MLPerf Inference Benchmarks: Erstmals mit Blackwell, MI300X & Turin sowie Granite Rapids

MLPerf-Benchmarks haben es geschafft: AMDs Instinct MI300X und Epyc „Turin“, Intel Xeon „Granite Rapids“, Nvidia B200 „Blackwell“ und Google TPUv6 krönen die neue Testserie. Noch nie zuvor wurden so viele auch noch nicht verfügbare Produkte in dem Test berücksichtigt. Das war und ist ein Ziel der Macher der Suite.
AMDs erstes Ergebnis ist da ...
Viel Kritik musste AMD in den letzten Quartalen dafür einstecken, dass sie es nicht schaffen, ein Ergebnis für einen in der Industrie aktuell stark beachteten Benchmark hervorzubringen. Nun ist es endlich soweit, die Hard- und Software soweit gereift, dass sich der Hersteller in die Öffentlichkeit traut. Und nebenbei bringt AMD dann nicht nur Instinct MI300X mit, sondern präsentiert die HPC-Beschleuniger im Gespann mit Turin-Prozessoren.
In einem zusätzlich anberaumten Call erklärte AMD der Presse die Hintergründe. Natürlich liegt es auch an der Software und dem so zu präsentierenden Komplettpaket, der Fokus des Personals lag laut AMD aber eben erst einmal darin, das Ökosystem bei zahlenden Kunden zum Laufen zu bringen. Also die Industrie kommt zuerst, da sie schließlich auch das Geld bringt, dann die Benchmarks. Auf die ersten Einträge sollen dann aber schnell weitere folgen.

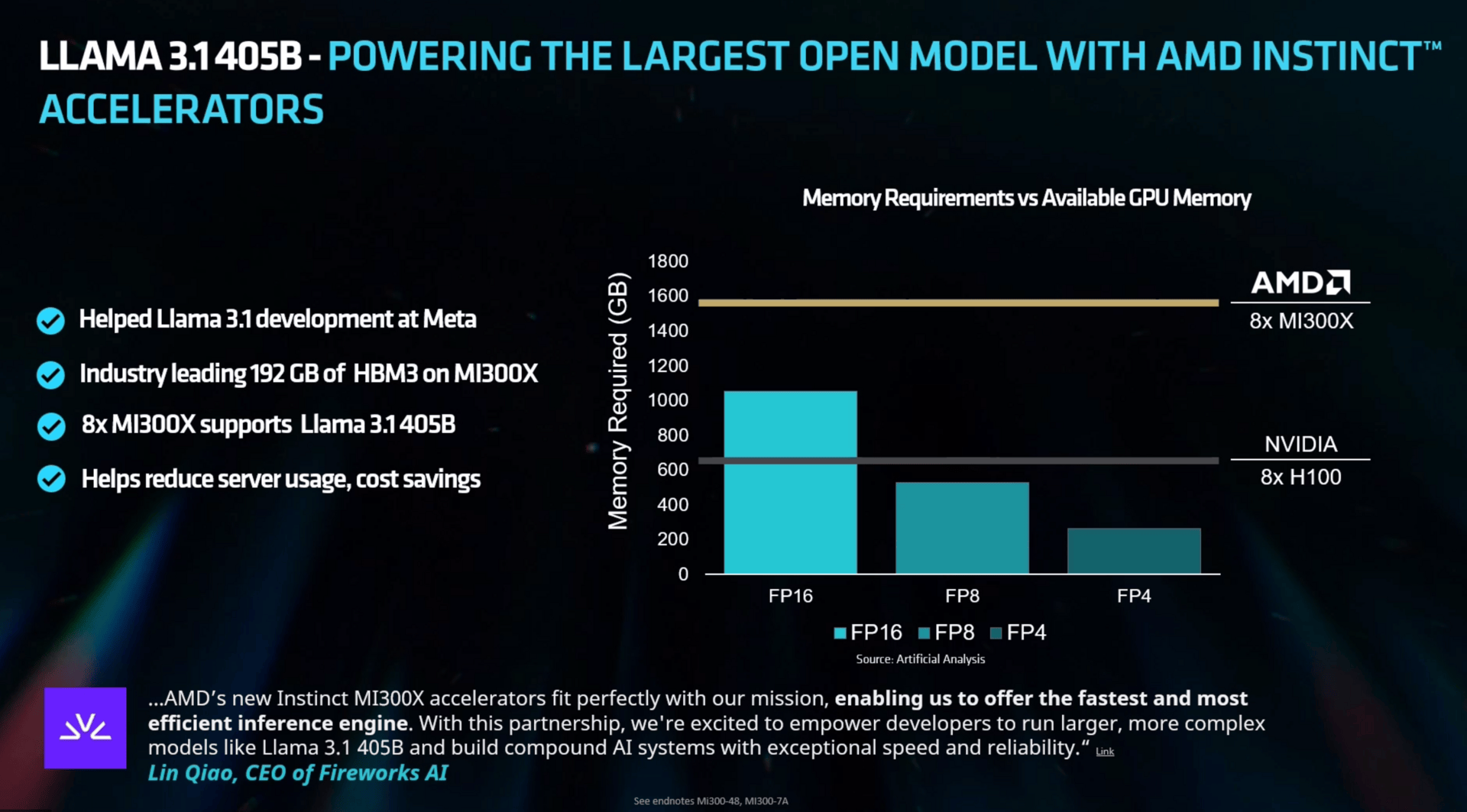
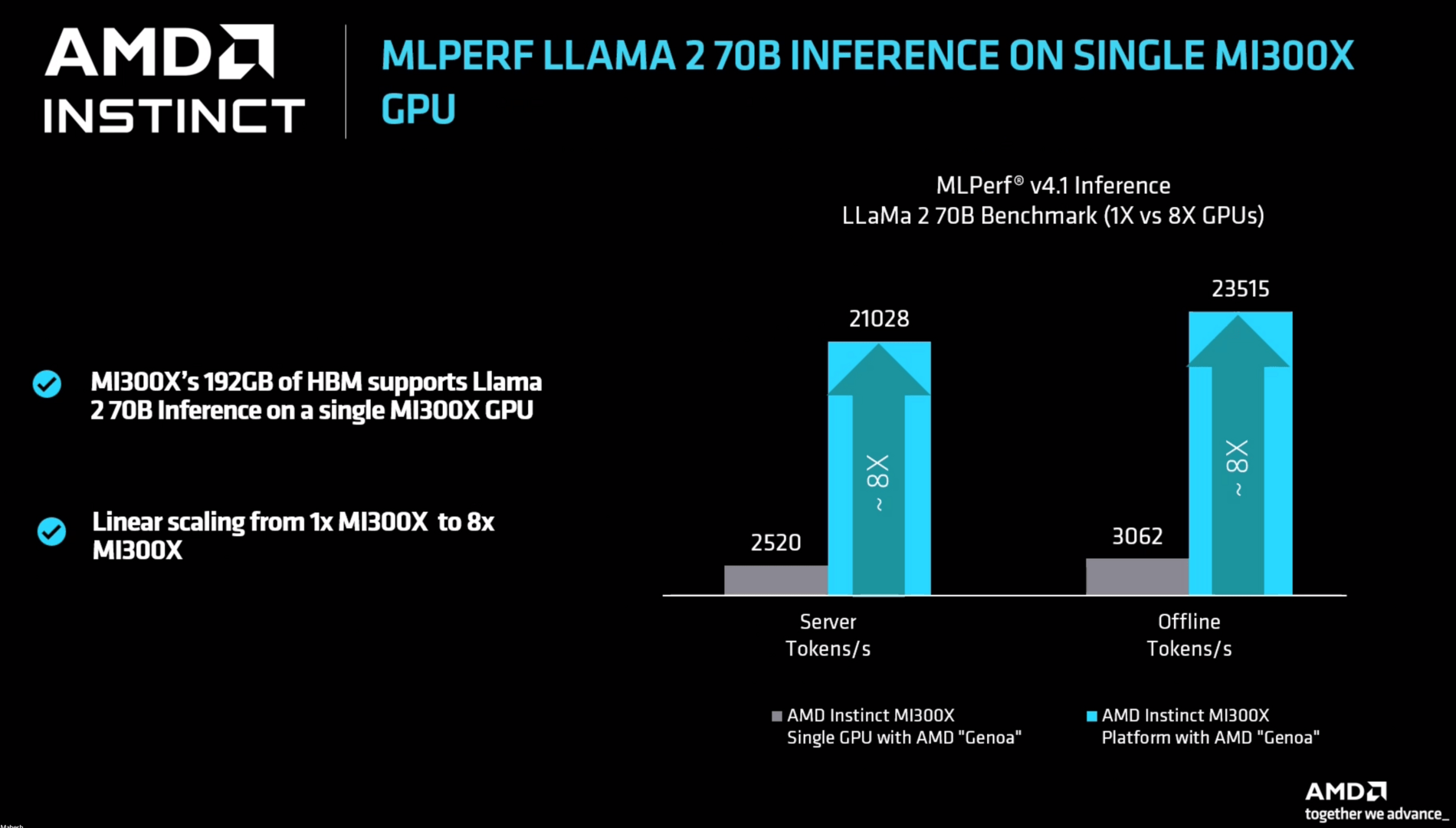
Die ersten Benchmarks von AMD sind am Ende auch eher ernüchternd. Ja, MI300X kann es mit Nvidia aufnehmen, aber gegen Nvidias kleinen H100 zu bestehen ist auch das Mindeste – inzwischen gibt es H200 und noch Ende 2024 sollen B200/B100 folgen.
So muss sich AMD auch direkt die erste Frage gefallen, wo denn die Rohleistung hin verpufft, vor allem bezüglich des 192 GByte großen Speichers und der eigentlich enormen Bandbreite. Laut AMD liegt das daran, dass bei MLPerf einige Parameter anders angepackt werden als