GeForce GTX 980 im Test 2.0: Technische Evolution mit Warp 32
2/4Technische Evolution mit Warp 32
Maxwell war nach Kepler der zweite radikale Umbau, den Nvidia innerhalb von zwei Generationen vollzogen hat. Der Aufbau der SM – Nvidia nutzte die Abkürzung SMX – besteht aus 192 Shader-Kernen, die sowohl Integer (INT, Ganzzahlen) und Floating Point (FP, Gleitkommazahl) berechnen können. Daten beziehen die Shader-Kerne aus einem Register-File mit 65.536 Einträgen.
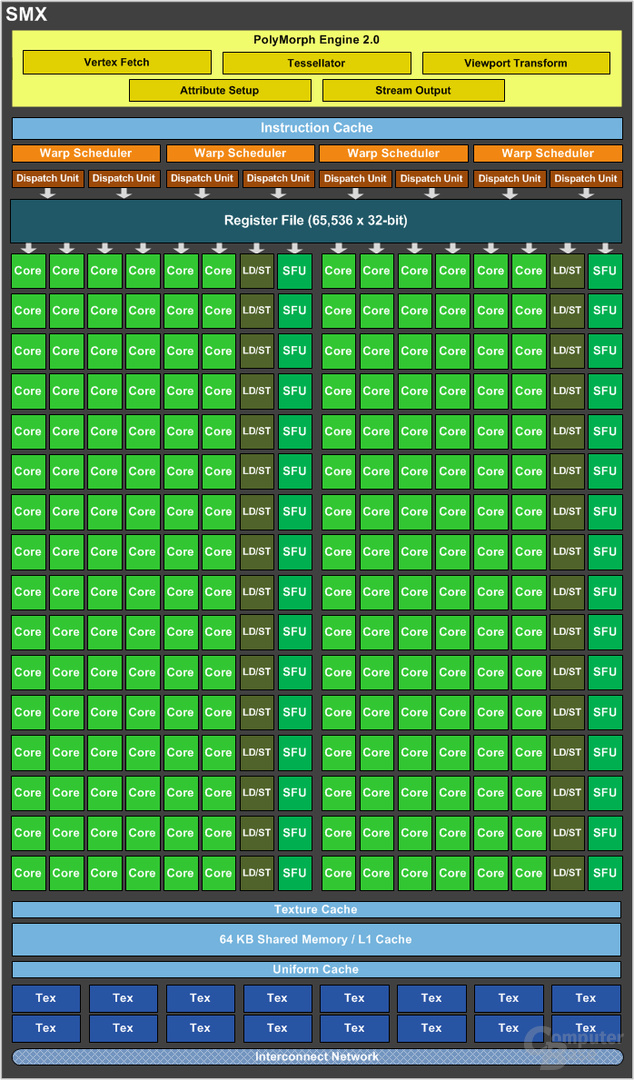
Die 192 Shader-Kerne werden dabei von vier Warp-Schedulern mit Operationen versorgt, sodass auf einer SMX 4 Warps gleichzeitig ablaufen können. Als Warp bezeichnet Nvidia den Zusammenschluss von mehreren Threads. Das Konzept wird als Single-Instruction-Multiple-Threads (SIMT) bezeichnet und ist eine Erweiterung des Single-Instruction-Multiple-Data (SIMD)-Konzeptes. Jeder Warp-Scheduler wiederum kann bis zu zwei Operationen – sofern diese voneinander unabhängig sind – an die Shader-Kerne übergeben. Es können so bis zu 8 Operationen auf den 192 Shader-Kernen berechnet werden.
Nvidia hat dabei eine Affinität zur Zahl 32, in einem Warp werden in der Regel 32 Threads zusammengefasst. 32 Threads pro Warp, bis zu zwei Operationen pro Warp, damit kommen bis zu 256 Werte zusammen, die berechnet werden müssen. In ungünstigen Konstellationen kann es dazukommen, dass zu wenige Rechenwerke vorhanden sind und dadurch Wartezeiten entstehen. Genauso kann es allerdings auch dazu kommen, dass nicht alle Rechenwerke genutzt werden. Beides sind ungünstige Szenarien, gleichzeitig wird jedoch nicht immer gerechnet, sondern es müssen auch Texturdaten angefordert werden, dafür besitzt eine SMX 16 Textureinheiten. Neben einigen anderen Bestandteilen – Instruction-Cache, Texture-Cache – besitzt jede SMX einen 64 KB großen L1-Cache, den sich die 4 Warps pro SMX teilen.
Bei Maxwell hat Nvidia die SMX zur SMM umgebaut und einige Änderungen vorgenommen. Nvidias Devise ist dabei die „power-of-two“. Das führte dazu, dass Nvidia die Shader-Kerne von 192 auf 128 reduziert hat – 2 hoch 7. Diese 128 Shader-Kernen werden zudem nicht mehr in einem großen Block organisiert, sondern in vier einzelnen Kacheln. Jede dieser Kacheln besitzt einen Warp-Scheduler und weiterhin kann dieser bis zu zwei Operationen auf die nun exklusiven 32 Shader-Kernen verteilen.
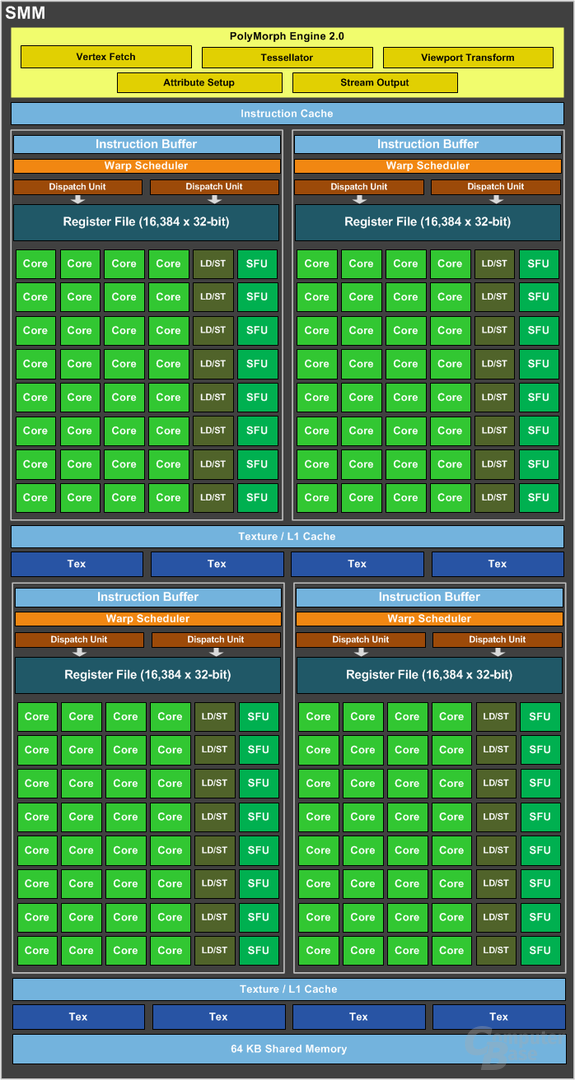
Diese neue Aufteilung verringert die Wahrscheinlichkeit, dass entweder zu viele Operationen auf zu wenig Rechenwerken berechnet werden müssen oder eben den umgekehrten Fall, dass zu wenig Operationen berechnet werden und Rechenwerke ungenutzt bleiben. Daneben hat jede Kachel einen eigenen Instruction-Buffer. Die bisher 16 Textureinheiten wurden auf 8 verringert und in zwei Blöcken aufgeteilt. Vier Textureineiten haben einen eigenen Texture / L1-Cache, der 64 KB große Shared-Cache bleibt erhalten. Diese Änderungen führen laut Nvidia dazu, dass diese neue Partition auf der einen Seite das Design sowie die Scheduling-Logik vereinfacht und dass Wartezeiten verringert werden.
Nvidia nutzt diesen grundlegenden Aufbau auch noch heute bei Ada Lovelace, nur dass die Shader noch einmal geteilt wurden in zwei 16er-Blöcke. Denn eine Schwachstelle hatte Maxwell sowie später Pascal: Alle Rechenwerke mussten den gleichen Datentyp bearbeiten, entweder FP- oder INT-Operationen. Bei Turing löste Nvidia dieses Problem damit, dass 16 der 32 Shader-Kerne exklusiv für INT-Operationen vorgesehen waren.

Bei Ampere wurden die 16 INT-Shader-Kerne um die Funktionalität für FP-Operationen ergänzt. Maxwell und Pascal können entweder eine INT- oder FP-Operation berechnen. Turing kann eine INT- und eine FP-Operation verarbeiten und Ampere sowie Ada Lovelace können zwei FP-, zwei INT- oder eine INT und eine FP-Operation bearbeiten.
Etwas PowerVR bitte
Maxwell hatte neben den umfassenden Änderungen der SMX zu SMM, noch etwas Weiteres im Gepäck, dass Nvidia so allerdings nie wirklich kommuniziert hat, auch wenn in den White-Papers zu Maxwell 1.0 und 2.0 entsprechende Andeutungen zu erkennen sind. Der bisher verwendete Renderer, der das Bild als Ganzes betrachtet hat, wurde durch einen Tiled-Based-Renderer ersetzt. Ein weiterer Teil der gestiegenen Effizienz von Maxwell ist damit gelüftet, auch wenn es fast zwei Jahre gedauert hat, bis im August 2016 AnandTech in einer News diesen Umstand veröffentlichte. Nvidia ist dabei allerdings nicht die Vorreiter dieser Technik im PC, diese Ehre gebührt einer anderen Firma, wobei das an dieser Stelle etwas komplizierter wird und man eher von Firmen schreiben muss. Gemeint ist der ST Kyro von STMicroeletronics – ComputerBase testet im Mai 2001 die Kyro 2 von Hercules. Der ST Kyro wurde aber nicht von STMicroeletronics entwickelt, sondern von Power VR Technologies, die wiederum eine Tochter von Imagination Technologies sind, die ältere Semester noch unter dem Namen VideoLogic kennen. Kompliziert, allerdings bedienten sich Kryo 1 und Kyro 2 bereits 2000 und 2001 einer Technik mit dem Namen Tiled-Based-Deffered-Renderer. In diesem wird das zu rendernde Bild in Kacheln aufgeteilt, was mehrere positive Effekte hat.

Bis Maxwell und bei AMD bis Vega, war der Immediate-Render vorherrschend, hier wurden also bei Full HD quasi alle 2 Mega Pixel direkt betrachtet. Das führte in der Regel dazu, dass überwiegend nicht sichtbare Polygone vollständig mit Texturen gerendert wurden, lagen mehre Polygone übereinander, hat erst im letzten Schritt der Z-Buffer entschieden, welches Polygon beim Pixel sichtbar ist. Mit der Zeit hat sich auch bei dem klassischen Renderer Techniken etabliert, die Polygone, sofern sie unsichtbar sind, ausschließen kann, doch gilt das eben nur dann, wenn das Polygon wirklich nicht sichtbar ist. Einer der Vorteile des Tiled-Based-Renderers liegt darin, dass eine Prüfung der Sichtbarkeit von Polygonen auch nur für Teile des Polygons möglich ist, die genau in der ausgewählten Kachel liegen. Werden nur die sichtbaren Teile eines Polygons gerendert, kann das Bandbreite zum VRAM sparen, nebenbei können die Daten im L2-Cache vorgehalten werden und bei passend gewählten Dimensionen der Kacheln die Arbeitslast besser ermittelt und verteilt werden. Wer sich das Prinzip eines Tiled-Based-Renders einmal „live“ ansehen möchte, kann das relativ einfach mit CineBench tun.