
Intel Lunar Lake im Detail: Die neuen E-Cores schlagen die alten P-Cores, Xe2 löst Xe ab

Intels neues mobiles SoC Lunar Lake entpuppt sich als sehr flottes Gesamtpaket mit einigen großen Überraschungen. Die neuen E-Cores sind schneller als die alten P-Cores, die neuen P-Cores noch einmal flotter. Dazu kommen Xe2-Grafik, die stärkere NPU und aktualisiertes I/O. Der umfangreiche Überblick vom Tech Day aus Taiwan.
Intel Lunar Lake: Chiplets und DRAM vereint
Intel Lunar Lake heißt die neue CPU-Serie des Branchenriesen, die explizit für den mobilen Markt gedacht ist. Wie Meteor Lake (Core Ultra 100) und später im Jahr Arrow Lake (Core Ultra 200) setzt sich das Gesamtkonstrukt aus verschiedenen Chips (Tiles) auf einem gemeinsamen Package zusammen, das erstmals auch den DRAM trägt – Apple Silicon lässt grüßen.
An Lunar Lake durfte sich Intels Design-Abteilung einmal richtig ausleben, Intels Fertigung blieb hingegen fast vollständig außen vor: TSMC übernimmt inklusive Packaging.
Für das Produkt war das allem Anschein nach die richtige Entscheidung, denn heraus kommt ein extrem performantes Gespann, das acht modernste CPU-Kerne (4 P-Cores und 4 E-Cores) sowie die Xe2-iGPU in einer N3-Fertigung von TSMC mit viel mehr Leistung und geringerer Leistungsaufnahme hervorbringt, sodass Intel mit Lunar Lake einen großen Sprung zu machen scheint. Dafür verantwortlich sind viele Anpassungen, auf die dieser Bericht eingehen wird.

Intel Lunar Lake in 8 Stichpunkten
- Mobiles System on a Chip (SoC) mit DRAM auf dem Package (wie Apple Silicon)
- Fertigung und Packaging durch TSMC, nur der „Base Tile“ als Bindeglied kommt von Intel
- 8 Kerne: 4 Performance- (P-Cores) und 4 Efficiency Kerne (E-Cores)
- P-Cores: Lion Cove, +14 % IPC vs. Raptor Cove (14. Gen Core)
- E-Cores: Skymont, +2 % IPC vs. Raptor Cove (14. Gen Core), +68 % IPC vs. Meteor Lake (LPE)
- Die Kerne wird auch Arrow Lake (Core Ultra 200 im Desktop) und ab 2025 Xeon nutzen
- iGPU: Premiere für Xe2 (kommt auch in Battlemage zum Einsatz)
- NPU mit 48 TOPS für Windows Copilot+
Die Lunar-Lake-Vorstellung und was sich daraus für Arrow Lake ableiten lassen könnte, ist auch Thema im ComputerBase-Podcast CB-Funk #71 gewesen (Ab 1:05:00 hh:mm:ss).

Intel Lunar Lake im Detail
Das mit Meteor Lake eingeführte Konzept der verschiedenen Chips, von Intel auch Tiles genannt, wird mit Lunar Lake fortgesetzt. Die wichtigen Bereiche bekommen so ihre dafür passende Fertigung, wenngleich bei Lunar Lake auch etwas mehr zusammengesetzt ist, was bei Meteor Lake noch getrennt war – Stichwort Grafikeinheit und SoC-Tile. Doch dazu später mehr.

Zwei Tiles statt vier bei Meteor Lake
Lunar Lake setzt nur auf zwei Tiles. Da wäre einmal der „Compute Tile“ aus TSMCs N3B-Fertigung, der alle CPU-Kerne sowie die Grafikeinheit einschließt, aber auch viele bis nahezu alle Aufgaben des SoC(-Tiles) bietet. Daran angeknüpft ist ein ein neuer Tile, der „Plattform Controller Tile“, den TSMC in N6 fertigt. Dieser übernimmt einige Dinge, die bei Meteor Lake noch im SoC-Tile steckten, erweitert sie allerdings um den I/O-Bereich, der die Möglichkeiten bietet, die normalerweise ein Chipsatz alias „Plattform Controller Hub“ aufweist – deshalb der Name „Plattform Controller Tile“. So werden aus den vier Tiles von Meteor Lake bei Lunar Lake nur noch zwei.

Intel stellt die Bodenplatte
Die beiden Tiles sitzen zusammen mit einem „Filler“ für ein rechteckiges Format und eine passende Stabilität für einen Kühler erneut auf einer Intel-Bodenplatte und sind mit Foverors mit ihr verbunden. Zum Komplettpaket gehört bei Lunar Lake immer auch Speicher direkt auf dem Package, sogenannter MoP („Memory on Package“). Apropos Package: TSMC baut am Ende alles zusammen.
Dass Lunar Lake nun schon im B0-Stepping in der Serienproduktion geht, ist natürlich auch TSMC zu verdanken. Intels eigene Fertigung sorgte in den letzten Jahren oft für Verzögerungen, weil unzählige Steppings aufgelegt werden mussten, um die Ziele zu erreichen. N3B ist der zweite TSMC-Prozess der 3-nm-Generation, Apple nutzt ihn ebenfalls. Nun kann Intel erstmals seit vielen Jahren wieder mit halbwegs gleichen Vorzeichen an den Start gehen.

