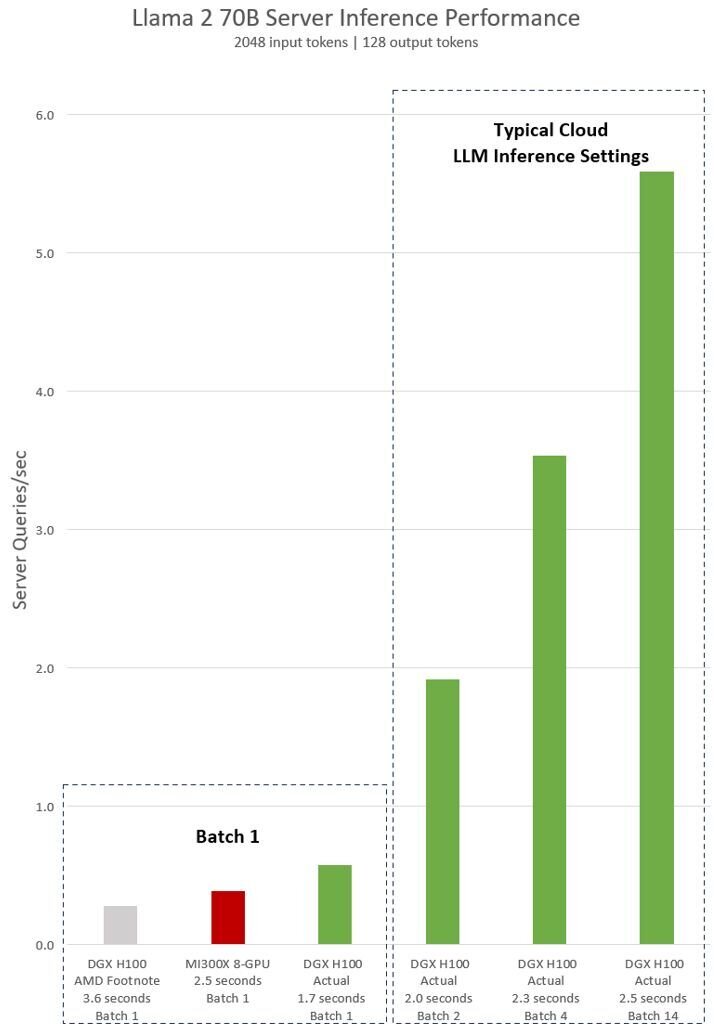
Wäre das der Fall gewesen, hätte das eigene Produkt den Benchmark im Large Language Model Llama 2 70B in 1,7 statt der von AMD genannten 3,6 Sekunden ausgeführt – was schneller und nicht langsamer als die von AMD für MI300X genannten 2,5 Sekunden ist. Eine Reaktion von AMD liegt bis dato nicht vor.
Dass Hersteller in ihren eigenen Benchmarks Best-Case-Szenarien abdecken, hat Tradition. Heutzutage beschränkt sich das oftmals auf die Wahl der Software und weniger auf Hardware-Einschränkungen. In dem jetzigen Fall lag ein wesentlicher Einflussfaktor Nvidia zufolge an der Schnittstelle zwischen Hardware und Software.
Nvidia wiederum nutzt den Anlass um den von AMD präsentierten Benchmarks eigene H100-Ergebnisse in – laut Nvidia – viel praxisrelevanteren Szenarien gegenüberzustellen. Die draus resultierenden wesentlich längeren Balken haben nichts mit dem von AMD genutzten Szenario zu tun, vermitteln beim schnellen Blick auf das Diagramm aber zweifelsohne eine haushohe Überlegenheit der Nvidia-GPU. Auch das dürfte kein Zufall sein.
Überraschend schnell hat Nvidia am Freitagabend dann doch noch eine Antwort von AMD in Form eines aktualisierten Benchmarks erhalten. Zu diesem erklärt AMD, dass sich bereits im letzten Monat die Software weiter entwickelt habe und man nun neue Ergebnisse auch mit ersten Optimierungen präsentieren könne. Dabei sieht AMD sich weiterhin vorn, selbst wenn Nvidia ihre angepasste Software nutzt.
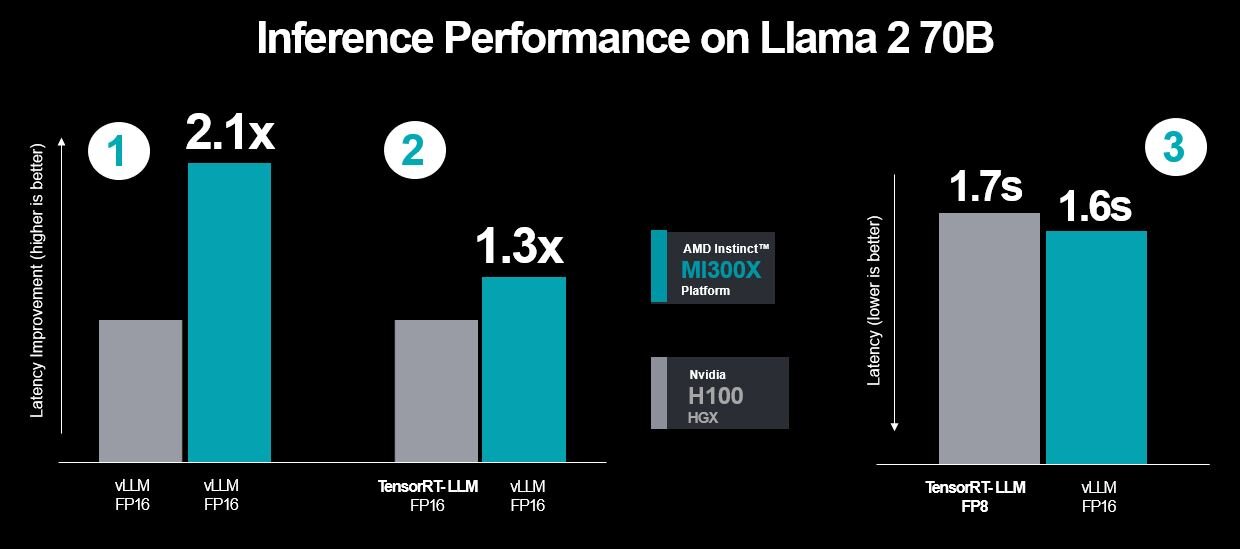
Wer am Ende Recht behält, ist so schwarz-weiß vermutlich nicht. Denn stets wird die Software weiterentwickelt, neue Szenarien tauchen auf. Eines zeigt der jüngste Schlagabtausch jedoch: Konkurrenz belebt das Geschäft. Und so etwas wie einen lachenden Dritten gibt es auch noch: Denn die Server werden auch bei AMD nicht angetrieben etwa von eigenen Epyc-CPUs, es kommt sowohl bei AMD als auch Nvidia ein Intel Xeon aus der Familie Sapphire Rapids zum Einsatz.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.