Grafikkarten-Generationen im Test: GeForce GTX 1070, RTX 2070, 3070 & 4070 im Vergleich

Wie viele FPS liefert eine GTX 1070 in aktuellen Spielen? Und wie viel schneller ist die RTX 4070 in Dauerbrennern wie Anno 1800 oder Overwatch 2? ComputerBase vergleich vier Generationen aus Nvidias 70er Serie: GeForce RTX 4070 vs. RTX 3070 vs. RTX 2070 vs. GTX 1070 in zehn Spielen im Test.
Die Motivation hinter diesem Test
ComputerBase testet regelmäßig Grafikkarten und hat dazu erst im Dezember 2023 den Testparcours wieder angepasst, ebenso wird die Grafikkartenrangliste mit aktuellen Kaufempfehlungen monatlich aktualisiert.
Der normale Testparcours wechselt in Anbetracht neuer Games, Spiele-Patches und Treiber regelmäßig, sodass Grafikkarten, die drei oder gar vier Generationen alt sind, aus Zeitgründen nicht beachtet werden. In diesem Artikel ist es anders und der Generationenvergleich ist (immer noch) Trumpf.
In diesem Test geht es um die Modelle GeForce GTX 1070, RTX 2070, RTX 3070 und RTX 4070.
Während AMD bei seinen Grafikkarten seit 2012 auf GCN („Graphic Core Next“) setzte und man Unterschiede in der Architektur bis 2019 sowie seit der Einführung von RDNA mit der Lupe suchen musste, war NVIDIA im gleichen Zeitraum oft mutiger bei Anpassungen. Das zeigt sich auch bei den Namen Pascal, Turing, Ampere und Ada.
Natürlich geht es dieses Mal ebenfalls um einen Vergleich der Architekturen. Um sie besser einordnen zu können, wird der Blick erneut etwas weiter zurückgehen, denn auch in Ada erkennt man gewisse Wurzeln in der Vergangenheit. Generationen sollen nicht nur gemessen, sondern ebenso verstanden werden.




Tesla: Wurzeln, die bis heute erkennbar sind
2007, also zeitgleich mit DirectX 10, brachte Nvidia die legendäre GeForce 8800 GTX auf den Markt und damit die Architektur Tesla, die bis heute die grobe Struktur aus Streaming-Multiprocessor, Texture-Processing-Cluster und Graphic-Processing-Cluster (also SM, TPC und GPC) definiert. Über die nachfolgenden Architekturen hatte sich dieser Aufbau bei Nvidia bewährt und kaum Änderungen erfahren.
Während der grobe Aufbau seit Tesla unverändert übernommen wird, sind die Veränderungen innerhalb des Aufbaus der einzelnen Bereiche teilweise gravierend. So bestand bei Tesla ein SM aus acht Shadern. Zwei SMs wurden zu einem TPC zusammengefasst, der vier oder acht Texture-Mapping-Units (je nach Lesart eigentlich vier Texture-Address-Units und acht Texture-Filtering-Units) und den L1-Cache vereinte. Mehrere TPCs bildeten dann den GPC und waren an den L2-Cache angebunden.
