Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
NewsISSCC 2018: Samsungs Z-SSD nutzt 48-Layer-3D-NAND mit 64 Gigabit
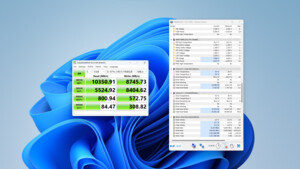
Im Rahmen der ISSCC 2018 hat Samsung weitere Details zur Z-SSD und dem Z-NAND preisgegeben. Beim Speicher handelt es sich um 48-Layer-3D-NAND mit deutlich verringerter Latenz. Im Gegenzug bietet ein Die nur 64 Gbit Speicherplatz. Der Phoenix-Controller besitzt acht Kanäle. Auch einige Benchmarks lieferte Samsung.
Sieht ja ganz beeindruckend aus was Samsung da aus NAND Flash rausgekitzelt haben will, aber es wundert mich bei den Latenzen wieso der Host Transfer von 8,5 auf 5,5µs und der tDMA (also wohl Zeit für die Übertragung der Daten) von 8 auf 4µs gesunken sein soll, obwohl auch die PM963 ein PCIe 3.0 x4 Interface hat.
SRAM haben eigentlich alle Controller, die DRAM less Controller könnten ja andernfalls gar nicht laufen, denn die Controller sind ja im Grunde auch nur CPU (meist mit ARM Kernen) und jede CPU braucht auch RAM um arbeiten zu können. Außerdem würde ich erwarten das ein PCIe SSD Controller dann auch die Befehle so schnell annehmen kann wie sie über seine PCIe Anbindung ankommen. Bzgl. des "by co-operation of Z-NAND and Controller" kann es mit dem NAND auch nichts mehr zu tun haben, denn oben sieht man ja, dass tMedia gerade von tDMA endet, die Daten stehen also im Caches des Controller, die müssen ja auch immer erst vollständig gelesen werden um die Fehlerkorrektur ausführen zu können, die Zeit dafür fehlt hier aber vollständig und danach können sie erst an den Host übertragen werden.
Das könnte sein, aber dann fehlt die Zeit für die Übertragung der Daten von der SSD zum Host und es erklärt auch nicht, wieso diese tHost/Transfer von 8,5 auf 5,5µs schrumpft, denn tController wird ja danach noch extra ausgewiesen, es müsste also nur die Zeit für die Übertragung der Befehle sein.
Ein einzige Erklärung wäre, wenn man einmal die Zeit mit und einmal ohne Nutzung von Energiesparzuständen nimmt.
Was ich mir vorstellen könnte ist, dass bei der Implementierung des SATA-Protokolls optimiert wurde und Verzögerungen, die beim vorherigen Design enthalten waren entfernen oder reduzieren konnte.
Hast du evtl. schon die Folien oder eine Aufzeichnung des Vortrags gefunden?
tDMA Zugriffszeit auf den NAND, tMedia Daten lesen, tR read mitsamt Fehlerkorrektur, tController Daten in den Controller schieben, tHost/Transfer Daten auf den Host kopieren. Erklärt zwar auch nicht wieso tHost schneller wurde, aber ja, man hat es einfach beschleunigt? Würde das nicht auf die Goldwaage legen.
tDMA als Zugriffszeit fürs NAND macht gar keinen Sinn, da diese ja erst erst am Ende anfällt, wenn die mit dem Medium zu tun hat, dann ist es die Zeit für das Übertragen der Daten vom NAND zum Controller. Die könnte auch Teil von tMedia sein, dann wäre tR die Zeit die das NAND selbst braucht um die Zellen auszulesen und die Daten im Register bereit zu stellen.
tController ist die Zeit die der Controller braucht um erst einmal mit Hilfe der Mappingtabelle die richtige NAND Adresse zu finden, die kann durchaus kürzer werden, wenn der Controller schneller arbeitet. tHost/Transfer kann aber nur kürzer werden, wenn das Interface schneller wäre oder das Protokoll schlanker, aber sowohl die SZ985 als auch die zum Vergleich genommene PM983 haben ein PCIe 3.0x 4 Interface und nutzen das NVMe Protokoll, da herrscht also Gleichstand.
Wenn es Teil von tMedia ist, was nicht so ganz klar zu sehen ist, dann könnte tDMA die Zeit für die Übertragung der Daten vom NAND zum Controller sein.
Eigentlich endet die Latenz ja mit der Übertragung der ersten Daten, auch wenn man sie so nicht messen kann. In den Benchmarks wird die Latenz daher immer gemessen indem möglichst wenig Daten übertragen werden, meisten eben 512 Byte, da die Programme eben den Anfang der Datenübertragung nicht erkennen können, sondern nur das Ende und bei möglichst wenig Daten verfälscht die Zeit für die Datenübertragung die Messung eben so wenig wie möglich. Benchmarks werden also immer mehr als diese 15,9µs anzeigen.