Intel Xe2: GPU-Architektur für Lunar Lake und Battlemage im Detail

Die auf der Computex vorgestellte Lunar-Lake-Architektur ist die erste, die Intels nächste Generation der Xe-GPU-Architektur einsetzt: Xe2. Auch „Battlemage“, die Basis der nächsten Generation Arc-Grafikkarte, wird das tun. Im Vorfeld der Messe gab Intel auf einem Tech Day tiefere Einblicke in die Veränderungen. Ein Überblick.
Die Xe2-Architektur im Überblick
Xe2 ist keine von Grund auf neu entwickelte Architektur, sondern baut auf Xe auf. Intel will allerdings aus den Eigenheiten und Problemen des Vorgängers gelernt haben. Xe2 soll entsprechend nicht nur deutlich besser, sondern auch problemfreier laufen.
Ganz konkret soll zum Beispiel die Unreal Engine 5 besser performen, die auf GPUs mit dem Xe immer mal wieder ihre Probleme hat. Als wichtigste Fortschritte bei Xe2 nennt Intel eine bessere Auslastung der GPU, eine optimierte Arbeitsverteilung und einen geringeren Software-Overhead.

SIMD 16 statt SIMD 8
Bei Xe2 wechselt Intel von einem SIMD-8-Design (Single instruction, multiple data) auf SIMD-16-Design. Xe2 kann also einen Befehl gleichzeitig auf 16 Einheiten (und optional auch SIMD 