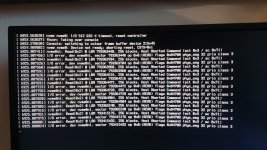
Hallo in die Runde,
ich habe seit einiger Zeit das Problem, dass Manjaro unregelmäßig mitten im Betrieb einfriert. Als Ursache habe ich die SSD in Verdacht, da nach einem Neustart ("REISUB") die SSD nicht erkannt wird und ich erst das System vom Strom nehmen muss, damit es wieder funktioniert. Als SSD nutze ich eine "SK Hynix Platinum P41 2TB", auf welcher Manjaro und meine gesamten Daten in mehreren Partitionen liegen. Die SSD ist im dritten Slot meines Mainboards (ASRock B650M Pro RS WiFi) installiert und zusätzlich mit einer Kupferplatte versehen. Die Temperatur im normalen Desktop-Betrieb liegt bei 43 °C. Falls relevant, meine restlichen Systemkomponenten sind hier zu finden. Ich nutze den dritten Slot, da in den beiden anderen meine Festplatten für Windows verbaut sind, ich nutze das System im Dualboot.
Anhand der auftretenden Fehlermeldungen hatte ich etwas gesucht und viele Einträge gefunden, dass die Stromsparmechanismen deaktiviert werden sollten. Ich habe daher in Grub den folgenden Befehl eingetragen:
Leider scheint das nicht geholfen zu haben. Wie könnte ich herausfinden, ob es an der SSD liegt? Das Mainboard habe ich noch nicht im Verdacht, da bei einem Neustart automatisch der Boot in Windows erfolgt und nur die Manjaro-SSD nicht erkannt wird, die beiden anderen SSDs sind voll funktionsfähig.
Für Tipps und Hinweise bin ich sehr dankbar!
(Daten sind nicht in Gefahr, die sind lokal vom NAS gespiegelt und private Daten liegen verschlüsselt auf VeraCrypt-Partitionen).
ich habe seit einiger Zeit das Problem, dass Manjaro unregelmäßig mitten im Betrieb einfriert. Als Ursache habe ich die SSD in Verdacht, da nach einem Neustart ("REISUB") die SSD nicht erkannt wird und ich erst das System vom Strom nehmen muss, damit es wieder funktioniert. Als SSD nutze ich eine "SK Hynix Platinum P41 2TB", auf welcher Manjaro und meine gesamten Daten in mehreren Partitionen liegen. Die SSD ist im dritten Slot meines Mainboards (ASRock B650M Pro RS WiFi) installiert und zusätzlich mit einer Kupferplatte versehen. Die Temperatur im normalen Desktop-Betrieb liegt bei 43 °C. Falls relevant, meine restlichen Systemkomponenten sind hier zu finden. Ich nutze den dritten Slot, da in den beiden anderen meine Festplatten für Windows verbaut sind, ich nutze das System im Dualboot.
Anhand der auftretenden Fehlermeldungen hatte ich etwas gesucht und viele Einträge gefunden, dass die Stromsparmechanismen deaktiviert werden sollten. Ich habe daher in Grub den folgenden Befehl eingetragen:
Bash:
nvme_core.default_ps_max_latency_us=0Leider scheint das nicht geholfen zu haben. Wie könnte ich herausfinden, ob es an der SSD liegt? Das Mainboard habe ich noch nicht im Verdacht, da bei einem Neustart automatisch der Boot in Windows erfolgt und nur die Manjaro-SSD nicht erkannt wird, die beiden anderen SSDs sind voll funktionsfähig.
Für Tipps und Hinweise bin ich sehr dankbar!
(Daten sind nicht in Gefahr, die sind lokal vom NAS gespiegelt und private Daten liegen verschlüsselt auf VeraCrypt-Partitionen).