neueinsteiger84
Lieutenant
- Registriert
- Sep. 2013
- Beiträge
- 942
Hallo zusammen,
habe das Thema nochmal hervorgekramt. Geht hier weiter, falls ihr keine Lust habt, alles zu lesen: https://www.computerbase.de/forum/t...achtraeglich-optimieren.2172493/post-29240414
----
Hallo zusammen,
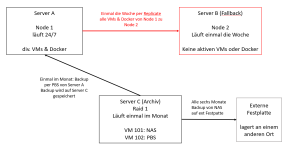
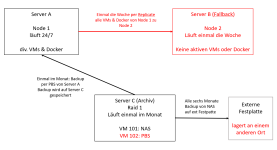
aktuell treibt mich ein bisschen das Thema Ausfallsicherheit meines kleinen Servers um. Ich betreibe jetzt keine kritischen Anwendungen. Nur mache ich mir Gedanken, was passiert, wenn der Server ausfällt.
Also wie viel Aufwand das für mich verursacht, insbesondere, da ich mich damit bisher (zum Glück) nicht beschäftigen musste.
Und auf meinem Server laufen ein paar VMs + Docker. In Summe nutze ich die Funktionalität des Servers schon täglich (Alleine wegen meiner Hausautomatisierung, dem integrierten NAS usw.)
Setup:
Der Server ist ein Lenovo Think Center Tiny mit einem i5-6500T und zwei SSDs als JBOD (500 GB und 2 TB --> also bisher auch keine großen Datenmengen).
Auf dem Server läuft unter anderem auch ein Proxmox Backup Server.
Backup ist ein zweiter, alter Xeon Server mit 2 4TB HDDs, welche in Raid 1 konfiguriert sind. Der Server läuft aber nur, wenn ich mal ein Backup erstelle, da er ein Idle Verbrauch von 40W hat.
Meine Sorge ist nun, dass eine der beiden SSDs ausfällt. Dann wäre ggf. mein NAS, meine Nextcloud, Home Assistant etc. würden nicht mehr funktionieren.
Und was dann? Zuerst mal eine neue SSD auftreiben (Dauer: 1 Tag+), dann - sofern es den Proxmox Backupserver nicht zerschossen hat - das letzte Backup "aktivieren".
Hat es sogar den Backupserver erwischt, müsste ich den erst mal neu aufsetzen. Das schaffe ich aber zeitlich möglicherweise erst an einem Wochenende --> mein Server ist dann schnell mal eine Woche down.
Und wenn ich Pech habe, ist das Backup alt und alle neuen Daten wären verloren.
Was sind meine bisherigen Gedanken:
1. Ich baue ein separates NAS mit Raid1 auf. Das binde ich dann per NFS in Proxmox ein. Und dann übertrage ich alle VMs in Proxmox auf den NFS Storage. Vorteil: Ich kann das NAS in Ruhe aufsetzen. Außerdem lässt mir das NAS einfach die Möglichkeit zu Speicherweiterung (falls ich mal ein Medienserver aufbauen will). Nachteil: ein weiteres System, entsprechende Anschaffungskosten. Das NAS kann ebenfalls ausfallen und verbraucht natürlich zusätzlich Strom
2. Ich baue einen weiteren Server auf mit ZFS Storage in Raid1 und betreibe dann diesen mit meinem bestehenden Server in einem Cluster. Erhöht nicht nur die Ausfallsicherheit, wenn mir eine SSD abraucht. Nach meinem Verständnis könnte dann sogar ein Server komplett ausfallen und der andere würde alles übernehmen können. Nachteil: identisch zu Punkt 1 oder?
--> ohne echte Begründung (da mir bisher noch das Know How fehlt), klingt diese Lösung besser als Variante 1
3. Sobald ich mal etwas Zeit habe, mache ich den Server platt (vorher Backup auf den Backupserver) und tausche die bestehende 500 GB SSD mit einer 2 TB SSD aus. Dann baue ich den Server erneut auf und beide SSDs als ZFS Raid 1.
Und dann nutze ich das aktuelle Backup aus dem Server.
Vorteil: die preiswerteste Lösung, kein weiteres System, kein zusätzlicher Stromverbrauch.
Nachteil: anstelle von 2.5 TB habe ich dann nur noch 2 TB. Das reicht mir aktuell aus.
Außerdem das gefühlte Risiko / Unwohlsein, dass irgendwas bei Erstellung des Backups falsch lief und ich den Server nicht mehr (vollständig) herstellen kann.
