P
pufferueberlauf
Gast
Das hier ist ein "Anker-Post" fuer Diskussionen rund um Bufferbloat oder Latenz-unter-Last-Zunahme.
Bufferbloat tritt üblicherweise dann auf wenn an Flaschenhals-Übergängen (neudeutsch "Bottleneck") von schnell zu langsam die Warteschlange (auch Pufferspeicher, neudeutsch "Buffer") zu groß ist und/oder zu schlecht verwaltet wird (neudeutsch "over-sized and under-managed"). Eine solche Situation tritt z.B. üblicherweise bei Internetzugängen auf da die Geschwindigkeit jedes einzelnen Anschlusses i.d.R. geringer ist als die Geschwindigkeit mit der das Edge-Element* des ISPs an dessen Backbone/das Internet angeschlossen ist. In Gegenrichtung passiert das im Modem/Router des Endkunden, da interne Netzwerke heute oft >= 1 Gbps-Ethernet verwenden während der Internet-Uplink meist << 1 Gbps ausfällt.
Warum kommt es genau zu dieser Latenzerhöhung?
"Dumme" Pufferspeicher sind meist als First In – First Out (FIFO; altdeutsch "der Reihe nach") organisiert, d.h. Pakete kommen am Ende dazu und werden Vorne weggenommen, d.h. jedes Paket wird erst dann weitergesendet wenn alle die vor ihm in der Warteschlange "sitzen" versendet wurden. Wenn jetzt die Neuzugangsrate am Hinter-Ende höher ist als die Senderate am Vorder-Ende, dann wird der Puffer immer voller, solange bis der Puffer die maximale konfigurierte Größe erreicht, dann werden neu dazukommende Pakete einfach verworfen (Taildrop). (Dieses Verwerfen führt bei TCP dazu, dass in betroffenen Flows auf einmal Pakete fehlen, was der Empfänger jedoch erst bemerkt wenn nach einem verlorenen Paket noch zwei weitere Pakete mit höherer Sequenznummer reinkommen, dann benachrichtigt er den Sender dass Pakete fehlen was der damit beantwortet, dass er die Senderate drosselt.) Fuer jedes Paket das versendet wird ensteht wieder Platz fuer ein neues Paket im Puffer. Solange der Puffer jetzt stark gefüllt ist wird jedes Paket zusätzlich fuer die Zeit verzögert die es braucht die Pakete zu versenden die vor ihm im FIFO liegen. Wenn der Puffer "gut" dimensioniert war, dann ist diese zusätzliche Latenz klein und "verschmerzbar", ist der Puffer aber überdimensioniert kann die zusätzliche lastabhängige Latenz so gross werden, dass interaktive/zeitkritische Anwendungen Probleme bekommen (beobachtet wurden Latenzen bis in den Sekundenbereich hoch). Weil mit der Zeit Speicher immer günstiger wurde (zumindest einfaches RAM fuer Puffer, Assoziativspeicher CAM/TCAM ist nach wie vor so teuer, dass er sparsam verwendet wird) haben die meisten Netzkomponenten auch immer größere Puffer spendiert bekommen (nach der Devise viel hilft viel) auch weil das hilft das bislang oft wichtigste Qualitätsmass den Durchsatz hoch zu halten. Die Puffer sind über die Zeit quasi angeschwollen, neudeutsch buffer-bloat...
Als Loesungen bieten sich an:
a) die Puffergroesse zu reduzieren
b) die existierenden Puffer besser zu verwalten (was darauf hinaus laeuft den Traffic-Quellen zu signalisieren, dass sie abbremsen sollen bevor der Puffer ueberfuellt ist, und/oder jedem Flow seinen eigenen Puffer zu Verfügung zu stellen und beim Pufferleeren die Egress-Kapazitaet fair zwischen den Flows zu verteilen)
In der Realität bietet sich eigentlich nur b) an, da a) das Problem hat, dass die optimale Puffergroesse letztlich von der RTT (aka "dem Ping") der einzelnen Flows abhängt, größere RTT erfordert größere Puffer, aber Puffer die fuer RTT Xms ideal dimensioniert sind fuehren bei RTT 2*Xms dazu, dass weniger Durchsatz erreicht wird.
Für b) existieren mehrere Ansätze, fuer interessierte Endnutzer mit Linux-basierten Routern bieten sich fq_codel und cake an, beide können unter OpenWrt einfach ueber sqm-scripts/luci-app-sqm ausprobiert werden (bzw. fuer OpenWrt Snapshots Anfang 2022 auch mit qosify stat sqm) hier die OpenWrt Konfigurationsempfehlungen: https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm und https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm-details.
Wie teste/messe ich Bufferbloat?
Ueber den Browser:
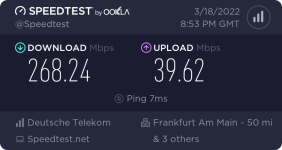
a) Der dslreports speedtest war lange Zeit die einzige oeffentiche Option, allerdings sind da im Laufe der Zeit immer mehr Probleme aufgetaucht/Messknoten verkustig gegangen, momentan kann man i.d.R. noch ganz passabel messen, wenn man HTTP statt HTTPS verwendet (die Zertifikate scheinen abgelaufen zu sein). Dafür den "use http"-Link in der rechten oberen Ecke des Speedtest-Widgets klicken. Hier eine englische Konfigurationsanweisung um mehr aus dem Test herauszuholen: https://forum.openwrt.org/t/sqm-qos...dslreports-speedtest-bufferbloat-testing/2803
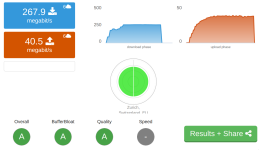
b) Waveform's Bufferbloat-Test: https://www.waveform.com/tools/bufferbloat (nach abgeschlossenem Test kann man eine CSV Datei mit den Durchschnittsgeschwindigkeiten, so wie allen individuellen Latenzmessungen der drei Phasen runter-laden).
c) Netflix https://fast.com (den kann man so konfigurieren, dass der Test mindestns 30 Sekunden laueft und auch den Upload testet)
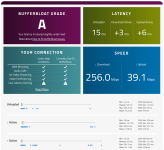
d) seit Mai 2022 enthaelt Oooklas speedtest.net App fuer Android und iOS eine "Detailed result" Ansicht bei der die Latenz auch unter Last fuer beide Richtungen getrennt gemessen und reportiert wird, bis jetzt jedoch noch nicht im Web-Client, in der CLI Anwendung oder in der Macos-App...
(der reportierte Latenzwert ist der Interquartil-Mittelwert, also berechnet aus dem mittleren 50% der Messwerte von 25-75%)
Von diesen haben a) und b) die besten/detailliertesten Informationen zur Latenz-unter-Last, die Entwickler von fast.com sind sich dessen jedoch bewusst und ziehen vielleicht irgendwann mal nach. Ein Problem ist bei Browsertests allerdings, dass die Resultate nicht nur das Netz sondern auch die Performance des Browsers und dessen "Responsiveness" testen, dafuer sind die schnell und einfach mit verschiedenen Endgeraeten durchzufuehren...
Von der Kommandozeile:
a) flents (https://flent.org) RRUL test, allerdings braucht man da die Adresse eines Netperf-Servers als Gegenstellen (kann man selber per VPS aufsetzen).
b) DIY: man kann die Latenz sehr gut entweder mit MTR oder mit gping betrachten, und muss nur waehrend der Messung eine saturierende Last erzeigen, z.B. durch Verwendung eines der Browser Speedtest (siehe oben, aber auch Ooklas Speedtest.net Nodes sind geeignet, oder breitbandmessung.de, und eigentlich jeder andere Speedtest auch) oder öffentlicher iperf3 Server.
Der Trick ist halt dass man die Latenzmessung startet und beobachtet bevor, waehrend und nach der Lasterzeugung dann kann man per Augenmass abschaetzen um wieviel sich die Latenz unter Volllast erhoeht.
Vom Mac:
Apple hat in aktuellem iOS und Macos Monterey einen neuen Netzwerktest integriert (networkQuality, siehe z.B. https://stadt-bremerhaven.de/speedy-grafische-oberflaeche-fuer-apples-networkquality/) der ein Bufferbloat korreliertes Mass, RPM genannt, liefert. Unter iOS ist das allerdings wohl nicht so einfach zu aktivieren, kann ich aus Ermangelung eines aktuellen iOS Gerätes leider nicht ausprobieren. Eine Go-Variante des Clienten befindet sich auf https://github.com/network-quality/goresponsiveness in Entwicklung, ist aber Stand 2022 04 13 wegen eines Go-Bugs nicht zuverlässig.
*) Das kann unterschiedliche Namen haben, CMTS bei Kabel/DOCIS, BRAS/PoP/BNG bei XDSL und FTTH, je nach ISP und Netzstruktur, die Gemeinsamkeit ist, dass an der Stelle die Vertragsrate durch einen Traffic-Shaper oder Traffic-Policer begrenzt wird.