Der neue P-Core: Lion Cove bringt +14 % IPC auch ohne Hyper-Threading
Intel Lunar Lake bekommt die nächste Generation der Performance-Kerne (P-Core). Sie werden auch in anderen Prozessoren verbaut werden, wenngleich die Ausführung in Lunar Lake explizit nur für diese Variante ist. Denn einige der markanten Änderungen für das mobile und auch in Kürze folgende Client-Segment greifen im Server-Bereich später nicht. Doch der Reihe nach.
-
 Intel The Lion Cove Architecture (Bild: Intel)
Intel The Lion Cove Architecture (Bild: Intel)

Lion Cove folgt Redwood/Raptor Cove
Lion Cove heißen die neuen vier Performance-Kerne. Sie folgen auf Redwood Cove (RWC) in Meteor Lake und Golden Cove (Alder Lake, 12. Gen Core) respektive deren Überarbeitung Raptor Cove (Raptor Lake, 13./14. Gen Core), in Anlehnung an Intels frühere Fertigungsschritte auch gern Golden Cove+ genannt. Redwood Cove war in vielen Dingen ohne IPC-Gewinne jedoch eher enttäuschend, wurde deshalb auch Golden Cove++ genannt. Mit Lion Cove gibt es nun wieder echte Änderungen und somit deutliche Zugewinne.

Hyper-Threading nur noch im Server
Eine der größten Anpassungen hat das Thema „Hyper-Threading Technology“ (HTT) erfahren. Es wurde bei den Lion-Cove-Kernen entgegen bisherigen Mutmaßungen zwar nicht komplett entfernt, wird jedoch für die mobilen und Client-Produkte nicht mehr aktiv sein. Im Server hingegen, wo die Kerne später auch genutzt werden, ist Hyper-Threading weiterhin mit dabei.
Zu dem Thema HTT holte Intel deshalb im Rahmen des Vorab-Events auch noch mal etwas weiter aus. HTT war nie eine Technologie, mit der man alles erschlagen konnte, man gewinnt aber in einem gewissen Umfeld viel Leistung zu relativ geringen Kosten. Das ist auch heute noch so, allerdings hat sich der Markt geändert und die hybride Architektur Einzug gehalten. Im Low-Power-Bereich können viele der Aufgaben nun eben die E-Cores übernehmen, die viel schneller geworden sind und trotzdem wenig Energie verbrauchen. Für HTT müssen hingehen immer die zwar noch leistungsstärkeren, jedoch auch deutlich energiehungrigeren P-Cores aktiv sein – die Rechnung geht im mobilen Umfeld nicht auf.
-
 Intel The Lion Cove Architecture (Bild: Intel)
Intel The Lion Cove Architecture (Bild: Intel)




Noch in den letzten Generationen sorgte Hyper-Threading für 30 Prozent mehr Leistung und so 20 Prozent mehr Performance bei gleicher Spannung/Takt – ohne dafür groß Platz in Anspruch zu nehmen. Vor allem im Profibereich gibt es deshalb keine Alternative, im Datacenter wird diese Leistung auch in Zukunft mitgenommen.

Die Weiterentwicklung der Scheduler im Betriebssystem weist nun zuerst den P-Cores die Aufgaben zu, dann den E-Cores, als Letztes den Hyper-Threading-Cores. Für spezielle Aufgaben sind sogar zuerst die E-Cores gesetzt, erst dann alles andere.
Für Lunar Lake hat sich Intel die Sache mit den P-Kernen und HTT noch einmal genauer angesehen. Ein explizit auf den Einsatz ohne HTT ausgelegter Kern kann am Ende hier sogar schneller arbeiten. Mit HTT würde man zwar noch immer die Betrachtung Leistung pro Fläche gewinnen, jeden anderen Bereich allerdings nicht. Deshalb fliegt dieses Feature im mobilen Bereich genauso heraus wie später im Desktop.
Breiteres Front End mit überarbeiteter Sprungvorhersage
Lion Cove kommt laut Intel mit einer fundamental geänderten Sprungvorhersage daher. Der sogenannte „Prediction Block“ ist bis zu acht Mal größer als zuvor, ohne dabei jedoch an Treffergenauigkeit einzubüßen – die Stärke von Intel. Um dies dann auch nutzen zu können, wurden die Bandbreiten drum herum deutlich gesteigert, damit es hier zu keinem Flaschenhals kommt.

Das gilt auch für den Micro-op-Cache, den Intel nun seit Jahren aufbietet: Da sich viele Befehle und Anfragen an einen CPU-Kern wiederholen, werden sie in einem Cache zwischengespeichert und können von dort sehr energiesparend direkt abgerufen werden, ohne dabei die Fetch- und Decode-Pipeline erneut hochfahren zu müssen. Der neue uOP-Cache stellt nun pro Cycle 12 uOPs zur Verfügung, zuvor waren es 8. Der komplette Cache kann jetzt über 5.250 uOPs vorhalten (zuvor 4K), im Queue sind 192 uOPs hinterlegt statt zuvor 144.
Out-of-Order-Engine wird geteilt und wächst
Bisher wurden die Datensätze aus dem Front End kommend von einem Scheduler an alle Ausführungseinheiten zugewiesen. Das erwies sich jedoch zuletzt als zunehmend wenig effizient, denn die Skalierbarkeit wurde stark eingeschränkt. Auf der anderen Seite gab es zu viel Overhead. Mit Lion Cove räumt Intel damit auf: Integer- und Vektor-Einheiten haben nun ihren eigenen Scheduler. Damit schlägt der Konzern mehrere Fliegen mit einer Klappe. Die Effizienz steigt bei kleineren CPUs an, für größere Lösungen können Integer- und/oder Vektor-Einheiten nach Bedarf separat ausgebaut werden.


Wird das Front End breiter, muss es auch das anschließende werden. Dies beginnt bereits bei der Zuweisung und führt letztlich zu den Execution-Ports alias Ausführungseinheiten: 18 sind hier nun gesetzt, das ist eine deutliche Steigerung von 50 Prozent. Die Register-Files wuchsen ebenfalls mit. Davon profitieren beide Seiten: Integer-Berechnungen können paralleler ausgeführt werden und steigern so die Leistung, auf der Vektor-Seite gilt Ähnliches. Vor allem die Verdoppelung der „FP Divider“ sorgt je nach Szenario für einen größeren Leistungssprung.


Intel geht den Apple-Weg: Mehr Cache für alle!
Das Herz des Speicher-Subsystems sind die Caches. Hier hat Intel deutliche Überarbeitungen vorgenommen und schwenkt dabei ein wenig auf den Apple-Weg ein. Apple erschlägt seit Jahren in den SoC vieles mit vergleichsweise riesigen Caches und gewinnt so an Leistung. Das war im x86-Bereich und mit älterer Fertigung nicht so leicht umzusetzen, ohne direkt am Reißbrett anzufangen: Denn beim Cache geht es stets um das ausgewogene Verhältnis von Bandbreite, Latenz und Kapazität – und das auch noch unter Berücksichtigung einer bestimmten Fläche und im Rahmen einer gewissen Menge an Energie.

Mit Lion Cove klappt dieser Sprung nun. Der komplett überarbeitete Cache bietet sehr hohe Bandbreiten bei geringer Latenz. Gleichzeitig bleibt er skalierbar – Server-CPUs mit Lion Cove werden noch größere Caches nutzen können.
Aus dem bisherigen L1D-Cache wird jetzt quasi ein L0-Cache mit ganz ähnlichen Parametern wie zuvor. Er ist für die 48 KByte mit 4 Cycles Latenz statt bisher 5 sogar noch flotter unterwegs. Daran anknüpfend folgt nun ein Zwischenschritt, der auf halbem Weg zum L2-Cache liegt. Dieser ist 192 KByte groß und ziemlich schnell, sodass noch deutlich mehr Daten für den Kern mit sehr geringer Latenz verfügbar werden – das steigert die IPC. Das wiederum hat dann ebenso zur Folge, dass der L2-Cache noch einmal wachsen kann – ohne die Strafen, dass die Latenz für wichtige Datensätze zu hoch wird, die jetzt bereits im neuen L1-Cache sitzen können. Lunar Lake wird so mit 2,5 MByte L2-Cache auskommen, für Arrow Lake gibt es 3 MByte L2-Cache pro P-Kern.

Eine dritte „Store Adress Generation Unit“ und weitere Steigerungen im Bereich der DTLB-Pages des Memory-Subsystems runden die Verbesserungen in dem Segment ab. Ergänzt werden die Caches auch noch von einem L3-Cache als letzte Stufe: 12 MByte wird dieser bei Lunar Lake groß sein.
Taktanpassungen nun in 16,67-MHz-Schritten
Seit Jahren ist der Taktzuwachs in 100-MHz-Schritten, auch „Bins“ genannt, bei Intel gesetzt. Bei Lunar Lake übernimmt eine viel feinere Abstufung in Form von 16,67-MHz-Schritten. Dies erlaubt es, je nach Anfrage an die Leistung viel feiner und damit effizienter ans Werk zu gehen. So kann das Powerbudget der CPU noch besser ausgenutzt werden: Wird wie im Beispiel eigentlich bei 3,08 GHz gedeckelt, weil es das Powerbudget erlaubt, wäre es bei der theoretischen CPU nach bisherigem Standard durch ihre 100-MHz-Schritte bei 3 GHz der Fall. Fortan sind schon durch diese Anpassung 2 Prozent mehr Takt und damit Leistung möglich.
-
 Intel The Lion Cove Architecture (Bild: Intel)
Intel The Lion Cove Architecture (Bild: Intel)

10 bis „>18 Prozent“ höhere IPC
Die neuen Lion-Cove-Kerne bieten im Neuaufbau in den Lunar-Lake-Prozessoren durchweg einen zweistelligen IPC-Zuwachs gegenüber Redwood Cove in Meteor Lake. Im Bereich geringer Leistungsaufnahme liegt dieser mit „>18 Prozent“ auf dem höchsten Niveau, fällt dann mit steigender Leistungsaufnahme stetig etwas ab. Im Durchschnitt nennt Intel +14 Prozent.

Unterm Strich stellt Lion Cove die größte Änderung seit Jahren im Bereich der Performance-Kerne dar. Einige Dinge wurden grundlegend neu aufgebaut und stellen so die Basis für kommende Generationen dar. Dazu zählt auch, dass Intel die Fesseln mit der eigenen Fertigung über Bord geworfen hat: Früher wurde eine Intel-CPU mit eigenen Tools für die eigene Fertigung gebaut. Lion Cove ist die erste, die nun Standard-Tools nimmt und eben voll auf Fremdfertigung setzen kann und setzt. Kleine „Functional Blocks“ (Fubs) werden ersetzt, neue Features können viel schneller hinzugefügt oder auch abgewählt werden. Arrow Lakes Lion Cove unterscheiden sich deshalb in einigen Bereichen des Kerns deutlich, betonte Intel in dem Zusammenhang.

Die neuen E-Cores sind der Star
Intels hybride Architektur steht seit Jahren auch für Efficiency-Kerne (E-Cores), also kleine Prozessorkerne, die effizient und über eine gesteigerte Anzahl wahlweise auch viel Leistung bieten sollen, vor allem für den alltäglichen Bedarf. Die Leistung lag dabei allerdings deutlich unter dem Niveau der P-Cores.
Skymont so schnell wie Raptor-Cove-P-Cores
Mit der neuen Generation, Codename Skymont, hebt Intel die aus der Atom-Sparte entstandenen Kerne auf eine derart neue Stufe, dass sie diese Altlasten nun wirklich hinter sich lassen können. Denn die vier E-Kerne in Lunar Lake bieten fortan die Leistung, die mit Raptor Cove in der 14. Core-Generation aktuell im Desktop verkauft wird. Der Sprung ist gewaltig.

Der Ansatz für die neuen E-Cores waren die Low-Power-E-Cores im SoC-Tile der Meteor-Lake-Chips. Die sind dazu gedacht, kleinste Aufgaben zu übernehmen, ohne die großen Kerne zu starten. Dort setzt Skymont an.
Front End nun mit 3-×-3-Cluster und Nanocodes
Skymont startet mit einer verbreiterten Sprungvorhersage. Alles wird etwas schneller und genauer, zuverlässiger durch die Bank weg. In den letzten Jahren hat Intel bereits „Cluster“ beim Decoder in den „Atoms“ eingesetzt – seit Tremont um genau zu sein. Dies wird fortgeführt. Bisher gab es zwei Cluster, nun werden es drei. Dies soll ohne großen Einfluss auf die Flächennutzung oder andere Parameter geschehen und extrem effizient sein. Alles, was Intel in den letzten drei Generationen aus diesem Ansatz gelernt hat, fließt nun in Skymont.
-
 Intel Next Gen E-core The Skymont Architecture (Bild: Intel)
Intel Next Gen E-core The Skymont Architecture (Bild: Intel)

Nanocode heißt eine der Neuheiten in den Clustern im Front End. Dahinter verbirgt sich ein kleiner Decoder im jeweiligen Cluster, der gewöhnliche und auch spezifische Befehle abarbeiten kann. Der dreifache Ansatz ermöglicht eine große Parallelisierung und stellt so viel mehr Bandbreite zur Verfügung, sodass viele Befehle an das Back End geliefert werden. Der Micro-op-Queue, also die Warteschleife, steigt so ebenfalls um 50 Prozent an.

Das Back End wird deutlich breiter
Gracemont war lediglich 5-wide, es konnten pro Cycle fünf Befehle abgearbeitet werden. Gracemont in Meteor Lake steigerte dies auf 6-wide, mit Skymont geht es nun auf eine 8-wide-Architektur. 8 uOPs per Cycle werden nun vom Front End in das Back End geliefert. Ein verdoppeltes Retirement macht schneller Ressourcen frei, um wieder neue uOPs in Empfang zu nehmen und weiter verarbeiten zu können.


Da alles breiter wird, müssen auch die folgenden Einheiten skaliert werden. Größere Buffer, viel mehr Einträge in Registern – alles wurde gesteigert. Am Ende führt dies zu insgesamt 26 Dispatch-Ports. Intel verfolgt dabei den Ansatz, dass zugewiesene Funktionalität in gewissen Bereichen deutlich effizienter vonstatten geht. Es wird also nicht jeder Scheduler geteilt, sondern eben auch mal direkt zugewiesen. Dies wiederum erlaubt dann parallelisiertes Ausführen. So gibt es acht Integer-ALUs, vor allem aber die Vektor-Seite bekommt einen Schub: Statt bisher zwei 128-Bit-FP-Einheiten sind es nun vier 128-Bit-Floatingpoint-Pipelines. Hinzu kommen deutliche Latenzverbesserungen in dem Bereich – mehr Bandbreite bei gleichzeitig geringerer Latenz sind hier quasi eine Win-win-Situation.


Mit all den zusätzlichen Hardware-Bausteinen vor allem im Vektor-Segment muss auch der Rest folgen. Der sogenannte Load/Store-Bereich wird deutlich aufgewertet, der L1D-Cache bleibt aber bei 32 KByte. Der 4 MByte große L2-Cache wird über vier E-Cores geteilt – das ist der sogenannte Vier-Kern-E-Core-Cluster. Die interne Bandbreite des L2-Caches wurde dabei verdoppelt, auch werden im Cache vorhandene Daten schneller und direkter zugewiesen, ohne Umwege über den Fabric zu nehmen.

Gegenüber Meteor Lakes LPE-Cores gewinnt man bis zu 68 Prozent IPC
Lohn dieser Anpassungen ist eine deutlich höhere IPC. In Integer-Tests sieht Intel die neuen Skymont-Kerne in Lunar Lake um 38 Prozent vor den LPE-Kernen in Meteor Lake. Werden die Vektor-Einheiten getestet, erhöht sich der Wert sogar auf 68 Prozent. Dabei gibt es keinen einzigen Fall, in dem geringere Leistung als bisher herauskommt. Durch die Bank sind starke Steigerungen zu verzeichnen.

Wird das etwas näher betrachtet und auf des Thema Leistung zu Leistungsaufnahme heruntergebrochen, sieht das Bild für Lunar Lakes Skymont-Ansatz entsprechend stark aus: Ein einzelner Kern braucht heute nur noch ein Drittel der Energie für die gleiche Leistung. Wird die gleiche Energie zugeführt, gewinnt der Skymont-Kern in Lunar Lake 70 Prozent Performance. Und am Ende ist das Design sogar noch so flexibel, dass es mehr Energie verträgt, sie umsetzen und so am Ende die Leistung verdoppeln kann.


