Vor ein paar Tagen hat mein QNAP NAS angefangen mir für eine der beiden WD RED HDDs (RAID 1) folgende Fehlermeldung rauszugeben:
Habe dann einen "Complete Test" durchgeführt:
Das NAS hat empfohlen einen bad block test laufen zu lassen
Habe ich mit folgendem Ergebnis gemacht:
Habe dann in die SMART werte reingeschaut auf der NAS reingeschaut.
Habe das dann gegoogelt und wenn ich das richtig verstehe sind 602 blocks(oder sektoren?) fehlerbehaftet aber noch nicht endgültig als bad markiert und keine blocks "aus der Reserve" als Ersatz zugewiesen worden.
Ich habe dann gelesen, dass das WD Drive Utility einen "Complete Drive Test" machen kann, bei dem dann alle Blöcke abgearbeitet und entsprechend zugewiesen oder wieder als "good" markiert werden.
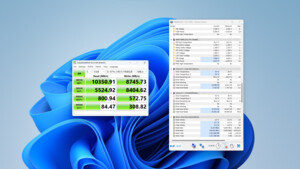
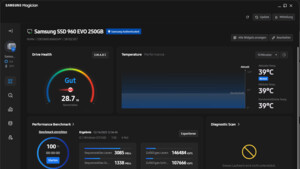
Habe das Tool heruntergeladen und auf einem Windows rechner installiert, die HDD aus dem NAS gezogen und angeschlossen. Leider erkennt das WD Drive Utility keine Festplatten (im PC steckt auch eine WD Green als Datenspeicher) und das alternative WD Dashboard Utility bricht den erweiterten Test nach einer Minute mit einer nichtssagenden Fehlermeldung ab. Habe dann noch mit CrystalDiskInfo ausgelesen aber keine neuen Erkenntnise:

Ich habe auch gegoogelt, dass andere Tools ausser WD Drive Utility alle Blöcke entsprechend behandeln können, angeblich auch Windows Bordmittel aber ich bin mir unsicher welche ich nehmen sollte. Meine Erwartung ist, dass entweder diese 602 Blöcke doch ok sind und zurückgesetzt werden oder eben "reallocated". Irgendwo stand dass eine moderne HDD ca. 1500 Reserveblöcke hat.
Auf der anderen Seite hat die Platte jetzt auch 48,5k Betriebsstunden (Fast 24/7 Betrieb seit ca. 2019) . Vielleicht ist das ja ein Zeichen die Platte in den Ruhestand zu schicken bevor sie komplett aufgibt und sich gar nicht mehr mit den Blöcken rumzuschlagen?")
Code:
[Hardware Status] "Host: 3.5" SATA HDD 2": Read I/O error, "UNRECOVERED READ ERROR ", sense_key=0x3, asc=0x11, ascq=0x4, CDB=88 00 00 00 00 01 5a e3 97 88 00 00 04 00 00 00 ..Habe dann einen "Complete Test" durchgeführt:
Code:
[Disk S.M.A.R.T.] Host: 3.5" SATA HDD 2 Complete Test result: Fatal or unknown error.Das NAS hat empfohlen einen bad block test laufen zu lassen
Code:
[Hardware Status] "Host: 3.5" SATA HDD 2": Medium error. Run a bad block scan on the drive. Replace the drive if the error persists.Habe ich mit folgendem Ergebnis gemacht:
Code:
[Storage & Snapshots] Finished scanning for bad blocks on disk "Host: 3.5" SATA HDD 2". Bad blocks detected: 602.Habe dann in die SMART werte reingeschaut auf der NAS reingeschaut.
Code:
ID 196 "Reallocated Event Count" = 0
ID 197 "Current Pending Sector" = 602
ID 198 "Uncorrectable Sector Count" = 0Habe das dann gegoogelt und wenn ich das richtig verstehe sind 602 blocks(oder sektoren?) fehlerbehaftet aber noch nicht endgültig als bad markiert und keine blocks "aus der Reserve" als Ersatz zugewiesen worden.
Ich habe dann gelesen, dass das WD Drive Utility einen "Complete Drive Test" machen kann, bei dem dann alle Blöcke abgearbeitet und entsprechend zugewiesen oder wieder als "good" markiert werden.
Complete Drive Test
The complete drive test checks every sector for error conditions, and inserts bad sector markers as needed.
Habe das Tool heruntergeladen und auf einem Windows rechner installiert, die HDD aus dem NAS gezogen und angeschlossen. Leider erkennt das WD Drive Utility keine Festplatten (im PC steckt auch eine WD Green als Datenspeicher) und das alternative WD Dashboard Utility bricht den erweiterten Test nach einer Minute mit einer nichtssagenden Fehlermeldung ab. Habe dann noch mit CrystalDiskInfo ausgelesen aber keine neuen Erkenntnise:
Ich habe auch gegoogelt, dass andere Tools ausser WD Drive Utility alle Blöcke entsprechend behandeln können, angeblich auch Windows Bordmittel aber ich bin mir unsicher welche ich nehmen sollte. Meine Erwartung ist, dass entweder diese 602 Blöcke doch ok sind und zurückgesetzt werden oder eben "reallocated". Irgendwo stand dass eine moderne HDD ca. 1500 Reserveblöcke hat.
Auf der anderen Seite hat die Platte jetzt auch 48,5k Betriebsstunden (Fast 24/7 Betrieb seit ca. 2019) . Vielleicht ist das ja ein Zeichen die Platte in den Ruhestand zu schicken bevor sie komplett aufgibt und sich gar nicht mehr mit den Blöcken rumzuschlagen?