Daneben schützt diese Variante nur vor dem Ausfall der SSD, aber nicht vor dem Ausfall des kompletten Servers. D
Ich hoffe, ihr könnt meine Gedanken und Sorgen nachvollziehen und mir weiterhelfen, eine gute Lösung zu finden.
Danke schon mal im voraus.
habe das Thema nochmal hervorgekramt. Geht hier weiter, falls ihr keine Lust habt, alles zu lesen: https://www.computerbase.de/forum/t...achtraeglich-optimieren.2172493/post-29240414
----
Hallo zusammen,
aktuell treibt mich ein bisschen das Thema Ausfallsicherheit meines kleinen Servers um. Ich betreibe jetzt keine kritischen Anwendungen. Nur mache ich mir Gedanken, was passiert, wenn der Server ausfällt.
Also wie viel Aufwand das für mich verursacht, insbesondere, da ich mich damit bisher (zum Glück) nicht beschäftigen musste.
Und auf meinem Server laufen ein paar VMs + Docker. In Summe nutze ich die Funktionalität des Servers schon täglich (Alleine wegen meiner Hausautomatisierung, dem integrierten NAS usw.)
Setup:
Der Server ist ein Lenovo Think Center Tiny mit einem i5-6500T und zwei SSDs als JBOD (500 GB und 2 TB --> also bisher auch keine großen Datenmengen).
Auf dem Server läuft unter anderem auch ein Proxmox Backup Server.
Backup ist ein zweiter, alter Xeon Server mit 2 4TB HDDs, welche in Raid 1 konfiguriert sind. Der Server läuft aber nur, wenn ich mal ein Backup erstelle, da er ein Idle Verbrauch von 40W hat.
Meine Sorge ist nun, dass eine der beiden SSDs ausfällt. Dann wäre ggf. mein NAS, meine Nextcloud, Home Assistant etc. würden nicht mehr funktionieren.
Und was dann? Zuerst mal eine neue SSD auftreiben (Dauer: 1 Tag+), dann - sofern es den Proxmox Backupserver nicht zerschossen hat - das letzte Backup "aktivieren".
Hat es sogar den Backupserver erwischt, müsste ich den erst mal neu aufsetzen. Das schaffe ich aber zeitlich möglicherweise erst an einem Wochenende --> mein Server ist dann schnell mal eine Woche down.
Und wenn ich Pech habe, ist das Backup alt und alle neuen Daten wären verloren.
Was sind meine bisherigen Gedanken:
1. Ich baue ein separates NAS mit Raid1 auf. Das binde ich dann per NFS in Proxmox ein. Und dann übertrage ich alle VMs in Proxmox auf den NFS Storage. Vorteil: Ich kann das NAS in Ruhe aufsetzen. Außerdem lässt mir das NAS einfach die Möglichkeit zu Speicherweiterung (falls ich mal ein Medienserver aufbauen will). Nachteil: ein weiteres System, entsprechende Anschaffungskosten. Das NAS kann ebenfalls ausfallen und verbraucht natürlich zusätzlich Strom
2. Ich baue einen weiteren Server auf mit ZFS Storage in Raid1 und betreibe dann diesen mit meinem bestehenden Server in einem Cluster. Erhöht nicht nur die Ausfallsicherheit, wenn mir eine SSD abraucht. Nach meinem Verständnis könnte dann sogar ein Server komplett ausfallen und der andere würde alles übernehmen können. Nachteil: identisch zu Punkt 1 oder?
--> ohne echte Begründung (da mir bisher noch das Know How fehlt), klingt diese Lösung besser als Variante 1
3. Sobald ich mal etwas Zeit habe, mache ich den Server platt (vorher Backup auf den Backupserver) und tausche die bestehende 500 GB SSD mit einer 2 TB SSD aus. Dann baue ich den Server erneut auf und beide SSDs als ZFS Raid 1.
Und dann nutze ich das aktuelle Backup aus dem Server.
Vorteil: die preiswerteste Lösung, kein weiteres System, kein zusätzlicher Stromverbrauch.
Nachteil: anstelle von 2.5 TB habe ich dann nur noch 2 TB. Das reicht mir aktuell aus.
Außerdem das gefühlte Risiko / Unwohlsein, dass irgendwas bei Erstellung des Backups falsch lief und ich den Server nicht mehr (vollständig) herstellen kann.
Daneben schützt diese Variante nur vor dem Ausfall der SSD, aber nicht vor dem Ausfall des kompletten Servers. D
Ich hoffe, ihr könnt meine Gedanken und Sorgen nachvollziehen und mir weiterhelfen, eine gute Lösung zu finden.
Danke schon mal im voraus.
Zuletzt bearbeitet: