shortrange
Banned
- Registriert
- Okt. 2013
- Beiträge
- 626
Hallo zusammen,
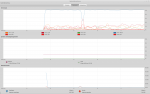
vorhin habe ich ein sehr großes Textdokument mit grep durchsucht, wobei ich zufällig die Systemüberwachung (gnome-system-monitor) offen hatte. Die Ausführung von grep hat bestimmt ca. sechs Minuten gedauert. Die Systemüberwachung zeigt unter dem Reiter "Ressourcen" auch die CPU-Auslastung an (genannt "CPU-Chronik").
Dabei ist mir aufgefallen, dass von den acht virtuellen Kernen (CPU: Intel Xeon E3-1231 v3; 4 Kerne, 8 Threads) immer nur einer mit 100% Prozent beansprucht wird. Die restlichen sieben virtuellen Kerne/Threads bleiben von der Ausführung des grep-Befehls unbeeinflusst (siehe Screenshot).
Damit der Befehl schneller ausgeführt wird, habe ich die Priorität der beiden Prozessen "bash" und "grep" von "Normal" auf "Sehr hoch" gesetzt. Das hat jedoch zu keiner Änderung geführt, die CPU-Last hat sich nicht verändert.
Ich erwarte ja nicht, dass die Auslastung des Prozessors so ist wie bei Prime95 unter Windows mit In-Place Large FFTs (siehe Screenshot). Doch ich hatte erwartet, dass sie zumindest etwas höher ist, als nur bei einem Thread auf 100%.
Woran liegt es, dass nur ein Thread auf 100% läuft und der Befehl nicht mehr Prozessorlast verursacht? Kann es sein, dass die SSD (Crucial MX300 275GB SATA) der Flaschenhals ist, weil der Prozessor die Daten nicht schnell genug einlesen kann?
Systemdaten:
vorhin habe ich ein sehr großes Textdokument mit grep durchsucht, wobei ich zufällig die Systemüberwachung (gnome-system-monitor) offen hatte. Die Ausführung von grep hat bestimmt ca. sechs Minuten gedauert. Die Systemüberwachung zeigt unter dem Reiter "Ressourcen" auch die CPU-Auslastung an (genannt "CPU-Chronik").
Dabei ist mir aufgefallen, dass von den acht virtuellen Kernen (CPU: Intel Xeon E3-1231 v3; 4 Kerne, 8 Threads) immer nur einer mit 100% Prozent beansprucht wird. Die restlichen sieben virtuellen Kerne/Threads bleiben von der Ausführung des grep-Befehls unbeeinflusst (siehe Screenshot).
Damit der Befehl schneller ausgeführt wird, habe ich die Priorität der beiden Prozessen "bash" und "grep" von "Normal" auf "Sehr hoch" gesetzt. Das hat jedoch zu keiner Änderung geführt, die CPU-Last hat sich nicht verändert.
Ich erwarte ja nicht, dass die Auslastung des Prozessors so ist wie bei Prime95 unter Windows mit In-Place Large FFTs (siehe Screenshot). Doch ich hatte erwartet, dass sie zumindest etwas höher ist, als nur bei einem Thread auf 100%.
Woran liegt es, dass nur ein Thread auf 100% läuft und der Befehl nicht mehr Prozessorlast verursacht? Kann es sein, dass die SSD (Crucial MX300 275GB SATA) der Flaschenhals ist, weil der Prozessor die Daten nicht schnell genug einlesen kann?
Systemdaten:
Code:
System: Host: mint18-desktop Kernel: 4.4.0-53-generic x86_64 (64 bit gcc: 5.4.0)
Desktop: Cinnamon 3.2.7 (Gtk 3.18.9-1ubuntu3.1) dm: mdm Distro: Linux Mint 18.1 Serena
Machine: System: Gigabyte product: H97-D3H Chassis: type: 3
Mobo: Gigabyte model: H97-D3H-CF v: x.x Bios: American Megatrends v: F5 date: 06/26/2014
CPU: Quad core Intel Xeon E3-1231 v3 (-HT-MCP-) cache: 8192 KB
flags: (lm nx sse sse2 sse3 sse4_1 sse4_2 ssse3 vmx) bmips: 27198
clock speeds: min/max: 800/3800 MHz 1: 3738 MHz 2: 3758 MHz 3: 3766 MHz 4: 3772 MHz
5: 3778 MHz 6: 3795 MHz 7: 3745 MHz 8: 3743 MHz
Graphics: Card: NVIDIA GK104 [GeForce GTX 660 Ti] bus-ID: 01:00.0 chip-ID: 10de:1183
Display Server: X.Org 1.18.4 drivers: nouveau (unloaded: fbdev,vesa)
Resolution: 1920x1200@59.95hz, 1920x1200@59.95hz
GLX Renderer: Gallium 0.4 on NVE4 GLX Version: 3.0 Mesa 11.2.0 Direct Rendering: Yes
Audio: Card-1 Intel 9 Series Family HD Audio Controller
driver: snd_hda_intel bus-ID: 00:1b.0 chip-ID: 8086:8ca0
Card-2 NVIDIA GK104 HDMI Audio Controller
driver: snd_hda_intel bus-ID: 01:00.1 chip-ID: 10de:0e0a
Sound: Advanced Linux Sound Architecture v: k4.4.0-53-generic
Network: Card: Intel Ethernet Connection I217-V
driver: e1000e v: 3.2.6-k port: f040 bus-ID: 00:19.0 chip-ID: 8086:153b
IF: eno1 state: up speed: 1000 Mbps duplex: full mac: <filter>
Drives: HDD Total Size: 275.1GB (24.7% used)
ID-1: /dev/sda model: Crucial_CT275MX3 size: 275.1GB serial: 164414822EE0
Partition: ID-1: / size: 244G used: 56G (25%) fs: ext4 dev: /dev/sda2
ID-2: swap-1 size: 8.52GB used: 0.00GB (0%) fs: swap dev: /dev/sda3
RAID: System: supported: N/A
No RAID devices: /proc/mdstat, md_mod kernel module present
Unused Devices: none
Sensors: System Temperatures: cpu: 29.8C mobo: 27.8C
Fan Speeds (in rpm): cpu: N/A
Repos: Active apt sources in file: /etc/apt/sources.list
deb http: //download.ebz.epson.net/dsc/op/stable/debian/ lsb3.2 main
Active apt sources in file: /etc/apt/sources.list.d/official-package-repositories.list
deb http: //ftp-stud.hs-esslingen.de/pub/Mirrors/packages.linuxmint.com serena main upstream import backport
deb http: //ftp.fau.de/ubuntu xenial main restricted universe multiverse
deb http: //ftp.fau.de/ubuntu xenial-updates main restricted universe multiverse
deb http: //ftp.fau.de/ubuntu xenial-backports main restricted universe multiverse
deb http: //security.ubuntu.com/ubuntu/ xenial-security main restricted universe multiverse
deb http: //archive.canonical.com/ubuntu/ xenial partner
Info: Processes: 212 Uptime: 2:09 Memory: 2136.2/7914.3MB
Init: systemd v: 229 runlevel: 5 default: 2 Gcc sys: 5.4.0
Client: Unknown python2.7 client inxi: 2.2.35