Cerebras CS-3 mit WSE-3: AI-Beschleuniger in Wafergröße hat 4 Billionen Transistoren

Das auf AI-Beschleuniger und entsprechende Hyperscaler spezialisierte Unternehmen Cerebras hat mit dem CS-3 auf Basis der WSE-3 heute die dritte Generation in Wafergröße vorgestellt. Der Prozessor hat praktisch die Größe eines Wafers und kommt deshalb auf 4 Billionen Transistoren. Der auserkorene Gegner heißt Nvidia H100.
Im Wettrennen um immer leistungsfähigere AI-Beschleuniger für das Training und Inferencing von Large Language Models (LLM) geht Cerebras mit der WSE-3 (Wafer-Scale Engine) den nächsten Schritt. Der Prozessor im Waferformat kommt wiederum in dem CS-3 getauften System zum Einsatz, von dem sich bis zu 2.048 für einen Hyperscale-AI-Supercomputer zusammenschalten lassen. 256 ExaFLOPS KI-Leistung stelle diese Lösung zur Verfügung und könne zum Beispiel Llama2-70B von Meta in weniger als einem Tag von Grund auf neu trainieren. Metas derzeitiges GPU-Cluster, das jedoch weiter ausgebaut werden soll, benötige hingegen einen Monat für diese Aufgabe.
WSE-3 mit 900.000 Kernen
Herz des CS-3 ist die in TSMC N5 gefertigte WSE-3 mit 900.000 Kernen, die speziell für Tensor-basierte, dünn besetzte (sparse) linear-algebraische Operationen optimiert wurden, um das Training neuronaler Netze und das Inferencing beim Deep Learning zu beschleunigen. Die WSE-3 ist 46.225 mm² groß, kommt auf 4 Billionen Transistoren und zeichnet sich durch 44 GB SRAM auf dem Chip aus, der mit einer Bandbreite von 21 Petabyte/s arbeitet. Das ist selbstredend deutlich mehr als bei den Caches des Nvidia H100, weshalb Cerebras mit einem Vorteil um den Faktor 880x wirbt, aber gleichzeitig weniger als das, was bei Nvidia mit 80 GB an HBM3 geboten wird.
-
 WSE-3 vs. H100 (Bild: Cerebras)
WSE-3 vs. H100 (Bild: Cerebras)

Zum Vergleich: Nvidias H100 wird in TSMC 4N gefertigt und erreicht bei 80 Milliarden Transistoren eine Größe von 826 mm². Bei AMD liegt der AI-Beschleuniger Instinct MI300X mit 192 GB HBM3 bei 153 Milliarden Transistoren und einer Größe von 1.017 mm².
Weiterer Speicher in MemoryX-Einheiten
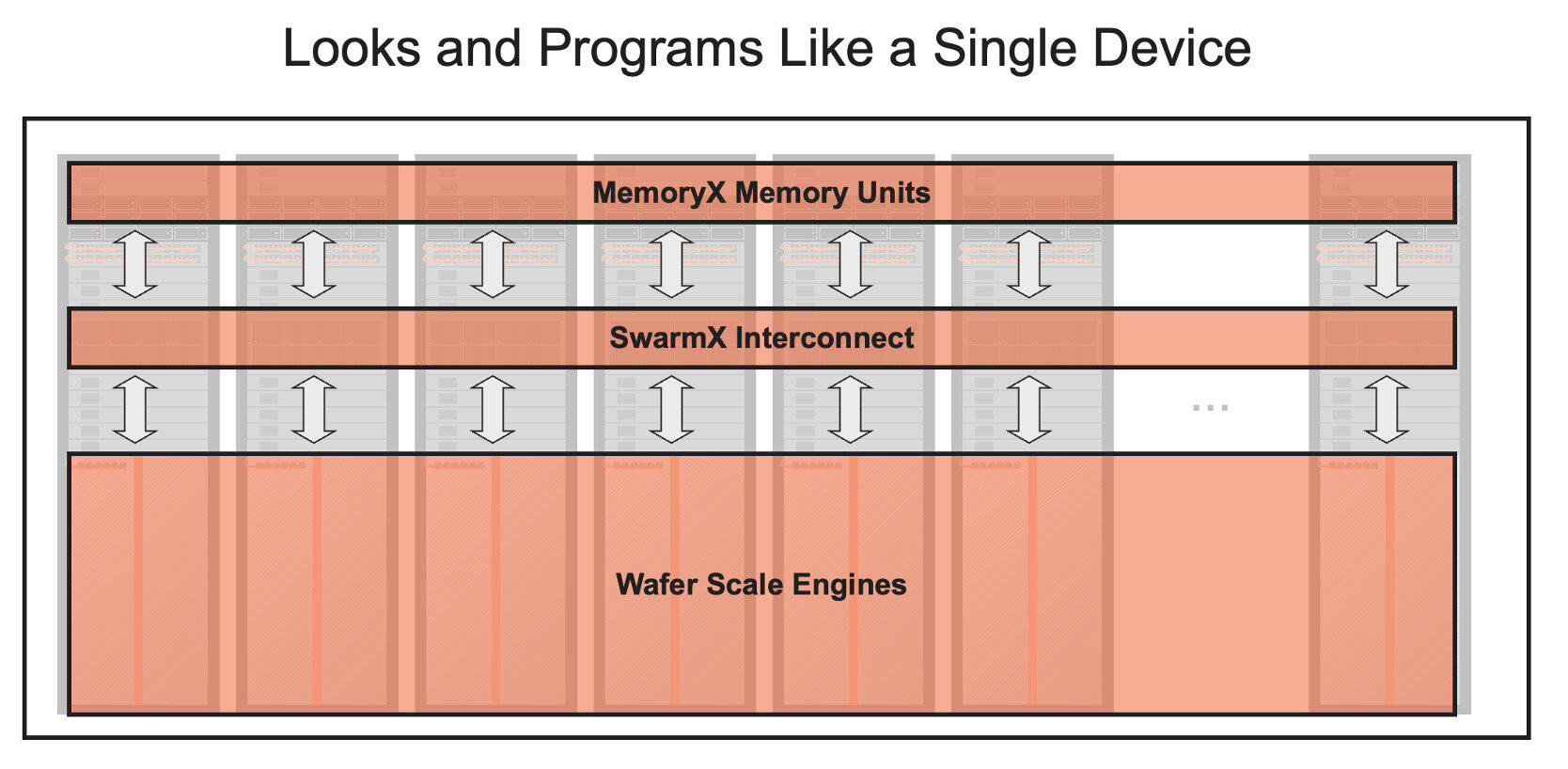
Cerebras lagert weiteren Speicher allerdings in zusätzliche MemoryX-Einheiten mit DRAM und Flash-Speicher aus, die über das SwarmX-Fabric mit 214 Petabit/s angebunden werden. Diese MemoryX-Module bietet Cerebras für Enterprise-Kunden mit 1,5 TB, 12 TB, 24 TB und 36 TB sowie für Hyperscaler-Kunden mit 120 TB und 1.200 TB an. Letztere Konfiguration könne 24 Billionen Parameter speichern und ebne somit den Weg für Large Language Models eine Größenordnung (Faktor 10x) über GPT-4 und Gemini. Ein einzelnes CS-3-Rack könne mehr Parameter speichern als ein GPU-Cluster mit 10.000 Nodes.
-
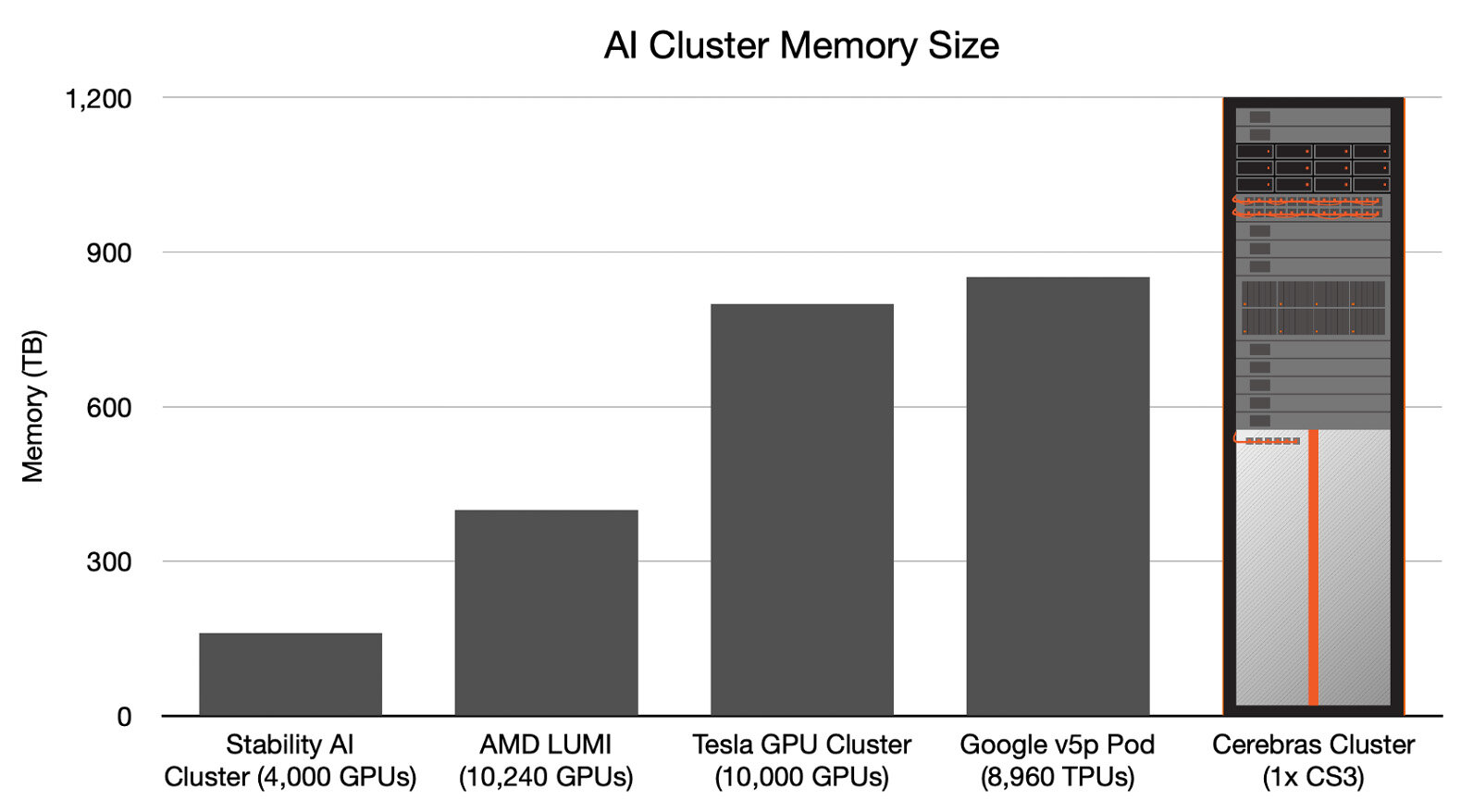 Vergleich des CS-3 zu anderen Lösungen (Bild: Cerebras)
Vergleich des CS-3 zu anderen Lösungen (Bild: Cerebras)




Ein CS-3 verbraucht 23 kW
Eigene Tests von Cerebras hätten ergeben, dass ein einzelnes CS-3-System bei der Nutzung der Large Language Models Llama 2, Falcon 40B und MPT-30B bis zu zweimal mehr Tokens/s verarbeiten könne als ein CS-2 der vorherigen Generation. Ein CS-3 liefere die doppelte Leistung ohne Steigerung des Verbrauchs oder der Kosten, argumentiert Cerebras, während bei neuen GPUs mit mehr als dem doppelten Verbrauch und mehr als den doppelten Kosten zu rechnen sei. Ein CS-3 belegt 15 RUs (Rack Units) und verbrauche 23 kW. Addiert werden müssen allerdings zusätzliche Verbraucher wie die MemoryX-Einheiten, die im Rack darüber positioniert werden.
Supercomputer CG-3 mit 64 CS-3
Einen ersten AI-Supercomputer auf Basis des CS-3 hat Cerebras mit dem Condor Galaxy 3 (CG-3) des Kollaborationspartners G42 ebenfalls angekündigt. Der CG-3 nutzt 64 CS-3-Systeme und kommt somit auf 58 Millionen Kerne und 8 ExaFLOPS. Gemeinsam mit dem vorherigen Condor Galaxy 1 und 2 will G42 mit der Fertigstellung des CG-3 im Laufe des zweiten Quartals auf 16 ExaFLOPS kommen. CS-3-Systeme mit WSE-3 werden laut Cerebras ab sofort an Kunden ausgeliefert. Bisherige Kunden sind die Mayo Clinic, GlaxoSmithKline, TotalEnergies Research, AstraZeneca, das Argonne National Laboratory und weitere.