32) ausführen. Das soll die Effizienz steigern und zugleich dafür sorgen, dass manche Kompatibilitätsprobleme gar nicht erst auftauchen – auch wenn Intel sich dazu nicht genauer geäußert hat.
-
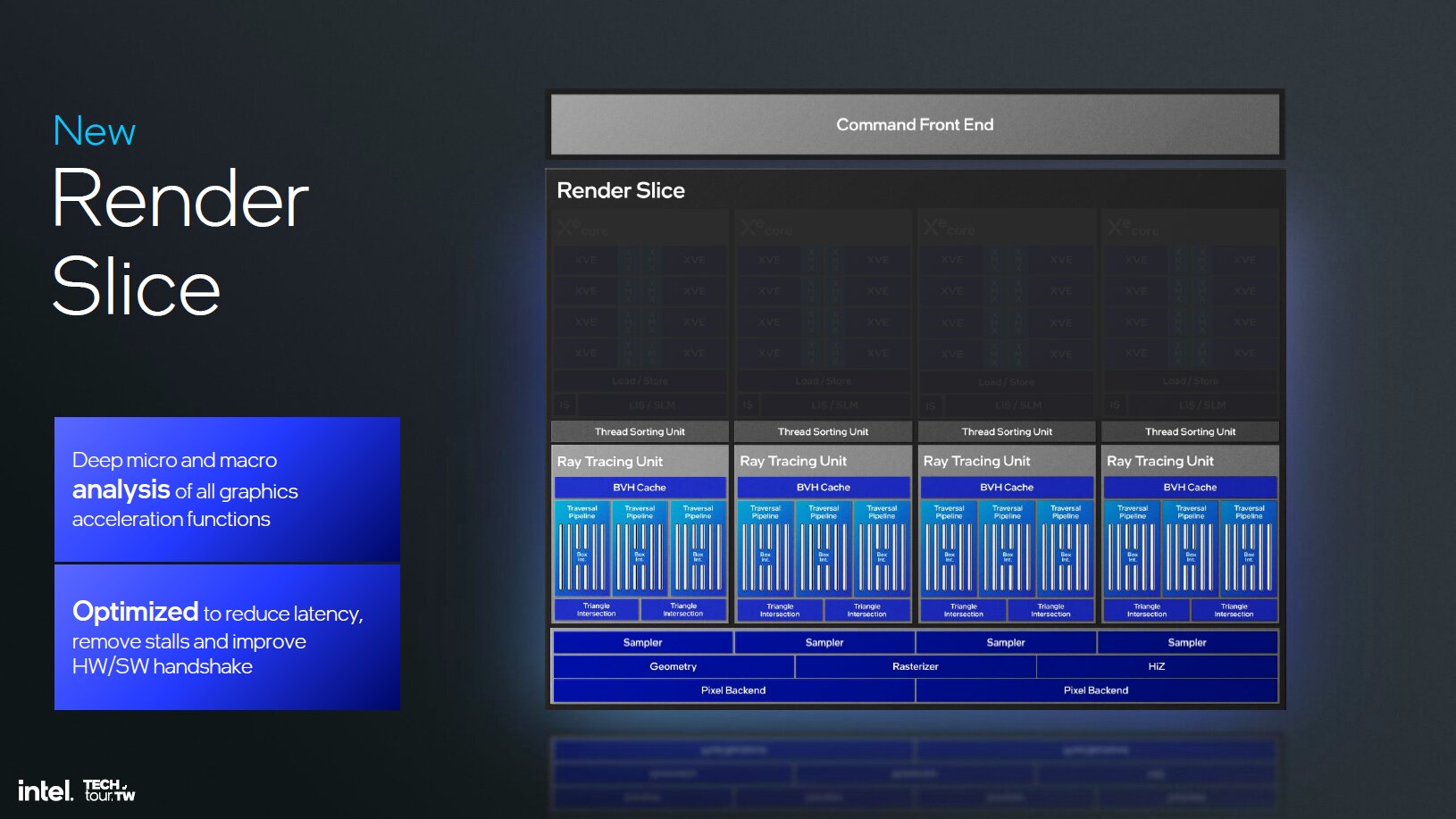
 Intel Xe 2 – Der generelle Aufbau (Bild: Intel)
Intel Xe 2 – Der generelle Aufbau (Bild: Intel)

Neu konfigurierte Vektor-Engines
Die neuen XVE-Einheiten, früher schlicht Vektor-Engines genannt, setzen sich aus 16 FP32-ALUs zusammen. Die Anzahl ALUs pro XVE hat sich damit also verdoppelt, jedoch halbiert sich zugleich die Anzahl der XVE-Einheiten pro Xe-Kern von 16 auf deren 8 – ein Xe2-Kern verfügt also immer noch über genauso viele ALUs wie ein Xe-Kern. Der Xe-Core ist das Äquivalent zu AMDs Compute Unit (CU) und Nvidias Streaming-Multiprocessor (SM).

Die MXM-Einheiten beherrschen mehr Formate
Neben den ALUs verfügt jeder Xe2-Kern über 8 XMX-Engines für Matrix-Multiplikationen, die für KI-Berechnungen zuständig sind. Das sind doppelt so viele wie zuvor; kein Wunder, andernfalls hätte die neue Konfiguration auch in diesem Fall dafür gesorgt, dass die absolute Anzahl fällt.