in anderen Tests, man hier durchaus einige Stellschrauben erkannt hat, und diese mit Softwareupdates angehen wird – aber noch nicht angegangen ist. Denn die Zukunft ist nah, vom schnellen und großen Speicher sollen neueste LLMs profitieren und auch den Weg freimachen für die nächste Generation Instinct, die bereits als MI325X im vierten Quartal erscheint.

... und wird gleich von Nvidia wieder kassiert
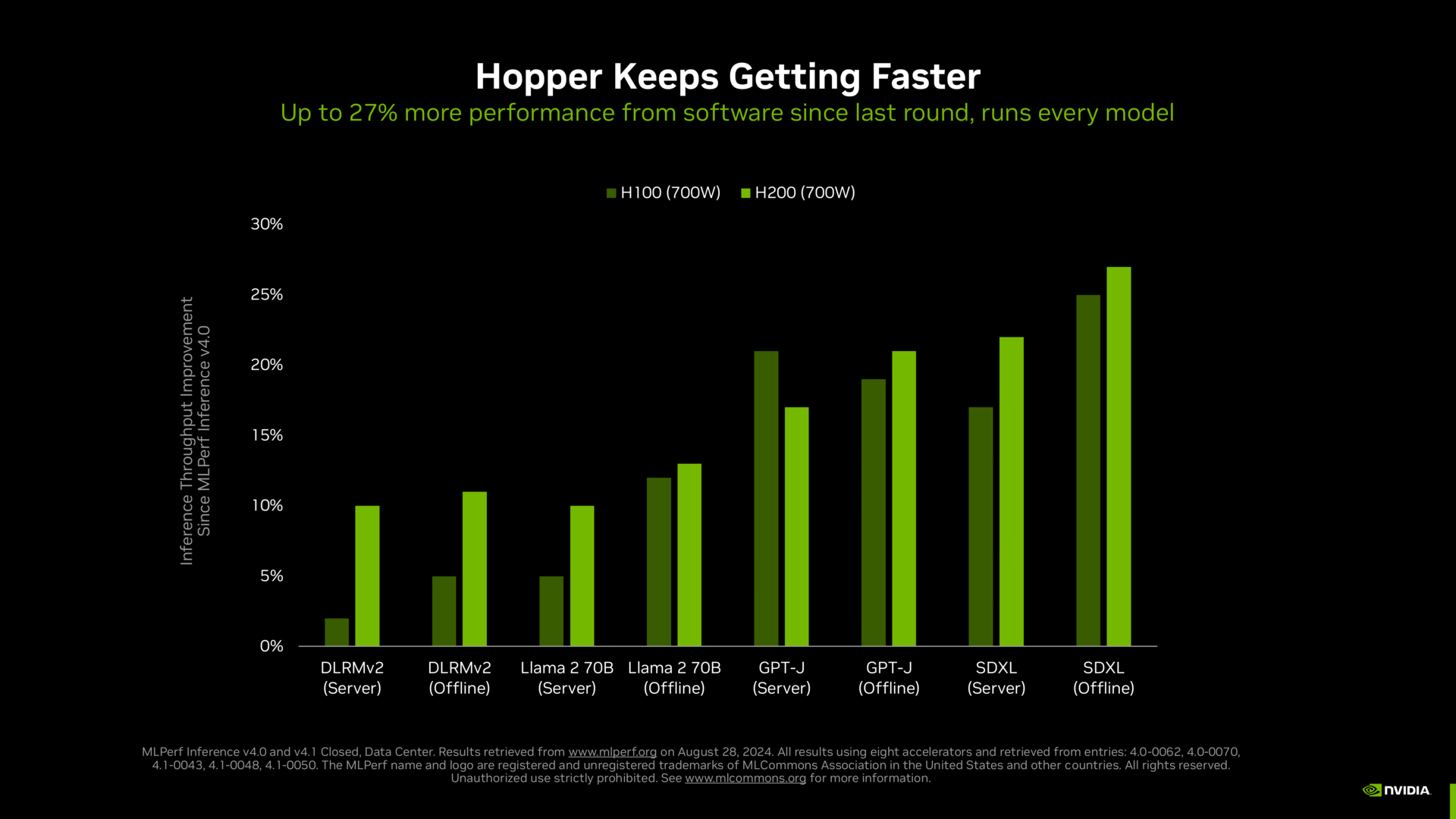
Der Platzhirsch in den Benchmarks ist unangefochten Nvidia. Nicht nur die diversen H100-Systeme, sondern auch Lösungen mit H200 finden mehr und mehr Berücksichtigung und führen klar das Feld an.

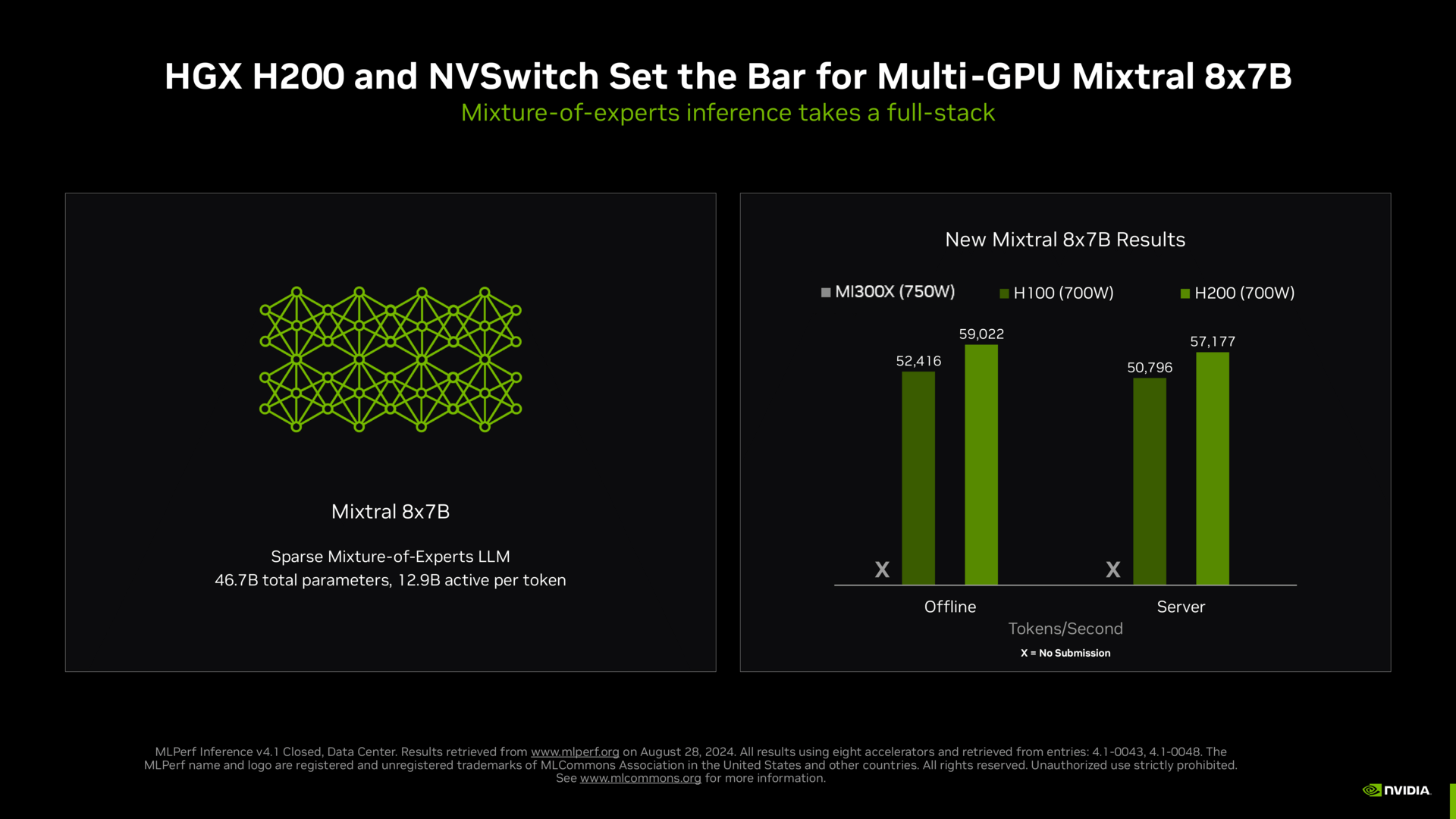
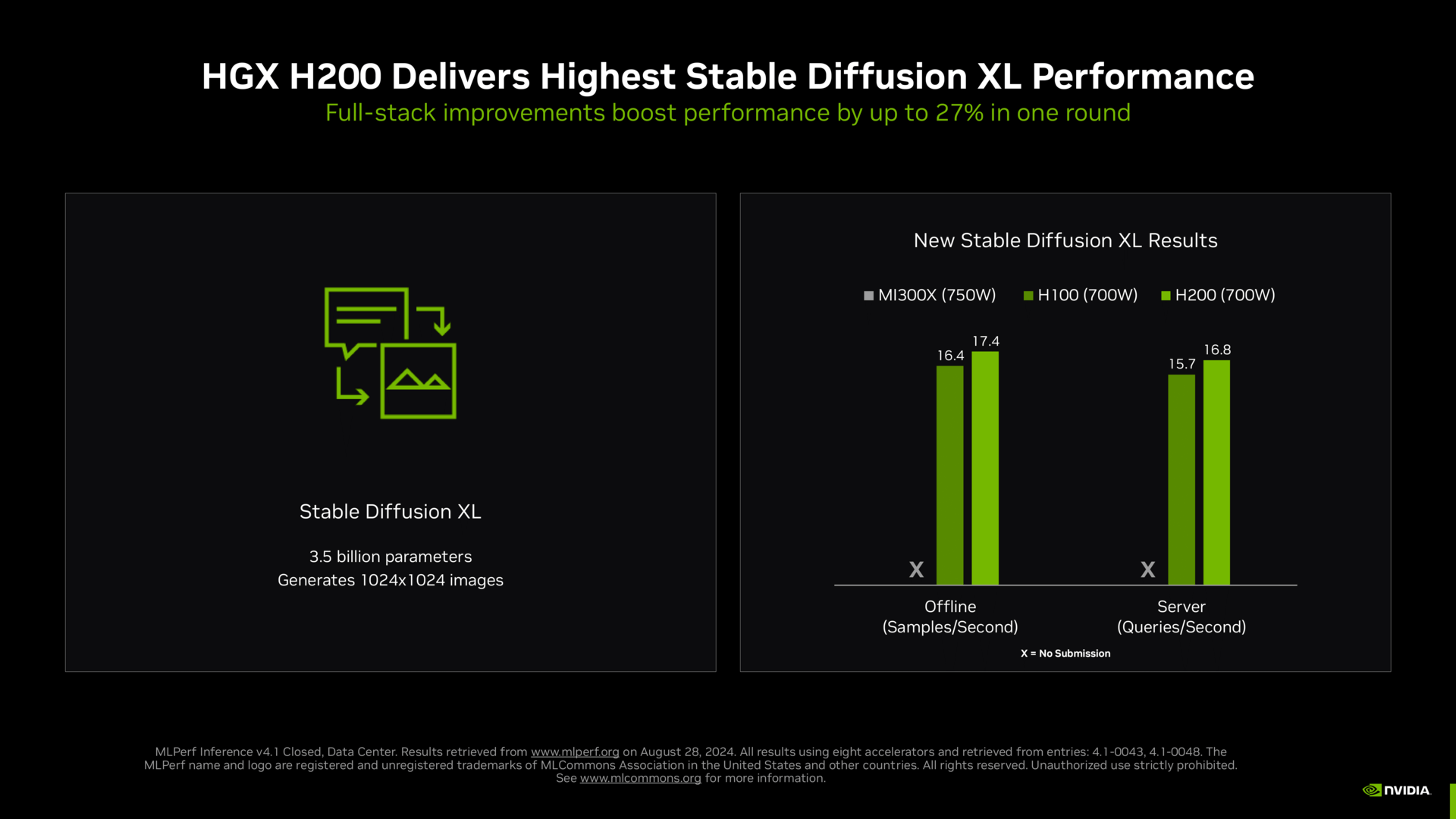
Das gute an den MLPerf-Ergebnissen ist, dass die Hersteller sie sich nicht selbst zurechtbiegen können. Jeder der beteiligten Parteien hat vorab Zugriff auf alle Ergebnisse, Unstimmigkeiten werden beseitigt. Dass in AMDs Benchmarks MI300X und H100 letztlich genau so schnell sind wie auf Nvidias Foliensatz, gibt es sonst nie zu sehen. Es zeigt aber auch, was AMD weggelassen hat: Jede schnellere Version, die Nvidia aktuell eigentlich auch bereits anbietet. Deshalb ist ML Commons eine durchaus gute Sache, wenn denn alle mitziehen.
Erstmals auch mit Nvidia Blackwell und AMD Turin
Neu dabei ist eine Preview von Blackwell. Und wie die Statuten von ML Commons besagen, muss das Preview-Ergebnis bis zur nächsten Runde mit finaler Hardware bestätigt werden – der Launch der Chips steht also unmittelbar bevor. Das gilt natürlich auch für den von AMD gezeigten Turin-Prozessor.
Das Blackwell-Ergebnis stellt dabei eine einzelne GPU alias B200-SXM-180GB mit 1.000 Watt TGP dar, die vier Mal schneller ist als H100. Das H100-Ergebnis wiederum wurde mathematisch aus einem 8-GPU-Server extrahiert. Im Endeffekt dürfte sich bei entsprechender Skalierung ein Ergebnis von rund 80.000 Token pro Sekunde für einen vollbestückten 8-GPU-Server mit Blackwell einstellen und damit die bisherigen Ergebnisse selbst der 1.000-Watt-H200-Version um mehr als das Doppelte übertreffen. In der nächsten Runde dürfte es soweit sein.

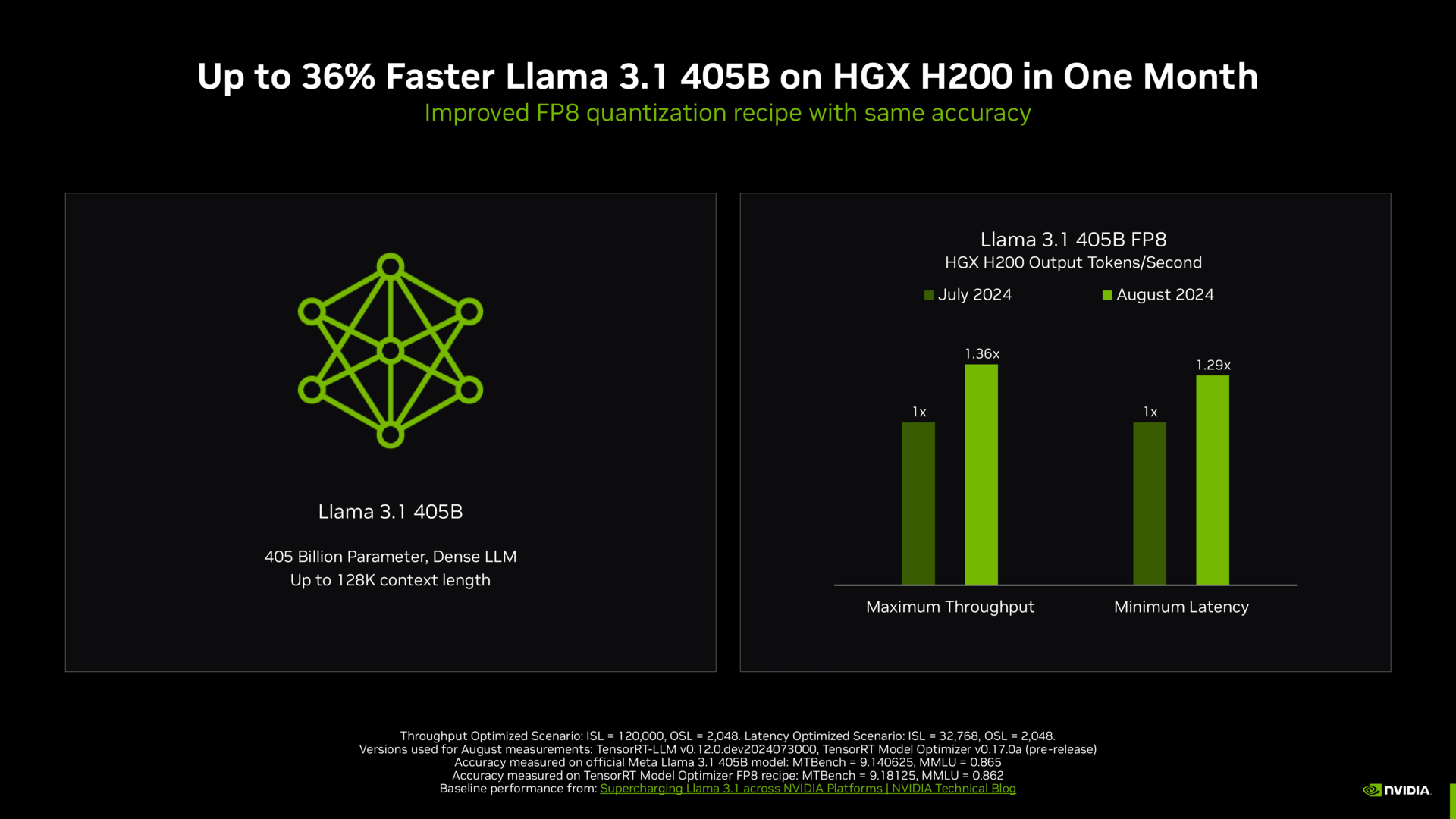
Nvidia wird den Platz an der Sonne so schnell nicht aufgeben. Wie sich die Software bei Nvidia entwickelt hat und wie so immer noch stetig viel mehr Leistung auf gleicher Hardware zutage gefördert wird, sucht ihresgleichen.
Intel Granite Rapids ist auch dabei
Von Intel kommen zur neuen Testrunde nicht nur die üblichen Ergebnisse der aktuellen Xeons, mit Intel Granite Rapids ist auch eine Preview vom neuen Xeon 6P dabei – die gleichen Regeln wie bei Blackwell gelten natürlich auch hier. Dieser Xeon 6980P erzielt im Test eine 1,9-fache Leistung des Vorgängers, was auch ins bisher prognostizierte Bild passt respektive ziemlich genau dem Multiplikator der Kerne entspricht: Ein aktueller Xeon hat bis zu 64 Kerne, Granite Rapids wird im Maximum mit 128 Kernen antreten. Ganz nebenbei bestätigt Intel dabei den Starttermin für die neuen Xeon 6P: Im September ist es im Rahmen eines Launch-Events soweit.
Google Trillium debütiert ebenfalls
Googles im Mai enthüllte sechste Generation der hauseigenen TPU ist ebenfalls erstmals mit von der Partie – auch hier noch als Preview. An die theoretischen Werte, im Mai wurde eine bis zu fünffache Leistungssteigerung genannt, kommt Google heute noch nicht heran, aber es ist ja auch hier quasi erst ein halb-offener Testlauf mit viel Optimierungsspielraum.
This is also Google Cloud’s first MLPerf submission using Trillium (launching later this year), the sixth-generation Tensor Processor Unit (TPU), and the most performant yet. Google Cloud achieved standout performance on the Stable Diffusion XL model, with Trillium delivering a 3.1x and 2.9x throughput improvement for samples/second and queries/second, respectively , compared to its predecessor, TPU v5e.
Google
Ein großer Schritt nach vorn
Die Entwicklung bei den großen Herstellern zeigt, dass ein anerkannter und von allen genutzter Benchmark die Leistung hinsichtlich AI für alle deutlich besser greifen lässt. Nun können Firmen mit gleichem Datensatz Kunden schneller davon überzeugen und ihre Karten ausspielen. Während Nvidia klar der Spitzenreiter in Sachen Leistung ist, können andere vielleicht viel leichter über den Preis oder die Effizienz punkten – eben genau so, wie es ein möglicher Kunde benötigt.
Die finalen Ergebnisse aller getesteten Lösungen präsentiert ML Commons einmal als MLPerf Inference: Datacenter benchmark sowie MLPerf Inference: Edge benchmark.
ComputerBase hat Informationen zu diesem Artikel von ML Commons, AMD, Nvidia und Intel unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.