Hallo zusammen,
ich hoffe, dass dieser Thread in einem angemessenen Bereich angelegt wurde...
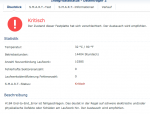
Ich habe mir vor einigen Tagen zwei HDDs mit 4TB hier im Forum gegönnt um mein NAS damit upzugraden. Das hat generell auch super funktioniert bis auf die Tatsache, dass eine der Festplatten laut Synology in einem "kritischen" Zustand ist. Der S.M.A.R.T. Test findet einen Fehler: "184 (end-to-end error)", was folgendes bedeutet:
"End-to-End error S.M.A.R.T. parameter is a part of HP's SMART IV technology and it means that after transferring through the cache RAM data buffer, the parity data between the host and the hard drive did not match. For detailed information see SMART IV Documentation from HP. Recommendations
This is a critical parameter. Degradation of this parameter may indicate imminent drive failure. Urgent data backup and hardware replacement is recommended."
Leider (somit kann ich nicht reklamieren) war dieser Fehler auch auf dem CDI-Screenshot im Verkaufsthread zu sehen, allerdings wird der Zustand der Platte dort tortzdem als GUT angezeigt, da der entsprechende Fehler wohl nicht ausgewertet wird bzw. nicht in die Gesamtbewertung eingeht.
Anbei seht ihr auch die Screenshots meines Synology. Hat jemand Erfahrungen mit dem Fehler? Sollte man schnell handeln oder kann man getrost "abwarten" bis der Fehler zu weiteren Problemen führt?
Danke und viele Grüße!
ich hoffe, dass dieser Thread in einem angemessenen Bereich angelegt wurde...
Ich habe mir vor einigen Tagen zwei HDDs mit 4TB hier im Forum gegönnt um mein NAS damit upzugraden. Das hat generell auch super funktioniert bis auf die Tatsache, dass eine der Festplatten laut Synology in einem "kritischen" Zustand ist. Der S.M.A.R.T. Test findet einen Fehler: "184 (end-to-end error)", was folgendes bedeutet:
"End-to-End error S.M.A.R.T. parameter is a part of HP's SMART IV technology and it means that after transferring through the cache RAM data buffer, the parity data between the host and the hard drive did not match. For detailed information see SMART IV Documentation from HP. Recommendations
This is a critical parameter. Degradation of this parameter may indicate imminent drive failure. Urgent data backup and hardware replacement is recommended."
Leider (somit kann ich nicht reklamieren) war dieser Fehler auch auf dem CDI-Screenshot im Verkaufsthread zu sehen, allerdings wird der Zustand der Platte dort tortzdem als GUT angezeigt, da der entsprechende Fehler wohl nicht ausgewertet wird bzw. nicht in die Gesamtbewertung eingeht.
Anbei seht ihr auch die Screenshots meines Synology. Hat jemand Erfahrungen mit dem Fehler? Sollte man schnell handeln oder kann man getrost "abwarten" bis der Fehler zu weiteren Problemen führt?
Danke und viele Grüße!