GeForce RTX 50: Nvidia veröffentlicht technisches Whitepaper für Blackwell

Nvidia hat das Whitepaper für die Blackwell-Architektur hinter GeForce RTX 50 veröffentlicht. Mit diesem Dokument geht Nvidia im Detail auf maßgebliche Änderungen zwischen den Architekturen ein und erklärt neue Features.
Ein tieferer Einblick in die Architektur
Nachdem heute die Tests der GeForce RTX 5080 und letzte Woche die Tests der GeForce RTX 5090 veröffentlicht wurden, kann ab jetzt auch das Blackwell Whitepaper auf der Nvidia-Webseite abgerufen werden.
Während bei der Vorstellung der Blackwell-Architektur überwiegend mit Schlagworten gearbeitet wurde und die gezeigten Grafiken vergleichsweise kleine Architektur-Änderungen zwischen Ada Lovelace und Blackwell zeigten, geht das Whitepaper entsprechend tiefer. Dass deutlich mehr hinter Blackwell steckt und vor allem viel Zukunft, zeigt der Umfang des Whitepapers von 57 Seiten.
Blackwell im Überblick
Nvidia schreibt zum Beginn des Whitepapers selbst, dass Blackwell für die nächste Generation an KI-unterstützen Spielen und Anwendungen entwickelt wurde. Folgende Punkte benennt Nvidia dabei:
- SM für neurales Shading
- Max-Q Funktionen für verbesserte Energieeffizienz
- 4. Generation der RT-Kerne
- 5. Generation der Tensor-Kerne
- Nvidia DLSS 4
- RTX Neurale Shader
- AI Management Processor (AMP)
- GDDR7-Speicher
- Mega Geometry
Das Whitepaper stellt diese Punkte anhand der Änderungen zwischen Ada Lovelace und Blackwell genauer vor und beschreibt die Möglichkeiten.
So wird zum Beispiel die Änderung der Streaming Multiprocessors zwischen Blackwell und Ada Lovelace genauer beschrieben. In den Grafiken zur Vorstellung von Blackwell ist für die SM zu erkennen, dass nun 32 Shader entweder INT- oder FP-Berechnungen ausführen. Bei Ada Lovelace und Ampere konnten nur 16 Shader mit 32-Bit-Ganzzahlen und -Fließkommazahlen umgehen, die weiteren 16 ALUs pro Shader-Partition konnten ausschließlich FP-Berechnungen ausführen.

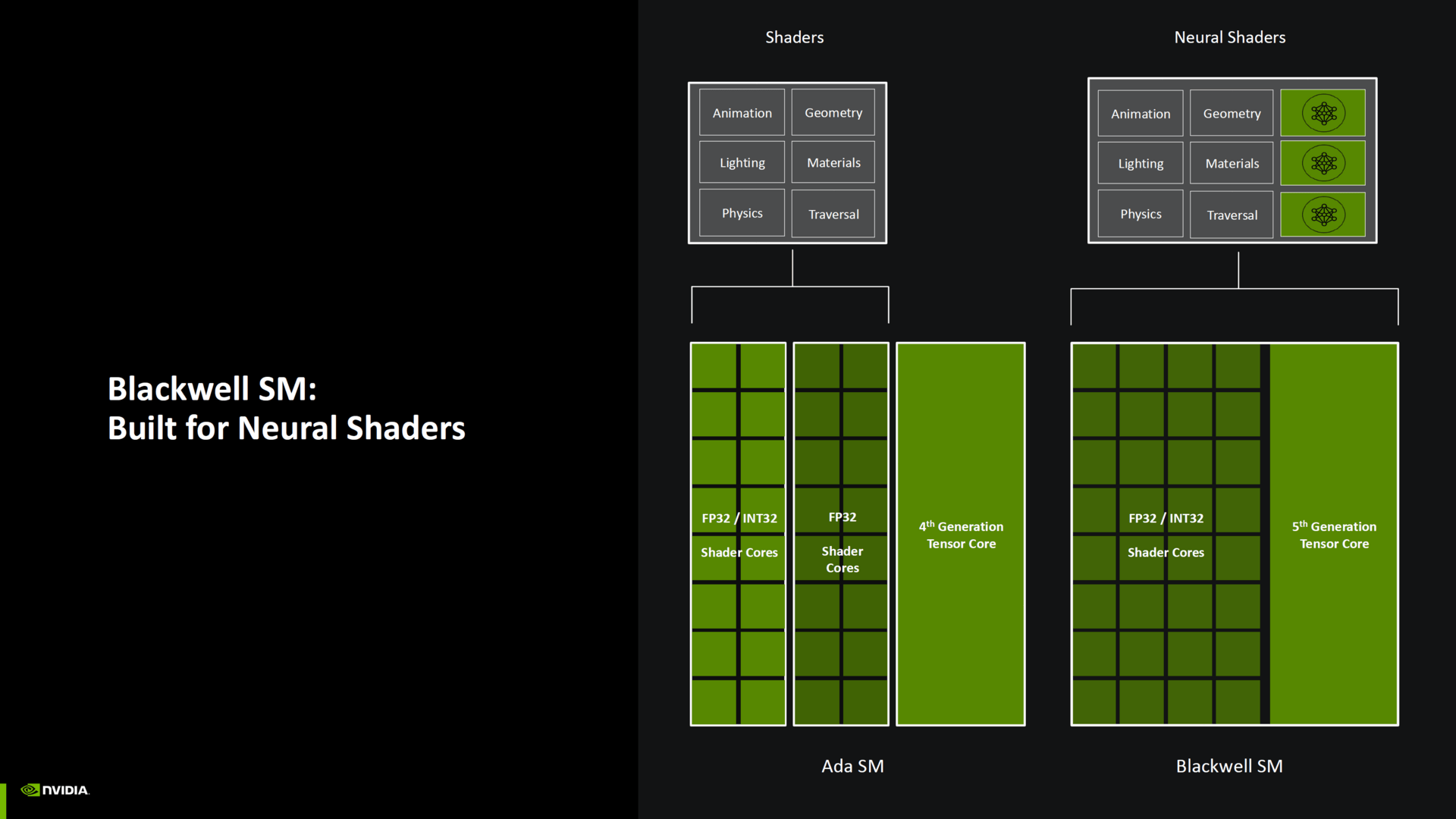
Mit dieser Änderung verliert Blackwell allerdings eine Fähigkeit gegenüber Ada Lovelace, die Nvidia mit Turing eingeführt hat: INT- und FP-Berechnungen können innerhalb einer Shader-Partition nicht mehr gleichzeitig in einem Taktzyklus ausgeführt werden.

Mega Geometrie und Raytracing
Einen besonderen Schwerpunkt legt Nvidia im Whitepaper auf die Mega Geometry sowie deren Auswirkungen auf die Raytracing-Kerne. So soll es mit der Mega-Geometrie nicht mehr notwendig sein, auf niedriger aufgelöste Proxys für Raytracing-Effekte zurückzugreifen. Damit soll es modernen LOD-Systemen (Level of Detail), wie Nanite in der Unreal Engine 5, ermöglicht werden, Raytracing-Effekte bei vollen Details zu berechnen.
Nvidia beschreibt dabei zwei große Hürden, die verhindern, dass Raytracing-Effekte bei modernen LOD-Systemen mit allen Details der Geometrie berechnet werden: „Cluster based LOD updates“ sowie die hohe Anzahl an verschiedenen Objekten in modernen Spielen. Nvidia führt zur Lösung die PTLAS (Partitioned Top-Level Acceleration Structure) ein und erweitert so die klassische TLAS (Top-Level Acceleration Structure).
Die Funktionalität der Mega Geometry steht dabei allen RTX-Grafikkarten seit Turing zur Verfügung. Entwickler können unter DirectX 12 mithilfe der NVAPI auf die Funktionen zurückgreifen. Für Vulkan gibt es eine Hersteller-Erweiterung, und Nvidias OptiX erhält nativen Support ab Version 9.0.
Und noch viel mehr
Neben den hier kurz vorgestellten Änderungen von Blackwell gegenüber Ada Lovelace und der neuen Mega Geometry gibt es noch weitere Änderungen, die an dieser Stelle aber den Rahmen sprengen würden. Wer mehr über Blackwell und Neural Shader wissen möchte, hat jetzt mit dem Whitepaper allerdings dafür die notwendigen Unterlagen.
- Nvidia GeForce RTX 5090 im Test: DLSS 4 MFG trifft 575 Watt im 2-Slot-Format
- Nvidia GeForce RTX 5080 im Test: DLSS 4 MFG und ein kleiner FPS-Boost
- Nvidia GeForce „Blackwell“: Technische Details zu RTX 5090, 5080 & 5070 (Ti)
- Nvidia DLSS 4: Multi Frame Generation und ein neues neuronales Netzwerk
- Nvidia Reflex 2 im Detail: So senkt Frame Warp die Latenz in allen Szenarien
| RTX 5090 | RTX 5080 | RTX 5070 Ti | RTX 5070 | |
|---|---|---|---|---|
| Architektur | Blackwell | |||
| GPU | GB202 | GB203 | GB203 | GB205 |
| Fertigung | TSMC 4N | |||
| Transistoren | 92,2 Mrd. | 45,6 Mrd. | 45,6 Mrd | 31,1 Mrd. |
| Chipgröße | 750 mm² | 378 mm² | 378 mm² | 263 mm² |
| SM | 170 | 84 | 70 | 48 |
| FP32-ALUs | 21.760 | 10.752 | 8.960 | 6.144 |
| RT-Kerne | 170, 4th Gen | 84, 4th Gen | 70, 4th Gen | 48, 4th Gen |
| KI-Kerne | 680, 5th Gen | 336, 5th Gen | 280, 5th Gen | 192, 5th Gen |
| Boost-Takt | 2.407 MHz | 2.617 MHz | 2.452 MHz | 2.512 MHz |
| FP32-Leistung | 104,8 TFLOPS | 56,3 TFLOPS | 43,9 TFLOPS | 30,9 TFLOPS |
| FP16-Leistung | 104,8 TFLOPS | 56,3 TFLOPS | 43,9 TFLOPS | 30,9 TFLOPS |
| FP16-Leistung über Tensor | 419 TFLOPS | 225 TFLOPS | 175,8 TFLOPS | 123,5 TFLOPS |
| Textureinheiten | 680 | 336 | 280 | 192 |
| ROPs | 176 | 112 | 96 | 80 |
| L2-Cache | 98.304 KB | 65.536 KB | 49.152 KB | |
| Speicher | 32 GB GDDR7 | 16 GB GDDR7 | 16 GB GDDR7 | 12 GB GDDR7 |
| -durchsatz | 28 Gbps | 30 Gbps | 28 Gbps | |
| -interface | 512 Bit | 256 Bit | 192 Bit | |
| -bandbreite | 1.792 GB/s | 960 GB/s | 896 GB/s | 672 GB/s |
| Slot-Anbindung | PCIe 5.0 ×16 | |||
| Video-Engine | 3 × NVENC (9th Gen) 2 × NVDEC (6th Gen) |
2 × NVENC (9th Gen) 2 × NVDEC (6th Gen) |
2 × NVENC (9th Gen) 1 × NVDEC (6th Gen) |
1 × NVENC (9th Gen) 1 × NVDEC (6th Gen) |
| TDP | 575 Watt | 360 Watt | 300 Watt | 250 Watt |