Mmmh, das klingt interessant, wo kann ich weitere Informationen finden?
https://www.bufferbloat.net/projects/
Bufferbloat tritt üblicherweise dann auf wenn an Flaschenhals-Übergängen (neudeutsch "Bottleneck") von schnell zu langsam die Warteschlange (auch Pufferspeicher, neudeutsch "Buffer") zu groß ist und/oder zu schlecht verwaltet wird (neudeutsch "over-sized and under-managed"). Eine solche Situation tritt z.B. üblicherweise bei Internetzugängen auf da die Geschwindigkeit jedes einzelnen Anschlusses i.d.R. geringer ist als die Geschwindigkeit mit der das Edge-Element* des ISPs an dessen Backbone/das Internet angeschlossen ist. In Gegenrichtung passiert das im Modem/Router des Endkunden, da interne Netzwerke heute oft >= 1 Gbps-Ethernet verwenden während der Internet-Uplink meist << 1 Gbps ausfällt.
Warum kommt es genau zu dieser Latenzerhöhung?
"Dumme" Pufferspeicher sind meist als First In – First Out (FIFO; altdeutsch "der Reihe nach") organisiert, d.h. Pakete kommen am Ende dazu und werden Vorne weggenommen, d.h. jedes Paket wird erst dann weitergesendet wenn alle die vor ihm in der Warteschlange "sitzen" versendet wurden. Wenn jetzt die Neuzugangsrate am Hinter-Ende höher ist als die Senderate am Vorder-Ende, dann wird der Puffer immer voller, solange bis der Puffer die maximale konfigurierte Größe erreicht, dann werden neu dazukommende Pakete einfach verworfen (Taildrop). (Dieses Verwerfen führt bei TCP dazu, dass in betroffenen Flows auf einmal Pakete fehlen, was der Empfänger jedoch erst bemerkt wenn nach einem verlorenen Paket noch zwei weitere Pakete mit höherer Sequenznummer reinkommen, dann benachrichtigt er den Sender dass Pakete fehlen was der damit beantwortet, dass er die Senderate drosselt.) Fuer jedes Paket das versendet wird ensteht wieder Platz fuer ein neues Paket im Puffer. Solange der Puffer jetzt stark gefüllt ist wird jedes Paket zusätzlich fuer die Zeit verzögert die es braucht die Pakete zu versenden die vor ihm im FIFO liegen. Wenn der Puffer "gut" dimensioniert war, dann ist diese zusätzliche Latenz klein und "verschmerzbar", ist der Puffer aber überdimensioniert kann die zusätzliche lastabhängige Latenz so gross werden, dass interaktive/zeitkritische Anwendungen Probleme bekommen (beobachtet wurden Latenzen bis in den Sekundenbereich hoch). Weil mit der Zeit Speicher immer günstiger wurde (zumindest einfaches RAM fuer Puffer, Assoziativspeicher CAM/TCAM ist nach wie vor so teuer, dass er sparsam verwendet wird) haben die meisten Netzkomponenten auch immer größere Puffer spendiert bekommen (nach der Devise viel hilft viel) auch weil das hilft das bislang oft wichtigste Qualitätsmass den Durchsatz hoch zu halten. Die Puffer sind über die Zeit quasi angeschwollen, neudeutsch buffer-bloat...
Als Loesungen bieten sich an:
a) die Puffergroesse zu reduzieren
b) die existierenden Puffer besser zu verwalten (was darauf hinaus laeuft den Traffic-Quellen zu signalisieren, dass sie abbremsen sollen bevor der Puffer ueberfuellt ist, und/oder jedem Flow seinen eigenen Puffer zu Verfügung zu stellen und beim Pufferleeren die Egress-Kapazitaet fair zwischen den Flows zu verteilen)
In der Realität bietet sich eigentlich nur b) an, da a) das Problem hat, dass die optimale Puffergroesse letztlich von der RTT (aka "dem Ping") der einzelnen Flows abhängt, größere RTT erfordert größere Puffer, aber Puffer die fuer RTT Xms ideal dimensioniert sind fuehren bei RTT 2*Xms dazu, dass weniger Durchsatz erreicht wird.