Von Single Core auf Multi Core umgelegt, bleibt das Bild erhalten. Bei gleicher Leistung liefern die vier Skymont-Kerne 2,9-fache Performance der zwei LPE-Cores in Meteor Lake. In der Spitze wird die Leistung vervierfacht. Lunar Lakes E-Core-Cluster ist also drei bis vier Mal schneller als der LPE-Cluster in Meteor Lake.
Exakt dieser letzte Punkt macht klar, warum die E-Cores nun viel mehr Aufgaben übernehmen können. Die LPE-Cores von Meteor Lake waren zu schwach für etwas mehr als Videos ansehen. Nun laufen auch Teams und Co stets nur auf den E-Cores, der komplette Chip bleibt so extrem effizient und spart Energie.
Skalierbarkeit von Low Power bis hoher Multi-Core-Durchsatz
Skymont wird in Lunar Lake debütieren und dort als „Mobile Low Power Island“ arbeiten. Es gibt keinen Ringbus, keinen L3-Cache; effizienter sollen Daten verarbeitet werden. Der Unterschied zwischen E-Cores an einem Ring mit LLC oder nicht liegt laut Intel aber nur bei rund 5 Prozent. Skymont wird in Zukunft auch in „Compute Tiles“ integriert und dort in den Ringbus eingebunden werden. Dann gibt es für die Kerne auch Zugriff auf den L3-Cache. Es wird das von Raptor Lake bekannte Schema umgesetzt.


Wie stark Skymont letztlich ist, zeigt sich beim Vergleich zum aktuellen P-Core Raptor Cove. Skymont wird nicht das 6-GHz-Taktniveau dieses Chips erreichen, aber auf gleichem Niveau liefert Skymont heute 2 Prozent mehr IPC als Raptor Cove. Hier ist die Betrachtung allerdings gemischt. Es gibt auch Anwendungen, in denen Skymont zurückliegt, in anderen dafür weit vorn. Unterm Strich lässt sich sagen, dass die IPC von Skymont und Raptor Cove die gleiche ist.

Da Skymont aber nicht im gleichen Frequenz- und TDP-Rahmen angesiedelt ist, sondern weiter unten, kann die Architektur die Vorteile besser ausspielen. Gegenüber Raptor Cove braucht es für die gleiche Leistung nur 60 Prozent der Energie – oder es liefert alternativ bei gleicher Energie 120 Prozent Performance.

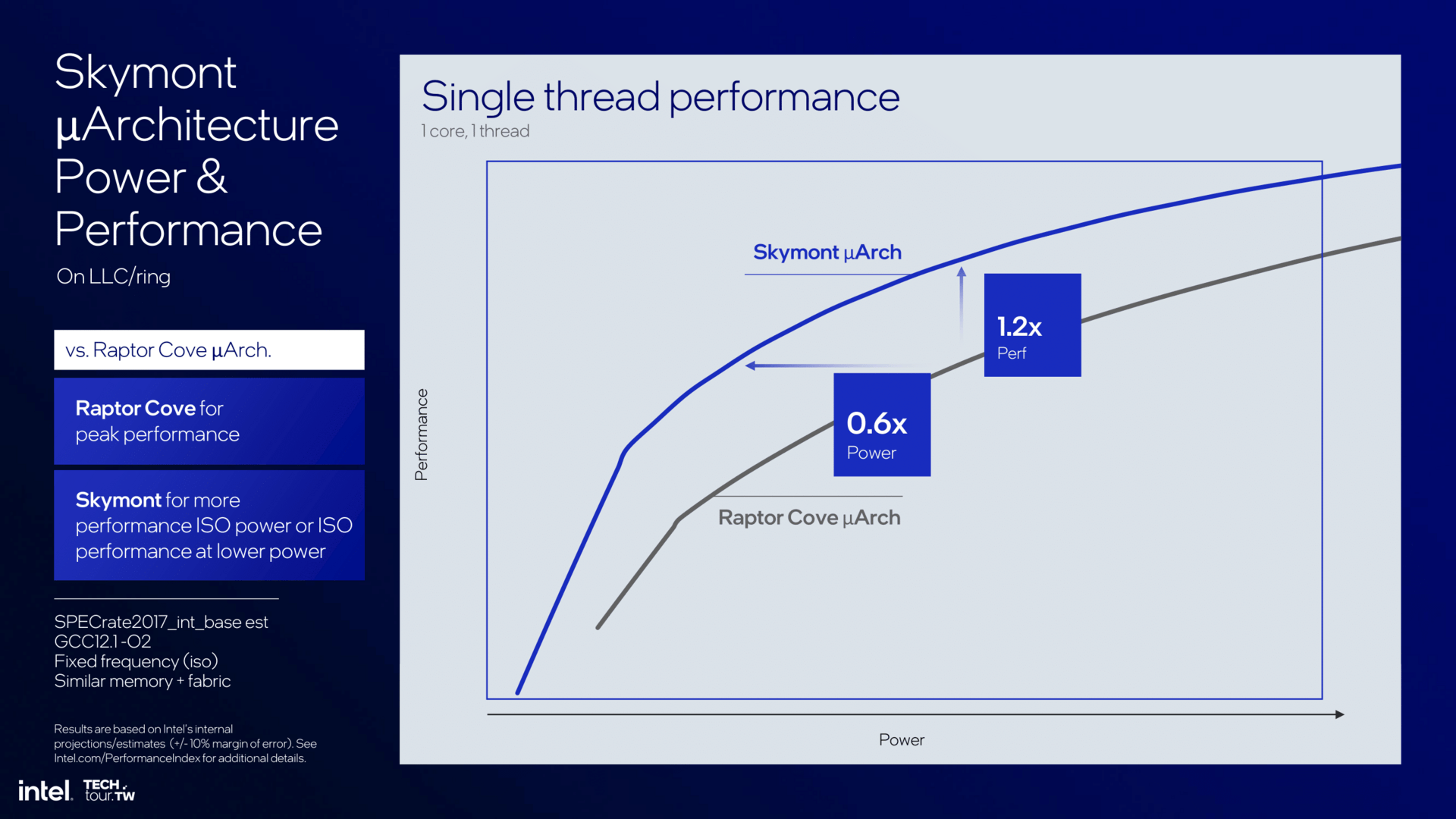
Anhand der vorhandenen Daten zu Skymont lassen sich nun einige Hochrechnungen anstellen. Denn die Architektur für die E-Kerne wird bekanntlich auch in Arrow Lake und damit in den Desktop Einzug halten. Die Multi-Core-Leistung der Lösungen dürfte sich gegenüber dem Vorgänger, sofern es keine größeren Einschränkungen im Takt gibt, deutlich erhöhen. Gleiches gilt dann auch für den Server-Prozessor Intel Clearwater Forest. Intel versprach ja bereits deutliche Zugewinne gegenüber dem jetzt startenden Sierra Forest: Sie könnten am Ende also noch etwas deutlicher ausfallen.
Die „Battlemage-Architektur“ von Lunar Lake
Als Grafikeinheit setzen die Lunar-Lake-Produkte auf eine neue GPU-Architektur mit der Bezeichnung „Xe2“. Sie wird auch die Basis für Battlemage, Codename für die Basis der 2. Generation der Arc-Grafikkarten, sein.
Tiefergehende Details zu den Veränderungen von Xe zu Xe2 liefert der Artikel Intels Xe2-Architektur für Lunar Lake und Arc 2.0 im Detail. An dieser Stelle geht es um die Umsetzung bei der iGPU des Lunar-Lake-SoC.
-
 Intel Xe 2 „Battlemage“ (Bild: Intel)
Intel Xe 2 „Battlemage“ (Bild: Intel)

So sieht die Lunar-Lake-Xe2-GPU aus
Lunar Lake setzt konkret auf 2 Render-Slices mit insgesamt 8 Xe-Kernen und damit 64 XVE-Einheiten. 1.024 FP32-ALUs sollte Lunar Lake damit aufweisen, diese Zahl erwähnt Intel aber nicht separat. Darüber hinaus gibt es 8 Textur- sowie Raytracing-Einheiten, 4 ROPs und einen 8 MByte großen L2-Cache.
Lunar Lake Gaming-Performance
Für die Leistung der Grafikeinheit von Lunar Lake präsentierte Intel in Taipeh keine Spiele-Benchmarks, es gab aber eine Angabe zur „GPU-Performance“: Sie soll rund 50 Prozent höher als beim direkten Meteor-Lake-Vorgänger ausfallen, was von Modell zu Modell jedoch variieren kann. Laut Intel soll die GPU in F1 24 bei unbekannter Detailstufe in Full HD in Verbindung mit XeSS „Performance“ selbst mit aktiviertem Raytracing 60 FPS und mehr erreichen. Darüber hinaus soll die neue GPU sowohl gegenüber Meteor Lake U als auch Meteor Lake H deutlich energieeffizienter arbeiten, ganz gleich ob eine geringe oder eine hohe Last anliegt.
-
 Intel Lunar-Lake-GPU – Effizienzsteigerungen (Bild: Intel)
Intel Lunar-Lake-GPU – Effizienzsteigerungen (Bild: Intel)

AI soll doppelt so schnell werden
AI spielt bei Lunar Lake eine wichtige Rolle. Die GPU (nicht NPU!) liefert mit den 64 XMX-Einheiten eine theoretische Rechenleistung von 67 TOPS bei einer Präzision von INT8. In einem vor Ort ausgeführten Stable-Diffusion-Benchmark war das neue Produkt dabei doppelt so schnell wie der Vorgänger.
Die Display-Engine unterstützt einen neuen Standard
Lunar Lake kommt mit einer neuen Display-Engine daher, die nun Monitore mit bis zu 8K60 HDR, 3 × 4K60 HDR oder 1.440/1.080 360 Hz ansprechen kann. Neben HDMI 2.1 werden auch DisplayPort 2.1 und der ganz neue Standard eDP 1.5 beherrscht. Maximal vier verschiedene Ports kann die GPU insgesamt unterstützen, wovon bis zu drei HDMI oder DisplayPort entsprechen können und einer eDP.
eDP 1.5 ist ein Standard, der explizit für Notebook-Displays entwickelt wurde. Die GPU kann dabei nun noch effektiver die Refreshrate vorgeben, auch Videos können so jetzt stotterfrei wiedergegeben werden. Bei einem 24-FPS-Film wird das Display dann einfach mit 48 Hz angesteuert.
-
 Intel Lunar-Lake-GPU – die Display-Engine (Bild: Intel)
Intel Lunar-Lake-GPU – die Display-Engine (Bild: Intel)








Darüber hinaus kann bei eDP 1.5 effektiver gesteuert werden, welcher Teil des Monitors aktualisiert wird, was den Energieverbrauch sinken lässt. Das reduziert die benötigte Leistungsaufnahme, was die Hauptaufgabe des neuen Standards ist. Intel nennt vor allem bei der Videowiedergabe größere Gewinne. Die Leistungsaufnahme der Datenübertragung an das Display soll sich im besten Fall in etwa dritteln.
Auch die Media Engine beherrscht einen neuen Codec
Wenig verwunderlich hat Intel auch die Media Engine umgebaut. So unterstützt Lunar Lake neben den bekannten Codecs AVC, VP9, HEVC und AV1 auch VVC bzw. H.266 als Nachfolger von HEVC (H.265).
-
 71 (Bild: Intel)
71 (Bild: Intel)







VVC soll gegenüber AV1 die Dateigröße eines Videos um rund 10 Prozent bei vergleichbarer Qualität reduzieren. Darüber hinaus soll es der Codec ermöglichen, dass beim Videostreaming durch intelligentes Puffern völlig unterbrechungsfrei die Auflösung gewechselt werden kann, bei aktuellen Codecs gibt es immer einen kleinen Haker. Darüber hinaus wurde der Codec für die Darstellung von klassischen Bildschirminhalten optimiert, während bisherige Codecs allesamt ausschließlich auf Filmwiedergabe optimiert worden sind. Damit soll zum Beispiel Schrift bei Remote-Desktop-Funktionen deutlich besser aussehen. Und zu guter Letzt soll der neue Codec für 360-Grad-Videos ausgelegt sein.
Davon abgesehen kann die neue Media Engine Videos mit bis zu 8K60 bei 10 Bit und HDR de- oder encodieren.

