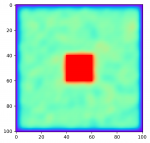
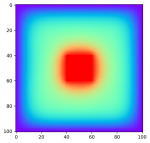
TheShooter
Lt. Junior Grade
- Registriert
- Juni 2011
- Beiträge
- 370
Hallo liebe Forengemeinde,
ich habe ein Programm geschrieben, was nach Laplace die Temperaturentwicklung eines Systems iterativ berechnet. Da ich gerne jeden Iterationsschritt in Echtzeit sehen möchte, benutze ich pygame um die Ergebnisse grafisch darzustellen.
Hier erst einmal der Code:
Das Problem ist nun, dass die Simulation super läuft, wenn ich n_jobs=1 (line 76) setze. Wenn ich jedoch die Anzahl der Jobs erhöhe, arbeitet das Programm auch, die Simulation funktioniert dann nur leider nicht richtig.
Ich habe bisher fast gar keine Erfahrung mit Parallelization, ich denke sogar dass ich hier eigentlich multiprocessing benutzen müsste.
In der obig eingestellten Auflösung ist die Performance auf einem Prozessorkern noch akzeptabel, sobald ich aber in Richtugn SD gehe, dauert ein Iterationsschritt mehrere Minuten.
Vielleicht gibt es auch noch andere Ansätze, wie ich die Performance verbessern könnte?
Wäre für frische Ideen sehr dankbar") .
.
Beste Grüße
The Shooter
PS: Das ganze läuft unter Python3 und wird unter Arch-Linux (Zen-Kernel) ausgeführt. Oh, und sorry für das "Denglish" im Code.
ich habe ein Programm geschrieben, was nach Laplace die Temperaturentwicklung eines Systems iterativ berechnet. Da ich gerne jeden Iterationsschritt in Echtzeit sehen möchte, benutze ich pygame um die Ergebnisse grafisch darzustellen.
Hier erst einmal der Code:
Python:
#importiere wichtige Libraries
import pygame
import numpy as np
from math import pi
import random
from joblib import Parallel, delayed
import multiprocessing
max_temp = 100 #maximale Temperatur
breite = 100 #Breite des Bildes
hoehe = 100 #Höhe des Bildes
x = np.linspace(0,breite,breite+1,dtype=int) #generiere x-koordinaten
y = np.linspace(0,hoehe,hoehe+1,dtype=int) #generiere y-koordinaten
area1_x = np.linspace(breite/2-10,breite/2+10,21,dtype=int) #x-koordinaten des ersten festen Temperaturbereichs
area1_y = np.linspace(hoehe/2-10,hoehe/2+10,21,dtype=int) #y-koordinaten des ersten festen Temperaturbereichs
rand = np.zeros((len(x),len(y))) #initialisiere das rand-array
def temp_color(temp): #konvertiere temperatur in Graustufenfarbe (0C...100C,schwarz...weiß)
val = int(temp*2.55)
return (val,val,val)
def draw_pixel(surface,pos,temp): #funktion um Pixel auf dem Schirm darzustellen
surface.set_at(pos,temp_color(temp))
def generate_rand(): #generiere eine zufällige Temperatur
rand = random.randrange(0,max_temp+1,1)
return rand
def initialize_temperature(): #generiere für jeden Punkt eine zufällige Temperatur
for i in range(len(x)):
for j in range(len(y)):
rand[i,j] = generate_rand()
def fixate_temperature(): #fixiere die Temperatur im Bereich area1
for i in np.nditer(area1_x):
for j in np.nditer(area1_y):
rand[i,j] = 100
for i in range(len(x)):
rand[i,0] = 0
rand[0,i-(breite-hoehe)] = 0
rand[i,hoehe] = 0
rand[breite,i-(breite-hoehe)] = 0
screen = pygame.display.set_mode((breite,hoehe)) #unser Bildschirm
def find_temp(i,j): #berechne die Temperatur basierend auf Laplace (iterativ später mit pool.map
fixate_temperature() #fixiere area1
#draw_pixel(screen,[i,j],rand[i,j])
rand[i,j] = 1/4*(rand[i+1,j]+rand[i,j+1]+rand[i-1,j]+rand[i,j-1]) #Laplace in Action
draw_pixel(screen,[i,j],rand[i,j]) #zeichne das neue Bild
return rand
initialize_temperature() #initialisiere die zufälligen Temperaturen
def main(): #die main-Funktion
pygame.init() #initialisiere pygame
pygame.display.set_caption("test-program") #Titel des Fensters
running = True
clock = pygame.time.Clock()
while running:
clock.tick(250) #Update-Intervall
num_cores=multiprocessing.cpu_count() #Anzahl der logischen Prozessoren
#iteriere über die find_temp-Funktion über alle Punkte
Parallel(n_jobs=1)(delayed(find_temp)(i,j) for j in range(len(y)-1) for i in range(len(x)-1))
print("ITER")
for event in pygame.event.get(): #damit man das Fenster schließen kann
if event.type == pygame.QUIT:
running = False
pygame.display.flip() #Zeichne ein neues Bild
pygame.quit() #sauberes Ende
if __name__=="__main__": #für die Windows-Nutzer
main()Das Problem ist nun, dass die Simulation super läuft, wenn ich n_jobs=1 (line 76) setze. Wenn ich jedoch die Anzahl der Jobs erhöhe, arbeitet das Programm auch, die Simulation funktioniert dann nur leider nicht richtig.
Ich habe bisher fast gar keine Erfahrung mit Parallelization, ich denke sogar dass ich hier eigentlich multiprocessing benutzen müsste.
In der obig eingestellten Auflösung ist die Performance auf einem Prozessorkern noch akzeptabel, sobald ich aber in Richtugn SD gehe, dauert ein Iterationsschritt mehrere Minuten.
Vielleicht gibt es auch noch andere Ansätze, wie ich die Performance verbessern könnte?
Wäre für frische Ideen sehr dankbar
Beste Grüße
The Shooter
PS: Das ganze läuft unter Python3 und wird unter Arch-Linux (Zen-Kernel) ausgeführt. Oh, und sorry für das "Denglish" im Code.