Bei Meteor Lake hatte Intel die MXM-Einheiten, obwohl Xe sie ebenfalls schon bot (siehe Intel Arc 1. Generation), noch weggelassen, aufgrund des mittlerweile aber geänderten Umfeldes setzen bei Xe2 sowohl die iGPU in Lunar Lake als auch Battlemage für die 2. Generation Arc darauf.

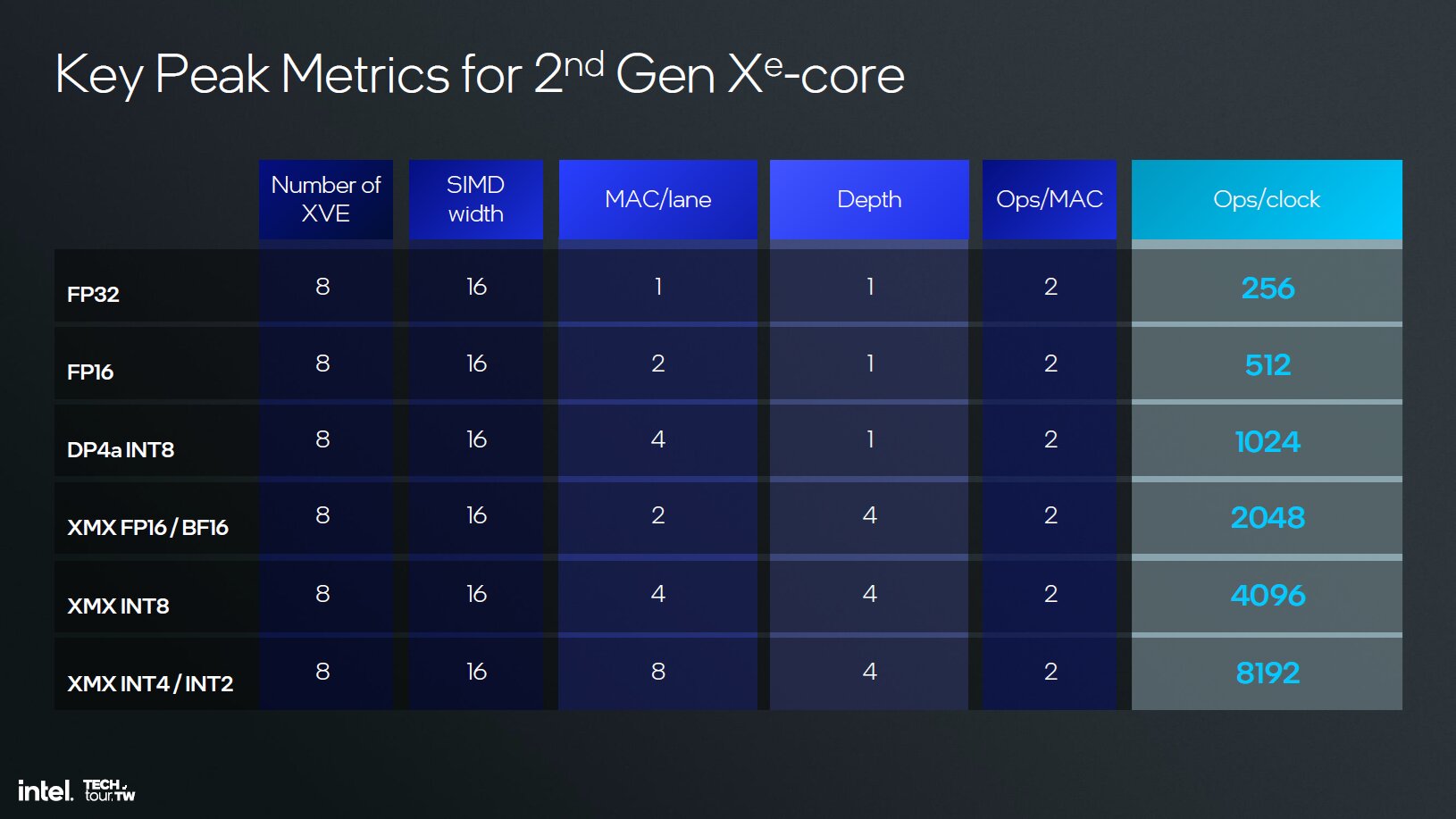
Die neuen XMX können auch weitere Formate berechnen, neben FP16 und BF16 sind auch INT8, INT4 sowie INT2 dabei – dasselbe gilt für Sparsity (zusammengepackte Matrix-Operationen). Erwähnenswert ist ferner, dass eine XVE-Einheit nun drei verschiedene Operationen gleichzeitig ausführen kann (sowohl Floating Point als auch Integer und Matrix gleichzeitig). Xe der ersten Generation konnte dies noch nicht.
Optimierungen für höhere Auslastung
Intel hat bei Xe2 neben den neuen Xe-Kernen diverse weitere Funktionseinheiten mit dem Ziel, die Latenzen zu verringern, Stalls zu vermeiden und die Zusammenarbeit zwischen Software und Hardware zu ermöglichen, angepasst. Unter anderem wurden die Geometrieeinheiten verbessert, die jetzt beim Mesh-Shading deutlich schneller sein sollen. Der L1-Cache, die Textureinheiten, die Culling-Möglichkeiten und die ROPs wurden mit Xe2 gegenüber Xe ebenfalls überarbeitet.