Die NPU wächst deutlich an und kann mehr
Die NPU 4, wie Intel sie nennt, ist zwei Mal so effizient wie die vorangegangene Version und bietet bis zu 48 TOPS – 3 mehr als Snapdragon X und zwei hinter AMD Ryzen AI 300. Meteor Lakes NPU deckelt bei 11,5 TOPS, die Leistung wird also mehr als vervierfacht. Mit Myriad X als erste Generation nahm das 2018 den Anfang. Keen Bay folgte mit der NPU der zweiten Generation, einige Windows-Studio-PCs wurden damit ausgestattet. Immerhin brachte diese Lösung bereits 7 TOPs.

Intel stellt direkt klar, dass alles, was auf Meteor Lake läuft, natürlich auch auf Lunar Lake funktioniert. Eine verbesserte Architektur basiert auf vielen kleinen Anpassungen, aber auch die gesteigerte Frequenz trägt zu erhöhter Leistung bei. Meteor Lake hat Defizite beim Takt und ebenso im Bereich Vektor-Compute.

Von der NPU 3 auf die NPU 4 werden viele Elemente verdreifacht, es gibt sechs Neural-Compute-Engines-Blöcke. Wie bereits erwähnt, spielen die Leistung, der Takt und die Leistungsaufnahme eine große Rolle: Bei gleicher Energie liefert die NPU 4 die doppelte Performance. Dass der Peak-Wert viel höher ausfällt, ist dabei zum Teil nebensächlich, denn Effizienz zählt im mobilen Bereich. Vergrößerte Caches und höhere Bandbreiten runden das Paket in dem Segment ab.

Bis zu 120 TOPS für AI hat sonst keiner
Stück für Stück hat Intel in den letzten Monaten auch an der AI-Leistung geschraubt. Hieß es erst, die dreifache Performance von Meteor Lake werde geboten, wurde dies seit einigen Wochen über die Marke von 100 TOPS gehievt, um so auch der Konkurrenz etwas Wind aus den Segeln zu nehmen. Die finale Angabe lautet nun sogar bis 120 TOPS, die Intels Lunar Lake damit für heute zum König machen.

Die neue NPU kommt dabei auf 48 TOPS. Den Großteil schultert hingegen die überarbeitete Xe-Grafikeinheit alias Battlemage, die es nun auf satte 67 TOPS selbst in dem kleinen integrierten Rahmen bringt. Das ist in dem Bereich 2,5 Mal mehr, als der Vorgänger bieten konnte. Und der fehlende Rest: Ja, auch CPU-Kerne liefern einige TOPS für AI-Anwendungen, das 4P+4E-Setup liefert dementsprechend den fehlenden Rest von rund 5 TOPS.
AMDs Strix Point ist etwas weniger performant. Die NPU liefert 50 TOPS, das Gesamtpaket laut aktuellster zum neuen Ryzen AI HX 9 370 Produktseite 80 TOPS. Qualcomms Snapdragon Elite X sind beide x86-Lösungen aber gewachsen, vor allem dank des Zusammenspiels aus der ziemlich ähnlichen NPU und einer starken GPU, bei der Qualcomm nicht in einer Liga spielt.
Unabhängig davon gestand Intel in Taipeh auch ein, dass es bisher keine Anwendungen gibt, die CPU, GPU und NPU parallel in Beschlag nehmen können – die Gesamt-TOPS sind damit nicht mehr als ein theoretischer Wert.
Auch noch im „Compute Tile“: Memory-Side-Cache und mehr
Gehen die Daten vom Chip nicht mehr einen Umweg zum Speicher, sondern sprechen sie ihn direkt nebenan an, spart dies viel Energie. Ein 8 MByte kleiner Zwischenspeicher auf dem „Compute Tile“ dient hier als zusätzlicher Helfer für gleich mehrere Bereiche einschließlich CPU, GPU sowie NPU und kann sogar Anfragen, die eigentlich an den RAM gehen sollten, abfangen.


Dieser ist ergänzend zu dem Cache verfügbar, den jeder Bereich sein Eigen nennt, wie beispielsweise die 12 MByte L3-Cache, die nur die P-Cores nutzen. Da die E-Cores nicht mehr an einem Ringbus hängen, ist dieser über das neue NoC („Network on a Chip“) auch der kürzeste Weg, um zu den P-Cores zu gelangen. Der Memory-Side-Cache kann hier also auch als so etwas wie der L3-Cache der E-Cores gesehen werden.
Ein PCT und Speicher komplettiert das Package
Der „Platform Controller Tile“ (oder Chipsatz, zuletzt zum Teil auch I/O-Tile genannt) beherbergt die für die Kommunikation zur Außenwelt wichtigen Dinge.
-
 Intel Keynote Day 1 (Bild: Intel)
Intel Keynote Day 1 (Bild: Intel)

Thunderbolt 4 ist nach wie vor integriert, mindestens zwei, manchmal auch drei Ports. Auf dem Chip ist obendrein Wi-Fi 7 integriert, Bluetooth 5.4 rundet das Paket ab. PCI Express wird über vier Lanes nach 5.1-Standard und vier Lanes nach 4.0-Standard geboten – vornehmlich für Storage. Auch Gigabit-LAN ist mit dabei. Zwei USB-3.0- und sechs USB-2.0-Buchsen für Legacy-Hardware fehlen ebenso wenig.


Im PCT steckt aber auch die Security-Engine, die alle bekannten Dinge inklusive CSME enthält, jedoch ebenso Neuheiten wie eine Partner-Security-Engine bietet.
Zusammengesetzt wird das Ganze wie folgt: Der Intel-basierte Base-Tile in der Fertigungsstufe P1227.1 bildet die Grundlage. Darauf sitzt der in TSMC N3B gefertigte „Compute Tile“ mit allen CPU-Kernen, der NPU und auch der Grafik, ergänzt vom „Platform Controller Tile“ aus TSMCs N6-Fertigung. Die Stromversorgung wurde komplett überarbeitet, jeder Bereich lässt sich einzeln ansteuern. Vier Power-Controller-Chips sorgen für die Verteilung und die hohe Effizienz.
-
 Intel Keynote Day 1 (Bild: Intel)
Intel Keynote Day 1 (Bild: Intel)


Der Speicher auf dem gleichen Package ist eine der Neuerungen, die vor allem für die Kundschaft interessant ist: OEM-Fertiger haben nun viel mehr Spielraum zur freien Verfügung, da alle wichtigen Bauteile bereits auf dem einzelnen Package verbaut sind. Bis zu 32 GByte LPDDR5 können bei Lunar Lake verbaut werden, maximal mit 8.533 MT/s.

Der Thread-Director wird noch besser
Mit Alder Lake eingeführt, hat sich der Thread-Director zu einem Must-have entwickelt. Der neue Thread-Director wird noch intelligenter, er soll beispielsweise anhand der Ausnutzung erkennen, ob eine Anwendung wirklich einen P-Core braucht oder ein E-Core doch reicht. Bei Lunar Lake ist der Ausgangspunkt in der Regel der E-Core – bei anderen CPUs kann sich dies je nach Einsatzgebiet aber ändern. Je nach Arbeitsumfang wird das dann von einem E-Core skaliert über weitere E-Cores oder gar P-Cores.
-
 Intel Lunar Lake Architecture Session Highlights (Bild: Intel)
Intel Lunar Lake Architecture Session Highlights (Bild: Intel)







Natürlich muss auch weiterhin das Betriebssystem mitspielen. Hier arbeitet Intel nach wie vor mit allen Partnern der Branche zusammen, um das zu gewährleisten.
Ersteindruck: Vielversprechend, ab Herbst im Handel
Mit Lunar Lake will Intel einen großen Schritt nach vorn machen. Dafür hat das Unternehmen an so vielen Stellen umgebaut, dass ein ganz neues Produkt entstanden ist. Und dass man dabei auf Intels eigene Fertigung verzichtet, kommt noch obendrauf. Aber so entsteht ein extrem effizientes Produkt, das dank TSMCs N3-Fertigung obendrein zu den modernsten im Markt gehört. Intel betonte in dem Zusammenhang stets, dass Arm keinen Vorteil habe und x86 sich nur anpassen müsse – mit angepasster Architektur und gleichwertiger Fertigung. Den Schritt hat der Konzern nun vollzogen.
Dass dabei nicht nur die Performance-Kerne deutlich an Leistung zulegen, sondern die kleinen Efficiency-Cores auf den IPC-Stand der besten Desktop-CPU-Kerne gehoben werden, ist eine große Überraschung und bietet Intel mehr Möglichkeiten. Fortan können die E-Cores nämlich nahezu alles allein und lassen den P-Core-Cluster schlafen, was die Effizienz deutlich steigert. Wird ein Maximum an Leistung verlangt, schalten sich die Performance-Kerne hinzu – dank nochmals verbessertem Thread-Director im bestmöglichen Fall.
-
 Intel Lunar Lake
Intel Lunar Lake






Auf der Grafikseite hat sich kaum weniger getan. In zweiter Generation ist Xe nun aktiv und verspricht einen ebenso großen Sprung nach vorn. Flankiert wird das von einer mehr als vier Mal so schnellen NPU, denn an AI kommt in Zeiten von Copilot+ schließlich keiner mehr vorbei.
Auf dem Papier sieht das Ganze überzeugend aus, doch die Realität liegt nachher im Notebook eines Partners und im Handel. Dort muss sich Lunar Lake dann gegen AMD Strix Point und Qualcomm Snapxdragon Elite X beweisen. Selten zuvor gab es so eine rasch aufeinanderfolgende Vorstellung dreier Unternehmen für denselben Markt und damit selten zuvor so viel Konkurrenz. Der Herbst wird definitiv heiß, denn dann sollte eine Vielzahl an Notebooks im Handel stehen.
Was noch fehlt? Konkrete Angaben zu den ersten Lunar-Lake-Prozessoren. AMD hat Ryzen AI 300 bereits in zwei Varianten vorgestellt, Intel bei Lunar Lake noch nicht einmal Core Ultra 200V als Serienname genannt.

ComputerBase hat Informationen zu diesem Artikel von Intel unter NDA im Rahmen einer Veranstaltung des Herstellers im Vorfeld der Computex in Taipeh, Taiwan erhalten. Die Kosten für An-, Abreise und drei Hotelübernachtungen wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe aus dem NDA war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.