Für b) existieren mehrere Ansätze, fuer interessierte Endnutzer mit Linux-basierten Routern bieten sich fq_codel und cake an, beide können unter OpenWrt einfach ueber sqm-scripts/luci-app-sqm ausprobiert werden (bzw. fuer OpenWrt Snapshots Anfang 2022 auch mit qosify stat sqm) hier die OpenWrt Konfigurationsempfehlungen: https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm und https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm-details.
Wie teste/messe ich Bufferbloat?
Ueber den Browser:
a) Der dslreports speedtest war lange Zeit die einzige oeffentiche Option, allerdings sind da im Laufe der Zeit immer mehr Probleme aufgetaucht/Messknoten verkustig gegangen, momentan kann man i.d.R. noch ganz passabel messen, wenn man HTTP statt HTTPS verwendet (die Zertifikate scheinen abgelaufen zu sein). Dafür den "use http"-Link in der rechten oberen Ecke des Speedtest-Widgets klicken. Hier eine englische Konfigurationsanweisung um mehr aus dem Test herauszuholen: https://forum.openwrt.org/t/sqm-qos...dslreports-speedtest-bufferbloat-testing/2803
b) Waveform's Bufferbloat-Test: https://www.waveform.com/tools/bufferbloat (nach abgeschlossenem Test kann man eine CSV Datei mit den Durchschnittsgeschwindigkeiten, so wie allen individuellen Latenzmessungen der drei Phasen runter-laden).
c) Netflix https://fast.com (den kann man so konfigurieren, dass der Test mindestns 30 Sekunden laueft und auch den Upload testet)
d) seit Mai 2022 enthaelt Oooklas speedtest.net App fuer Android und iOS eine "Detailed result" Ansicht bei der die Latenz auch unter Last fuer beide Richtungen getrennt gemessen und reportiert wird, bis jetzt jedoch noch nicht im Web-Client, in der CLI Anwendung oder in der Macos-App...
(der reportierte Latenzwert ist der Interquartil-Mittelwert, also berechnet aus dem mittleren 50% der Messwerte von 25-75%)
Von diesen haben a) und b) die besten/detailliertesten Informationen zur Latenz-unter-Last, die Entwickler von fast.com sind sich dessen jedoch bewusst und ziehen vielleicht irgendwann mal nach. Ein Problem ist bei Browsertests allerdings, dass die Resultate nicht nur das Netz sondern auch die Performance des Browsers und dessen "Responsiveness" testen, dafuer sind die schnell und einfach mit verschiedenen Endgeraeten durchzufuehren...
Von der Kommandozeile:
a) flents (https://flent.org) RRUL test, allerdings braucht man da die Adresse eines Netperf-Servers als Gegenstellen (kann man selber per VPS aufsetzen).
b) DIY: man kann die Latenz sehr gut entweder mit MTR oder mit gping betrachten, und muss nur waehrend der Messung eine saturierende Last erzeigen, z.B. durch Verwendung eines der Browser Speedtest (siehe oben, aber auch Ooklas Speedtest.net Nodes sind geeignet, oder breitbandmessung.de, und eigentlich jeder andere Speedtest auch) oder öffentlicher iperf3 Server.
Der Trick ist halt dass man die Latenzmessung startet und beobachtet bevor, waehrend und nach der Lasterzeugung dann kann man per Augenmass abschaetzen um wieviel sich die Latenz unter Volllast erhoeht.
Vom Mac:
Apple hat in aktuellem iOS und Macos Monterey einen neuen Netzwerktest integriert (networkQuality, siehe z.B. https://stadt-bremerhaven.de/speedy-grafische-oberflaeche-fuer-apples-networkquality/) der ein Bufferbloat korreliertes Mass, RPM genannt, liefert. Unter iOS ist das allerdings wohl nicht so einfach zu aktivieren, kann ich aus Ermangelung eines aktuellen iOS Gerätes leider nicht ausprobieren. Eine Go-Variante des Clienten befindet sich auf https://github.com/network-quality/goresponsiveness in Entwicklung, ist aber Stand 2022 04 13 wegen eines Go-Bugs nicht zuverlässig.
*) Das kann unterschiedliche Namen haben, CMTS bei Kabel/DOCIS, BRAS/PoP/BNG bei XDSL und FTTH, je nach ISP und Netzstruktur, die Gemeinsamkeit ist, dass an der Stelle die Vertragsrate durch einen Traffic-Shaper oder Traffic-Policer begrenzt wird.
Mmmh, das klingt interessant, wo kann ich weitere Informationen finden?
https://www.bufferbloat.net/projects/
Zuletzt bearbeitet von einem Moderator: