HuntedHirsch
Newbie
- Registriert
- Apr. 2022
- Beiträge
- 2
Hallo liebe Community!
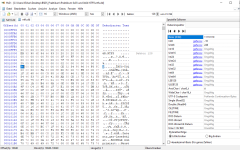
Im Rahmen von meinem Studium beschäftigen wir uns mit Dateisystemen, sowie deren Aufbau. Nun ist die Frage aufgekommen wieso die Größe des MFT-Eintrags im HexDump eines NTFS-Datenträgerabbilds kodiert ist. Der entsprechende Offset findet sich bei 0x40 und kann entweder positiv oder negativ im Zweierkomplement sein. Im Hexadezimalen ist alles von 0x00 - 0x7F positiv und alles von 0x80 - 0xFF negativ (im Zweierkomplement betrachtet). Möchte man nun die Größe des MFT-Eintrags auslesen, so muss man schauen ob der vorhandene Wert positiv oder negativ ist. Ist er positiv, so ist der gewonnene Wert die Größe des MFT-Eintrags in Clustern. Ist der Wert negativ, so muss mittels Zweierkomplement die Größe berechnet werden. Im Screenshot darunter ist der entsprechende Wert bereits markiert.
Das markierte Byte wird im Dateninspektor als Int8, also Ganzzahl dargestellt. Demnach ist die 0xF6 im Dezimalen eine -10. Jetzt muss man 2^|-10| rechnen um die Größe des MFT-Eintrags in Bytes zu errechnen. Das wäre hier 1024 und umgerechnet in Hex 0x400.
Nun ist die Frage warum man sich dafür entschieden hat bei positiven Werten direkt die Clusteranzahl anzugeben und bei negativen Werten die Größe des MFT-Eintrags in Bytes. (siehe Übersicht im Screenshot)
Vielleicht hat ja wer eine Idee")
Vielen Dank & noch mehr Grüße
Im Rahmen von meinem Studium beschäftigen wir uns mit Dateisystemen, sowie deren Aufbau. Nun ist die Frage aufgekommen wieso die Größe des MFT-Eintrags im HexDump eines NTFS-Datenträgerabbilds kodiert ist. Der entsprechende Offset findet sich bei 0x40 und kann entweder positiv oder negativ im Zweierkomplement sein. Im Hexadezimalen ist alles von 0x00 - 0x7F positiv und alles von 0x80 - 0xFF negativ (im Zweierkomplement betrachtet). Möchte man nun die Größe des MFT-Eintrags auslesen, so muss man schauen ob der vorhandene Wert positiv oder negativ ist. Ist er positiv, so ist der gewonnene Wert die Größe des MFT-Eintrags in Clustern. Ist der Wert negativ, so muss mittels Zweierkomplement die Größe berechnet werden. Im Screenshot darunter ist der entsprechende Wert bereits markiert.
Das markierte Byte wird im Dateninspektor als Int8, also Ganzzahl dargestellt. Demnach ist die 0xF6 im Dezimalen eine -10. Jetzt muss man 2^|-10| rechnen um die Größe des MFT-Eintrags in Bytes zu errechnen. Das wäre hier 1024 und umgerechnet in Hex 0x400.
Nun ist die Frage warum man sich dafür entschieden hat bei positiven Werten direkt die Clusteranzahl anzugeben und bei negativen Werten die Größe des MFT-Eintrags in Bytes. (siehe Übersicht im Screenshot)
Vielleicht hat ja wer eine Idee
Vielen Dank & noch mehr Grüße