-
 Intel Xe 2 – Der generelle Aufbau (Bild: Intel)
Intel Xe 2 – Der generelle Aufbau (Bild: Intel)
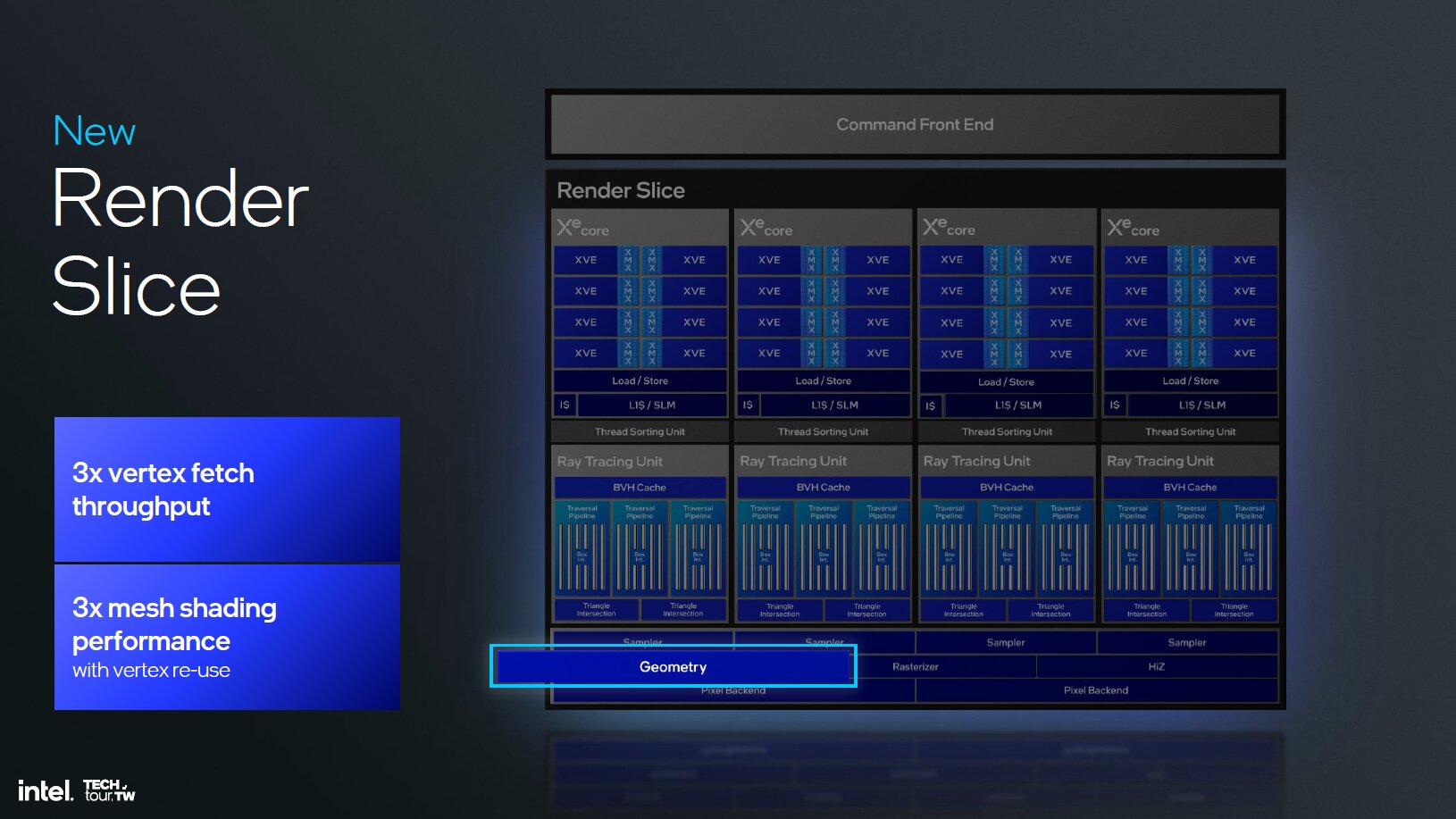
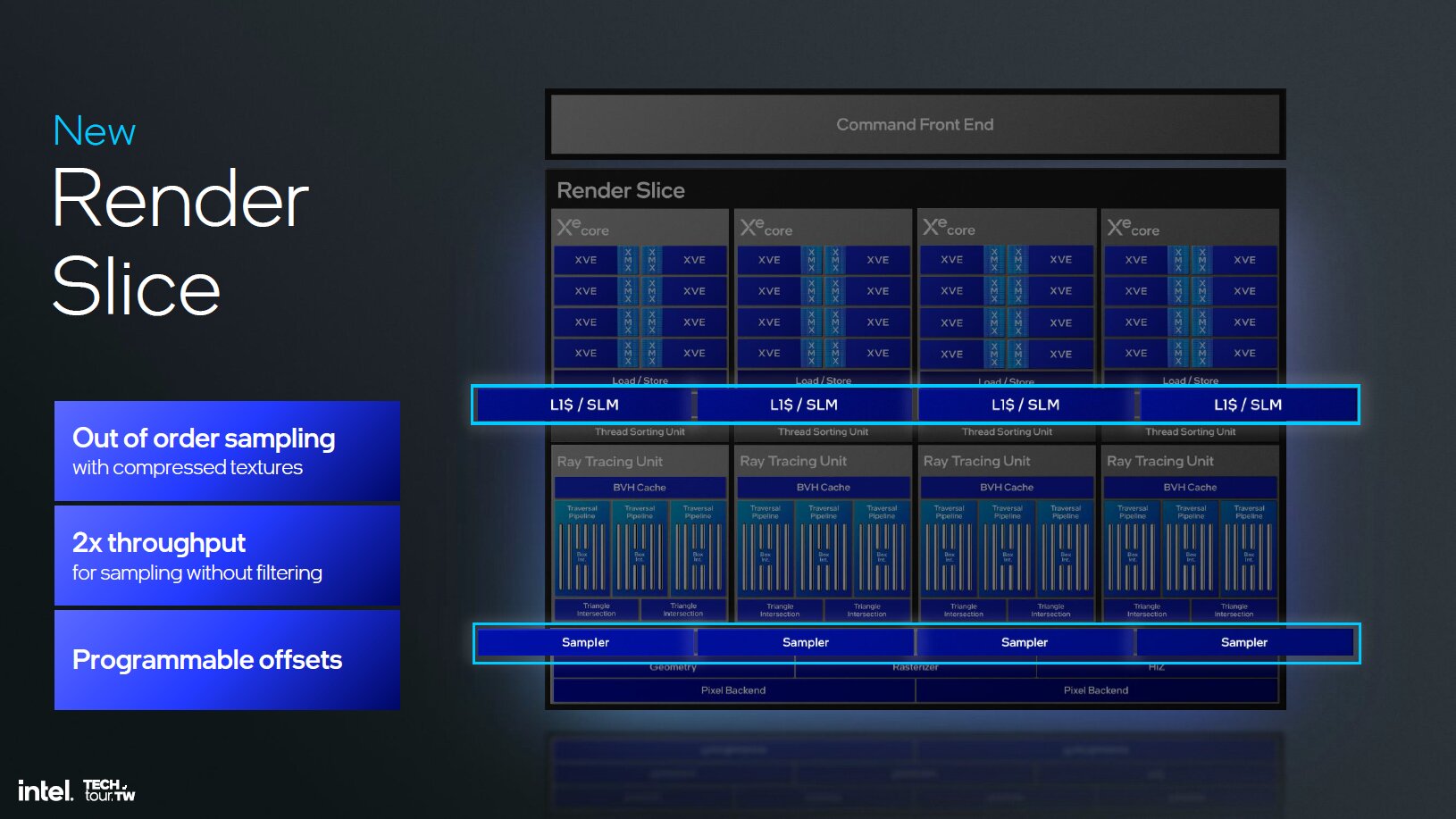
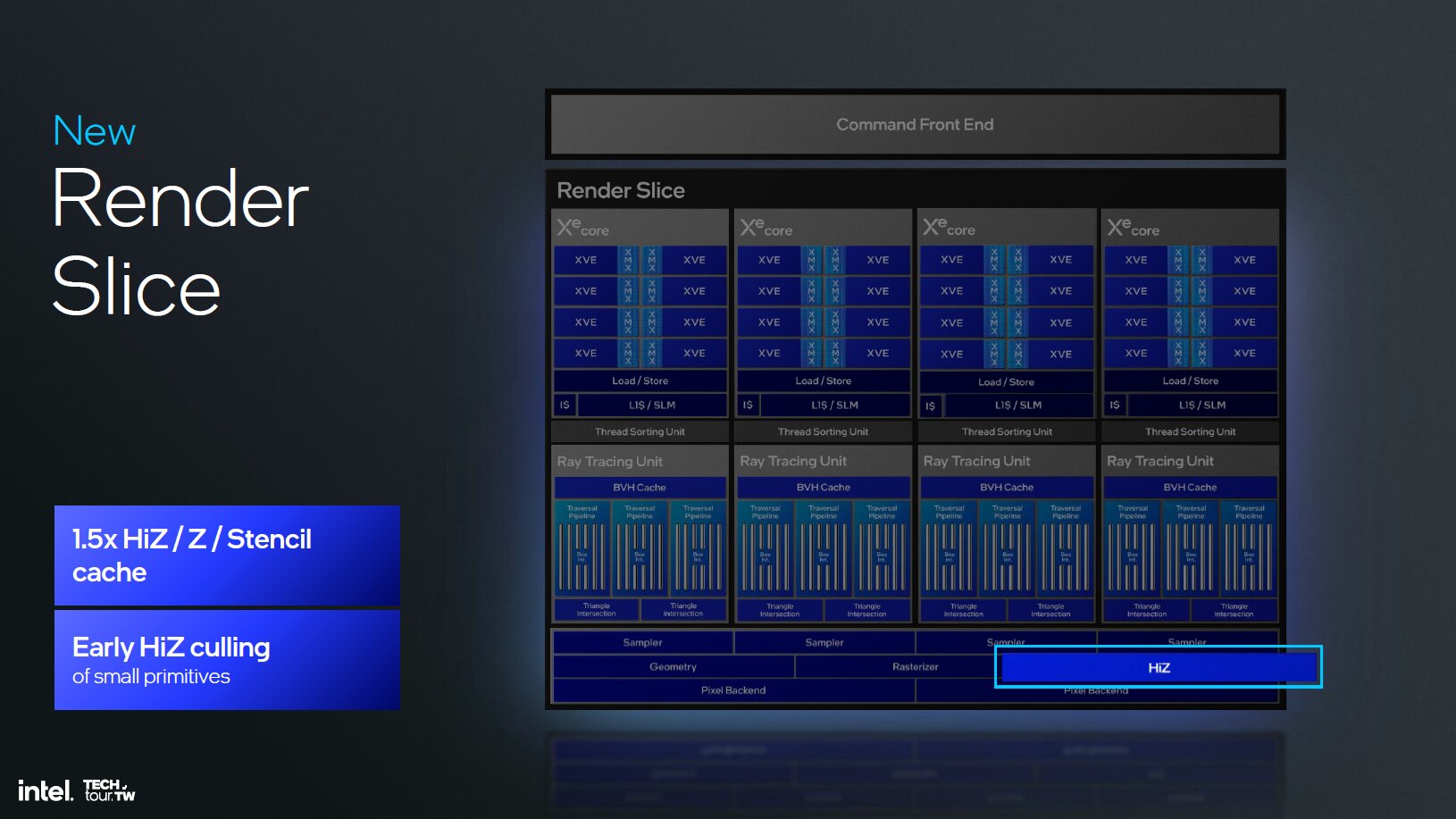
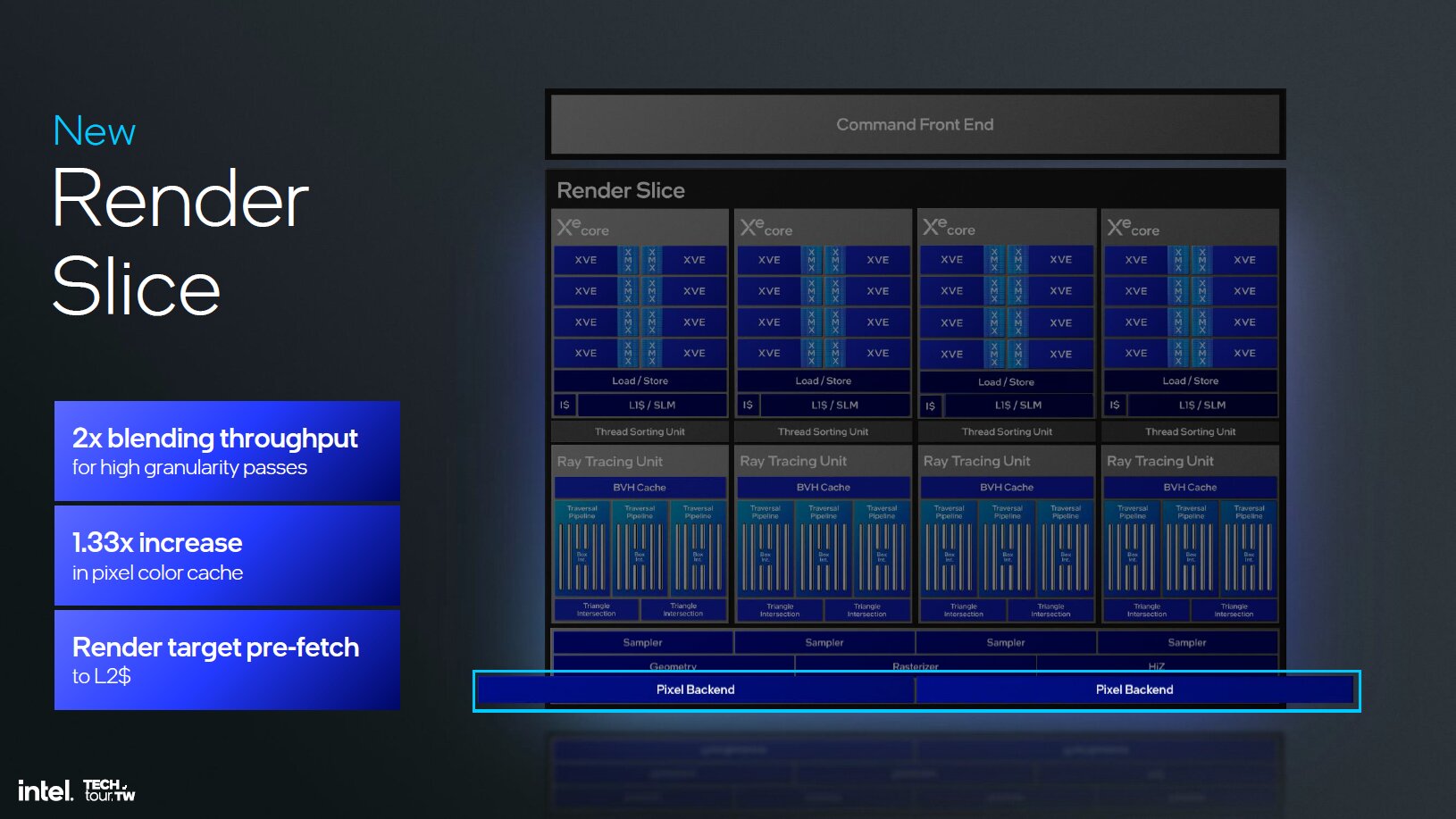
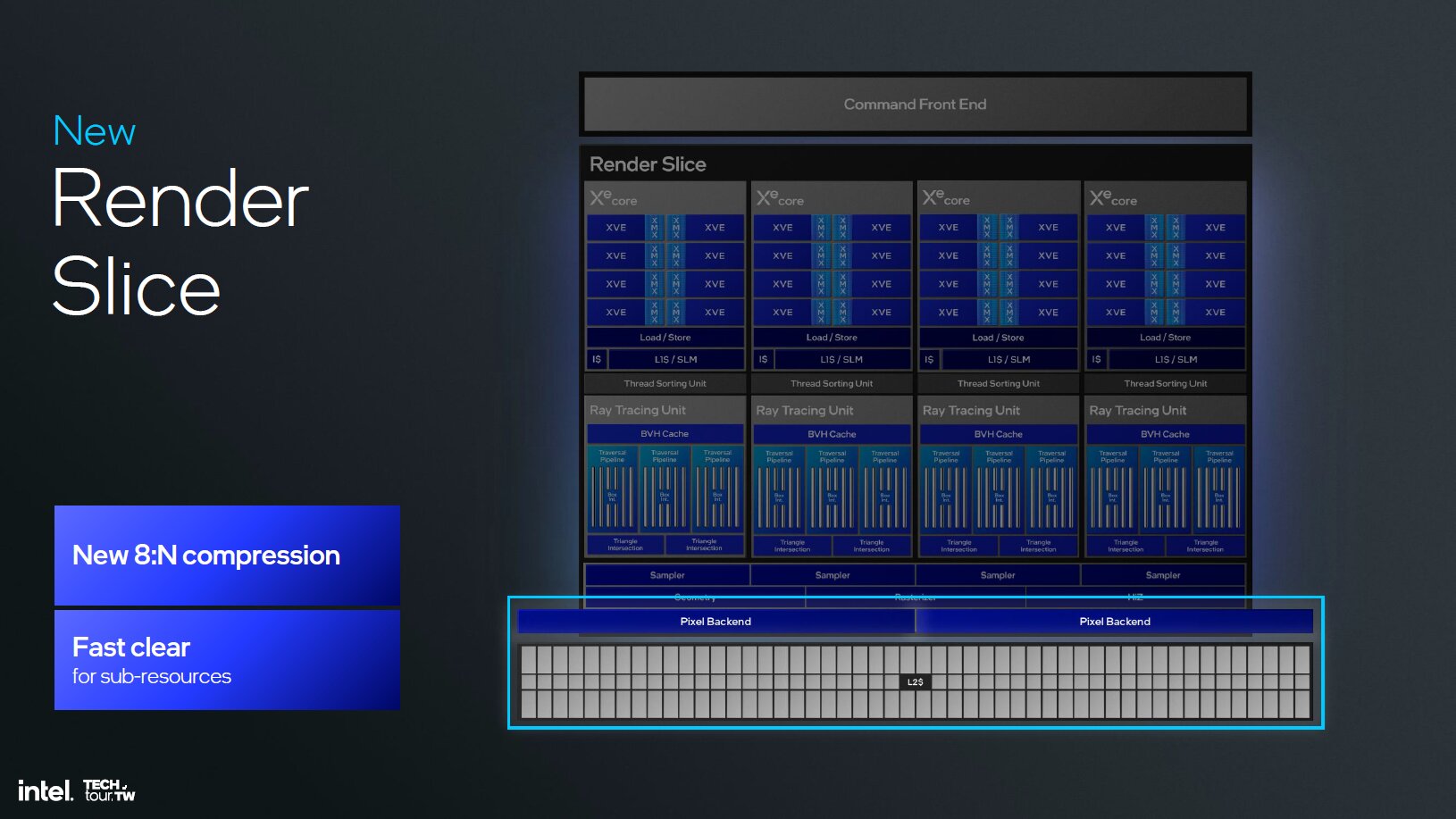
Schnellere RT-Einheiten
Raytracing war laut Intel ein wichtiges Thema bei Xe2. Es gibt nach wie vor 4 separate RT-Einheiten pro Render-Slice, sie wurden jedoch deutlich aufgebohrt. So sind bei Xe2 3 statt 2 Traversal-Pipelines vorhanden, sodass jetzt 18 anstelle von 12 Traversal-Tests pro Takt ausgeführt werden können. Darüber hinaus sind nun 18 statt 12 Box-Intersection-Tests möglich und 2 anstelle von 1 Triangle-Intersection-Test. Die theoretische Raytracing-Leistung hat sich pro Einheit also um mehr als 33 Prozent erhöht.

In der Theorie ist Xe2 klar schneller als Xe 1
Intel hatte in Taipeh zwar keine Spiele-Benchmarks parat, bot jedoch die Ergebnisse einiger komplett theoretischer Benchmarks an. Dabei ging es zum Beispiel um „Compute Dispatch“, also den Aufruf zur Durchführung eines Compute-Befehls, der auf Xe2 um den Faktor 7 schneller als auf Xe erfolgen soll. Mesh-Shader sollen um den Faktor 4,1 schneller werden, Sampler-Feedback um 2,7, Tessellation um 1,2 und Raytracing je nach Testreihe um 1,6 bis 2,1.

Die Benchmarks waren dabei normalisiert, d.h. Konfiguration der GPUs und deren Takt spielten keine Rolle, nur der Architektur-Unterschied schlug laut Intel durch.
Da es sich am Ende aber ohnehin um Intels eigene, völlig voneinander losgelöste, theoretische Benchmarks handelt, ist die praktische Aussagekraft extrem gering. Einzig gesichert sein dürfte, dass Xe2 bei gleicher Anzahl an Ausführungseinheiten und gleichem Takt schneller als Xe werden wird. Aber was davon in welchem Szenario wirklich auch ankommen wird, steht in den Sternen.

ComputerBase hat Informationen zu diesem Artikel von Intel unter NDA im Rahmen einer Veranstaltung des Herstellers im Vorfeld der Computex in Taipeh, Taiwan erhalten. Die Kosten für An-, Abreise und drei Hotelübernachtungen wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe aus dem NDA war der frühestmögliche Veröffentlichungszeitpunkt.
- be quiet! Light Wings LX: Neue Lüfter mit 16 Naben-ARGB-LEDs zum niedrigeren UVP
- be quiet! Light Base 900 & 600: Showcase-Gehäuse haben Glas und drei Ausrichtungen
- Corsair Xeneon 34WQHD240-C: Lüfterloser QD-OLED-Monitor mit 240 Hz und 1.000 nits
- +80 weitere News