Hallo,
ich habe meine defekte Festplatte mit einer Recovery Software gerettet. Sie hat mir leider fast zu jeder Datei mehrere Duplikate ausgespuckt. Zwar habe ich versucht händisch alle zu entfernen, aber es dauert einfach zu lange. Bin deshalb seit Tagen auf der Suche nach einem Skript der mir das Leben erleichtern kann, leider ohne Erfolg.
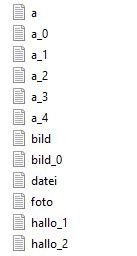
Zu den Dateinamen werden "*_0" ; "*_1" ; "*_2" .. "*_17" .. usw. hinzugefügt, so sind die Duplikate benannt (siehe Anhang für ein Bsp).
Ich würde ja gerne alle, die mit "*_Zahl" enden, löschen, aber manchmal funktioniert die "originale" Datei nicht und deshalb brauche ich eben öfters eines der Duplikate.
Deshalb habe ich mir folgendes ausgedacht:
1. händisch alle nicht funktionierende Dateien löschen. Ich glaube da führt kein Weg vorbei (dauert zwar bisschen aber zum Glück muss ich nicht einzeln draufklicken, ich sehe mit der passenden Ansicht im Ordner ob eine Datei funktioniert oder beschädigt ist.)
1. Sortieren nach Name
2. Entferne die aktuelle Datei wenn die vorherige Datei eine "_Zahl" am Ende hat und diese Zahl kleiner ist als die Zahl von der aktuellen Datei.
Ich hoffe dass mir jemand weiterhelfen kann. Leider wollte/konnte die Firma von dieser Software nicht weiterhelfen (hat sogar ziemlich teuer gekostet!)
Vielen Dank im Voraus!
ich habe meine defekte Festplatte mit einer Recovery Software gerettet. Sie hat mir leider fast zu jeder Datei mehrere Duplikate ausgespuckt. Zwar habe ich versucht händisch alle zu entfernen, aber es dauert einfach zu lange. Bin deshalb seit Tagen auf der Suche nach einem Skript der mir das Leben erleichtern kann, leider ohne Erfolg.
Zu den Dateinamen werden "*_0" ; "*_1" ; "*_2" .. "*_17" .. usw. hinzugefügt, so sind die Duplikate benannt (siehe Anhang für ein Bsp).
Ich würde ja gerne alle, die mit "*_Zahl" enden, löschen, aber manchmal funktioniert die "originale" Datei nicht und deshalb brauche ich eben öfters eines der Duplikate.
Deshalb habe ich mir folgendes ausgedacht:
1. händisch alle nicht funktionierende Dateien löschen. Ich glaube da führt kein Weg vorbei (dauert zwar bisschen aber zum Glück muss ich nicht einzeln draufklicken, ich sehe mit der passenden Ansicht im Ordner ob eine Datei funktioniert oder beschädigt ist.)
1. Sortieren nach Name
2. Entferne die aktuelle Datei wenn die vorherige Datei eine "_Zahl" am Ende hat und diese Zahl kleiner ist als die Zahl von der aktuellen Datei.
Ich hoffe dass mir jemand weiterhelfen kann. Leider wollte/konnte die Firma von dieser Software nicht weiterhelfen (hat sogar ziemlich teuer gekostet!)
Vielen Dank im Voraus!