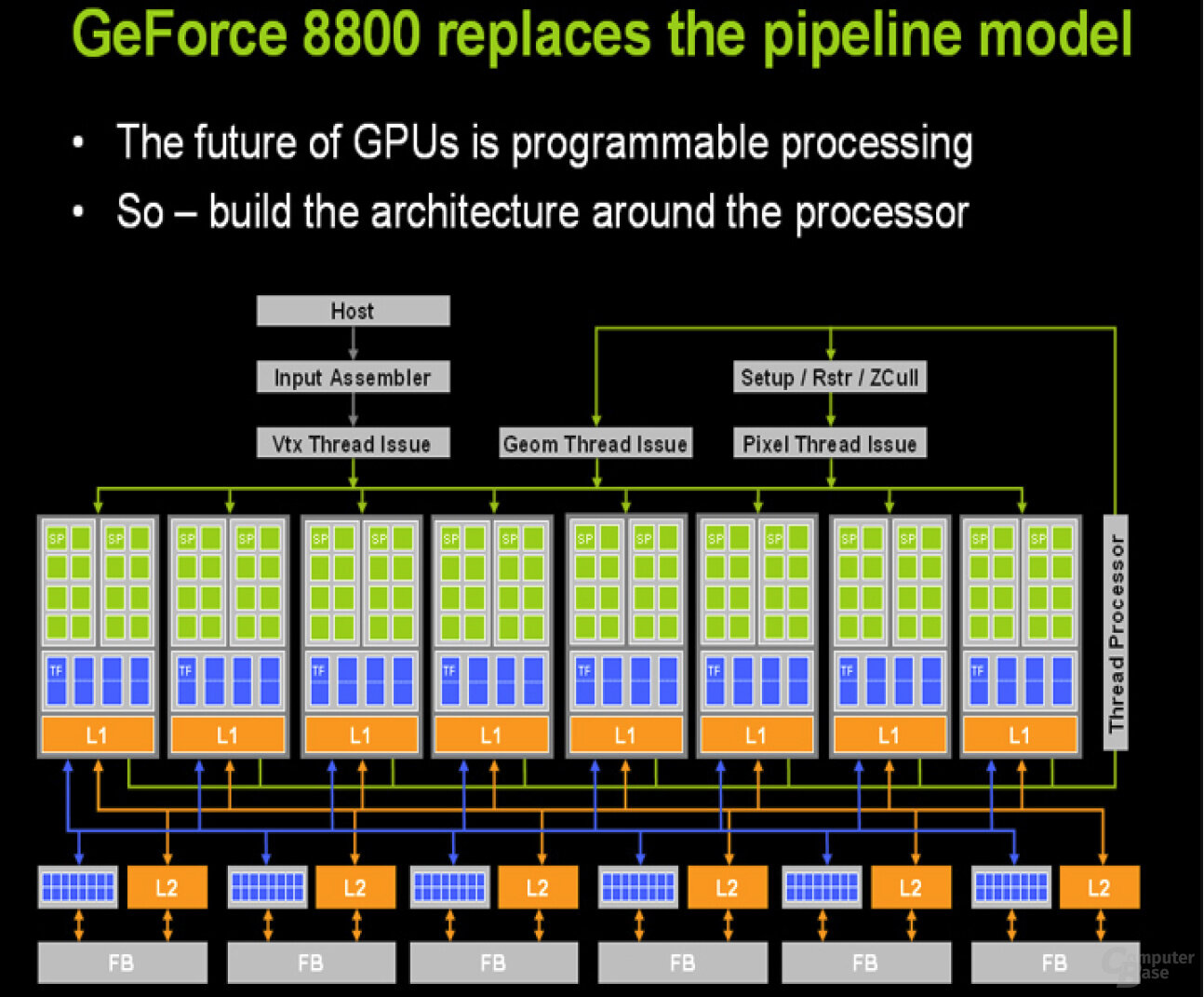
Mit der zweiten Auflage als GeForce GTX 280 und GT200 wurden drei SMs zu einem TPC verbunden – eine Anpassung im Kleinen, um die TMU besser auszulasten. Die ersten großen Änderungen an Tesla kamen mit Fermi. 32 Shader bildeten nun zusammen mit vier TMUs einen SM. Der TPC fiel erst mal heraus. Eine Gemeinsamkeit der Architekturen bis zu diesem Stand war die asynchrone Taktdomäne: Die Shader takteten höher als der Rest der GPU, was gerade bei Fermi zu einigen Problemen führte.
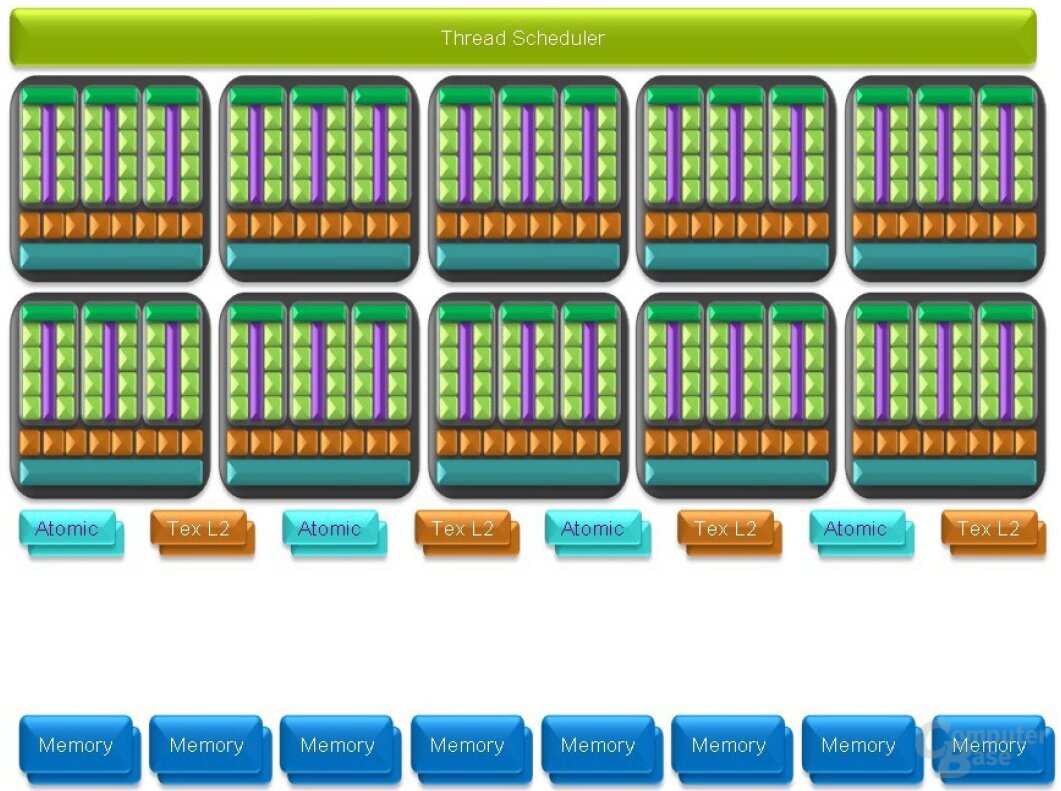
Mit Kepler wurde die Architektur das erste Mal radikal umgebaut. Die SMs hatten jetzt 192 Shader statt wie bisher 32, dazu kamen 16 TMUs. Diese Änderungen führten dazu, dass die Shader den gleichen Takt wie die restliche GPU hatten, was die Effizienz drastisch verbesserte.
Der nächste radikale Umbau folgte schnell: Maxwell. Die SMs bestehen seitdem aus vier Tiles mit einem eigenen Register-File – 32 Shader pro Tile, dazu 8 TMUs. Maxwell konnte durch diese neue Struktur der SMs positiv überraschen und die GeForce GTX 980 war circa 7 Prozent schneller als die GTX 780 Ti. Die GTX 780 Ti hatte dabei knapp 41 Prozent mehr Shader (2.880 gegen 2.048), die GTX 980 konnte dafür mit 1.126 MHz knapp 28 Prozent höher takten. Der Takt glich die fehlenden Shader allerdings nicht vollständig aus.
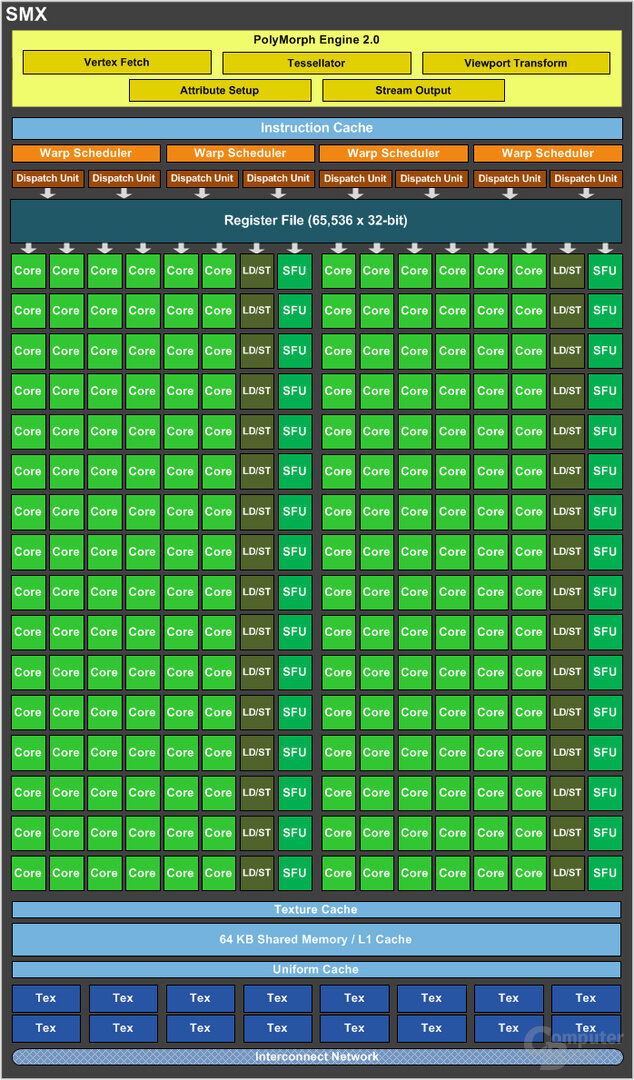

GeForce GTX 1070, RTX 2070, RTX 3070 und RTX 4070: Es ist leichter und doch ähnlich?
Ein Kritikpunkt bei dem Generationenvergleich der Radeon-Grafikkarten ist, dass die ausgewählten Modelle in der Form nicht zusammenpassen. Gerade die 7800 XT ist negativ aufgenommen worden. In diesem Test ist es vom Namen her leichter, denn alles sind 70er-Karten und auch bei den Chips spiegelt es sich wider (nur die RTX 2070 sticht heraus): GP104, TU106, GA104, AD104.
Gleichzeitig ist es allerdings auch bei Nvidia in diesem Fall nicht so einfach, was an den Preisverschiebungen der letzten Jahre liegt. Die GTX 1070 hatte einen UVP von 379 US-Dollar, bei der RTX 2070 stieg er auf 499 US-Dollar an und wurde bei der RTX 3070 gehalten. Der UVP für die 4070 erhöhte sich um 100 US-Dollar auf 599 US-Dollar. Es verhält sich ähnlich wie bei AMD und den Preisen für die Radeon RX 7800 XT bei 499 US-Dollar, während die RX 6700 XT mit 479 US-Dollar nur knapp darunter lag. RX 5700 XT und Vega 56 hatten unverbindliche Verkaufspreise von 399 US-Dollar.
Es gibt also auch dieses Mal verschiedene Möglichkeiten, wie das Testfeld zusammengestellt werden kann. Gerne können Leser in den Kommentaren mitteilen, wie sie dieses Testfeld aufgebaut hätten.
| GeForce GTX 1070 | GeForce RTX 2070 | GeForce RTX 3070 | GeForce RTX 4070 | |
|---|---|---|---|---|
| Architektur | Pascal | Turing | Ampere | Ada |
| Chip | GP 104 | TU106 | GA104 | AD104 |
| Design | TSMC 16nm | TSMC 12nm | Samsung 8nm | TSMC 4N |
| Transistoren | 7,2 Mrd. | 10,6 Mrd. | 17,4 Mrd. | 35,8 Mrd. |
| Chipgröße | 314 mm² | 445 mm² | 393 mm² | 295 mm² |
| SMs | 15 | 36 | 46 | 46 |
| FP32-ALU | 1.920 | 2.304 + 2.304 (INT) | 5.888 | |
| RT-Kerne | – | 36, 1st Gen | 46, 2nd Gen | 46, 3rd Gen |
| Tensor-Kerne | – | 144, 2nd Gen | 184, 3rd Gen | 184, 4th Gen |
| Base-Takt | 1.506 MHz | 1.410 MHz | 1.500 MHz | 1.920 MHz |
| Boost-Takt | 1.683 MHz | 1.620 MHz | 1.730 MHz | 2.475 MHz |
| FP32-Rechenleistung | 6,9 TFLOPs | 7,46 TFLOPs | 20,3 TFLOPs | 29,1 TFLOPs |
| FP16-Rechenleistung | 6,9 TFLOPs | 14,92 TFLOPs | 20,3 TFLOPs | 29,1 TFLOPs |
| FP16 über Tensor | – | 59,72 TFLOPs | 81 TFLOPs | 117 TFLOPs |
| Textureinheiten | 120 | 144 | 184 | |
| ROPs | 64 | 96 | 64 | |
| L2-Cache | 2048 KB | 4.096 KB | 36.864 KB | |
| Speicher | 8 GB GDDR5 | 8 GB GDDR6 | 12 GB GDDR6X | |
| Speicherdurchsatz | 8 Gbps | 14 Gbps | 21 Gbps | |
| Speicherinterface | 256 Bit | 192 Bit | ||
| Speicherbandbreite | 256 GB/s | 448 GB/s | 504 GB/s | |
| Slot-Anbindung | PCIe 3.0 | PCIe 4.0 | ||
| TDP | 150 Watt | 175 Watt | 220 Watt | 200 Watt |



Testsystem und Spiele
Bereits im Generationenvergleich zu den Radeon-Grafikkarten wurde das verwendete Testsystem vorgestellt und es gab seitdem keine Änderungen. Es unterscheidet sich in wichtigen Punkten von dem regulären Testsystem, die Ergebnisse sind daher nicht vergleichbar und sollen den Eindruck der Grafikkarten ergänzen.
| Komponenten | Hersteller |
|---|---|
| CPU | Intel Core i9-14900K |
| Mainboard | Gigabyte Z790 Gaming X AX |
| RAM | 64 GB DDR5-6400, CL-32-39-39-102 |
| Festplatte | 2 TB Samsung 990 Pro |
| Gehäuse | Fractal Design Torrent |
| Kühler | Fractal Design Celsius+ 360 |
| Netzteil | Seasonic Prime PX-750 |
| Betriebssystem | Windows 11 23H2 |
| Treiber | 546.33 |
| Sicherheits-Features | Kernisolierung und Speicherintegrität aktiviert |
| rBAR | Aktivierung durch Treiberprofil |
Ins Auge springt bereits der Unterschied beim Prozessor: Es kommt ein Intel Core i9-14900K zum Einsatz und kein Ryzen 9 7950X3D. Ebenso werden 64 statt 48 GB RAM verwendet. Ein weiterer Punkt ist die Windows-Installation, die im Alltag eingesetzt wird. Programme wie Discord, HiDrive und Cryptomator können die FPS negativ beeinflussen. rBAR wird bei Nvidia in einzelnen getesteten Spielen per Profil aktiviert oder deaktiviert, während bei AMD rBAR/SAM im Treiber generell de- oder aktiviert werden kann.
Ein weiterer Vorteil des Generationenvergleiches ist, dass es bei der Auswahl der Titel mehr Freiheit gibt. In diesem Test finden sich daher Multiplayer-Games, Spiele mit einer hohen Langzeitmotivation und selbstverständlich auch aktuelle Vertreter. Wie im vorherigen Vergleich besteht die Liste aus diesen zehn Games:
| Spiele | Einstellungen |
|---|---|
| Cyberpunk 2077 | Ultra; DLSS aus; RT „Psycho“ |
| Anno 1800 | Ultrahoch; FSR aus |
| Warhammer 40,000: Darktide | Hoch, FSR aus |
| Diablo II: Resurrected | Sehr hoch, VFX „Ultrahoch“ |
| Doom Eternal | Ultra-Alptraum |
| Final Fantasy XIV | Alle Einstellungen maximiert |
| Starfield | Ultra; DLSS aus |
| Total War: Warhammer III | Ultra |
| Call of Duty: Modern Warfare 3 | Extrem |
| Overwatch 2 | Ultra; DLSS aus |
Ihr habt die Wahl: Macht mit bei den Reader's Choice Awards 2025 und bestimmt eure Hersteller des Jahres!