Sonnenheim
Newbie
- Registriert
- Dez. 2017
- Beiträge
- 7
Hi, ich habe hier eine 3TB WD Red bei der der Quicktest im WD Dashboard wiederholt mit Fehlercode 7 abbricht. CDI zeigt keine Auffälligkeiten. Kann ich der Platte noch vertrauen?




Folge dem Video um zu sehen, wie unsere Website als Web-App auf dem Startbildschirm installiert werden kann.
Anmerkung: Diese Funktion ist in einigen Browsern möglicherweise nicht verfügbar.
AEonVi schrieb:@Sonnenheim Huhu, und was besagt der Fehlercode: 7 im WD Dashboard?
https://support-de.wd.com/app/answe...stern-digital-dashboard:-fehlercodes#subject2Der vorherige Selbsttest wurde abgeschlossen, wobei das Leseelement des Tests fehlgeschlagen ist. Testen Sie erneut, nachdem Sie die Verbindungen überprüft haben. Ersetzen Sie das Laufwerk, wenn der Fehler wiederholt auftritt.
Der Lesetest ist fehlgeschlagen.Sonnenheim schrieb:Also laut support-de.wd.com : Der vorherige Selbsttest wurde abgeschlossen, wobei das Leseelement des Tests fehlgeschlagen ist. Testen Sie erneut, nachdem Sie die Verbindungen überprüft haben. Ersetzen Sie das Laufwerk, wenn der Fehler wiederholt auftritt.
Mal abgesehen vom letzten Satz kann ich mit der Beschreibung leider nichts anfangen.
Mit über 8 Jahren reiner Betriebszeit hat sie sich ihren Ruhestand doch redlich verdient.Sonnenheim schrieb:Die Platte ist auf jeden Fall Schrott.
Sehr vielsagend. Lade dir mal GSmartControl runter. Das kann dir mehr Infos liefern und auch selber SMART self-test anstossen.Sonnenheim schrieb:Fehlercode 7
Danke! Das Tool kannte ich noch nicht und ersetzt jetzt bei mir auf jeden Fall CDI. Wenn ich das Log richtig interpretiere scheint die Platte schon nach gut einem Jahr den ersten Defekt gehabt zu haben - ein Wunder das sie dann noch so lange ohne Zwischenfall durchgehalten hat.Fusionator schrieb:Lade dir mal GSmartControl runter.
Fusionator schrieb:Lade dir mal GSmartControl runter.
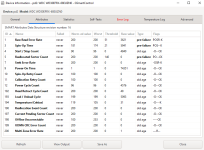
Das sieht er so als als würde das Tool Murks anzeigen, weil die Fehler (raw value) sind ja alle 0 und auch die normalized Werte weit über dem Threshold.Sonnenheim schrieb:Ich habe jetzt noch zwei weitere Platten mit GSmartControl angeschaut und alle haben, wie auch die WD Red, bei "Raw Read Error Rate", "Spin-Up Time" und "Reallocated Sector Count" den Typ "pre-failure". Lese ich die Ausgabe falsch oder habe ich gewaltiges Pech mit meinen HDD's?
CDI kann automatisch mit Windows gestartet werden, was auf jeden Fall nicht schlecht ist. Sollte also ein schwebender oder gar wiederzugewiesener Sektor auftauchen, wirst du sofort gewarnt.Sonnenheim schrieb:ersetzt jetzt bei mir auf jeden Fall CDI
Da ist nix Murks. Einfach verstehen, was da steht. Die Rohwerte werden alle aus der Platte ausgelesen.TomH22 schrieb:Das sieht er so als als würde das Took Murks anzeigen, weil die Fehler (raw value) sind ja alle 0 und auch die normalized Werte weit über dem Threshold.
Sonnenheim schrieb:Lese ich die Ausgabe falsch oder habe ich gewaltiges Pech mit meinen HDD's?
Ich weiß ja nicht was Du siehst. Aber die rohe Anzahl wiederzugewiesener Sektoren steht da eindeutig mit 0 und trotzdem schreibt das Tool "pre-fail" daneben.Fusionator schrieb:Da ist nix Murks. Einfach verstehen, was da steht. Die Rohwerte werden alle aus der Platte ausgelesen.
Raw Value ist z.B. nicht 0 und diese pre failure ist einfach nur eine Einordnung von GSmartControl nach der "Kritikalität" 🤣 wiederzugewiesene Sektoren sind nun mal ein ganz schlechtes Zeichen. Da brauchen wir nicht rumdiskutieren
Das selbe wie du, aber das passiert, wenn man Sachen nicht richtig zitiert bzw. aus dem Kontext reißt.Purche schrieb:Ich weiß ja nicht was Du siehst.
Es sind eben nicht alle 0.TomH22 schrieb:weil die Fehler (raw value) sind ja alle 0
Ist ja nicht zu übersehen und das mit pre-failure ist einfach eine Einstufung des Programms für bestimmte Attribute. Mehr nicht und das ist auch unabhängig von dem Rohwert, also auch bei nagelneuen Platten/SSDs immer so.Purche schrieb:Aber die rohe Anzahl wiederzugewiesener Sektoren steht da eindeutig mit 0 und trotzdem schreibt das Tool "pre-fail" daneben.
Type Bei Grenzunterschreitung droht ein baldiger Ausfall (Pre-fail) / der Parameter informiert über Temperatur / Alterungsprozesse der Festplatte (Old age)
Da habe ich mich unsauber ausgedrückt. Ich bezog mich auf die Werte die 0 und Pre-Fail stehen haben.Fusionator schrieb:Es sind eben nicht alle 0.
Ja, mit dieser Erklärung macht es Sinn. Das "Pre-Fail" ist also nicht eine Einstufung des aktuellen Wertes, sondern der Relevanz dieses Attributes für die Gesundheit der Platte. So wie beim Auto die Ölwarnlampe rot ist...Fusionator schrieb:Da das Tool ja auf smartctl basiert, zitiere ich mal kurz aus https://wiki.ubuntuusers.de/Festplattenstatus/
Also, die Type Werte sind tatsächlich kein Murks, sondern wir haben alle die Ausgabe falsch gelesen.Sonnenheim schrieb:Ich habe jetzt noch zwei weitere Platten mit GSmartControl angeschaut und alle haben, wie auch die WD Red, bei "Raw Read Error Rate", "Spin-Up Time" und "Reallocated Sector Count" den Typ "pre-failure". Lese ich die Ausgabe falsch oder habe ich gewaltiges Pech mit meinen HDD's?
Genau so scheint der "Type" Wert zu lesen seinPurche schrieb:Klar, jede Platte die am Ende mit zu vielen wiederzugewiesenen Sektoren gestorben ist, hat da mal ne 0 stehen gehabt. Die 0 muss also ein ganz böses Anzeichen drohenden Unheils sein
Grundsätzlich muss man bei Nutzung von Diagnosetools über USB auch immer im Hinterkopf haben, das die USB-SATA Wandler das nicht immer transparent und ohne Probleme unterstützen.Sonnenheim schrieb:Der vorherige Selbsttest wurde abgeschlossen, wobei das Leseelement des Tests fehlgeschlagen ist.
Gute Frage, aber ich glaube nicht, dass WD dermaßen perfekte Platten baut, dass da nie die ECC Fehlerkorrektur eingreifen müsste. Insofern sollte dass schon den Wert nach ECC Fehlerkorrektur wieder spiegeln. Vielleicht ist das der Wert für die zweite KorrekturstufeTomH22 schrieb:Aber meint Raw-Read Anzahl Leserfehler vor oder nach Fehlerkorrektur?
Kann man. HEX ist die default Einstellung. Ist aber trotzdem bei bestimmten Platten/Attributen nützlichTomH22 schrieb:Ich habe CDI noch nie benutzt, kann man das auf Dezimal umstellen?
Die Probleme, die ich bisher hatte waren lediglich: Kein Firmwareupdate möglich und extended Selftest bricht wegen automatischem Sleep jedes Mal ab.TomH22 schrieb:Grundsätzlich muss man bei Nutzung von Diagnosetools über USB auch immer im Hinterkopf haben, das die USB-SATA Wandler das nicht immer transparent und ohne Probleme unterstützen.